Hugging Face の AXERA-TECH で AX650N 用の Kokoro デモが公開されていたので LLM-8850 で試してみました。
環境作成
デモのダウンロード
git lfs をインストールしていない場合は、ここの手順に従ってインストールしてください。
Hugging Face から kokoro.axera をダウンロードします。
git clone https://huggingface.co/AXERA-TECH/kokoro.axera
デモの実行に必要な axengine もダウンロードしておきます。
git clone https://huggingface.co/AXERA-TECH/PyAXEngine
uv 仮想環境の作成
READNE.md の説明では conda を使っていますが、uv を使ってみます。uv をインストールしていない場合は以下でインストールできます。
curl -LsSf https://astral.sh/uv/install.sh | sh
依存Pythonパッケージをインストールします。
cd kokoro.axera
uv init
uv add -r requirements.txt
uv add axengine@file://../PyAXEngine/axengine-0.1.3-py3-none-any.whl
uv run python -m spacy download en_core_web_sm
デモの実行
uv run demo_kokoro_ax.py --text \
"こんにちは、これはテキスト読み上げのテストです。" \
--lang j --voice checkpoints/voices/jf_alpha.pt \
--output output_jp.wav -d models
以下のようなメッセージが表示されます。
[INFO] Available providers: ['AXCLRTExecutionProvider']
初始化模型...
[INFO] Using provider: AXCLRTExecutionProvider
[INFO] SOC Name: AX650N
[INFO] VNPU type: VNPUType.DISABLED
[INFO] Compiler version: 5.0-patch1-dirty d9477bd2-dirty
[INFO] Using provider: AXCLRTExecutionProvider
[INFO] SOC Name: AX650N
[INFO] VNPU type: VNPUType.DISABLED
[INFO] Compiler version: 5.0-patch1-dirty d9477bd2-dirty
[INFO] Using provider: AXCLRTExecutionProvider
[INFO] SOC Name: AX650N
[INFO] VNPU type: VNPUType.DISABLED
[INFO] Compiler version: 5.0-patch1-dirty d9477bd2-dirty
2025-12-10 23:27:51.282885442 [W:onnxruntime:Default, device_discovery.cc:164 DiscoverDevicesForPlatform] GPU device discovery failed: device_discovery.cc:89 ReadFileContents Failed to open file: "/sys/class/drm/card1/device/vendor"
初始化完成: 4.191s
============================================================
输出: output_jp.wav | 时长: 3.52s
============================================================
初始化: 4.191s
音频推理: 0.488s (共1次)
├─ Model1: 0.021s (平均21.0ms)
├─ Model2: 0.017s (平均17.3ms)
├─ Model3: 0.202s (平均202.2ms)
└─ Model4 onnx: 0.086s (平均86.3ms)
