はじめに
まだ途中までしか書けていません。
注:と記載したところは、このQiita記事の筆者である @ikeyasu のコメントです
以下、できるだけ論文の流れに沿ってまとめます。
図は、全て元論文からの引用です。
訳は Google Translate や DeepL にお手伝いして頂きました。
論文リンク
https://arxiv.org/pdf/1905.11108.pdf
https://github.com/arXivTimes/arXivTimes/issues/1235
参考リンク
Behavior Cloning(行動クローニング。訳語は合っているのだろうか。。)
https://note.com/npaka/n/n8db35d24d44f
adversarial imitation methods(敵対的模倣法。訳語は合っているのだろうか。。)
オンポリシー・オフポリシー
https://qiita.com/ABmushi/items/83a639506fcbc4050ce8
soft Q learning
https://arxiv.org/pdf/1702.08165.pdf
https://www.slideshare.net/DeepLearningJP2016/dlreinforcement-learning-with-deep-energybased-policies
soft actor critic
https://qiita.com/ku2482/items/fb79d8209f1162d9f141
Abstract
実演から専門家の行動を模倣する学習は、特に高次元で連続的な観測や未知のダイナミクスを持つ環境では困難な場合があります。
行動クローニング(BC)に基づく教師付き学習法では、エージェントが貪欲に実証行動を模倣するため、エラーの蓄積により実証状態からドリフトしてしまうという分布シフトに悩まされる。
最近の強化学習(RL)に基づく手法、例えば逆RLや生成的敵対的模倣学習(GAIL)は、RLエージェントを長い地平線上で実演に一致するように訓練することで、この問題を克服している。
タスクの真の報酬関数が不明であるため、これらの方法は、しばしば逆探学習を伴う複雑で脆弱な近似技術を用いて、デモンストレーションから報酬関数を学習する。我々は、RLを使用するが、報酬関数の学習を必要としない単純な代替案を提案する。
重要なアイデアは、エージェントに長い地平線上でデモにマッチするインセンティブを与えることであり、新しい分布外の状態に遭遇したときにデモ状態に戻るように促すことである。
我々は、エージェントに、デモされた状態でデモされた行動にマッチした場合にはr=+1の一定の報酬を与え、それ以外の行動にはr=0の一定の報酬を与えることで、これを達成する。
我々がソフトQ模倣学習(SQIL)と呼ぶ手法は、標準的なQ学習アルゴリズムや政策外のアクター批判アルゴリズムにわずかな変更を加えるだけで実装できる。
理論的には、SQILはBCの正則化された変種として解釈されることを示す。経験的には,Box2D,Atari,MuJoCoのさまざまな画像ベースの低次元タスクにおいて,SQILがBCよりも優れた性能を発揮し,GAILと比較して競争力のある結果を達成することを示す.
1 Introduction
多くの逐次的意思決定問題は模倣学習によって取り組むことができる:専門家がエージェントに最適に近い行動を示し、エージェントは新しい状況でその行動を複製しようとする[Argall et al., 2009]。
この論文では、専門家の行動実演と環境との相互作用能力が与えられた場合に、エージェントが専門家の真似をするように訓練する問題を考える。
エージェントは報酬信号を観測したり、専門家に問い合わせたりすることはなく、状態遷移のダイナミクスを知らない。
行動クローニング(BC)に基づく標準的なアプローチでは、教師付き学習を用いて、行動の結果について推論することなく、貪欲に実証された行動を真似る。
その結果、複合的なエラーがエージェントを実証された状態から遠ざける原因となる [Ross et al., 2011]。
