XNOR-net
-
元論文
-
解説記事
-
ソースコード
以下、論文の内容に沿って進めます。前半を細かく、後半を要約気味にしています。
図は、全て元論文からの引用です。
訳はGoogle Tanslateにお手伝いして頂きました。
Abstract
- 我々は、標準的な畳み込みニューラルネットワークに2つの効率的な近似を提案する:バイナリ重みネットワークとXNORネットワーク。
- Binary-WeightNetworksでは、フィルタはバイナリ値で近似され、32倍のメモリ節約になります。
- XNOR-Networksでは、フィルタと畳み込みレイヤへの入力の両方がバイナリです。
- XNOR-Networksは、主にバイナリ演算を使用してコンボリューションを近似します。
- これにより、58倍高速の畳み込み演算と32倍のメモリ節約が実現します。
- XNOR-Netsは、リアルタイムでCPU(GPUではなく)上で最先端のネットワークを実行する可能性を提供します。
- 私たちのバイナリネットワークは、シンプルで正確で効率的で、難しいビジュアルタスクに取り組んでいます。
- 我々は、ImageNet分類タスクに対する我々のアプローチを評価する。
- AlexNetのBinary-Weight-Networkバージョンでの分類精度は、完全精度のAlexNet(上位1つの測定値)の2.9%にすぎません。
- 最近のネットワーク二値化手法であるBinaryConnectとBinaryNetsとの比較を行い、これらの手法をImageNetの大きなマージンで上回り、トップ1精度で16%以上の向上となった
1. Introduction
-
Deep neural network は、複数のアプリケーション領域において、コンピュータービジョンや音声認識を著しく向上させた。
-
コンピュータグラフィックスにおいては、Convolutional Neural Networkがstate-of-the-artの結果をobject recognitionやdetectionで出している
-
畳み込みニューラルネットワークは、現実世界のアプリケーションで有用な物体認識および検出に関する信頼できる結果を示す。
-
最近の認識の進展に伴い、バーチャルリアリティ(VR by Oculus)、拡張現実感(AR of HoloLens)、スマートウェアラブル機器においても興味深い進歩が起こっている。
-
これら2つの部分をまとめると、スマートポータブル機器に最先端の認識システムのパワーを装備することが適切な時期である。
-
しかし、CNNベースの認識システムは、大量のメモリと計算能力を必要とする。
-
高価なGPUベースのマシンではうまく動作しますが、携帯電話や組み込み機器などの小型機器には適していない
-
たとえば、AlexNet は61Mのパラメータ(249MBのメモリ)を持ち、1.5B(15億)のHigh precision operations(高精度演算)を実行して1つのイメージを分類する
-
これらの数値は、より深いCNN、例えばVGG (セクション4.1を参照)ほどさらに高い
-
これらのモデルは、限られたストレージ、バッテリ電力、および携帯電話などのより小さいデバイスの処理能力をすぐさま消費する
-
本論文では2つの類似した手法を検討する
-
Binary-Weight-Networks (Neural networks with binary weight)
-
Binary-Weight-Networksでは、すべてのウェイト値がバイナリで近似される
-
Binary weightを使ったCNN では特に小さくなり、〜32倍小さくなる
-
加えて、2倍ほど速くなる
-
大きなCNNのBinary-Weight近似は、同じレベルの正確さを維持しながら、小型のポータブルデバイスであっても、そのメモリに適合することができる(セクション4.1節と4.2を参照)
-