rtf:0.138
============================================================
途中、GPUが見つからない旨のメッセージが表示されていますが、これは onnxruntime モジュールのインポート時に出るもので、このメッセージが出ても ONNX モデルは CPU で処理されるので問題ありません。
生成された音声は output_jp.wav ファイルに出力されます。以下で再生できます。
aplay output_jp.wav
デモスクリプトのパラメータ
| パラメータ | 説明 |
|---|---|
| --axmodel_dir, -d | モデルファイルのディレクトリ(デフォルト models) |
| --voice, -v | 声紋ファイルのパス(必須) |
| --text, -t | 合成するテキスト(多言語対応) |
| --lang, -l | 言語コード(例: a, z, j, ...)。現状は中国語、英語、日>本語のみ検証済み |
| --config, -c | 設定ファイルのパス |
| --output, -o | 出力する wav ファイル名 |
| --fade_out, -f | 音声末尾のフェードアウト時間(秒)。音声末尾のノイズ軽>減のため |
| --max_len, -m | 最大文分割長(デフォルト 96) |
TTSサービス
Kokoro を利用した音声合成サービスのデモもあります。 kokoro_svr.py というものですが、中国語音声にしか対応していないので、とりあえず日本語に対応した kokoro_svr_jp.py にしてみました。差分は次のとおりです。
--- kokoro_svr.py 2025-12-08 21:52:48.734836469 +0900
+++ kokoro_svr_jp.py 2025-12-10 00:30:22.692752456 +0900
@@ -13,7 +13,7 @@
_tts_cache = {}
-def get_tts(lang = "z"):
+def get_tts(lang = "j"):
axmodel_dir = "models"
config = "checkpoints/config.json"
if lang not in _tts_cache:
@@ -67,7 +67,7 @@
if not sentence:
self._send_json({"error": "Field 'sentence' is required"}, 400)
return
- lang = params.get("language", "z")
+ lang = params.get("language", "j")
try:
sample_rate = int(params.get("sample_rate", 24000))
except ValueError:
@@ -84,7 +84,7 @@
# 生成音频
try:
tts = get_tts(lang)
- audio = tts.run(sentence, speed=speed, sample_rate=sample_rate, voice = "checkpoints/voices/zf_xiaoyi.pt")
+ audio = tts.run(sentence, speed=speed, sample_rate=sample_rate, voice = "checkpoints/voices/jf_alpha.pt")
except Exception as e:
self._send_json({"error": f"TTS failed: {e}"}, 500)
return
TTSサービスを起動します。
uv run kokoro_svr_jp.py --port 28000
別のターミナルから以下を実行してみます。
curl -X POST "http://127.0.0.1:28000/tts" \
-H 'Content-Type: application/json' \
-d '{ "sentence": "こんにちは、これはテキスト読み上げのテストです。" }' \
--output tts_jp.wav
生成された音声は tts_jp.wav ファイルに出力されます。以下で再生できます。
