#はじめに
皆さんは画像分類、してますか?

代表的なグランドチャレンジの1つであるILSVRCが2017年を以って終了し、
何だかちょっぴり元気がなくなった気がする2018年画像分類界隈、いかがお過ごしでしょうか。
え、僕ですか? が、頑張っては居ます…。
しかし、グランドチャレンジが一区切りを迎えたとはいえ、
画像の分類にはまだまだ未解決の問題が山積しています。
未解決の問題の1つがスモールデータでの学習です。
画像分類の分類精度の向上には膨大な枚数の正解付きの画像が必要ですが、
ImageNetのように**『数百万枚の画像に正解を付ける』**というのは現実的ではありません。
少枚数の正解付きの画像をうまく活用し、分類精度の高いモデルを作ることは、実応用上で不可欠と言えます。
多くの場合は外部データを用いることで解決を図っています。
特に巨大なデータセットからの転移学習や、半教師あり学習は一定の成功を納めています。
ただし外部データの利用には著作権や高い計算コスト等の障害があり、
外部データを用いない場合、スモールデータでの学習は依然として厳しいのが実情です。
さて、そんなスモールデータでの学習なのですが、ここで一つの疑問が浮かび上がります。
そもそも外部データを用いない場合、最新技術でどの程度の分類精度を達成できるのでしょうか。
実は包括的な比較は未だ存在せず、スモールデータでの学習が実際どの程度難しいのかは不透明のままなのです。
本記事ではその疑問に答えるべく、たった1000枚で画像分類を学習する新タスクに対して、
とある学生(@imenurok)が遊んで、学んで、取り組んだ記録をお送りします。
本記事を通して、ご覧の皆様が何かしら糧となるものを得られれば幸いです。
#0. Train with 1000
最近、学習データ数が1,000くらいのスモールデータの深層学習に興味を持っているところです。学習データが1,000しかないと、mnistやcifar10, cifar100などの性能はどれくらいかなということで、ホームページを作成してみました。
— Masayuki Tanaka (@likesilkto) November 14, 2018
ぜひ、結果をsubmitしてみてください。https://t.co/vHCUbDrxQn
Train with 1000は東京工業大学の田中先生から今年提案された、
たった1000枚で画像分類モデルを学習した際の分類精度を比較するタスクです。
(詳細はプロジェクトページを御覧ください)
『1000枚』と言うと多いと感じるかもしれませんが、
標準的なデータセットであるImageNet、MNIST、CIFAR-10/100と比較すると圧倒的に少規模です。
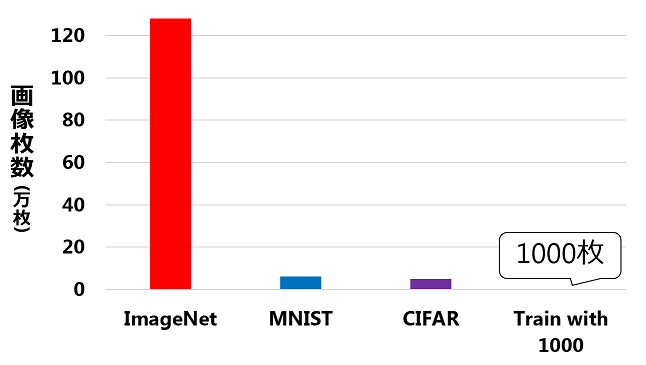
<図1. 主要な画像分類データセットImageNet、MNIST、CIFAR-10/100とTrain with 1000の学習画像枚数の比較>
Train with 1000はMNIST、CIFAR-10/100の三種類存在しますが、本記事ではCIFAR-10を対象としています。
CIFAR-10は、既に人間のスコアを大幅に上回り99%の分類精度が報告されているデータセットではありますが、
本来の1/50の規模でしか学習できない今回の場合、分類精度が低下し人間のスコアを下回ることが予想されます。
従って、Train with 1000は非常に挑戦的なタスクと言えます。
一方で1/50の規模でしか学習できないということは、
1/50の学習コストで様々な検証が行える、非常に低コストなタスクということでもあり、
スモールデータの状況を踏まえると、挑戦的で、かつ非常に有益なタスクと言えます。
(完璧に部外者なので、好き勝手にメチャクチャ褒められる、素敵!)
