嘆けとて 月やはものを 思はする
かこち顔なる わが涙かな
西行法師(86番) 『千載集』恋・926
■□■ 現代語訳 ■□■
「嘆け」と言って、月が私を物思いにふけらせようとするのだろうか? いや、そうではない。
月のせいだとばかりに流れる私の涙なのだよ。
はじめに

ハローワールド!
こちらはカノジョできない機械学習界隈エンジニア Advent Calendar 2016の22日の内容です。
年の瀬になりまして上流データサイエンティストの皆さんは愛する方とシャンパン片手に優雅な日々を過ごしいることと思います。
就活の年だった僕の話ですか? やめましょうかこの話。
しかし、華やかな世界の陰には泥臭い世界が広がっているものです。
シャンパンの気泡を生み出した酵母が澱となって底に沈むように、日々報告される深層学習の輝かしい成果の裏では数多の「失敗」研究たちが人知れず消えていきます。
何故彼らは消えていくのか。
何故彼らは消えなければならなかったのか。
本記事ではコンピュータによる画像の認識を研究している自分が生み出し、人知れず消えていこうとしている深層学習の「失敗」研究に供養を兼ねてスポットを当てていこうと思います。
失敗研究1『ResNet with Gates』
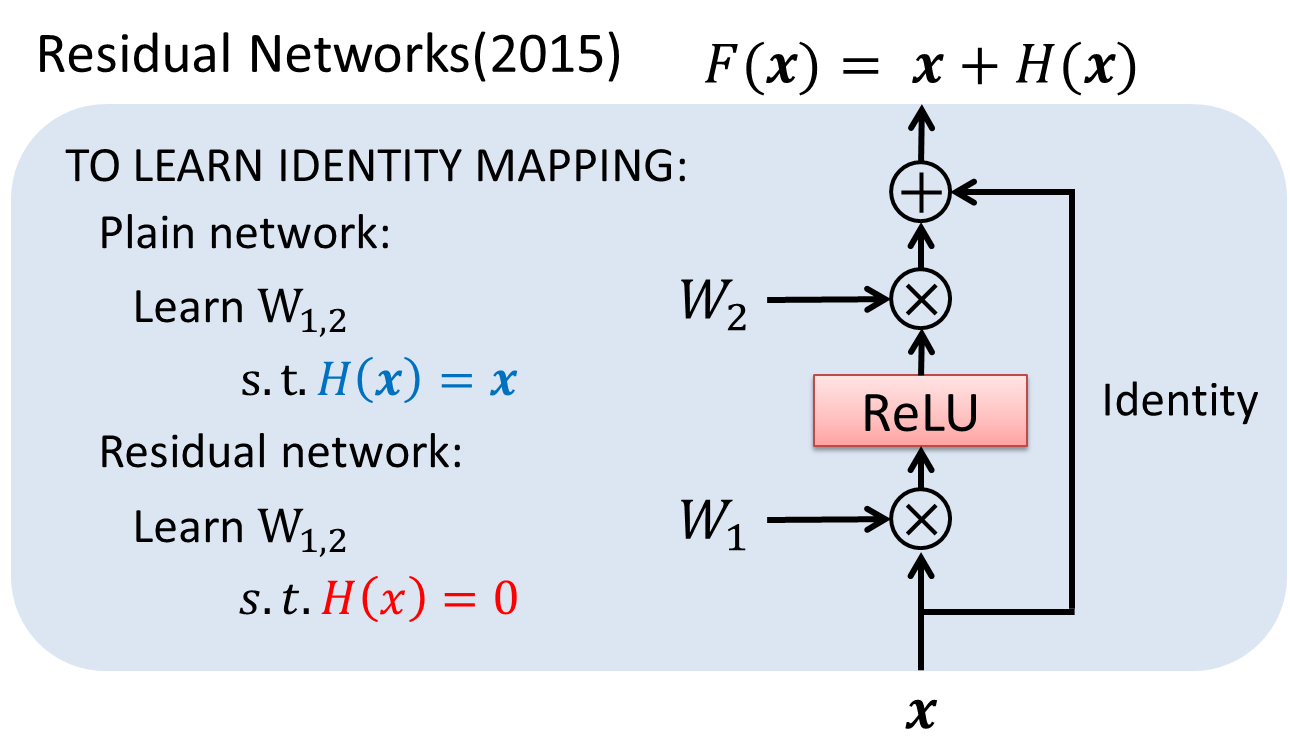
昨年から今年にかけての画像認識におけるブレイクスルーといえば、何と言ってもResNetです。
ResNetは様々な所で解説されているので詳しくは言及しませんが、入力xを畳み込みの後で足し合わせることで飛躍的に精度を向上させた画像認識用超多層深層学習ネットワークです。
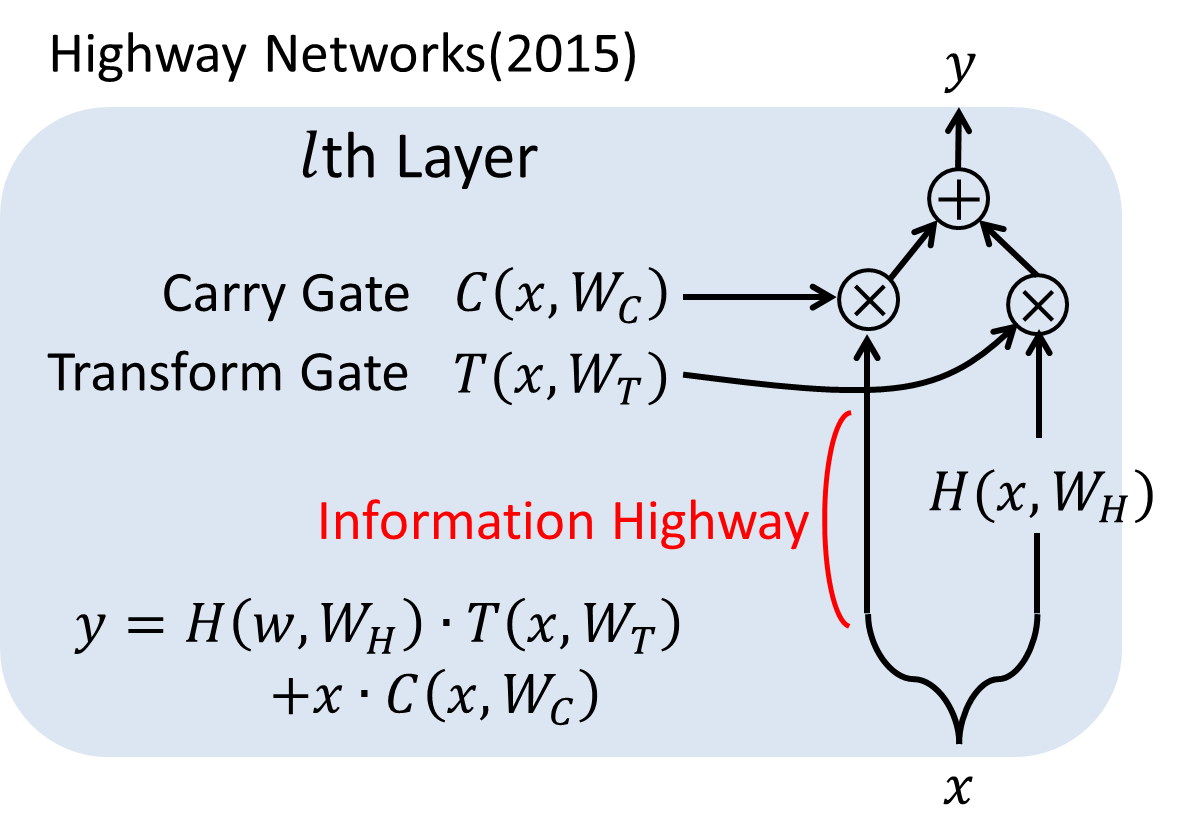
他方、2015年にはResNetとは少し違う超多層深層学習のためのアプローチとして,Highway Networksが提案されています。
