はじめに
Priority Encoder とは、あるビット列が与えられて、そのビット列をLSB(またはMSB)から探索して最初に1だったところを見つけます。見つかった位置を数字(Binary Integer)で返すものを Priority Encoder と言います。
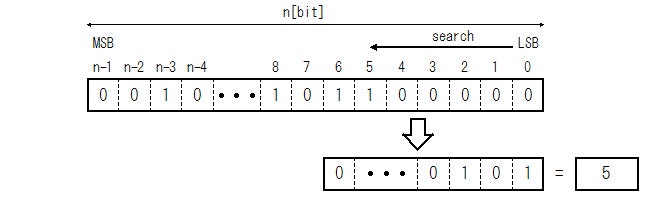
Fig.1 Priority (Binary Integer) Encoder
また、数字で返さずに、入力されたビット列のうち、最初に1だったところのみ1にして後は全部0にして返す場合(One Hot)もあります。
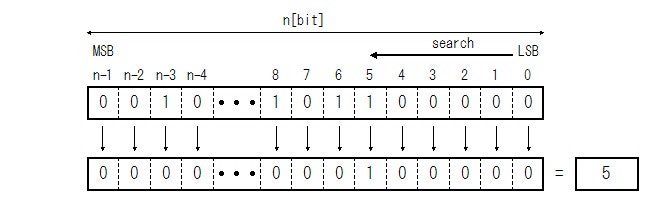
Fig.2 Priority (One Hot) Encoder
この記事では、このPriority (One Hot) Encoder のビット列の大きさが Generic 変数で与えられた1ビット〜1024ビット超の可変値とした時のVHDL の記述方法と、それを論理合成した時の結果を示します。
ライセンス
二条項BSDライセンス (2-clause BSD license) で公開しています。
Algorithm
1. For-loop with exit
VHDL の For-loop は exit 文でループを脱出することが出来ます。これを使って記述する方法です。
procedure Priority_Encode_To_OneHot_Use_Exit(
Data : in std_logic_vector;
variable Output : out std_logic_vector;
variable Valid : out std_logic
) is
variable result : std_logic_vector(Data'range);
begin
result := (others => '0');
for i in Data'low to Data'high loop
result(i) := Data(i);
exit when (Data(i) = '1');
end loop;
Output := result;
Valid := or_reduce(Data);
end procedure;
こんなの論理合成出来るの? という疑問もありますが、意外と出来たりします。ただ、STARC の 『RTL 設計スタイルガイド』では「for-loop 文内で exit,next は使用しない」のが必須になっています。理由は論理合成ツールが生成するRTLのイメージが掴みにくいからですが、実はその通りで、論理合成ツールによって生成する回路が異なります。入力データのビット数が数ビットの場合は、この記述方法でも特に問題ありませんが、数十ビット以上になると論理合成ツールの出来次第みたいなところがあるので使用には注意が必要です。
2. For-loop with found flag
フラグを使って値を生成する方法です。found_1 フラグは false に初期化しておき、ループを使って入力データを探索し、最初に1を見つけたら found_1 フラグをセットしてそれ以降は全て0にします。
procedure Priority_Encode_To_OneHot_Use_Flag(
Data : in std_logic_vector;
variable Output : out std_logic_vector;
variable Valid : out std_logic
) is
variable result : std_logic_vector(Data'range);
variable found_1 : boolean;
begin
found_1 := false;
for i in Data'low to Data'high loop
if found_1 = false then
result(i) := Data(i);
found_1 := (Data(i) = '1');
else
result(i) := '0';
end if;
end loop;
Output := result;
Valid := or_reduce(Data);
end procedure;
3. For-loop with or-reduce
出力するビット列の個々のビットの立場になって、自分のビットに1が立つ条件を考えてみると、それは次の二つの条件を満たした場合であることが判ります。
- 入力データの自分と同じ位置にあるビットが1の場合
- 入力データの自分より前の位置のビットが全て0の場合
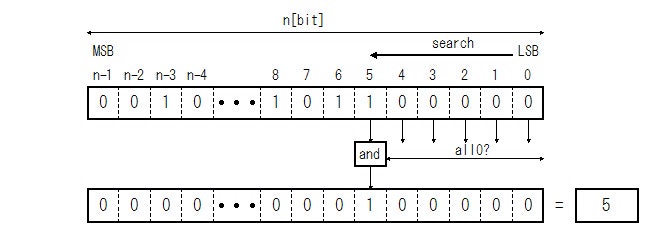
Fig.3 For-loop with or-reduce
上の条件通りに VHDL を記述すると次のようになります。
procedure Priority_Encode_To_OneHot_Use_OrReduce(
Data : in std_logic_vector;
variable Output : out std_logic_vector;
variable Valid : out std_logic
) is
variable result : std_logic_vector(Data'range);
begin
for i in Data'range loop
if (i = Data'low) then
