この記事はMySQL Advent Calendar 2023 22日目の記事です。
はじめに
個人サービスでPlanetScaleを利用しているのですが、ある日突然以下のエラーが発生しました
primary is not serving, there is a reparent operation in progress
このエラーによって、DBが2時間程利用出来ない事態に陥りました。エラーの内容からプライマリサービスが機能していない以外に原因がわからなかったので対処した内容をまとめます。
エラーが起きたときの状態
読み取り行数が56億と少し多いサービスとなります。
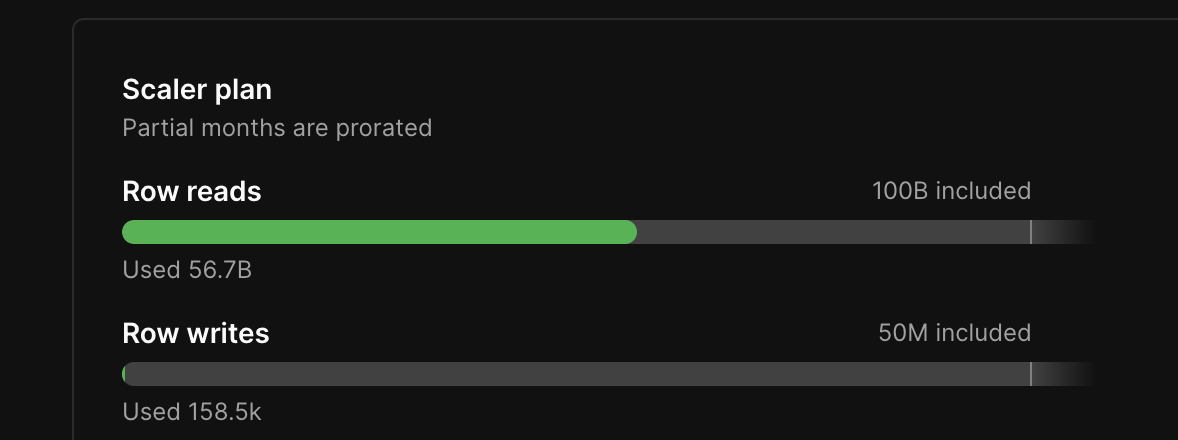
異様な数字に見えますが、以下のリンクにて「Rows read is a measure of the work that the database engine does,」と書いてあり、単純な読み取り行数ではないため負荷状況はQuery Insightsから確認する必要があります。
原因はVitessらしい
結論から言うとPlanetScaleが利用しているVitessというアーキテクチャによりエラーであり、バッファサイズが足りない場合に発生するようです。MySQLが出しているエラーではありません。詳しくは以下に記載してあります。
Vitess(ヴィテス)とはYouTubeの開発チームがMySQLのスケーラビリティの課題を解決するため作ったデータベースソリューションであり、PlanetScaleの特徴であるノンブロッキングマイグレーションなどの機能はVitessが提供している機能の1つとなります。
復旧
フェイルオーバー中なので待てばいずれ復旧するのですが、何個か対処できることがあるので記載します。
辛抱強く待つ
一番シンプルな方法です。私の場合は2時間止まっていたので待てませんでしたが余裕があれば辛抱強く待つことでいずれ完了します。正直なところ、私はすごく焦ってしまいmsccccさんというPlanet Scaleの中の人にメンションを飛ばして改善策を聞きました。早急なご返信と丁寧な回答いただきすごく助かりました![]()
バックアップから復旧する
バックアップからブランチを作成し、プライマリブランチを切り替える方法です。私はこの方法を利用しました。バックアップは1Gで0.023ドルなのでケチらずに細かく取るのもリスクヘッジにはなるかと思いました。
