前置き
今回はPowerQueryの超超ちょ~基本的なことを書きます。
M言語の解説なんか書いても普通のPowerBIユーザには専門的過ぎて需要がないようなので、誰にでも役立ちそうな基本的な内容です。
基本的なことなのでこれまでにも誰かが書いてると思うんですが、ちょっと探しても見当たらなかったので、自分が書いたほうが速いなと。
やりたいこと
前置きはそのくらいにして、今回やりたいことを説明しましょう。
こんな感じの質問がありまして
単一のExcelのファイルからテーブルを読み込んで、そこからメジャー作成やレポーティングなどしてたのですが
やはり単一のExcelファイルではなく、特定のフォルダに置いた複数のExcelファイルから読み込む方法にやり直したいです。
クエリの編集で何とかならないでしょうか。
途中まで作りこんじゃったけど、後になってクエリを大幅に書き換えたい、ってことはまぁある話ですよね。あんまりいいことではないかもだけど。
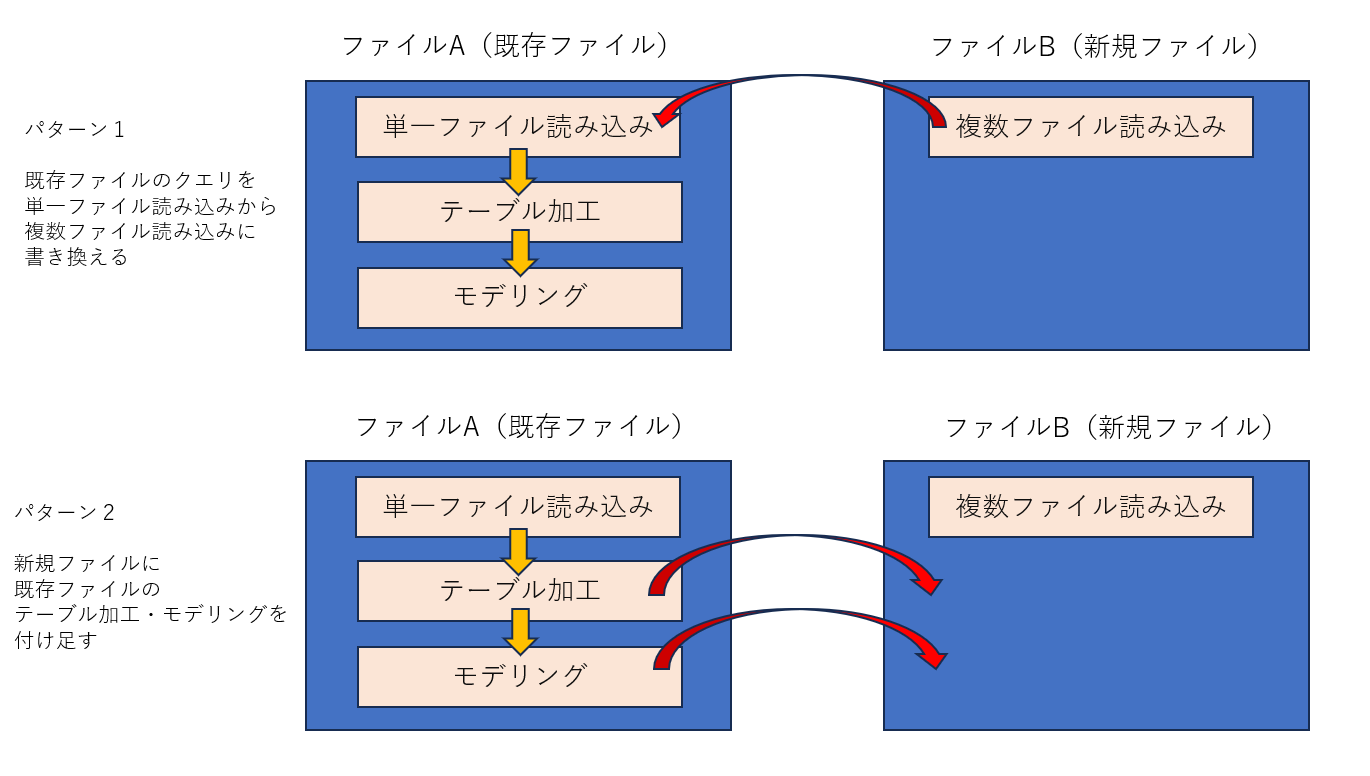
まず、これを実現するためには、次の2つの方法が考えられると思います。
パターン1.既存ファイルのクエリを編集して、単一ファイル読み込みから複数ファイル読み込み(フォルダ読み込み)に変更する方法
パターン2.新規ファイルを作って複数ファイル読み込み(フォルダ読み込み)のクエリを作り、そこに既存ファイルのテーブル加工部分やモデリング(メジャー作成・ビジュアライズ)を持っていく
図にするとこうです。
今回はパターン1の方法を説明します。
実演するために、こんなサンプルを用意しました。
サンプルデータ(単一ファイル)

サンプルデータ(複数ファイル)