result(i) := Data(i);
else
result(i) := Data(i) and (not or_reduce(Data(i-1 downto Data'low)));
end if;
end loop;
Output := result;
Valid := or_reduce(Data);
end procedure;
ちなみに or_reduce とは与えられたビットすべてのor(論理和)をとります。したがって、ビットのどれかが1の場合に1になります。or_reduce の not(否定)はビットの全てが0の場合に1になります。
4. Use Decrement
これは For-loop を使わずに加算器(減算器)を使って該当するビットのみ1にする方法です。
procedure Priority_Encode_To_OneHot_Use_Decrement(
Data : in std_logic_vector;
variable Output : out std_logic_vector;
variable Valid : out std_logic
) is
variable i_data : std_logic_vector(Data'length-1 downto 0);
variable t_data : std_logic_vector(Data'length downto 0);
variable d_data : std_logic_vector(Data'length downto 0);
variable r_data : std_logic_vector(Data'length-1 downto 0);
variable o_data : std_logic_vector(Data'range);
begin
i_data := Data;
t_data := "0" & i_data;
d_data := std_logic_vector(unsigned(t_data) - 1);
r_data := i_data and not d_data(i_data'range);
o_data := r_data;
Valid := or_reduce(i_data);
Output := o_data;
end procedure;
このアルゴリズムは、ループをまわさないので一見良さそうに見えます。もちろんコンピュータープログラムとしてはループを回すアルゴリズムに比べて高速に演算します。ただ、それはあくまでもコンピューターの場合であって、FPGAなどの論理回路の場合は意外と低速です。コンピューターにとって良いアルゴリズムが論理回路にとっては必ずしもそうでは無いという典型的な例と言えます。
5. Parallel and Recursive
1〜4で説明したアルゴリズムは、いずれも、入力データのビット長が大きいと、それだけ低速になります。何故なら、for-loop で回すにしても加算器を使うにしても、最上位ビットのデータを生成するために入力データの最下位ビットの情報を伝搬する必要があるからです。
ここではビット長がある程度大きい場合を想定して、並列処理することを考えましょう。主な考え方は次の図の通りです。
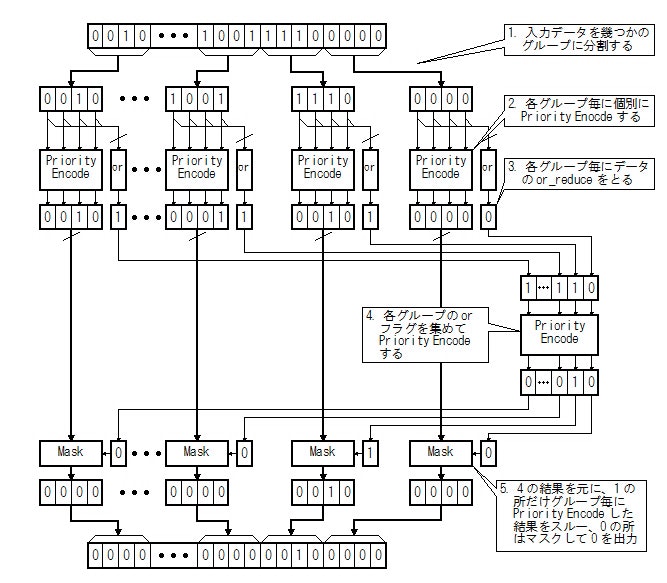
Fig.4 Parallel and Recursive Priority Encoder Diagram
このアルゴリズムでは、入力ビットをグループ毎に個別かつ並列にpriority encode します。また、priority encode を再帰的に処理します。
これを VHDL で記述すると次のようになります。
procedure Priority_Encode_To_OneHot_Selectable(
Min_Dec_Len : in integer;
Data : in std_logic_vector;
variable Output : out std_logic_vector;
variable Valid : out std_logic
) is
begin
if Data'length >= Min_Dec_Len then
Priority_Encode_To_OneHot_Use_Decrement(Data,Output,Valid);
else
Priority_Encode_To_OneHot_Use_OrReduce(Data,Output,Valid);
end if;
end procedure;
procedure Priority_Encode_To_OneHot_Use_RecursiveCall(
Min_Dec_Len : in integer;
Max_Dec_Len : in integer;
Data : in std_logic_vector;
variable Output : out std_logic_vector;
variable Valid : out std_logic
) is
constant Dec_Num : integer := (Data'length+Max_Dec_Len-1)/Max_Dec_Len;
constant Dec_Bits : integer := (Data'length+Dec_Num-1)/Dec_Num;
variable result : std_logic_vector(Data'range);
