On-Policy、Off-Policyの具体例であるSARSAとQ学習を比べてなんとなくこの二つがどう違うのか分かるようにまとめてみた。
用意した環境
例としてオンラインで見れる教科書"Reinforcement Learning: An Introduction By Richard S. Sutton and Andrew G. Barto"のExample 6.6で紹介されている「崖沿い歩き」の環境下でSARSAエージェント、Q学習エージェントがどう振る舞うかを観察してみる。
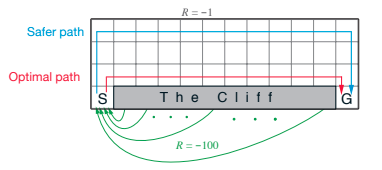
エージェントはスタート(S)からスタートし...
- ゴール(G)に進むと、
+1の報酬。振り出しに戻る。
- マスからはみ出ると、
-1の報酬。振り出しに戻る。 - 崖(The Cliff)に進むと、
-100の報酬。振り出しに戻る。 - それ以外の場所なら報酬
0。
Safer pathは崖から遠くを通ってゴールへ。しかし、最適なルートは崖沿いに崖から落ちずに進み切ることである。
実際のpygame上の画面。小さめの四角(左下)はエージェント。黄色四角がゴール。濃いグレーの四角が崖。

SARSA(On-Policy)エージェント
Q\left(S_t,A_t\right)\leftarrow Q\left(S_t,A_t\right)+\alpha[R_{t+1}+\gamma Q\left(S_{t+1},A_{t+1}\right)-Q\left(S_t,A_t\right)]
未来の行動(action)が現戦略(Policy)に乗っ取って(On)選ばれると想定して学習する。例えば現戦略がε-greedyだった場合、学習される評価関数Qはε-greedyのExplore(低確率で発生するランダムな行動選択)を想定して更新される。つまり、必ずしも最善策(Greedy Action)をとるとは限らない前提で学習が行われる。
def agent_step(self, reward, state):
# 次の行動(next_action)を現戦略(ε-greedy)に乗っ取って選択
next_action = 0
rnd = np.random.random()
if rnd < self.episilon:
# Explore
next_action = np.random.randint(0,4)
else:
# Exploit(Greedy Action)
next_action = np.random.choice( np.flatnonzero(self.Q[state[0],state[1]] == np.max(self.Q[state[0],state[1]])) )
# 次の行動の価値をTD学習の方法で計算
target = reward + self.gamma*self.Q[state[0],state[1],next_action]
# 評価関数の更新
self.Q[self.last_state[0],self.last_state[1],self.last_action] += self.alpha*(target - self.Q[self.last_state[0],self.last_state[1],self.last_action])
self.last_action = next_action
self.last_state = state
return next_action
SARSAエージェントの結果がこちら。
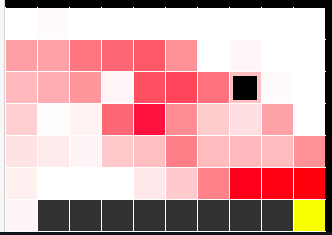
赤い部分ほどQ関数の値が高い。図を見れば分かる通りエージェントは崖沿いを避けるようにゴールにたどり着く。SARSAはOn-Policyである。つまり、ε-greedyのExploreが発生して崖から落ちるのを考慮して学習が行われるため、崖沿いの道は選択されにくくなる。特に今回の設定だと、ゴール到達の報酬+1に比べて、崖に落ちた時のペナルティが-100と巨大なため、たとえ数パーセント(今回は5%)という小さな確率でExploitによる崖転落が発生するとしても、崖沿いの最適ルートを選ぶにはリスクが大きすぎる。
Q学習(Off-Policy)エージェント
Q\left(S_t,A_t\right)\leftarrow Q\left(S_t,A_t\right)+\alpha[R_{t+1}+\gamma \max_{a} Q\left(S_{t+1},a\right)-Q\left(S_t,A_t\right)]
未来の行動(action)が現戦略(Policy)に**関係なく(Off)**常に最善のものが選ばれると想定して学習する。例えば現戦略がε-greedyだったとしても、学習される評価関数はε-greedyのExploreを想定せずに更新される。つまり、必ず最善策(Greedy Action)が取られる前提で学習が行われる。
def agent_step(self, reward, state):
# 次の行動はGreedyと言う前提で価値を計算
target = reward + self.gamma*np.max(self.Q[state[0],state[1]])
# 評価関数の更新
self.Q[self.last_state[0],self.last_state[1],self.last_action] += self.alpha*(target - self.Q[self.last_state[0],self.last_state[1],self.last_action])
# でも実際に選ぶ行動は現政策(ε-greedy)に基づいて選ばれる。
rnd = np.random.random()
if rnd < self.episilon:
# Explore
next_action = np.random.randint(0,4)
else:
# Exploit(Greedy Action)
next_action = np.random.choice(np.flatnonzero(self.Q[state[0],state[1]] == self.Q[state[0],state[1]].max()))
self.last_action = next_action
self.last_state = state
return next_action
Q学習エージェントの結果がこちら。
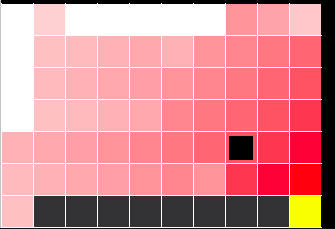
なるべく崖沿いを通るようにQ関数が学習される。これはQ学習がOff-Policyであるからだ。Off-Policyの時、エージェントは自らの戦略に含まれるε-greedyのExploreを考慮に入れない。Q学習なら、最適行動のみを考慮に入れて学習する。つまり、エージェントがExploreによるリスク(-100の報酬)が発生するのを無視して、崖沿いをまっすぐ進む行動をとることを前提に学習する。
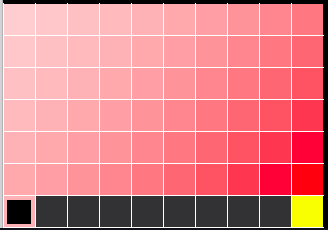
ちなみにQ学習の学習速度をPlanningという方法で速くするDyna-Q学習を行ったところ下のようなさらに正確な結果が得られた。
参考文献
- Reinforcement Learning: An Introduction: http://incompleteideas.net/book/the-book-2nd.html
- コードはGithubに公開した。