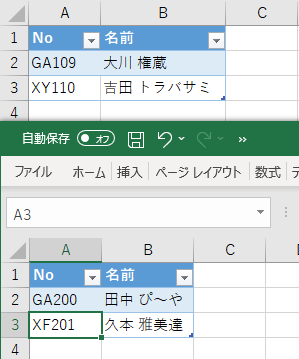
(いろいろ雑というツッコミがありそうだけど許して)
このサンプルで、単一ファイルのほうのデータを読み込んで、クエリ編集後の結果、次の通りになっていたとします。
クエリ最終結果
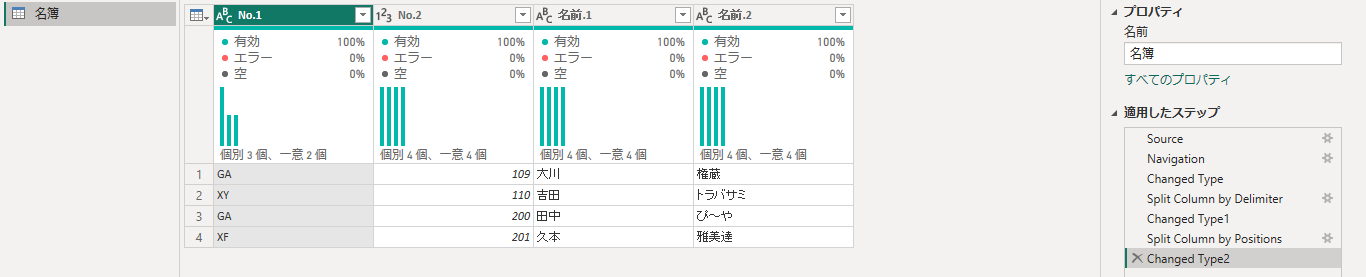
現状は単一ファイルのデータから読み込んでいますが、これを複数ファイルのほうから読み込んで、同じ結果になるようにしたい、というのが今回のやりたいことというわけです。
さっきの図で言うところの、ファイルA(既存ファイル)のクエリがこれに当たります。
フォルダからの複数ファイルの読み込み
パターン1でやるということなので、複数ファイル読み込みのクエリを新規に作る必要があります。ファイルBですね。
まずはフォルダから複数ファイルを読み込むとどうなるかを確認しましょう。
特定のフォルダを作り、そのフォルダに先ほどの複数ファイルを格納します。
(フォルダ名はdata、ファイル名はそれぞれdata1.xlsxとdata2.xlsxとしてます、テキトーです)
早速読み込んでみます。
データの取得でフォルダを選択して
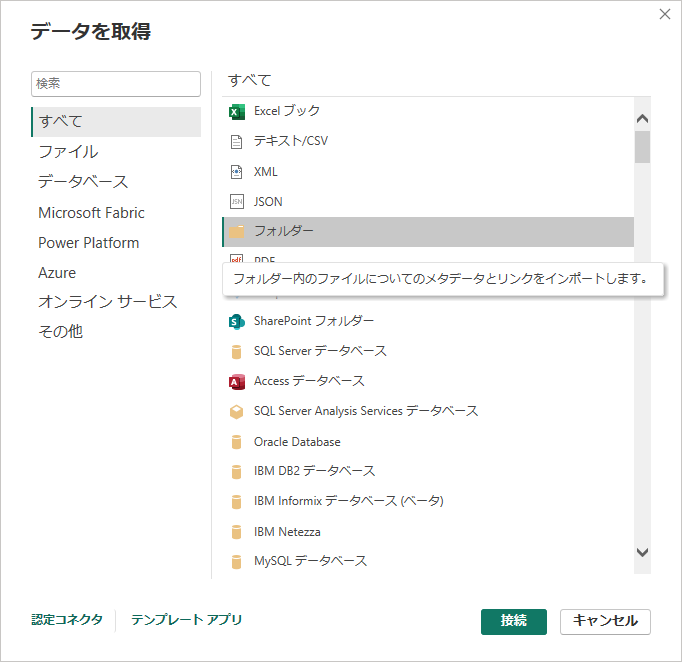
データを取得したいフォルダパスを入れます。さっきのdataフォルダです。

クエリを編集したいので、データの変換をクリックします。

するとこの画面になります。ここで一番左に Content という列があるので、その列の右側にある下向きの矢印ボタンを押します。(カーソルを合わせると「ファイルの結合」というポップアップが出ます)