XNOR-Networksでは、入力とウェイト値の双方がバイナリに近似される
-
バイナリウェイトとバイナリ入力により、畳み込み演算を効率的に実装することができます。
-
畳み込みのすべてのオペランドが2進である場合、畳み込みはXNORおよびビットカウント演算によって推定することができる。
-
XNOR-NetsはCNNを近似し、CPUで約58倍の速度を動作する。
-
これは、XNOR-Netsが小さなメモリとGPUのないデバイスでリアルタイム推論を可能にすることを意味する(XNOR-Netsの推論はCPU上で非常に効率的に実行できる)
-
知る限りでは、本論文はImageNetのような大規模データセットにバイナリニューラルネットワークの評価を提示する最初の試みである。
-
我々の実験結果は、畳み込みニューラルネットワークを2値化するために提案された方法が、ImageNet Challenge ILSVRC2012のTop-1 画像分類に大きなマージン(16.3%)で他の最先端のネットワーク二値化方法を凌駕することを示している。
-
本論文の貢献は2つある
-
まず、畳み込みニューラルネットワークで重み値を2進化する新しい方法を紹介し、最先端のソリューションと比較してこのソリューションの利点を示す
-
第2に、バイナリウェイトとバイナリ入力を備えた深いニューラルネットワークモデルであるXNOR-Netsを紹介し、XNOR-Netsは標準ネットワークと比較して類似の分類精度を得ることができることを示している
2. Related Work
https://qiita.com/supersaiakujin/items/6adaf9731c9475891911#related-work
3. Binary Convolutional Neural Network
- L-Layer CNNアーキテクチャを$\langle \mathcal{I},\mathcal{W},\ast \rangle$と表現する
- $\mathcal{I}$は、tensor のセットで、
- $\mathbf I=\mathcal{I}_{l(l=1,\dots,L)}$ は、$l^{\text{th}}$番目のレイヤーの入力のtensor (Figure 1 の緑の箱)
- $\mathbf I \in \mathbb{R}^{c \times w_{in} \times h_{in}}$で、 $(c,w_{in},h_{in})$はチャンネル数、width, height に対応する
- $\mathcal{W}$は、tensor のセットで、
- $\mathbf W =\mathcal{W}_{lk (k=1,\dots,K^{l})}$ は、$l^{\text{th}}$番目のレイヤーの$k^{\text{th}}$番目のWeight
- $K^l$は$l^{th}$番目のレイヤーのweight filterの数
- $\mathbf W \in \mathbb{R}^{c\times w\times h}$で、 $w \leq w_{in}, ~~h \leq h_{in}$.
- $\ast$はConvolution operation で、$\mathbf I$と$\mathbf W$をオペランドとして取る(本論文では、convolution filter biasを用いない)
- Binar-weightでは、$\mathcal{W}$は、binary tensors
- $XNOR-Networks$では、$\mathcal{I}$と$\mathcal{W}$が、binary tensors
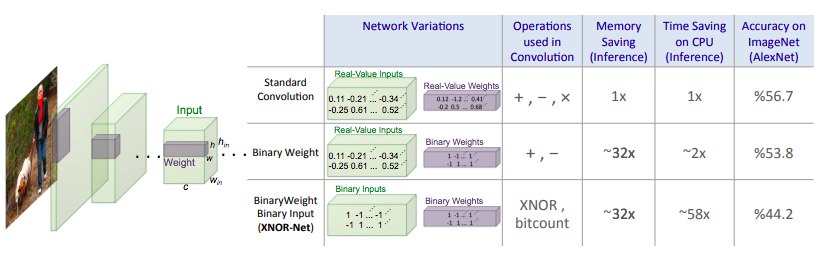
Fig. 1:
畳み込みニューラルネットワークの2つの効率的なバリエーションを提案する。
BinaryWeight-Networks:ウェイトフィルタにバイナリ値が含まれている。