以下では、どのように分類精度を向上させたのかについて順を追って説明します。
#1. <ベースライン> PyramidNet-SD (64.5%)
下記は『論文として報告されているCIFAR-10の分類精度』を,自分の知る限り高い順に列挙したものです。
(2018年12月25日現在/間違いがあったらこっそり教えて下さい)
<表1. CIFAR-10の分類精度一覧>
| 名前 | モデル | 分類精度 | 備考 |
|---|---|---|---|
| GPipe | AmoebaNet-B (6,512) | 99.0% | 転移学習 |
| ARS-Aug | PyramidNet-SD | 98.7% | |
| AutoAugment | PyramidNet-SD | 98.5% | |
| ARS-Aug | AmoebaNet-B (6,128) | 98.5% | |
| ARS-Aug | Shake-Shake 2*112d | 98.4% | |
| ARS-Aug | Shake-Shake 2*96d | 98.3% | |
| AutoAugment | AmoebaNet-B (6,128) | 98.2% | |
| 森下らの手法 | ResidualDenseNet-SD | 98.1% | |
| AutoAugment | Shake-Shake 2*112d | 98.1% | |
| AutoAugment | Shake-Shake 2*96d | 98.0% |
参考: GPipe、ARS-Aug、AutoAugment、森下らの手法
ただし、最も優れているGPipeはImageNetの学習済みモデルを利用するため、Train with 1000の条件から外れます。
GPipeを除くと、ARS-AugとAutoAugmentの双方でPyramidNet-SDが現時点で最も優れたモデルとなります。
従って、Train with 1000において現時点で最高水準の分類精度を達成しうるモデルはPyramidNet-SDと言えます。
(後記で言及しますが、実際は一応更に優れたモデルが提案されています。じ、実装できなかったんや…。)
実際にTrain with 1000に対してPyramidNet-SDを利用した所、**分類精度は64.5%**を達成しました。
本実験ではPyramidNet-SDをベースラインとし、更に認識精度を改善しうる手法について検討を行いました。
#2. +AutoAugment (75.3%)
何とかベースラインを伸ばせないかと画像分類モデルの改善に悪戦苦闘していた所、
研究活動や学会業務、そして即日論文実装をこなしつつ、同人活動する行動力の化身であり、
画像研究Slackの主催で積極的に国際学会に投稿する画像研究ガチ勢、ひっつ氏からアドバイスを頂戴しました。
しょぼいモデルから大きめのモデルまで試してみましたけど1000枚だとモデルの差よりaugmentationの差のほうがでかそうという印象はあります(ResNet20でも70%以上は出る)
— ひっつ@C95日曜ヨ31b (@HITStales) November 27, 2018
そこでモデルの改善をひとまず諦め、データ増強に焦点を当てることとしました。
データ増強で注目したのが、表1にも存在するAutoAugmentです。
AutoAugmentは、3溝(10の32乗)ものデータ増強手法の組み合わせの中から、
validation dataの分類精度を向上させうるデータ増強手法の組み合わせを強化学習で探索する手法です。

<図2. AutoAugmentで得られた組み合わせをImageNetに対して適応した際のデータ増強の例>
探索の結果得られるデータ増強手法は相応に強力であり、CIFAR-10の実験では、
分類精度が既に96%を上回る全ての手法で1%程度もの大幅な分類精度の改善に成功しています。
(これははっきり言って異常な程の改善です)
既にCIFAR-10における探索結果が提供されているため、本実験ではこの探索結果をそのまま利用しました。
これは表1におけるAutoAugment(PyramidNet+SD)相当であり、この時点で最先端の手法を適応していることになります。
その結果、**分類精度は75.3%を達成し、ベースラインから10.8%**の改善を達成しました。
#3. +BC-Learning (77.7%)
更にAutoAugmentでは検討されていなかったBC-Learningを導入することで、精度の向上を図りました。
同様の手法であるmixup、及びBC-Learningは、
乱数に基づいて二つの画像と対応するラベルを混ぜあわせるデータ増強手法です。
これはデータセットの各データ間について線形補間を行い、線形補間された部分も学習に含めることに相当し、