BCの問題点は、エージェントがドリフトして分配不能状態に遭遇した場合、エージェントが実証状態に戻る方法を知らないことである。
逆強化学習(IRL)に基づく最近の手法は、RLエージェントを訓練することでこの問題を克服し、実証された行動を模倣するだけでなく、実証された状態を訪問することもできるようにしている[Ngら、2000、Wulfmeierら、2015、Finnら、2016b、Fuら、2017]。
これはまた、生成的敵対的ネットワークを用いてIRLを実装する生成的敵対的模倣学習(GAIL)[HooおよびErmon,2016][Goodfellowら,2014,Finnら,2016a]の背後にある核心的な考え方である。
タスクの真の報酬関数が未知であるため、これらの方法は、敵対的訓練を通じてデモから報酬信号を構築するため、実際に実装して使用することが困難である[Kurachら、2018]。
本論文では、敵対的模倣法()の有効性は、逆説的訓練や報酬関数の学習を全く必要としない、より単純なアプローチによって達成できるということを主な考えとしている。
直感的には、敵対的手法は、エージェントに
(1)実証された状態で実証された行為を真似るインセンティブと
(2) 新たな分布外の状態に遭遇したときに、実証された状態に戻るような行動を取るインセンティブを与える。
逆境法がBCのような貪欲法よりも優れている理由の一つは、貪欲法が行うのは (1)を行うのに対し、逆説法は(1)と(2)の両方を行う。我々のアプローチは、学習された報酬の代わりに一定の報酬を用いることで、逆説的な学習を行わずに(1)と(2)の両方を行うことを目的としている。
重要な考え方は、学習された報酬関数を用いてエージェントに報酬信号を与える代わりに、デモされた状態でデモされた行動にマッチした場合にはr = +1の一定の報酬を与え、それ以外の行動にはr = 0の一定の報酬を与えればよいということである。
本論文では、敵対的模倣法(adversarial imitation methods)の有効性は、逆説的訓練や報酬関数の学習を全く必要としない、より単純なアプローチによって達成できるということを主な考えとしている。
直感的には、敵対的手法は、エージェントに
(1)実証された状態で実証された行為を真似るインセンティブと
(2) 新たな分布外の状態に遭遇したときに、実証された状態に戻るような行動を取るインセンティブ
を与える。
敵対的手法がBCのような貪欲法よりも優れている理由の一つは、貪欲法が行うのは (1)を行うのに対し、敵対的手法は(1)と(2)の両方を行う。我々のアプローチは、学習された報酬の代わりに一定の報酬を用いることで、敵対的手法の学習を行わずに(1)と(2)の両方を行うことを目的としている。
重要な考え方は、学習された報酬関数を用いてエージェントに報酬信号を与える代わりに、デモされた状態でデモされた行動にマッチした場合にはr = +1の一定の報酬を与え、それ以外の行動にはr = 0の一定の報酬を与えればよいということである。
(a)イミテーションポリシーによって暗示された報酬関数にスパースティープリファクタを課すことによって、長い地平線のイミテーションを学習するBCの正則化された変種を実装することを示すことによって、動機づけられる。
このアプローチは、理論的には、
(a)模倣ポリシーによって暗示される報酬関数に事前にスパース性を課すことにより、
長期的な模倣を学習するBCの正規化された変数を実装することを示したと言える。
そして、(b)状態遷移ダイナミクスに関する情報を模倣ポリシーに組み込む。
直感的に言えば、我々の方法は、(a)非常に疎な報酬関数を用いてエージェントを訓練することによって達成され、(b)は教師付き学習の代わりにRLを用いてエージェントを訓練することによって達成される。
我々は、ソフトQ-learning [Haarnoja et al., 2017]を用いて、エージェントの経験再生バッファを専門家のデモンストレーションで初期化し、デモンストレーションの経験では報酬を一定のr = +1に設定し、エージェントが環境と対話しながら収集する新しい経験のすべてで報酬を一定のr = 0に設定することによって、我々のアプローチを実現する。