aplay tts_jp.wav
2025/12/27 追記
2025/12/26 に kokoro.axera が更新され、上記記事から以下が変更になりました。
- ボイス用ファイルの形式が .pt (PyTorch モデル形式)から .npy (.npy 形式ファイル)に変更
- gradio を用いた Web ブラウザ UI を追加
kooro_svr.py の変更
1 によって kokoro_svr.py も変更になったので、日本語用に書き換えていた kokoro_svr_jp.py も変更します。ついでにデフォルトのポートも変更してしまいます(8000 のままだと OpenAI API のポートとかぶってしまうので)。
--- kokoro_svr.py 2025-12-27 18:41:42.609301820 +0900
+++ kokoro_svr_jp.py 2025-12-27 18:50:35.220352964 +0900
@@ -74,7 +74,7 @@
if not sentence:
self._send_json({"error": "Field 'sentence' is required"}, 400)
return
- lang = params.get("language", "z")
+ lang = params.get("language", "j")
try:
sample_rate = int(params.get("sample_rate", 24000))
except ValueError:
@@ -88,7 +88,7 @@
return
- voice = params.get("voice", "zf_xiaoyi")
+ voice = params.get("voice", "jf_alpha")
if voice not in voice_list:
self._send_json({"error": f"Voice {voice} not found"}, 400)
return
@@ -124,7 +124,7 @@
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Whisper Server")
- parser.add_argument("--port", type=int, default=8000, help="Port to run the server on")
+ parser.add_argument("--port", type=int, default=28000, help="Port to run the server on")
args = parser.parse_args()
host = "0.0.0.0"
port = args.port
動かすには scipy のインストールが必要になりました。次のコマンドでインストールしておいてください。
uv add scipy
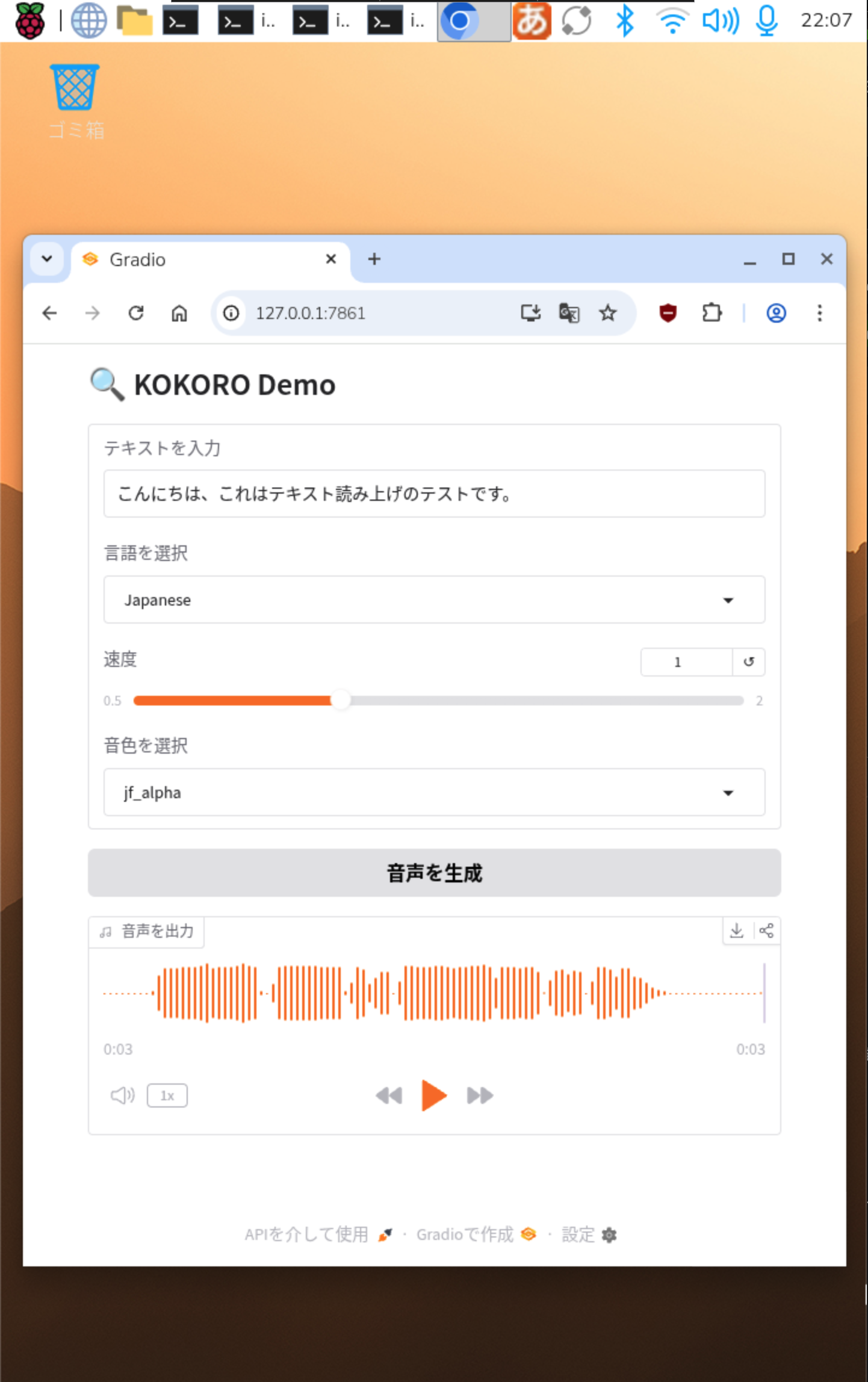
Gradio による Web UI デモ
Gradioを使った Web UI デモが追加になりました。使うには、ます Gradio をインストールします。
uv add gradio
デモスクリプトは gradio_demo.py というものですが、UI のラベルなどが中国語なので、日本語にしてみた gradio_demo_jp.py にしてみました。差分は次のとおりです。
--- gradio_demo.py 2025-12-26 20:33:37.447867328 +0900
+++ gradio_demo_ja.py 2025-12-27 18:52:50.559960867 +0900
@@ -10,10 +10,10 @@
result = subprocess.run(['ip', 'a'], capture_output=True, text=True)
output = result.stdout
- # 匹配所有IPv4
+ # すべての IPv4 アドレスを得る
ips = re.findall(r'inet (\d+\.\d+\.\d+\.\d+)', output)
- # 过滤掉回环地址
+ # ループバックアドレスを除外
real_ips = [ip for ip in ips if not ip.startswith('127.')]