データセットをより巨大なデータセットとして擬似的に扱うことになります。
これは膨大な枚数の学習が上手くいくのと同様に、分類精度の向上が期待できます。
(実際に、mixupとBC-Learningはどちらも広範な実験で、精度の向上が確認されています。)
これらはarxiv上で僅か1日違いで提案された手法であり、先に提案されたmixupがよく利用されます。
僕は乱数を決めるのにベータ分布を使うmixupより、一様分布を使うBC-Learningが好きです。
BC-Learningを導入によって、**分類精度は77.7%を達成し、ベースラインから13.2%**の改善を達成しました。
#4. +α (78.4%)
最後に、現在絶賛研究中の手法をブチ込みました。
こちらはAutoAugmentの分類精度を上回るために開発した手法で、
各種ベースラインを0.1%~1%程度上回ることをCIFAR-10/CIFAR-100で確認しています。
最終的に、この手法によって**分類精度は78.4%を達成し、ベースラインから13.9%**の改善を達成しました。
こちらは近日なにかしらの形で公開すると思うので、
ここでは更に分類精度を向上させる手法があるとだけ言及しておきます。
(公開後に追記するかもしれません)
まとめ
挑戦的で、かつ非常に有益なタスクであるTrain with 1000に取り組む中で、
参考記録(下記参照)ではありますが、実際にたった1000枚の学習で分類精度78.4%を達成することが出来ました。
しかし同時に、CIFAR-10における最先端の手法の数々を組み合わせ、
例え未発表の手法まで盛り込んで、その中で最善の学習をしたとしても、
現時点では本来の分類精度である99%や人間のスコアである94%に及ばないことが明らかになりました。無念。
これはTrain with 1000というタスクの困難さとその意義を示す結果であり、
学習画像枚数が1/50になることで、分類精度が20%近くも低下してしまうということは、
今後の画像分類におけるスモールデータでの学習における、1つの基準になるものだと考えています。
ここからいかにして、更に分類精度を改善することができるのか。
今後の画像分類とその発展も、目が離せないものになっていくと考えています。
なお、以下の部分はオマケです。本記事に関する注意や学習条件や更なる改善のアイデアを書いてあります。
Train with 1000にチャレンジする方は、参考にしたりしなかったりしてみてください。
本年は今年の漢字「災」が象徴するかのように、激動の年でした。
それは震災や豪雨、台風や猛暑、そして大小様々な社会的事象が齎した「災い」に留まらず、
複数の革命的な大規模手法が提案された、画像処理の分野においても同様だったのではないかと思います。
(かくいう自分自身、研究内容の軌道修正が迫られてるのでね…)
その中で、本記事が実践的な理解や新たな研究への着手をする上で何某か、皆様の支えになれば幸いです。
末筆ですが、本記事を御覧になっていただき、心から本当に有難うございます!
この記事をご覧の、腕に覚えがある方は是非Train with 1000にチャレンジして僕の無念を晴らして下さい!
#(注意)
AutoAugmentのCIFAR-10における探索はTrain with 1000の範疇を越えたデータで探索しているため、
データ増強かデータ生成かの判断次第で、プロジェクトページ中の下記の条件に引っかかる可能性があります。
Data augmentations are OK.
Data generations are OK. But the data generator should be also trained with 1,000 samples.
従って本実験の結果は公的な結果ではなく、あくまでTrain with 1000のCIFAR-10における参考記録となります。
頑張れば、まぁこんくらい分類精度を出せるんやなぁ程度に御留意ください。
(各種学習条件)
基本的には下記の条件で学習を行いました。
ただし、データ増強は適宜AutoAugment等に変更しています。
データ増強: Random Crop + Horizontal Flip + Cutout
Epoch: 1800
Learning Rate: 0.1 (Cosine Annealing)
Weight Decay: 0.0001
各種Ensemble: なし
特に各種EnsembleについてはTrain with 1000のプロジェクトページで許可されています。
Ensemble is OK. But each network should be trained with 1,000 samples.