押すとこの画面。Excelブックからどのテーブル(もしくはどのシート)を読み込みたいかを選びます。選んだらOKをクリック。
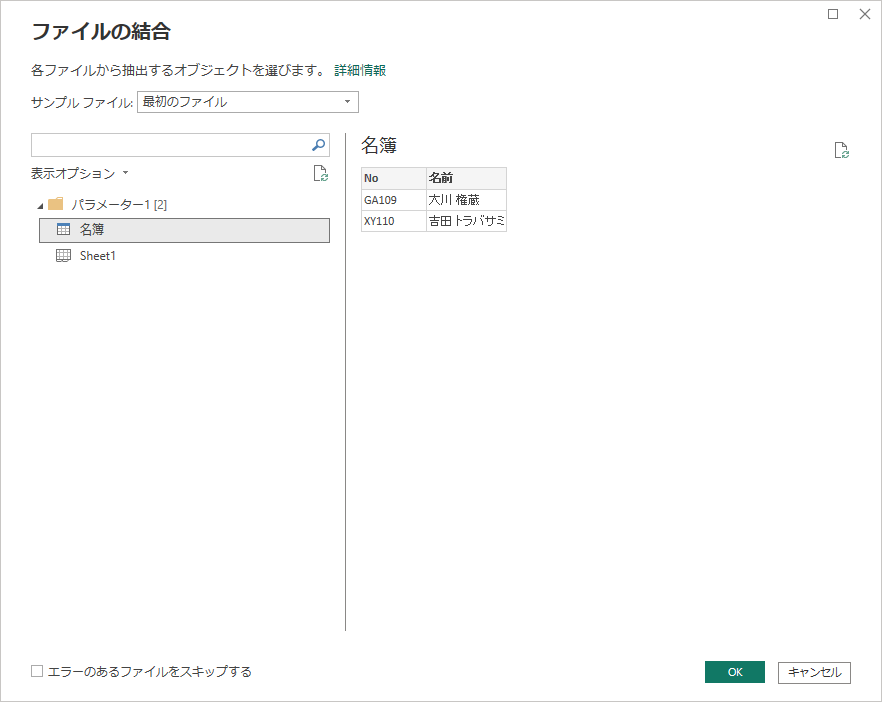
するとこの画面。ヘルパークエリが作られて、いっきにクエリが増えました。
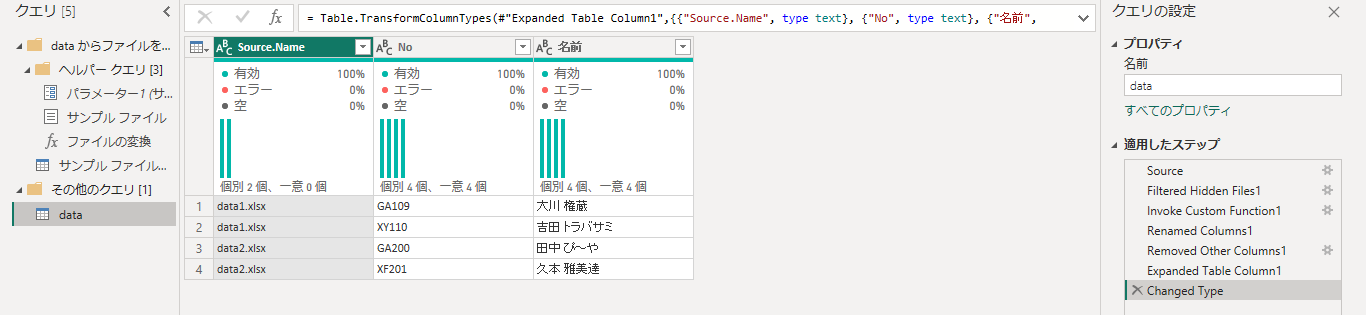
一番左の Source.Name という列(ファイル名)が邪魔ですね。列を消したいのですが、最後のステップで Source.Name 列の型変換が発生しているので、まず型変換のステップを消して、列削除のステップを追加してから、再度、型変換します。(Mコードを編集できる人はそのほうが楽です)
説明が面倒くさいので詳しい説明は省きます。
最終、こうなります。
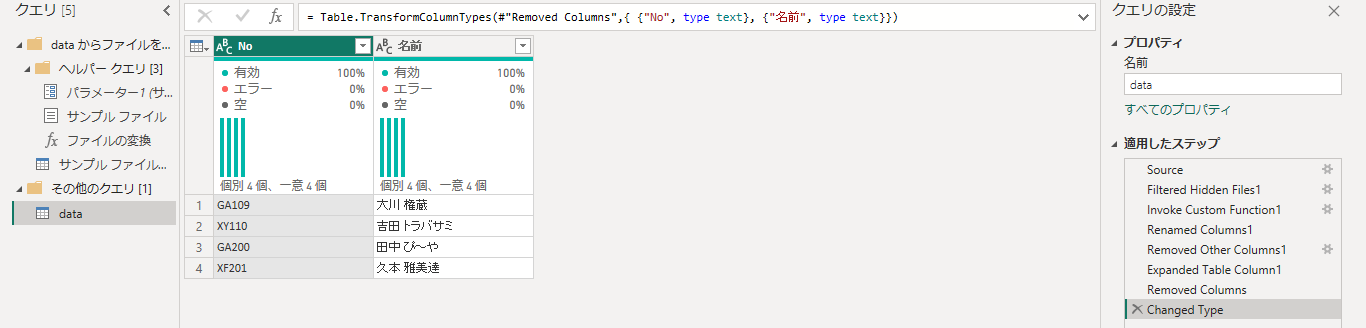
ちなみに詳細エディタでは下記の通り。
let
Source = Folder.Files("[パス省略]\PowerBI\ファイル分割\data"),
#"Filtered Hidden Files1" = Table.SelectRows(Source, each [Attributes]?[Hidden]? <> true),
#"Invoke Custom Function1" = Table.AddColumn(#"Filtered Hidden Files1", "ファイルの変換", each ファイルの変換([Content])),
#"Renamed Columns1" = Table.RenameColumns(#"Invoke Custom Function1", {"Name", "Source.Name"}),
