皆様こんにちは。
今回はPandasを用いてCSVファイルを結合する際の結合方法、内部結合と外部結合について整理していきたいと思います。
前回の記事:Pandas:2つのCSVファイルを結合する方法
以下のCSVファイルで結合を実施します。
クラス名簿3.csv

出身中学校2.csv

結合方法を指定する際はmerge()メソッド内でhowで指定します。
pandas.merge(引数1, 引数2, on = '結合キー', how = '結合方法')
| 結合方法 | howの指定 |
|---|---|
| 内部結合(INNER JOIN) | inner |
| 外部結合:左(LEFT OUTER JOIN) | left |
| 外部結合:右(RIGHT OUTER JOIN) | right |
| 外部結合:ALL(FULL OUTER JOIN) | outer |
今回は前回の記事と同様に「クラス名簿3.csv」をdf、「出身中学校2.csv」をdf2、「中学校コード」を結合キーとし、それぞれ下記のように記述します。
# 内部結合
pandas.merge(df, df2, on = '中学校コード', how = 'inner')
# 外部結合:左
pandas.merge(df, df2, on = '中学校コード', how = 'left')
# 外部結合:右
pandas.merge(df, df2, on = '中学校コード', how = 'right')
# 外部結合:All
pandas.merge(df, df2, on = '中学校コード', how = 'outer')
内部結合(INNER JOIN)
「内部結合」は結合に用いたキーを基準として、左(df)、と右(df2)に共通するもののみを出力します。
別の言い方をすると、「中学校コード」の列を見た時にどちらのファイルにも存在するものだけを出力するという事です。
今回の例で言えば、df(クラス名簿3.csv)の中学校コード列には「7」、「8」というコードが存在しますが、df2(出身中学校2.csv)の中学校コード列には存在しません。
また、df2には「5」、「6」というコードが存在しますが、dfには存在しません。
そのため、どちらかにしか存在しない「5」、「6」、「7」、「8」を含む行は無視され、両者に共通するキーの値を持つ行のみが出力されます。
実際に結合したファイルを見てみましょう。

想定通り両ファイルに共通するもののみが出力されていることが分かると思います。
ちなみにどちらが左でどちらが右なのかという事については、コードの見た目通りに左側の引数が左、右側の引数が右の認識で問題ありません。
外部結合(OUTER JOIN)
1.外部結合:左(LEFT OUTER JOIN)
「外部結合:左」は左(df)を基準とし、基準になったファイルについては全ての行を出力しますが、他方はキーの値が一致する行のみが出力され、存在しない場合は空欄となります。
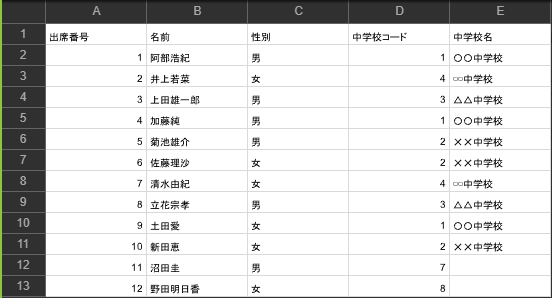
上記の通りdfは全ての行が出力されていますが、df2には中学校コード「7」、「8」を持つ中学校名は存在していないため、中学校名の欄は空になっています。
2.外部結合:右(RIGHT OUTER JOIN)
「外部結合:右」は先程とは反対で、右(df2)を基準とします。

df2の全ての行が出力されますが、dfには中学校コード「5」、「6」を持つ生徒はいないため、先程同様空欄になっていることが分かります。
3.外部結合:ALL(FULL OUTER JOIN)
「外部結合:ALL」は上記2つのハイブリッドのような形で、両ファイルのキーの値が一致しているか否かに関わらず全ての行を出力します。

まとめ
今回はPandasで結合する際の結合方法についてまとめてみました。
内部結合が見た目は一番きれいに結合されますが、実際に業務で何かファイルを結合しようとした場合、全ての欄が正しく埋められているとは限らないため、そうした際に外部結合を使いこなすことが重要なのかなと感じました。
今後も勉強を続け、より理解を深めていきたいと思います。