手始めに78.4%を越えるなら、まず狙い目はEnsembleの適用だと思います。
#(上手くいかなかった手法 / 上手くいくかもしれない手法)
##1. 上手くいかなかった手法
###・(単純な)AutoAugment+BC-Learning
AutoAugmentにBC-Learningを組み合わせる際に、
連鎖的なデータ増強処理中のどのタイミングでBC-Learningのmixを行うかによって、
最終的な分類精度が変化するという現象を確認しました。
具体的にはHorizontal Flipの後、Cutoutの前にmixしないと、分類精度が2%程度下がりました。
通常のCIFARでは、BC-Learningのタイミングでの精度の変化を確認出来なかったので、
この現象に関しては偶々なのか、意味があるのか、完璧に謎です。賢い人、誰か教えて下さい。
###・ARS-Aug
ARS-Augは、転移学習を除いて現時点のCIFAR-10/100において最も高い分類精度を達成した手法です。
AutoAugmentをベースにした効果的なデータ増強を提案しており、CIFAR-10/100で有効なことを確認しています。
しかし、AutoAugmentと同様CIFAR-10での探索結果を用いた所、
Train with 1000ではこの増強方法はAutoAugmentの精度を若干下回る結果となりました。
「データの傾向が変われば、適したデータ増強手法も変わる」とのAutoAugmentにおける言及を踏まえると、
Train with 1000ではデータの傾向が変わり、有効でなくなったことが予想されます。
###・+β
こちらも前述のαと同じく現在絶賛研究中の手法です。
特にこのβはCIFAR-10/100でαを僅かに上回ることを確認しており、78.4%を超えることが期待されました。
しかし、Train with 1000では、前述の78.4%を上回る改善を達成することが出来ませんでした。
こちらも近日なにかしらの形で公開すると思うので、ここでは言及だけしておきます。
(公開後に追記するかもしれません)
##2. 上手くいくかもしれない手法
###・Aki.氏のデータ増強
画像データ分析コンペティションでは常に僕を上回ってた絶対に勝てない勢の一人で
画像データ分析のプロフェッショナルであるAki.氏によると、AutoAugmentはそこまで有効でないそうです。
「お手製手作りaugment >= AutoAugment >>>>> albumentationsにある機能だけで作り直してみたやつ」という感じでうまく行かなくて首を傾げている。
— aki. (@ak11) December 6, 2018
更に上の分類精度を目指すのであれば、こっそり教えてもらうと良いかもしれません。
###・ResidualDenseNet-SD
単体でPyramidNet+SDを上回る手法です。
ResNetの残差構造にDenseNetライクな構造を組み込むことによって、多層かつ効率的なモデル設計を実現しています。
転移学習や特別なデータ増強等の手法なしに唯一、表1の最高分類精度競争に名を刻む手法です。
一般に画像分類モデルはパラメータ数が多いほど高い分類精度を達成しやすいのですが、
ただ分類精度を改善するだけでなく、PyramidNet-SDと比較して半分程度のパラメータ数で達成しています。
改善するだけでも大変なのに、パラメータ数も削減しちゃう、日本が誇るヤベーやつ森下兄貴。
上手く再現できなかった実装が公開されてなかったため、今回は検証対象としませんでした。
###・ProxylessNAS
こちらも単体でPyramidNet+SDを上回る手法です。
データセットに対して最適なモデル構造を探索する手法の1つで、強化学習/勾配計算で構造を探索します。
高精度なだけでなく、ResidualDenseNet-SDと比較しても圧倒的に低パラメータであり、極めて有望な手法の一つです。
力量不足で実装できなかった実装が公開されてなかったため、今回は検証対象としませんでした。
###・AmoebaNet
ProxylessNASに準じるものの、単体でPyramidNet+SDを上回る手法です。
データセットに対して最適なモデル構造を探索する手法の1つで、進化型計算で構造を探索します。
ただしAutoAugmentではPyramidNet+SDを下回る(表1参照)ため、今回は検証対象としませんでした。
###・Train with 1000における各種探索系手法の学習
今回の実験で用いたAutoAugment、Augmented Random Searchは
本来の用途である探索は一切行わず、CIFAR-10での探索結果をそのまま利用しています。
これではTrain with 1000内でのデータが考慮されておらず、有効なデータ増強が行えていないかもしれません。
Train with 1000を用いて、AutoAugment等の探索手法で有効なデータ増強を発見することは、
更なる分類精度の改善に寄与する可能性があります。
同様にProxylessNAS等の探索手法で有効な構造を発見することで、更にその上の精度を目指せるかもしれません。