これは各層にゲートを設け,学習結果をそのまま通すか加工するかという制御を行うことで、深いネットワークを学習できるようにする手法です。
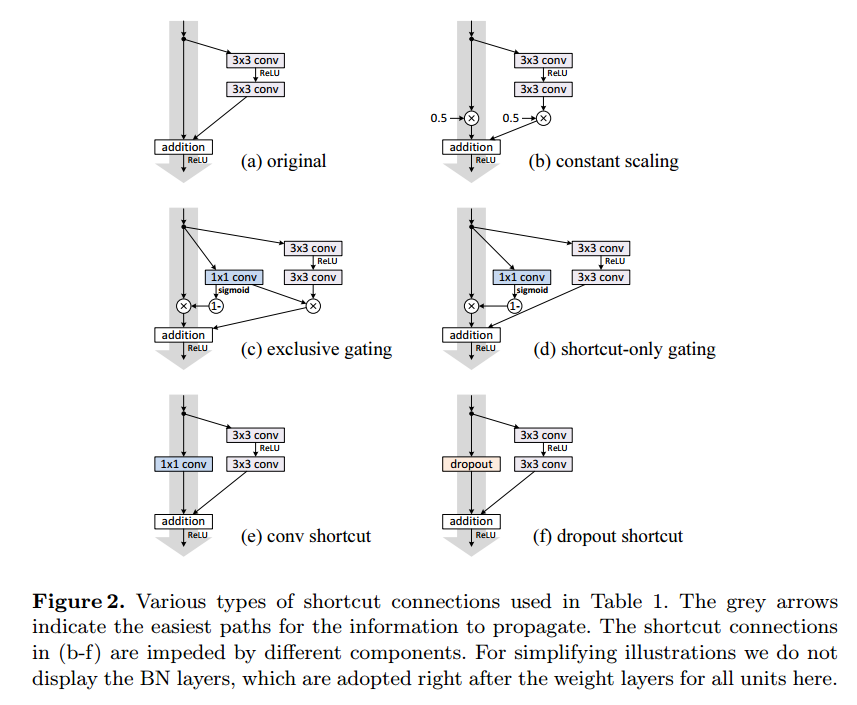
しかし、これらの工夫を用いても、数百層の学習が限界とされています。
一般に『多層になればなるほどネットワークの表現力が高くなり、性能が上がりやすい』と言われているため、より多層でも学習が上手く進む構造の提案は非常に重要です。
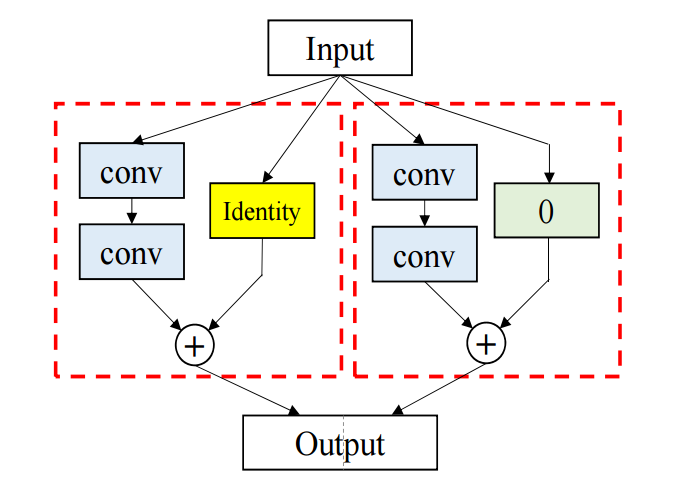
そこで、ResNetの構造とHighway Networksのゲートを組み合わせることで、より多層なネットワークの実現が出来るのではないかと考え、簡単な実験を行いました。
そして、見事に散りました。
自分の実験ではResidual Functionとは別にゲート用のFunctionを設定し、Residual Functionの出力を制御する形でゲートの導入を行いました。
しかし、幾つかの条件で検討しましたが、メモリや計算時間を食うばかりで認識精度は低下してしまいました。
その後の先行研究の調査で、同様の実験はResNetの著者らによる追実験でも言及されており、同様に性能の改善を望んだものの、失敗していたらしいということを知りました。
教訓: 先行研究の調査はしっかりしよう。
失敗研究2『Snapshot Adamble』
画像認識ではネットワークの構造に焦点が当たることが多いですが、一方でネットワークをどのようなハイパーパラメータで最適化するかも非常に重要になります。
Training and investigating Residual NetsのAlternate optimizersで示されているように、ResNetのような優れたネットワークであっても最適化の設定によっては上手く学習できないことがあります。
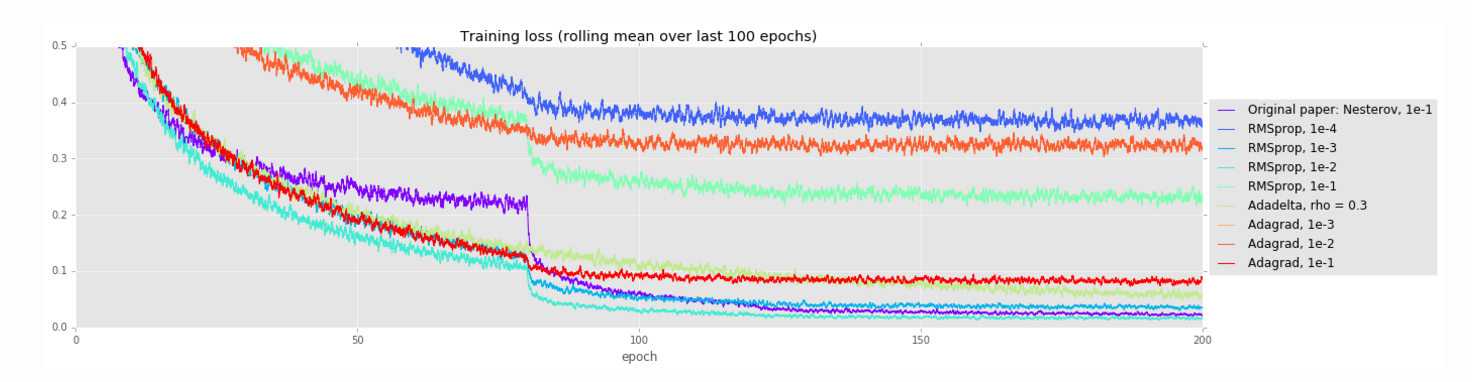