alias i_data : std_logic_vector(Data'length-1 downto 0) is Data;
variable o_data : std_logic_vector(Data'length-1 downto 0);
variable o_valid : std_logic_vector(Dec_Num-1 downto 0);
variable onehot : std_logic_vector(Dec_Num-1 downto 0);
begin
for i in 0 to Dec_Num-1 loop
Priority_Encode_To_OneHot_Selectable(
Min_Dec_Len => Min_Dec_Len,
Data => i_data(minimum(i_data'left, (i+1)*Dec_Bits-1) downto i*Dec_Bits),
Output => o_data(minimum(i_data'left, (i+1)*Dec_Bits-1) downto i*Dec_Bits),
Valid => o_valid(i)
);
end loop;
if (Dec_Num > 1) then
Priority_Encode_To_OneHot_Use_RecursiveCall(
Min_Dec_Len => Min_Dec_Len,
Max_Dec_Len => Max_Dec_Len,
Data => o_valid,
Output => onehot,
Valid => Valid
);
for i in 1 to Dec_Num-1 loop
if (onehot(i) = '0') then
if (i = Dec_Num-1) then
o_data(o_data'left downto i*Dec_Bits) := (others => '0');
else
o_data((i+1)*Dec_Bits-1 downto i*Dec_Bits) := (others => '0');
end if;
end if;
end loop;
else
Valid := o_valid(0);
end if;
Output := o_data;
end procedure;
Performance and Resource
Vivado
Performance
Xilinx社の Vivado(2015.4)で論理合成&配置配線した時の性能を遅延時間で示します。遅延時間が大きいほど遅いことを示します。
ビット幅が64ビット以内であれば、各アルゴリズムの違いはそれほどありません。ビット幅がそれ以上になるとアルゴリズムでの違いが顕著になります。
Table.1 Performance (Vivado 2015.4)
| Device | Parameter | Data Path Delay [nsec] | |||||
| Algorithm | |||||||
| Family | Speed | WIDTH | 1 | 2 | 3 | 4 | 5 |
| Zynq-7010 | 1 | 4 | 1.335 | 1.470 | 1.435 | 1.435 | 1.435 |
| 8 | 1.901 | 1.882 | 1.882 | 1.882 | 1.882 | ||
| 12 | 1.975 | 1.975 | 1.975 | 2.436 | 1.975 | ||
| 16 | 2.117 | 2.154 | 1.989 | 2.565 | 1.989 | ||
| 32 | 2.848 | 2.641 | 2.690 | 3.184 | 3.184 | ||
| 48 | 3.024 | 2.880 | 3.133 | 3.676 | 3.676 | ||
| 64 | 3.315 | 3.743 | 3.307 | 3.949 | 3.949 | ||
| 96 | 4.595 | 5.442 | 3.622 | 4.844 | 3.518 | ||
| 128 | 4.548 | 4.472 | 4.628 | 6.100 | 4.488 | ||
| 160 | 4.671 | 4.697 | 4.756 | 7.041 | 4.642 | ||
| 192 | 5.624 | 4.857 | 4.976 | 7.971 | 4.757 | ||
| 224 | 5.433 | 5.075 | 4.928 | 8.803 | 4.907 | ||
| 256 | 5.974 | 5.096 | 5.020 | 9.542 | 4.954 | ||
| 384 | 6.512 | 5.188 | 5.648 | 13.336 | 5.340 | ||
| 512 | 7.844 | 5.909 | 6.125 | 20.222 | 5.795 | ||
| 1024 | 12.376 | 8.383 | 7.730 | 38.619 | 7.830 | ||
| 2048 | 25.479 | 9.306 | - | 77.770 | 8.765 | ||
| 3072 | 30.839 | 9.630 | - | 115.989 | 9.037 | ||
| 4096 | 43.213 | 9.746 | - | 156.031 | 9.333 | ||
Resource
Table.2 Resource (Vivado 2015.4)