XNOR-Networks:計量と入力の両方がバイナリ値を持つ場合
これらのネットワークは、自然画像分類において非常に正確である一方で、メモリおよび計算に関して非常に効率的である。
これにより、ポータブルデバイスの限られたリソースで正確なコンピュータービジョン技術の使用が可能になる
3.1 Binary-Weight-Networks
- $\langle \mathcal{I},\mathcal{W},\ast \rangle$ をバイナリーネットワーク化するために、実数ウェイトの$\mathbf W \in \mathcal{W}$をバイナリフィルター $\mathbf B$と、スケーリングファクター$\alpha$を用いる
\mathbf B \in \{ +1, -1 \}^{c \times w \times h}
\alpha in \mathbb{R}^+
- これにより、$\mathbf W \approx \alpha \mathbf B$となるようにし、以下の通り、Convolutional operationを近似する
式1:
\mathbf I \ast \mathbf W \approx (\mathbf I \bigoplus \mathbf B) \alpha
- ここで、$\oplus$ は、かけ算の無い、Convolutional operator とする
- Weight valueをバイナリーとすると、Convolutionを足し算と引き算のみで実装できる
- Binary weightのCNNを、$\langle \mathcal{I},\mathcal{B},\mathcal{A},\ast \oplus$ と表現する
- $\mathcal{B}$は、バイナリーテンサーのセット
- $\mathcal{B} = \mathcal{B}_{lk}$は、バイナリーフィルター
- $\mathcal{A}$は、スケーラに用いる正の実数
- $\alpha = \mathcal{A}_{lk}$は、スケーリングフィルター
- $\mathcal{W}{lk} \approx \mathcal{A}{lk} \mathcal{B}_{lk}$
Estimating binary weight
- 一般性を失うこと無く$\mathbf W$と$\mathbf B$を近似したいので、$\mathbf W \approx \alpha \mathbf B$のための以下の最適化を解く
式2:
J(\mathbf B, \alpha) = \| \mathbf W - \alpha \mathbf B \|^2
\DeclareMathOperator*{\argmax}{argmax}
\alpha^{\ast}, \mathbf B^{\ast} =\argmax_{\alpha, \mathbf B}J(\mathbf B, \alpha)
- この式は、以下の通り展開できる
式3:
J(\mathbf B, \alpha) = \alpha^2\mathbf{B}^T\mathbf{B} - 2 \alpha\mathbf{W}^T\mathbf{B} + \mathbf W^T\mathbf W
- $\mathbf B \in { +1, -1 }^{n}$ において、$\mathbf B^T\mathbf B = n$ は定数となる。また、$\mathbf W$は既知の変数のため、$\mathbf W^T\mathbf W$も定数となる。$c=\mathbf W^T\mathbf W$とする。これで、式3を書き換えると以下のようになる。
J(\mathbf B, \alpha) = \alpha^2n - 2\alpha\mathbf W^T\mathbf B + c
- よって、最適化を求めるには、以下のような$\mathbf B$を求めたら良い。(αは正の値であることので、式2では、それは最大化において無視することができる)