#"Removed Other Columns1" = Table.SelectColumns(#"Renamed Columns1", {"Source.Name", "ファイルの変換"}),
#"Expanded Table Column1" = Table.ExpandTableColumn(#"Removed Other Columns1", "ファイルの変換", Table.ColumnNames(ファイルの変換(#"サンプル ファイル"))),
#"Removed Columns" = Table.RemoveColumns(#"Expanded Table Column1",{"Source.Name"}),
#"Changed Type" = Table.TransformColumnTypes(#"Removed Columns",{ {"No", type text}, {"名前", type text}})
in
#"Changed Type"
既存ファイルにクエリを貼り付ける
さぁ、いよいよ、もともと作っていたファイルのクエリを、今新しく作ったクエリに置き換えます。
まず、単一ファイルのほうのクエリ結果をもう一度見ておきましょう。今回はこんな感じのクエリになっています。
単一ファイルからのクエリ再掲
これの詳細エディタは次の通り。
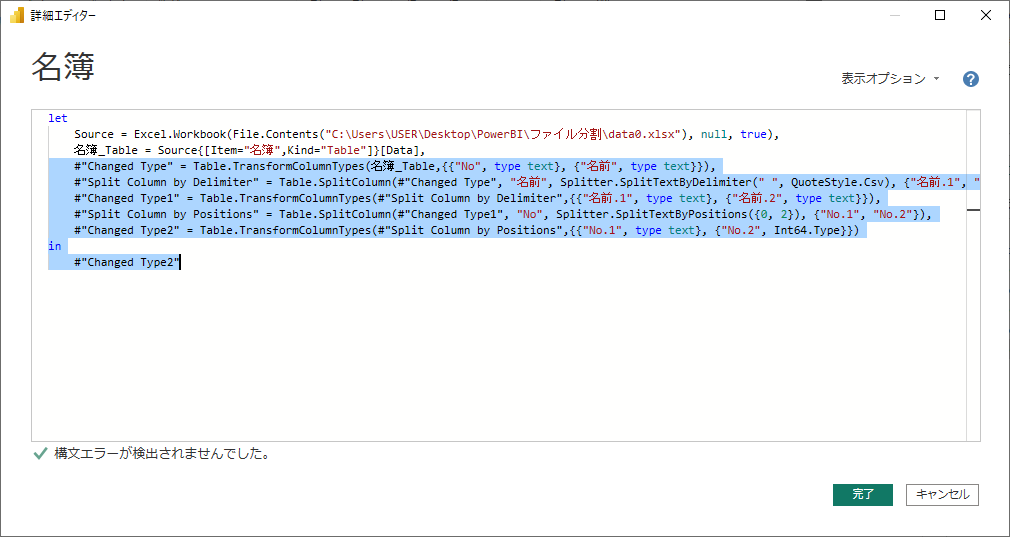
let
Source = Excel.Workbook(File.Contents("[パスは省略]\PowerBI\ファイル分割\data0.xlsx"), null, true),
名簿_Table = Source{[Item="名簿",Kind="Table"]}[Data],