2016年にも様々な最適化手法が提案されていますが、中でもSnapshot Ensembleと呼ばれる周期的な学習率の設定は、徐々に学習率を調整する従来手法よりも性能が高いということが示されています。
これは急激に学習率を減らすことで意図的に局所解に近付け、学習率を一気に増やすことで局所解の近くから再度学習を始めるサイクルを繰り返すことでより最適解に近い局所解を探索する手法です。
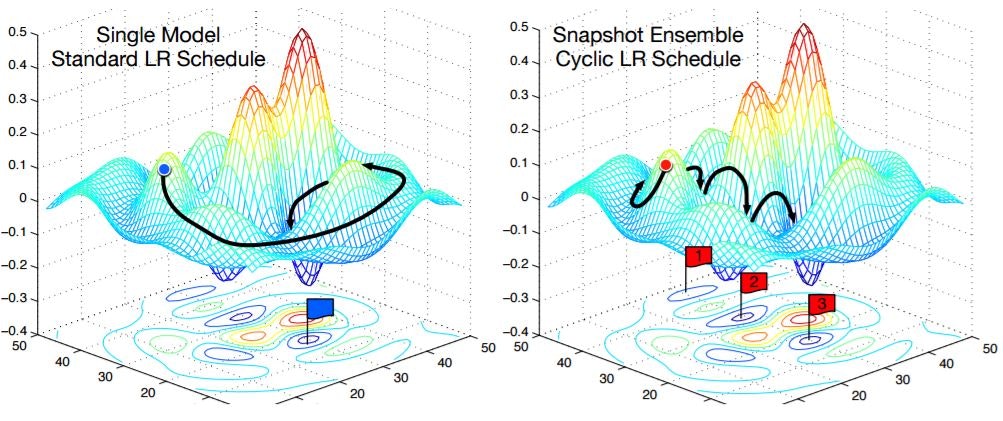
しかし、Snapshot Ensembleは学習率の初期値の設定が難しいという問題があります。
これはAdamに代表される学習に応じてある程度学習率を設定出来る手法とSnapshot Ensembleを併用することで、軽減できると考えられます。
そこで、AdamをSnapshot Ensemblesで調整することで、実際に学習が可能かを実験しました。
そして、見事に散りました。
Snapshot Ensembleは急激に学習率を増加させることで局所解周辺からの脱出を図り、再学習を促しています。
しかし実験では学習率を自動調整する手法との組み合わせてしまったことで、局所解から脱出できないという新たな問題が生まれてしまいました。
この問題を避けるためには従来の学習率の自動調整法とは真逆の、意図的にパラメータを局所解から遠ざける新たな自動調整手法へのスイッチが必要となります。
これは修士の学生が挑むにはいささか荷が重いため、この実験はあえなくお蔵入りとなりました。
教訓: 理論と実践の両立が大事。
失敗研究3『SlideNet』
画像認識ネットワークもまた進化した年でした。
やはり花型はResNetやその発展型でしたが、提案された数多くのネットワークは必ずしもResNetにまつわるものではありませんでした。
中でもDenseNetは一際異彩を放っていたネットワークです。
DenseNetは過去の畳み込み層の出力を全て保持しつつ、新しい特徴を徐々に生成するネットワークです。