改善策
今後、フェイルオーバー中のエラーが発生する確率を下げるための改善策です。
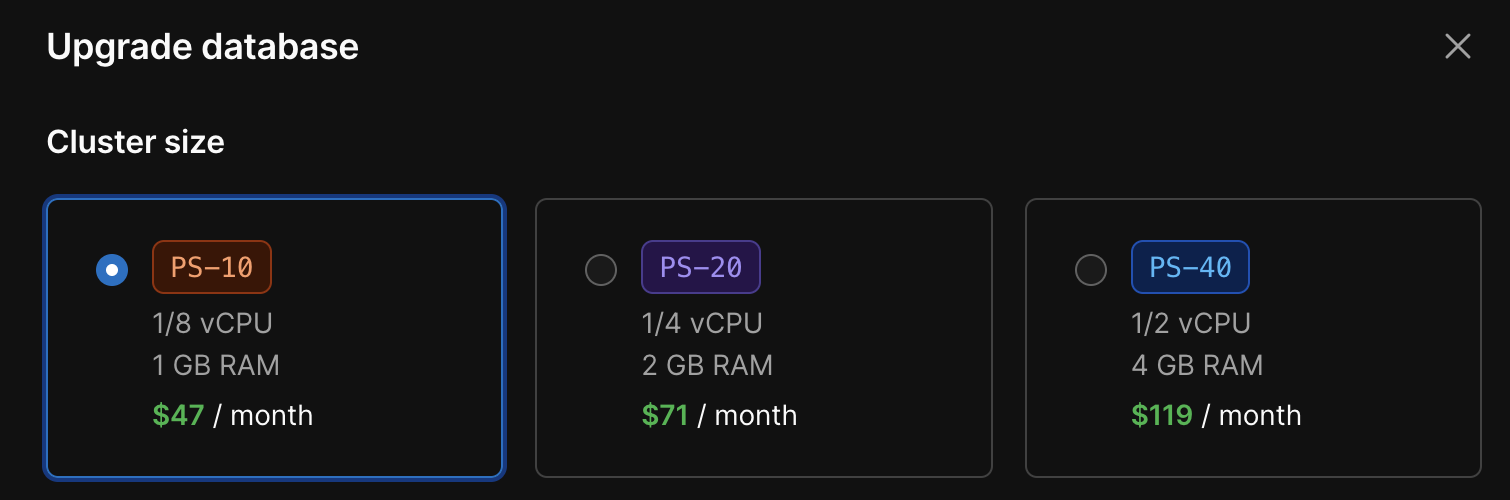
プランを上げる
一番シンプルな方法です。Scaler Proからメモリサイズを選択できます。どのプランにあげればよいかわからない場合はサポートに問い合わせると教えてくれます。さらにどのクエリに負荷が掛かっているか、何をしたらコストが下げられるかなどアドバイスしてくれます。ちなみにPS-40を推奨されましたが平凡なサラリーマンにひと月119ドルはきつい...
クエリを見直す
負荷が高いクエリを見直すことでバッファサイズを軽減することができます。Query Insightsで読み取り行数など確認出来るので負荷が高いクエリを調べることができます。ここでは適切なインデックスが貼られているかなどに注視してもよいでしょう。
なんとダッシュボードからEXPLAINを実行できます!EXPLAINを実行するには該当の行を選択しshow explain planを選択すると実行できます。


不要なクエリを削除する
当然ですが、利用する必要のないクエリがないか見直しましょう。私の場合はここが原因でした。効率的なクエリや適切なインデックスにばかり意識が行ってしまい、肝心な不要な呼び出しがあることに気がつくのが遅くなりました。一番先に確認しても良い観点かもしれません。
まとめ
上記の改善により56億readから11億readまで改善しバッファサイズの減少、パフォーマンスの改善が出来ました。まさかフェイルオーバー中にエラーが発生して復旧が遅くなるなんてことは想定していなかったため驚きました。適切なDB設計が出来ていないことや単純なミスが要因となってしまったのであまり遭遇することはないかもしれませんが困っている方のお役になればと思い書きました。PlanetScaleは比較的リーズナブルとはいえそれなりのコストがかかりますので、まずはクエリやサービスに問題がないかチェックした方が幸せになるかもしれません。
参考
https://github.com/vitessio/vitess/issues/9908
https://github.com/vitessio/vitess/issues/6206