ソフトQ-learningはオフポリシー・アルゴリズムであるため、エージェントは必ずしも正の報酬を経験するためにデモ状態を訪問する必要はない。その代わりに,エージェントは最初にバッファに追加されたデモンストレーションをリプレイする. このように、我々の手法は、エージェントが必ずしもデモ状態に到達できないような、確率的なダイナミクスや連続的な状態を持つ環境でも適用可能である。この手法をソフトQ模倣学習(SQIL)と呼ぶ。
本論文の主な貢献は、高次元で連続的な観測と未知のダイナミクスを持つMDPにおいて有効な、シンプルで一般的な模倣学習アルゴリズムであるSQILである。
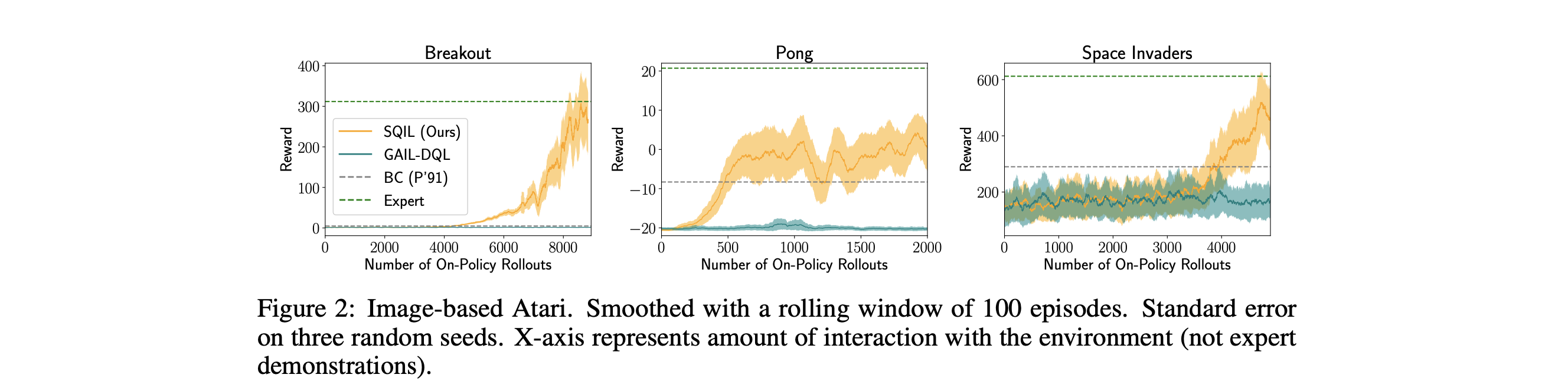
我々は、4つの画像ベースの環境(Car Racing, Pong, Breakout, SpaceInvaders)と3つの低次元環境(Humanoid, HalfCheetah, Lunar Lander)で実験を行い、SQILと2つの先行手法との比較を行った。BC および GAIL と比較しました。
その結果、SQILはBCよりも優れており、GAILと比較しても競争力のある結果が得られることがわかりました。
我々の実験では、SQIL の主な利点として以下の 2 点が挙げられている。
(1)敵対的訓練や報酬関数の学習を行わなくても、BCの状態分布シフト問題を克服できるため、画像などでの利用が容易になる。
そして
(2) 既存のQ-learningや政策外のアクタークリティックアルゴリズムを用いて実装するのが簡単であること。
2 Soft Q Imitation Learning
SQILは、3つの小さな、しかし重要な修正を加えたソフトQラーニング[Haarnoja et al., 2017]を実行する。
(1) 最初にエージェントの経験リプレイバッファをデモンストレーションで埋め、報酬は定数r = +1に設定されます。
(2)エージェントが世界と対話し、新しい経験を蓄積すると、それはリプレイバッファに追加され、これらの新しい経験のための報酬を一定のr = 0に設定します。
(3)リプレイバッファから各サンプルの実演体験数と新規体験数(各50%)のバランスをとる。
これらの3つの修正は、BCの正則化された変種との等価性を介して、第3節で理論的に動機づけられる。
これらの修正は、直感的には、実証状態では専門家の真似をし、デモンストレーション状態から外れた場合にはデモンストレーション状態に戻るような行動をとるというインセンティブをエージェントに与える単純な報酬構造を作り出す。
重要なことに、ソフトQ-learningはオフポリシーアルゴリズムであるため、エージェントは必ずしも正の報酬を経験するためにデモ状態を訪問する必要はありません。その代わりに,エージェントは,最初にバッファに追加されたデモンストレーションをリプレイする.このように,SQIL は,エージェントが実際にデモ状態に遭遇することがないかもしれない高次元の連続状態を持つ確率的な環境で使用することができる.

- 注:
SQILはAlgorithm 1にまとめられており、ここで$Q_θ$はソフトQ関数、$D_{demo}$はデモンストレーション、$δ^2$はソフトベルマン誤差の2乗であり、 $r ∈ {0, 1}$ は状態や行動に依存しない一定の報酬である。
$\delta^{2}(\mathcal{D}, r) \triangleq \frac{1}{|\mathcal{D}|} \sum_{\left(s, a, s^{\prime}\right) \in \mathcal{D}}\left(Q_{\boldsymbol{\theta}}(s, a)-\left(r+\gamma \log \left(\sum_{a^{\prime} \in \mathcal{A}} \exp \left(Q_{\boldsymbol{\theta}}\left(s^{\prime}, a^{\prime}\right)\right)\right)\right)\right)^{2}$
