🚨 まず最初に伝えたいこと
「
ai_prep_searchのchunk_to_retrieveの冒頭が>で始まっていたら、それはテーブルが真っ二つに切られた死体です」 ⚰️
知らずに Vector Search に流すと、RAG の精度がジワジワ落ちます。本記事では Bronze → Silver → Vector Search 用 Silver への変換を ノートブックの実行順に追体験 できる形で解説します 🚀
📌 こんな方におすすめ
- 🤖 Databricks で RAG パイプラインを組もうとしている人
- 📄 PDF を
ai_parse_documentでパースしている人 - 🪄
ai_prep_search(Beta) を本番投入しようか迷っている人 - 🤯 「テーブルの途中で chunk が切れる問題」に頭を抱えている人
🎯 3 行まとめ
| # | 知見 |
|---|---|
| 1️⃣ |
ai_prep_search (Beta, 2026-04-08 リリース) のサポート options は 'version' のみ。chunk_overlap も chunking_strategy も存在しない 🚫 |
| 2️⃣ | 大型の表は chunk 中間で物理切断される。「セマンティックチャンキング」というマーケ文言を信じすぎてはいけない ⚠️ |
| 3️⃣ | 解決策は 「事前防御 (parse 直後に table を <tr> 単位分割) + 事後修復 (SQL Window 関数で断片を結合)」の二段構え ✨ |
📚 そもそも ai_prep_search って何?
公式マニュアル(Microsoft Learn ja-jp 版 Last updated 2026-04-17):
ai_prep_search()関数は、ai_parse_documentの構造化された出力を RAG ベクター検索および情報取得システム用に最適化された形式に変換します。
📋 公式仕様サマリー
| 項目 | 内容 |
|---|---|
| 🔧 シグネチャ | ai_prep_search(parsed VARIANT, [options MAP<STRING, STRING>]) RETURNS VARIANT |
| 📦 必要 Runtime | Databricks Runtime 18.2 以降 または Serverless 環境 3 以上 |
| 💻 対応言語 | Python または SQL |
| ⚙️ サポート options | 'version' のみ |
| 🚧 ステータス | Beta (2026-04-08 リリース) |
🚨 大前提:表データはベクトルDBに向かない(最初に押さえるべきこと)
これは初学者エンジニアに最初に伝えたいことです 🙏
| # | 制約 | 具体例 |
|---|---|---|
| 1️⃣ | 意味の最小単位がセル単位ではなく 行×列の交差 | 「523」というセル単独では何の数値か復元できない 🤷 |
| 2️⃣ | トークン長制限と表サイズの不整合 | 財務諸表は単独で 8,192 tokens を超える 📈 |
| 3️⃣ | HTML タグが埋め込みベクトルのノイズになる |
<td> を含むクエリが本来無関係な表に過剰ヒット 🎯❌ |
| 4️⃣ | チャンク境界で表が分断されると意味が消える | 上半分は「列ヘッダー」、下半分は「裸の行」👻 |
| 5️⃣ | 数値・単位・通貨の比較演算は守備範囲外 | 「売上が前年比10%増の部門」はベクトルでは答えられない ❌📊 |
💡 数値比較が要件にあるなら、本記事のアプローチではなく構造化テーブル併用パターンを採用すべきです。
🗺️ 全体パイプライン図
実装は次の流れで進めます。本記事はこの順番で実行順に解説します:
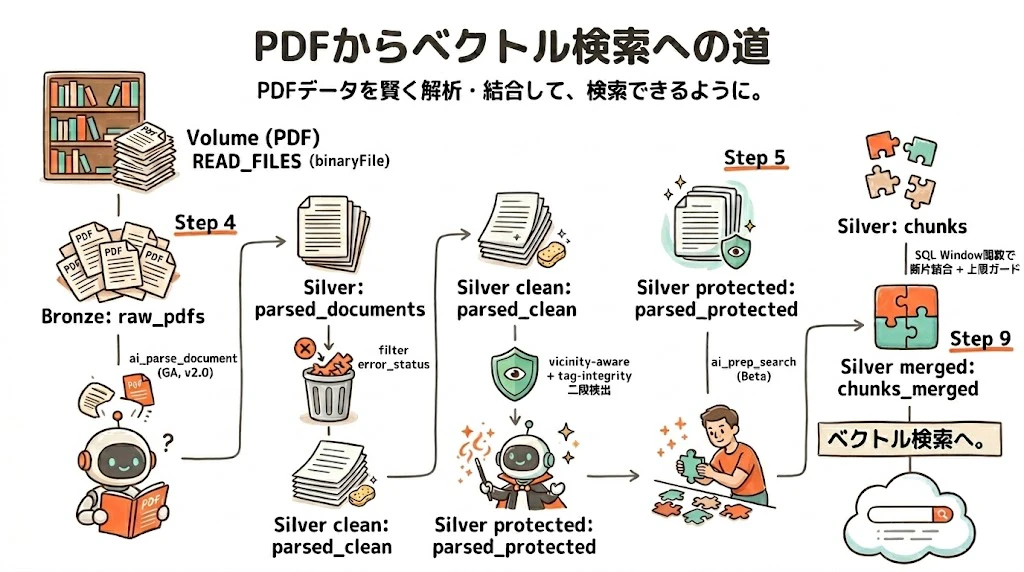
📁 Volume (PDF)
↓ READ_FILES (binaryFile)
🥉 Bronze: raw_pdfs ← Step 3
↓ ai_parse_document (GA, v2.0)
🥈 Silver: parsed_documents ← Step 4
↓ filter error_status
🥈 Silver clean: parsed_clean
↓ 🛡️ vicinity-aware + tag-integrity 二段検出