- この最適化は、$\mathbf W_i \geq 0$ のとき$\mathbf B_i = +1$で、$\mathbf W_i < 0$のとき$\mathbf B_i = -1$のときに解くことができる(最大化される)結局、最適値 $\mathbf B^\ast$は、以下の通りとなる。
\mathbf B^\ast=sign(\mathbf W)
- 最適値 $\alpha^\ast$は、$J$を$\alpha$に関して導関数を求め(微分し)、ゼロとしておくと良い。

- ※ 筆者注:
- こちらの記事 で解説されていますが、以下の通り微分して変形しています。(Qiita記事より引用)
\begin{eqnarray}
\frac{\partial J(B,\alpha)}{\partial \alpha}=2\alpha n - 2 W^TB^* = 0\\
\alpha^* = \frac{W^TB^*}{n}\\
\end{eqnarray}
- これを、$\mathbf B^\ast$を前の式に置き換える

- したがって、絶対重み値(l1ノルム)の平均値となる。
Training Binary-Weights-Networks

-
一般的にTrainingは、3ステップに分かれる。Forward、Backward, Update。
-
バイナリウェイト(畳み込みレイヤー)を持つCNNを訓練するために、フォワードパスおよびBackward propagation中のウェイトのみを2進化する。
-
パラメータを更新するときは、高精度(実数値)ウェイトを使用する。 勾配降下ではパラメータの変化が小さいため、パラメータを更新した後の2値化はこれらの変化を無視してしまう。
-
Algorithm1は、バイナリ加重を用いてCNNを訓練するための手順を示す。
-
まず、$\mathcal{B}$と$\mathcal{A}$を計算して各レイヤーの重みフィルタを2値化する。次にバイナリ重みとそれに対応するスケーリング係数を使用して順方向伝搬を呼び出し、すべての畳み込み演算を式1で実行する。
-
勾配は推定された重みフィルタ$\widetilde{\mathcal{W}}$に関して計算される。 最後に、パラメータおよび学習率は、例えば運動量またはADAMによるSGD更新などの更新規則によって更新される
-
トレーニングが終了したら、実際の価値の重みを維持する必要はありません。 推論では、2進化された重み付きの順方向伝播のみを実行するためです。
3.2 XNOR-Networks
- 畳み込み層への入力は、依然として実数値のテンソルのため、 ここでは、重みと入力の両方を2進化する方法について説明する。
- これにより、畳み込みは、XNORとビットカウント演算を使用して効率的に実装できる。 これはXNOR-Networksの重要な要素である
- バイナリウェイトとバイナリ入力を持つためには、畳み込み演算の各ステップでバイナリオペランドを実行する必要があります。
- 畳み込みは、シフト演算とドット積を繰り返すことからなる。 シフト操作は、重みフィルタを入力に移動し、内積は、重みフィルタの値と入力の対応する部分との間で要素ごとの乗算を実行する。 binary演算でドット積を表現すると、畳み込みはbinary演算を使って近似することができます。 2つのバイナリベクトル間の内積は、XNOR-ビットカウント演算によって実現することができる。
- このセクションでは、$\mathbb{R}^{n}$内の2つのベクトル間のドット積を{+1, -1}$^n$内の2つのベクトル間の内積で近似する方法を説明する
Binary Dot Product:
- $\mathbf X, \mathbf W \in \mathbb R^n$の内積をするとき、$\mathbf X, \mathbf W \approx \beta \mathbf H^T \alpha \mathbf B$となる。このとき、$\mathbf H, \mathbf B \in$ {+1, -1}$^n$、$ \beta, \alpha \in \mathbb R^+$
- 先ほどと同じような最適化を解く
式7:

- $\mathbf Y \in \mathbb R^n$ を、$\mathbf Y_i = \mathbf X_i \mathbf W_i, \mathbf C \in ${+1, -1}$^n$とし、$\mathbf C_i = \mathbf H_i \mathbf B_i$とし、$\gamma in \mathbb R^n$を$\gamma = \beta \alpha$として、式7を書き換えると以下の通りとなる
- 1はn次元ベクトルであり、そのすべての要素は1である。
- $1^T$は最適化から因数分解することができ、最適解は式2から次のように達成することができる


-
は独立しており、
のとき、
で、以下のようになる
式10

- したがって、重み値の符号をとることによって、バイナリ重みフィルタの最適な推定を簡単に達成することができる。 最適なスケーリング係数は、絶対重み値の平均値である。
Binary Convolution:
Fig .2 この図は、3.2項で説明したバイナリ演算を使った畳み込み近似の手順を示している。

- Convolving weight filter $\mathbf W \in \mathbb{R}^{c \times w \times h}$($w_{in} >> w, h_{in} >> h$)と入力のテンソル $\mathbf I \in \mathbb{R}^{c \times w_{in} \times h_{in}}$は、$\mathbf W$のサイズと同じ $\mathbf I$のサブテンソルに対して、スケーリングファクター$\beta$を用いる必要がある
- サブテンソルのうち2つを figure 2 に$X_1, X_2$として描いた(2行目)
- サブテンサー同士がオーバーラップしているため、$\beta$の計算量は大きく削減できる。
- これを削減するために、まず、行列
つまり各要素の絶対値をチャンネル方向に平均した値を求める
- そして、$\mathbf A$ を2d filter
とconvolution する。
- $\mathbf K$は、は、インプット$\mathbf I$の全てのサブテンソルのスケーリングファクター$\beta$を含む。
- $\mathbf K_{ij}$ は、location $ij$の中央とするサブテンソルのための$\beta$に対応する。
- この処理は、figure 2 の3行目に示してある
- $\mathbf I$($\mathbf K$と表記)のすべてのサブテンソルの重みと$\beta$のスケーリング係数$\alpha$を取得すると、主にバイナリ演算を使用して入力$\mathbf I$と重みフィルタ$\mathbf W$の畳み込みを近似することができる。
式11:

- $\circledast$はXNORとbitcountによるconvolutional operation。
- $\odot$は要素ごとの掛け算。
- これは図2の最後の行に示されている。非バイナリ操作の数はバイナリ操作に比べて非常に少ない。
Training XNOR-Networks
Fig. 3: この図には、XNOR-Network(右)と典型的なCNN(左)のブロック図を含む

-
CNNの典型的なブロックには、いくつかの異なるレイヤが含まれる。図3(左)は、CNNの典型的なブロックを示す。
-
このブロックは、以下の順に4つのレイヤーを持つ。
-
1コンボリューション、
-
2バッチノーマライズ、
-
3アクティベーション、
-
4プーリング
-
Batch Normalization層は、入力バッチを平均と分散で正規化します。
-
活性化は、要素ごとの非線形関数(例えば、Sigmoid、ReLU)である。
-
プーリング層は、入力バッチに任意のタイプのプーリング(例えば、最大、最小または平均)を適用する。
-
バイナリ入力にプールを適用すると、情報が大幅に失われる。
-
たとえば、バイナリ入力のmax-poolingは、その要素の大部分が+1に等しいテンソルを返す。
-
したがって、我々は畳み込みの後にプール層を置く。
-
二値化による情報損失をさらに低減するために、二値化する前に入力を正規化する。
-
これにより、データがゼロ平均を保持することが保証されるため、ゼロに閾値を設定すると、量子化誤差が小さくなる。
-
バイナリCNNのブロック内のレイヤの順序を図3(右)に示す。
-
バイナリActivationレイヤ(BinActiv)は、セクション3.2で説明したように、$\mathbf K$と$sign(\mathbf I)$を計算します。
-
$sign$関数$q=sign(r)$の勾配を計算するため、BinaryNet と同じように、$g_r = g_q1_{|r| \leq 1} $とする
-
次のレイヤー BinConv では、$\mathbf K$と$sign(\mathbf I)$が与えられ、式11によりBinary convolutionが行われる
-
そして、最後のレイヤーPoolで、pooling operation を適用する
-
バイナリ畳み込み後に、非バイナリアクティベーション(例えば、ReLU)を挿入することができる。これは、最先端のネットワーク(AlexNetやVGGなど)を使用する場合に役立つ。
-
いったんバイナリCNN構造を持つと、トレーニングアルゴリズムはアルゴリズム1と同じになる。
4. Experiments
Fig. 4: この図は、メモリ(a)と計算(b-c)に関するバイナリ畳み込みの効率を示している。 (a)AlexNet、ResNet-18、VGG-19の3つの異なるアーキテクチャで、バイナリと倍精度の重みに必要なメモリを対照している。 (b、c)はバイナリ畳み込みによって得られたスピードアップを示している。(b)はチャネル数、(c) はフィルタサイズで比較している

4.1 Efficiency Analysis
通常のConvolutionの計算量は以下の通り示せる。
式12:

-
$cN_{\mathbf W}N_{\mathbf I}$ : オペレーション数
-
$c$ は、channel数
-
$N_{\mathbf W} = wh$
-
$N_{\mathbf I} = w_{in}h_{in}$
-
バイナリコンボリューションの近似(式11)は、$cN_{\mathbf W}N_{\mathbf I}$ のバイナリーオペレーションを持ち、$N_{\mathbf I}$ の非バイナリーオペレーションを持つ。
-
現世代のCPUでは、CPUの1クロックで64のバイナリ演算を実行できるため、高速化は上の式12のように計算できる。
4.2 Image Classification on ILSVRC2012
AlexNet
Fig. 5: この図は、訓練期間にわたるTop-1とTop-5のimagenet分類精度を比較している。 我々のアプローチであるBWNとXNOR-Netは、BinaryConnect(BC)とBinaryNet(BNN)をすべてのエポックで大きな差(〜17%)で凌駕している。