| Device | Parameter | Resource [LUTs] | |||||
| Algorithm | |||||||
| Family | Speed | WIDTH | 1 | 2 | 3 | 4 | 5 |
| Zynq-7010 | 1 | 4 | 8 | 8 | 8 | 8 | 8 |
| 8 | 17 | 17 | 17 | 17 | 17 | ||
| 12 | 26 | 26 | 26 | 37 | 26 | ||
| 16 | 38 | 40 | 38 | 48 | 38 | ||
| 32 | 79 | 82 | 82 | 101 | 101 | ||
| 48 | 122 | 125 | 134 | 152 | 152 | ||
| 64 | 162 | 165 | 207 | 203 | 203 | ||
| 96 | 225 | 251 | 330 | 305 | 311 | ||
| 128 | 223 | 226 | 358 | 333 | 349 | ||
| 160 | 380 | 290 | 493 | 403 | 440 | ||
| 192 | 329 | 338 | 622 | 474 | 533 | ||
| 224 | 519 | 426 | 760 | 544 | 626 | ||
| 256 | 455 | 512 | 882 | 614 | 711 | ||
| 384 | 669 | 703 | 1665 | 896 | 1069 | ||
| 512 | 974 | 903 | 3023 | 1248 | 1426 | ||
| 1024 | 1823 | 1870 | 13542 | 2408 | 1987 | ||
| 2048 | 3531 | 3415 | - | 4715 | 3612 | ||
| 3072 | 5293 | 5050 | - | 7029 | 5424 | ||
| 4096 | 6949 | 6775 | - | 9349 | 7271 | ||
1. For-loop with exit
このアルゴリズムは、入力データのビット幅が256ビット以内であれば他のアルゴリズムとそれほど遜色ない結果を示しました。しかし、それ以上のビット幅ではビット幅が増えるにつれて、急速に悪化しています。
2. For-loop with found flag
このアルゴリズムが、意外と健闘しています。性能や容量のどちらをみても他のアルゴリズムよりも良い結果を出しています。しかも5の並列化したアルゴリズムと遜色ない結果を出しています。気合い入れて並列化した記述をした身としては、ちょっとがっかりなほどです。
3. For-loop with or-reduce
このアルゴリズムは、実は入力データのビット数が2048ビットを超えると、 Vivado の論理合成が終了しませんでした。どうやらこのアルゴリズムは Vivado は不得意なようで、最適化に苦労するようです。しかしビット数が小さい場合は最適化が効くらしくそれなりの結果を出しています。
4. Use Decrement
このアルゴリズムは、Xilinx の FPGA ではあまりうまくいきませんでした。もともと FPGA の加算器はキャリーを伝搬する方式です。Xilinx の FPGA には、キャリー伝搬用の回路と配線は専用のものが用意されていてそれなりに高速なのですが、総遅延時間はビット数に比例するので、ビット数が大きいと、他のアルゴリズムに比べて目に見えて遅くなりました。
繰り返しますが、コンピューターにとって良いアルゴリズムが論理回路にとっては必ずしもそうでは無いという典型的な例と言えます。
5. Parallel and Recursive
2のアルゴリズムとそれほど変わらない結果でした。一応、最速な結果が出てますが、苦労した割りには感満載です。
Quartus
Altera社の Quartus Prime (15.1) Light Editiionで論理合成&配置配線した時の性能を動作周波数で示します。動作周波数が大きいほど速いことを示します。
Table.3 Performance (Quartus Prime 15.1 Light Edition)
| Device | Parameter | Fmax(MHz) Slow 1100mV 85C Model | |||||
| Algorithm | |||||||
| Family | Speed | WIDTH | 1 | 2 | 3 | 4 | 5 |
| Cyclone V | 4 | 811.69 | 811.69 | 811.69 | 811.69 | 811.69 | |
| 8 | 647.25 | 647.25 | 430.48 | 647.25 | |||
| 12 | 528.54 | 528.54 | 528.54 | 431.48 | 528.54 | ||
| 16 | 460.41 | 460.41 | 460.41 | 360.36 | 460.41 | ||
| 32 | 318.98 | 318.98 | 311.92 | 287.69 | 287.69 | ||
| 48 | 240.96 | 240.96 | 239.41 | 224.62 | 224.62 | ||
| 64 | 175.38 | 175.38 | 193.27 | 245.58 | 245.58 | ||
| 96 | 141.00 | 141.00 | 133.74 | 187.41 | 186.12 | ||