一方、PyramidNetもまた異彩を放っていました。
PyramidNetはResidual Functionを持ちながらもDenseNetと同様に新しい特徴を徐々に生成するネットワークです。
この二つのネットワークは興味深いことに、Channel数を増やしていくというとても似たアプローチで高い精度を実現しています。
DenseNetはChannel増加部分にだけ焦点を当てることで省メモリでありながら高い精度を実現しています。
PyramidNetはChannel増加部分にだけではなくresidual部分も計算することで、CIFAR-10でDenseNetに匹敵し、CIFAR-100に至ってはDenseNetを1%程度上回る高い精度を実現しており、提案時点でState-of-the-artな手法となっていました。
しかし,PyramidNetは深くなればなるほどDenseNetよりもメモリが厳しくなってしまうという課題を抱えています。
それぞれのネットワークを構成するユニットにおけるchannelをn、Channelを増加分をとしたとき、DenseNetはn→aの畳み込みを扱えば良いのに対して、PyramidNetはn→(n+a)の畳み込みを扱わなければならないためです。
一方でPyramidNetはその110層の中で最初と最後を除く108層もの間でResidual Functionを計算し続けるため、その中には余分な畳み込みが含まれていると考えられます。
余分な畳み込みを計算しなければ精度を維持しながらメモリ増加を抑えることが出来ると考えられます。
そこで層が深まるについて畳み込みを行うChannelを徐々にスライドさせていくことで畳み込み計算をしないChannelを作れば、PyramidNetと同程度の精度を維持しながらPyramidNetよりもメモリ増加を抑えることが出来ると考え実験を行いました。
そして、見事に散りました。