🛡️ Silver protected: parsed_protected ← Step 5
↓ 🪄 ai_prep_search (Beta)
🥈 Silver: chunks ← Step 6
↓ 🧩 SQL Window 関数で断片結合 + 上限ガード
🧩 Silver merged: chunks_merged ✨ ← Step 9 ← Vector Search に流す
🛤️ ノートブック実行順ガイド
✅ Step 0: 依存ライブラリのインストール 📦
BeautifulSoup と lxml をインストール。HTML タグ意識的分割で必須です。
%pip install --quiet beautifulsoup4 lxml
dbutils.library.restartPython()
💡 これがないと「タグの構造を理解した分割」ができません。
✅ Step 1: Widget 定義 🎛️
Notebook 上部に「変数を入力できるフォーム」を作って、コードを書き換えなくても catalog や schema を変更可能にします。
# 🎛️ ベース Widget
dbutils.widgets.text("catalog", "sandbox", "📦 1. Catalog")
dbutils.widgets.text("schema", "default", "📂 2. Schema")
dbutils.widgets.text("volume", "pdf_demo", "📁 3. Volume (PDF source)")
dbutils.widgets.text("image_volume", "pdf_demo_images", "🖼️ 4. Image Volume")
# 検証する PDF セットを選択
dbutils.widgets.dropdown(
"pdf_set",
"all",
["academic", "sec_10k", "ipcc", "all"],
"📚 5. PDF Set"
)
# 保護プリプロセスの動作パラメータ
dbutils.widgets.dropdown(
"table_split_threshold",
"threshold_balanced_3000",
["threshold_strict_2000", "threshold_balanced_3000", "threshold_loose_4000"],
"🛡️ 6. Table Split Threshold"
)
| 設定 | 説明 |
|---|---|
pdf_set=all |
4 PDFs (arXiv 2 本 + Apple 10-K + IPCC AR6) を一括 DL |
threshold_balanced_3000 |
3000 chars 超のテーブルを分割 (推奨) |
📌 派生 widget も自動登録
SQL セルから IDENTIFIER(:t_chunks) で参照できるよう、テーブルのフルパスも widget に登録します。
T_RAW = f"{CATALOG}.{SCHEMA}.raw_pdfs"
T_PARSED = f"{CATALOG}.{SCHEMA}.parsed_documents"
T_CLEAN = f"{CATALOG}.{SCHEMA}.parsed_clean"
T_PROTECTED = f"{CATALOG}.{SCHEMA}.parsed_protected"
T_CHUNKS = f"{CATALOG}.{SCHEMA}.chunks"
T_CHUNKS_RAW = f"{CATALOG}.{SCHEMA}.chunks_raw"
T_CHUNKS_MERGED = f"{CATALOG}.{SCHEMA}.chunks_merged"
T_FIXED_CMP = f"{CATALOG}.{SCHEMA}.chunks_fixed_size_baseline"
✅ Step 2: Volume 準備 + サンプル PDF 配置 📥
🏗️ スキーマと Volume を作成
CREATE SCHEMA IF NOT EXISTS IDENTIFIER(:catalog || '.' || :schema);
CREATE VOLUME IF NOT EXISTS IDENTIFIER(:catalog || '.' || :schema || '.' || :volume)