#"Changed Type" = Table.TransformColumnTypes(名簿_Table,{{"No", type text}, {"名前", type text}}),
#"Split Column by Delimiter" = Table.SplitColumn(#"Changed Type", "名前", Splitter.SplitTextByDelimiter(" ", QuoteStyle.Csv), {"名前.1", "名前.2"}),
#"Changed Type1" = Table.TransformColumnTypes(#"Split Column by Delimiter",{{"名前.1", type text}, {"名前.2", type text}}),
#"Split Column by Positions" = Table.SplitColumn(#"Changed Type1", "No", Splitter.SplitTextByPositions({0, 2}), {"No.1", "No.2"}),
#"Changed Type2" = Table.TransformColumnTypes(#"Split Column by Positions",{{"No.1", type text}, {"No.2", Int64.Type}})
in
#"Changed Type2"
このクエリの1~3行目が、単一ファイル読み込みのクエリ部分です。この部分を、さっき作った複数ファイル読み込みのクエリで置き換えたい。
…のですが、その前にヘルパークエリを持ってくる必要があります。
先ほど作ったフォルダ読み込みのほうのクエリで、クエリペインの「ヘルパークエリ」というグループを右クリックしてコピー(もしくはCtrl+Cでも可)します。
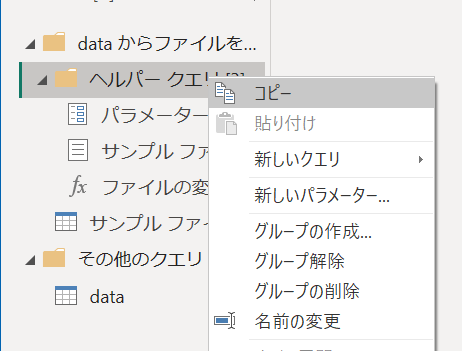
コピーできたら、既存ファイルのほうのクエリペイン(PowerQueryエディタの一番左側のとこね)で右クリックして貼り付け(もしくはCtrl+Vでも可)します。
貼り付けた結果がこう。
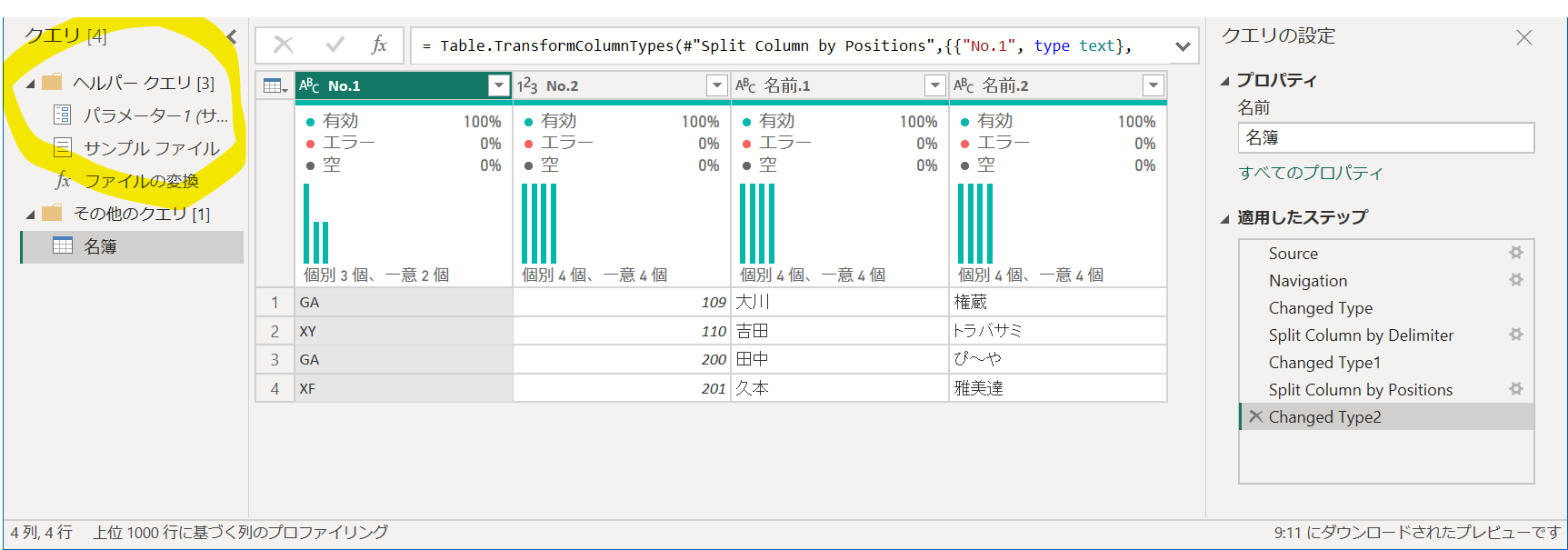
ヘルパークエリを貼り付けできたら、先ほど作った複数ファイル読み込みのクエリの詳細エディタで、コードの下2行以外(inの直前まで)をコピーします。
既存ファイルのクエリの単一ファイル読み込み部分は、上から4行目(#"Changed Type"ステップ)までなので、上から4行目までを削除し、代わりに先ほどコピーした複数ファイル読み込みのコードを次の通り貼り付けます。貼り付けると、次のように怒られます(笑)。
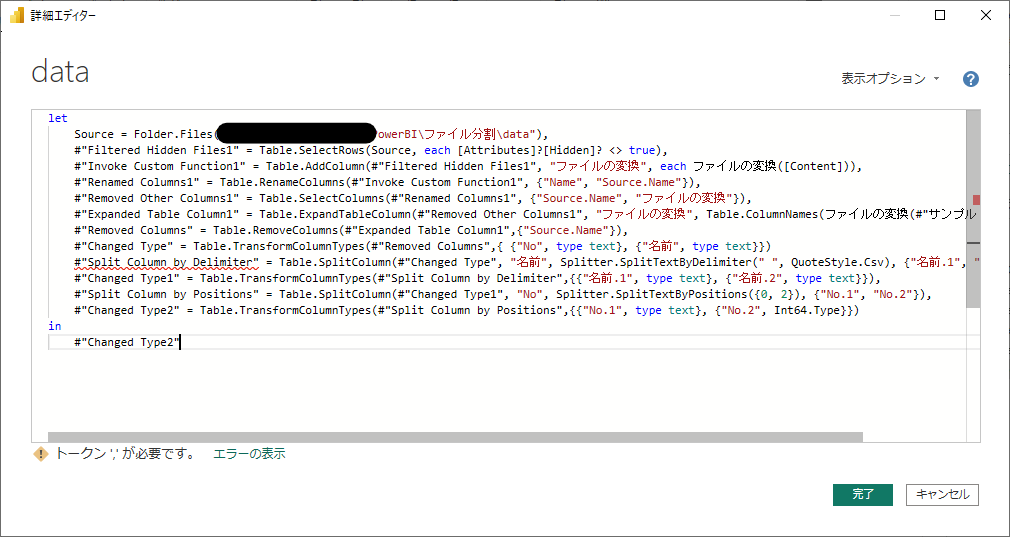
詳細エディタではステップをカンマで区切って繋がないといけないですが、#"Split Column by Delimiter"の前にカンマがないので怒られています。なので、カンマを追加します。すると怒られなくなります。
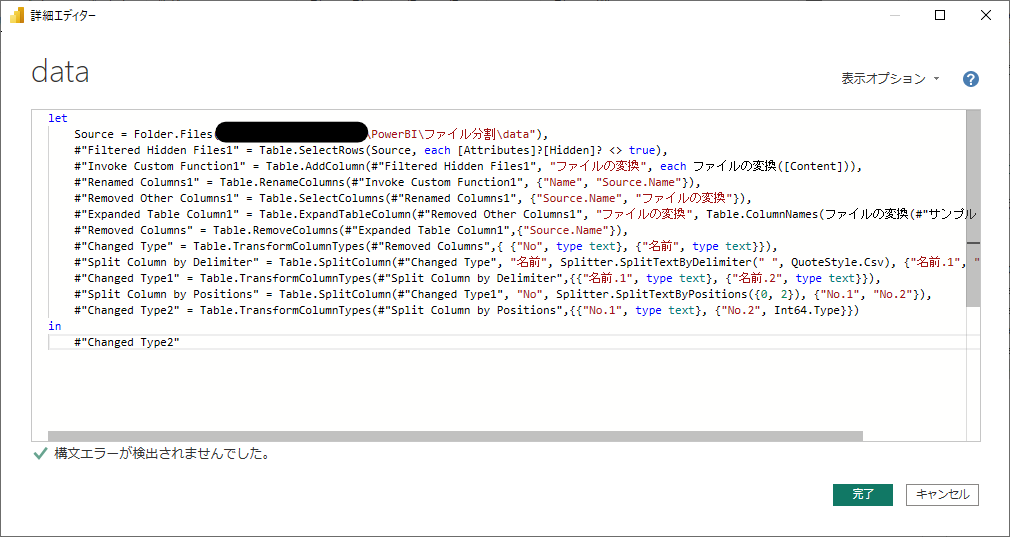
この時点で、詳細エディタでは次の通り。
let
Source = Folder.Files("[パスは省略]\PowerBI\ファイル分割\data"),