Table 1: この表は、full precisionネットワークの最終精度(Top1〜Top5)をbinary precisionネットワークと比較しています。 バイナリウェイトネットワーク(BWN)とXNORネットワーク(XNORNet)と競合の手法; BinaryConnect(BC)およびBinaryNet(BNN)を比較している。

Residual Net
Fig. 6: この図は分類精度を示している。 ResNet-18を使用したバイナリウェイトネットワークとXNORネットワークによるImageNetデータセットのトレーニングエポックの(a)トップ1および(b)トップ5の尺度。

Table 2: この表は、binary precisionネットワークによって達成された最終的な分類精度をResNet-18アーキテクチャのFull precisionネットワークと比較しています。

GoogleNet Variant
著者注:なぜか結果が書いていない。。
4.3 Ablation Studies
※ 著者注:"Ablation Studies"(切除研究)とは、モデルまたはアルゴリズムのいくつかの「特徴」を除去し、それがどのように性能に影響するかを見ること
本発明の方法と従来のネットワーク二値化方法との間には、バイナリCNNの2値化技法とブロック構造の、2つの重要な相違点がある。
二値化のために、我々は訓練の反復ごとに最適なスケーリング係数を見つける。
ブロック構造では、XNOR-Netをトレーニングするために量子化損失を減少させる方法でブロック内のレイヤーを順序付けする。
ここでは、バイナリネットワークのパフォーマンスにおけるこれらの各要素の影響を評価する。
式6を用いてスケーリング係数$\alpha$を計算する代わりに、ネットワークパラメータとして$\alpha$を考慮することができる。
換言すれば、2進畳み込み後のレイヤは、畳み込みの出力に各フィルタのスカラーパラメータを乗算する。
これは、バッチ正規化でアフィンパラメータを計算するのと同様である。
Table 3-aは、スケーリング係数を計算する2つの方法とバイナリネットワークのパフォーマンスを比較しています。
3.2節で述べたように、CNNの典型的なブロック構造は二進化には適していません。
Table 3-bは、標準ブロック構造C-B-A-P(畳み込み、バッチ正規化、活性化、プール)を構造B-A-C-Pと比較しています。
(Aはバイナリアクティベーション)。
Table 3:この表では、我々のアプローチの2つの重要な要素を評価する。 最適なスケーリング係数を計算し、バイナリ入力を持つCNNブロック内のレイヤの正しい順序を指定する。 (a)バイナリウェイトネットワークの訓練におけるスケーリングファクタの重要性を実証し、(b)CNNブロック内のレイヤの順序付け方法がXNORNetworksのトレーニングにとって重要であることを示している。 C、B、A、Pはそれぞれ畳み込み、バッチ正規化、Activate関数(ここではバイナリアクティベーション)、プーリングを表す。

5 Conclusion
- ニューラルネットワークのための簡単で、効率的で正確なバイナリ近似を導入する。
- 重みのバイナリ値を見つけることを学ぶニューラルネットワークを訓練する。ネットワークのサイズを約32倍縮小し、非常に深いニューラルネットワークを制限されたメモリを持つポータブルデバイスにロードする可能性を提供する。
- 我々はまた、畳み込みを近似するために主にビット単位の演算を使用するアーキテクチャXNOR-NETを提案する。
- これは約58倍のスピードアップを実現し、リアルタイムのCPU(GPUではなく)上の最先端の深いニューラルネットワークの推論を実行する可能性を可能にする。