| 128 | 105.21 | 105.21 | 101.00 | 169.89 | 177.71 | ||
| 160 | 86.09 | 86.09 | 85.46 | 145.84 | 190.55 | ||
| 192 | 72.49 | 72.49 | 72.10 | 132.40 | 174.00 | ||
| 224 | 61.56 | 64.06 | 61.56 | 111.42 | 168.18 | ||
| 256 | 55.28 | 54.06 | 55.28 | 102.15 | 157.88 | ||
| 384 | 36.19 | 36.79 | 36.19 | 74.64 | 153.14 | ||
| 512 | 27.85 | 27.42 | 27.85 | 60.28 | 149.68 | ||
| 1024 | 13.80 | 14.14 | - | 32.07 | 129.85 | ||
| 2048 | 7.08 | 7.09 | - | - | 113.57 | ||
| 3072 | 4.62 | - | - | - | - | ||
Table.4 Resource (Quartus Prime 15.1 Light Edition)
| Device | Parameter | Resource [ALMs] | |||||
| Algorithm | |||||||
| Family | Speed | WIDTH | 1 | 2 | 3 | 4 | 5 |
| Cyclone V | 4 | 1.8 | 1.8 | 1.8 | 1.8 | 1.8 | |
| 8 | 5.3 | 5.3 | 9.8 | 5.3 | |||
| 12 | 9.3 | 9.3 | 9.3 | 14.2 | 9.3 | ||
| 16 | 12.0 | 12.0 | 12.0 | 19.1 | 12.0 | ||
| 32 | 27.5 | 27.5 | 27.5 | 38.5 | 38.5 | ||
| 48 | 40.2 | 40.2 | 39.2 | 57.8 | 57.8 | ||
| 64 | 56.0 | 56.0 | 54.7 | 78.6 | 78.6 | ||
| 96 | 84.9 | 84.9 | 83.4 | 119.8 | 114.8 | ||
| 128 | 113.5 | 113.5 | 112.2 | 158.6 | 153.8 | ||
| 160 | 141.6 | 141.6 | 140.2 | 199.2 | 193.2 | ||
| 192 | 175.5 | 175.5 | 175.3 | 240.3 | 230.5 | ||
| 224 | 232.6 | 204.5 | 232.6 | 281.1 | 273.2 | ||
| 256 | 266.4 | 233.7 | 266.4 | 322.7 | 307.0 | ||
| 384 | 408.7 | 348.8 | 408.7 | 483.8 | 473.8 | ||
| 512 | 552.3 | 464.3 | 552.3 | 648.2 | 611.5 | ||
| 1024 | 1066.3 | 921.7 | 41690.5 | 1309.6 | 1244.8 | ||
| 2048 | 2120.0 | 1836.7 | - | 2313.7 | 2479.7 | ||
| 3072 | 3169.4 | - | - | - | - | ||
1. For-loop with exit
2. For-loop with found flag
3. For-loop with or-reduce
Quartus では、上の3つのアルゴリズムでの違いはほとんどありませんでした。ビット幅が大きくなるのと比例して遅延時間が増えています。おそらく、Quartus はあまりこの手の For-loop の最適化が Vivado に比べて上手くないようです。
4. Use Decrement
Altera の FPGA もキャリー伝搬方式の加算器です。キャリー伝搬用の回路と配線は専用のものが用意されていてそれなりに高速なのですが、総遅延時間はビット数に比例するので、ビット数が大きいとそれに比例して遅くなっています。
ただ、Xilinx の Vivado の場合と異なり、For-loop の最適化がダメダメなので、それに比較するとマシな結果を出しています。
5. Parallel and Recursive
Altera の場合は、並列化の記述がよく効きました。頑張って書いた甲斐がありました。
Comment
このような単純な回路でも、記述方法によって、また使用するデバイスやツールによって異なる結果がでました。どれか一つに絞るのではなく、用途に応じて記述方法を変えるくらいの工夫が必要でしょう。
Reference
ここで説明した VHDL のコードと、論理合成時に使用したスクリプトは以下のところにあります。
https://github.com/ikwzm/Generic_Priority_Encoder
また、ここで説明した VHDL のコードを他からも利用しやすいようにパッケージにしたものが、こちらにあります。
https://github.com/ikwzm/PipeWork/blob/master/src/components/priority_encoder_procedures.vhd