#"Filtered Hidden Files1" = Table.SelectRows(Source, each [Attributes]?[Hidden]? <> true),
#"Invoke Custom Function1" = Table.AddColumn(#"Filtered Hidden Files1", "ファイルの変換", each ファイルの変換([Content])),
#"Renamed Columns1" = Table.RenameColumns(#"Invoke Custom Function1", {"Name", "Source.Name"}),
#"Removed Other Columns1" = Table.SelectColumns(#"Renamed Columns1", {"Source.Name", "ファイルの変換"}),
#"Expanded Table Column1" = Table.ExpandTableColumn(#"Removed Other Columns1", "ファイルの変換", Table.ColumnNames(ファイルの変換(#"サンプル ファイル"))),
#"Removed Columns" = Table.RemoveColumns(#"Expanded Table Column1",{"Source.Name"}),
#"Changed Type" = Table.TransformColumnTypes(#"Removed Columns",{ {"No", type text}, {"名前", type text}}),
#"Split Column by Delimiter" = Table.SplitColumn(#"Changed Type", "名前", Splitter.SplitTextByDelimiter(" ", QuoteStyle.Csv), {"名前.1", "名前.2"}),
#"Changed Type1" = Table.TransformColumnTypes(#"Split Column by Delimiter",{{"名前.1", type text}, {"名前.2", type text}}),
#"Split Column by Positions" = Table.SplitColumn(#"Changed Type1", "No", Splitter.SplitTextByPositions({0, 2}), {"No.1", "No.2"}),
#"Changed Type2" = Table.TransformColumnTypes(#"Split Column by Positions",{{"No.1", type text}, {"No.2", Int64.Type}})
in
#"Changed Type2"
完了して詳細エディタを閉じると、こう。
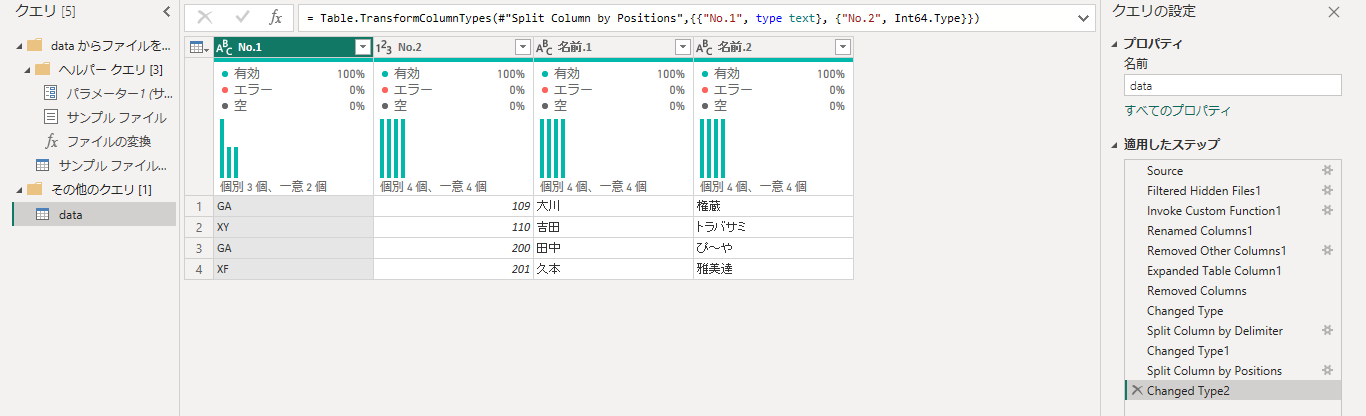
できた~
注意点
面倒くさいので説明してませんでしが、注意点を箇条書きします。
- クエリを貼り付けるときはステップ名に注意。(M言語のルールを満たすようにしようね、M言語のルールはここでは説明しないけど)
- 当然ですが、単一ファイルから読み込もうが複数ファイルから読み込もうが、テーブルの構造は変わってはいけない。Source.Name列を削除したのは見た目を整えるためだけじゃなく、テーブルの構造を一致させるためにも必要なこと。