- 注:$\triangleq $は、定義するの意味。
セクション4の実験では、畳み込みニューラルネットワークまたは多層パーセプトロンを使用して$Q_θ$をモデル化しており、ここでθはニューラルネットワークの重みである。
付録のセクションA.3では、ハイパーパラメータλsampの値を含む追加の実装の詳細が記載されている;$λ_{samp} = 1$の単純なデフォルト値が様々な環境でうまく機能することに注意されたい。
アルゴリズム 1 の 5 行目の模倣ポリシーが専門家のように振る舞うようになると、専門家のような遷移の数が増えていき、割り当てられた報酬がゼロのバッファ Dsamp に追加されます。
これにより、エキスパートを模倣することに対する効果的な報酬は時間の経過とともに減衰していきます。
4行目の勾配ステップのためにサンプリングされたデモ経験と新しい経験の数(それぞれ50%)のバランスをとることで、この効果的な報酬はゼロに減衰するのではなく、少なくとも1/(1 + λsamp)のままであることが保証されます。
実際には、ソフトベルマンエラー損失の 2 乗が最小に収束した時点で SQIL を停止しても、この報酬の減衰はパフォーマンスを低下させないことがわかります。
など、付録の図8を参照のこと)。
先行手法も同様の手法を必要とすることに注意:GAILおよび敵対的IRL(AIRL)[Fuら、2017]の両方とも、識別器の訓練セット内の正の例と負の例の数のバランスをとり、AIRLはオーバーフィットを避けるために早期の停止を必要とする傾向がある。
3 Interpreting SQIL as Regularized Behavioral Cloning
(T.B.D)
4 Experimental Evaluation
我々の実験の目的は、画像のような高次元で連続的な観測と未知のダイナミクスを持つ様々なタスクにおいて、SQILを既存の模倣学習手法と比較することである。
我々は、4つの画像ベースのゲーム(Car Racing、Pong、Breakout、Space Invaders)と3つの状態ベースのタスク(Humanoid、HalfCheetah、Lunar Lander)について、BCおよびGAIL4に対するSQILのベンチマークを行う[Brockmanら、2016、Bellemareら、2013、Todorovら、2012]。
また、ルナランダーゲームでのアブレーション研究を通じて、SQILのどのコンポーネントがそのパフォーマンスに最も貢献しているかを調査する。
付録のセクションA.3には、追加の実験的詳細が記載されている。
4.1 Testing Generalization in Image-Based Car Racing
この実験の目的は、各手法がどれだけ専門家の実演を模倣できるかだけでなく、実演では見られない新しい状態に一般化する政策をどれだけ獲得できるかを研究することである。
そのためには,専門家による実演とは異なる初期状態分$S_{0}^{train}$を持つ環境で訓練を行うことで,デモンストレーション$S_{0}^{\text {demo}}$ の状態分布と実際に遭遇した状態とのミスマッチを系統的に制御することができる.
OpenAIジムのカーレースゲームの実験を行っています。
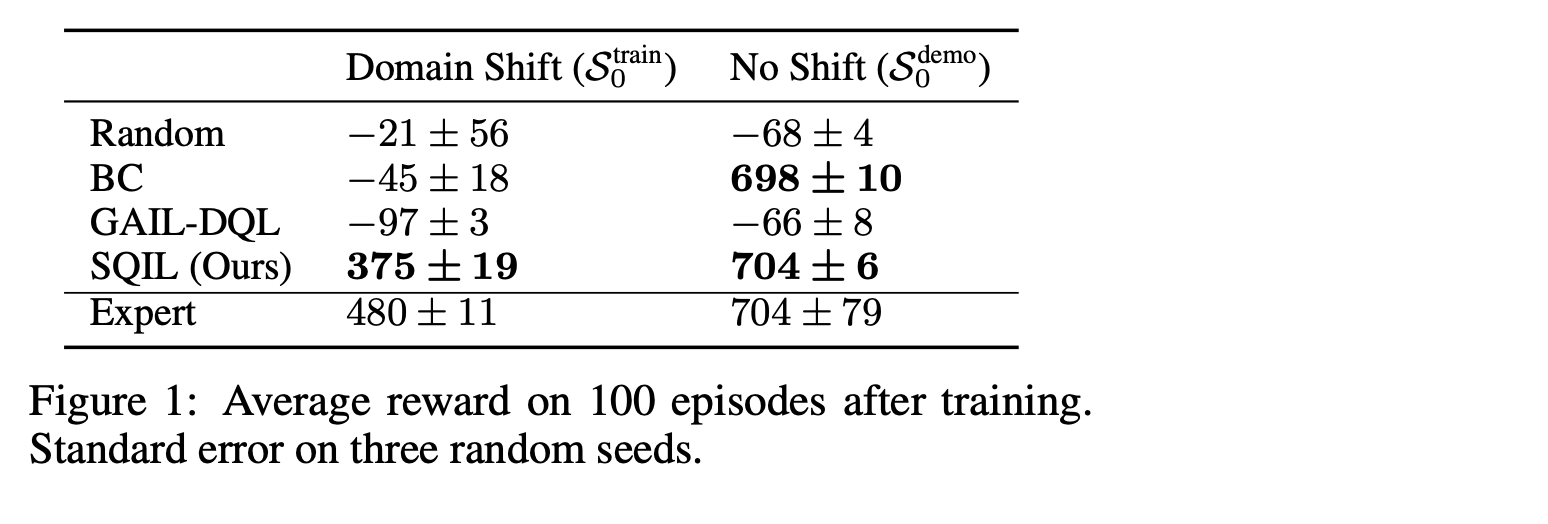
$S^{train}_{0}$を作成するには、車を90度回転させて、$S^{demo}_0$ のようにトラックに平行ではなく、トラックに垂直に始まるようにします。
この介入は、模倣学習者に大きな一般化の課題を与える。なぜなら、エキスパートのデモンストレーションには、車が道路に対して垂直な状態、あるいは道路の軸から大きく外れている状態の例が含まれていないからである。エージェントは、道路に戻るためにタイトターンを行い、道路に平行になるように方向を安定させ、エキスパートのデモンストレーションを模倣するために前進することを学習しなければならない。