return real_ips
@@ -50,20 +50,20 @@
lang_key = LANG_CODES_REV[language] # 例:Mandarin Chinese -> z
filtered_voices = [v for v in voice_list.keys() if v.startswith(lang_key)]
- # 例句填充
+ # 例文を挿入
example_text = EXAMPLE_SENTENCES.get(lang_key, "")
if not filtered_voices:
return gr.update(value=example_text), gr.update(value=None, choices=[])
return (
- gr.update(value=example_text), # 更新输入文本
- gr.update(value=filtered_voices[0], choices=filtered_voices) # 更新音色
+ gr.update(value=example_text), # 入力テキストを更新
+ gr.update(value=filtered_voices[0], choices=filtered_voices) # 音色を更新
)
voice_list = {}
-# 加载checkpoints/voices下的所有pt文件的文件名作为key
+# checkpoints/voices_npy 配下にあるすべての .npy ファイルのファイル名をキーとして読み込む
voice_list = glob.glob("checkpoints/voices_npy/*.npy")
voice_list = {os.path.basename(v).replace(".npy", ""): v for v in voice_list}
@@ -90,20 +90,20 @@
with gr.Row():
with gr.Column():
- sentence = gr.Textbox(label="输入文本",value="爱芯元智半导体股份有限公司,致力于打造世界领先的人工智能感知与边缘计算芯片.")
- language = gr.Dropdown(label="选择语言", choices=list(LANG_CODES_REV.keys()), value="Japanese")
+ sentence = gr.Textbox(label="テキストを入力",value="こんにちは、これはテキスト読み上げのテストです。")
+ language = gr.Dropdown(label="言語を選択", choices=list(LANG_CODES_REV.keys()), value="Japanese")
speed = gr.Slider(label="速度", minimum=0.5, maximum=2.0, value=1.0, step=0.1)
voice = gr.Dropdown(
- label="选择音色",
+ label="音色を選択",
choices=list(v for v in voice_list.keys() if v.startswith(LANG_CODES_REV["Japanese"])),
value=list(v for v in voice_list.keys() if v.startswith(LANG_CODES_REV["Japanese"]))[0] if voice_list else None,
allow_custom_value=True
)
- generate = gr.Button("生成音频")
+ generate = gr.Button("音声を生成")
with gr.Column():
- audio = gr.Audio(label="输出音频")
+ audio = gr.Audio(label="音声を出力")
- # 点击生成按钮时,调用服务器端的TTS API
+ # 生成ボタンをクリックすると、サーバー側の TTS API を呼び出す
generate.click(
fn=tts,
inputs=[sentence, language, speed, voice],
@@ -115,10 +115,11 @@
outputs=[sentence, voice],
)
-# 启动
+# 起動
ips = get_all_local_ips()
port = 7861
for ip in ips:
print(f"* Running on local URL: http://{ip}:{port}")
ip = "0.0.0.0"
+os.makedirs("history", exist_ok=True)
demo.launch(server_name=ip, server_port=port)
TTSサービスを起動します。
uv run kokoro_svr_jp.py
別のターミナルでデモスクリプトを起動します。
uv run gradio_demo_jp.py
Web ブラウザから次の URL にアクセスします。
http://127.0.0.1:7861
テキストを入力して「音声を生成」ボタンをクリックすると、hostory/ 配下に合成した音声ファイルが出力されます。生成した音声の再生も Web UI 上で可能です。