この実験の欠点はパラメータの検討範囲が広すぎるということです。
どの程度スライドすれば良いのか、どの程度Channelを増加させていけば良いのか、スライドする固定Channelの畳み込みの設定をどうするのか、層数をどうするのか、学習率は、と考えるととても研究室レベルで行える実験ではありませんでした。
PyramidNetにやや劣る精度こそ出せたものの、ResNeXtやDenseNet-BCなどそれぞれの改良法も進んだことで、この実験もお蔵入りとなってしまいました。
教訓: できる範囲のことで勝負を挑もう。
おわりに
本記事では私が遭遇した3つの失敗実験を取り上げました。
本年はここに書けないくらい恥ずかしいドジから、もしかしたらちゃんとした研究に繋がるかもしれないものまで、大小様々な失敗を繰り返しました。
一方でローソンの売上予測で日本4位になったりと、大小様々な成功も経験しました。
そうした全てをひっくるめて2016年はとても充実した一年だったのではないかと思います。
そんな中でも世界は恐ろしいスピードで目まぐるしく変化しています。
深層学習に関する研究もこの1年だけでも急激に進んでおり、専門分野の画像認識に関する研究を追いかけるだけでも精一杯というのが苦しい本音です。
また、理論面のみに限らずソフトウェアやハードウェア環境の進化も目覚ましく、D-Waveやコヒーレント・イジングマシンといった次世代計算機に関する研究の融合も進んでいます。
理論、ソフト、ハードが融合した同時多発的なブレイクスルーが近々到来することは想像に難くないでしょう。
果たして2017年の深層学習はどのようなものになっているのでしょうか。
そしてこんなことばかりしてる実験馬鹿に彼女が出来る日が来るのでしょうか。
私自身も微力ながら2017年を少しでも良い年にできるように、頑張っていく所存です。
そして来年も多分彼女は出来ないのでこのような場で何か発表できたらなと考えています。
最後まで読んでいただき、ありがとうございます。