皆様こんにちは。
今回はPython学習の一環として、Pandasを用いて2つのCSVファイルを結合する方法を学んだので、記事にしようと思います。
環境は「Google Colaboratory」を使用しますが、こちらの使用方法については前回の記事にリンク等を乗せておりますので、そちらも是非ご覧ください。
前回の記事:Pandas:インデックス無しでCSVファイルを出力する方法
merge()メソッドを使って結合する
今回は以下のような2つのCSVファイルを用意しました。
クラス名簿2.csv
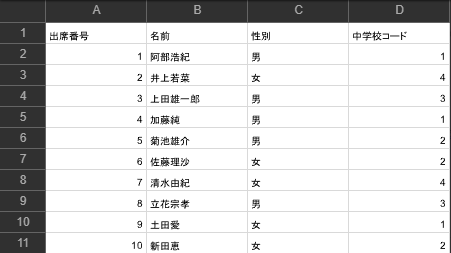
出身中学校.csv
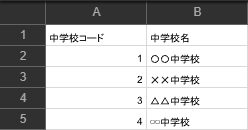
まずは2つのCSVファイルを読み込み、変数に格納します。
# google driveをマウント
from google.colab import drive
drive.mount('/content/drive')
# pandasをインポート
import pandas as pd
# 2つのCSVファイルをデータフレームとして読み込む
df = pd.read_csv('/content/drive/MyDrive/Python学習/CSV/クラス名簿2.csv')
df2 = pd.read_csv('/content/drive/MyDrive/Python学習/CSV/出身中学校.csv')
次にデータフレームを結合しますが、これにはmerge()メソッドを用い、下記の構文で記述します。
pandas.merge(引数1, 引数2, on = 'キー')
引数1、引数2にはそれぞれのデータフレームを格納した変数を、キーには結合に用いる共通のカラム名(列名)を記述します。
今回のCSVファイルには、どちらにも「中学校コード」という共通のカラムが存在するため、こちらをキーとして用います。
では、以下のコードでデータフレームを結合します。
# データフレームを結合
df_merged = pd.merge(df, df2, on = '中学校コード')
ワンポイント:その1
merge()メソッドは共通のカラムを自動的に見つけて結合してくれるため、今回のように1つだけ共通している場合は「on = 'キー'」の部分は省略可能です。
ただし、省略可能な場合でも明示していた方がどこを基準に結合したのかが分かりやすくなります。
ワンポイント:その2
例えば結合に用いたいカラム名が「中学校コード」、「学校コード」のようにそれぞれ異なる場合はrename()メソッドを用いて結合前にカラム名を変更することで対応できます。
構文:df.rename(columns={'元のカラム名': '変更後のカラム名'})
結合したデータフレームの中身を確認してみます。
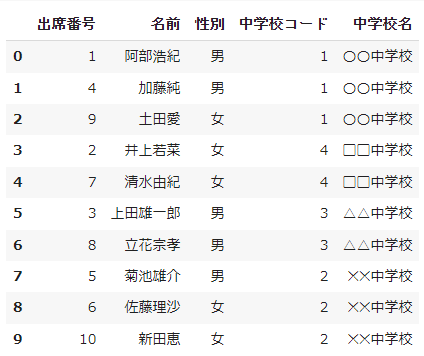
共通のキーである「中学校コード」を基に結合することができましたが、順番が「中学校名」を基準に自動で並べ替えられてしまいました。
sort_values()メソッドを使って整理する
このままの状態だと気持ちが悪いので、sort_values()メソッドを使って出席番号順に並べ替えます。
構文は下記の通りとなります。
df.sort_values('キー')
キーには並べ替えに用いるカラム名を記述します。
では、実際にデータフレームを並べ替えます。
# 出席番号順に並べ替え
df_sorted = df_merged.sort_values('出席番号')
再びデータフレームの中身を確認してみます。

出席番号順になっていることが確認できました。
ワンポイント:その3
sort_values()メソッドはデフォルトでは昇順で並べ替えになっています。
降順で並べ替えたい場合はascendingにFalseを指定しましょう。
例:df_sorted = df_merged.sort_values('出席番号', ascending = False)
後は前回の記事同様にインデックス無しでCSVファイルを出力して完了になります。
全体としては以下のコードになります。
# google driveをマウント
from google.colab import drive
drive.mount('/content/drive')
# pandasをインポート
import pandas as pd
# 2つのCSVファイルをデータフレームとして読み込む
df = pd.read_csv('/content/drive/MyDrive/Python学習/CSV/クラス名簿2.csv')
df2 = pd.read_csv('/content/drive/MyDrive/Python学習/CSV/出身中学校.csv')
# データフレームを結合
df_merged = pd.merge(df, df2, on = '中学校コード')
# 出席番号順に並べ替え
df_sorted = df_merged.sort_values('出席番号')
# CSVファイルとして出力
filePath = '/content/drive/MyDrive/Python学習/'
df_sorted.to_csv(filePath + 'クラス名簿(結合済).csv', index = False)
最後に出力されたCSVファイルを確認してみましょう。
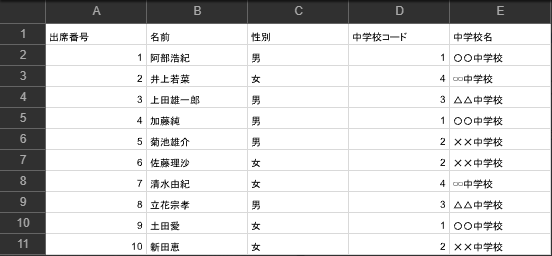
正しく結合できていることが確認できました。
内部結合?
実は今回行った結合方法は内部結合と呼ばれるもので、下記のようにmerge()メソッド内でhowで指定することができます。
df_merged = pd.merge(df, df2, on = '中学校コード', how = 'inner')
howはデフォルトではinnerとなっているため、今回のように省略した場合は自動的に内部結合(INNER JOIN)になります。
結合方法は内部結合も含めて下記の4種が基本形となります。
- 内部結合(INNER JOIN)
- 外部結合:左(LEFT OUTER JOIN)
- 外部結合:右(RIGHT OUTER JOIN)
- 外部結合:ALL(FULL OUTER JOIN)
結局のところ内部結合とは何なのか? 他の結合方法との挙動の違いは? 等といったことはまだしっかりと理解ができていないため、結合方法に関することは次回の記事でまとめたいと思います。
まとめ
いかがだったでしょうか。
まだまだ学習途中ではありますがPandasを使ったCSVファイルの結合方法についてまとめてみました。
結合方法の違いについて、またmerge()メソッド以外のメソッドについても今後の学習でより理解を深めていきたいと思います。