COMMENT 'PDF source for ai_parse_document demo 🐰';
CREATE VOLUME IF NOT EXISTS IDENTIFIER(:catalog || '.' || :schema || '.' || :image_volume)
COMMENT 'Rendered page images for multimodal RAG 🖼️';
📥 サンプル PDF をダウンロード
| ページ数 | 期待最大 table chars | 特徴 | |
|---|---|---|---|
| 📜 Attention Is All You Need (arXiv) | 15 | 3,101 | 軽量、表小さめ |
| 📜 BERT (arXiv) | 16 | 1,195 | さらに表小さい |
| 💼 Apple 10-K FY2025 | 80 | 5,020 | 連結財務諸表が大型 💰 |
| 🌍 IPCC AR6 SYR Longer Report | 115 | 5,111 | 気候データ表が複雑 🌡️ |
import os, urllib.request
PDF_CATALOG = {
"academic": {
"attention_is_all_you_need.pdf": {
"url": "https://arxiv.org/pdf/1706.03762.pdf",
...
},
"bert.pdf": {...},
},
"sec_10k": {"apple_10k_fy2025.pdf": {...}},
"ipcc": {"ipcc_ar6_syr_longer_report.pdf": {...}},
}
# SEC は User-Agent 必須
req = urllib.request.Request(
url,
headers={"User-Agent": "Databricks-Notebook-Educational example@example.com"}
)
⚠️
ai_parse_documentは 1 ドキュメントあたり最大 100MB / 500 ページ 制限があります。
✅ Step 3: Bronze - PDF をバイナリで読む 🥉
🔰 なぜ Bronze テーブルが必要?
ai_parse_document は 入力に BINARY 型の列を要求します。READ_FILES(..., format => 'binaryFile') を使うと、PDF を content (BINARY), path, _metadata 列をもつテーブルにできます。
CREATE OR REPLACE TABLE IDENTIFIER(:t_raw) AS
SELECT
path,
content,
_metadata.file_name AS file_name,
_metadata.file_size AS file_size,
_metadata.file_modification_time AS file_modification_time
FROM READ_FILES(
:volume_path,
format => 'binaryFile',
fileNamePattern => '*.{pdf,PDF}'
)
-- 100MB 制限ガード
WHERE _metadata.file_size < 100000000;
✅ Step 4: Silver - ai_parse_document でパース 🥈✨
PDF (BINARY) を入力すると、VARIANT 型の構造化データを返します。
CREATE OR REPLACE TABLE IDENTIFIER(:t_parsed) AS
SELECT
path,
file_name,
file_size,
ai_parse_document(
content,
map(
'version', '2.0',
'imageOutputPath', :image_volume_path,
'descriptionElementTypes', '*'
)
) AS parsed
FROM IDENTIFIER(:t_raw);
🔍 element の中身を確認
type の取りうる値:
-
text/title/section_header/table/figure/caption/page_header/page_footer/page_number/footnote
⚠️ 重要: 「table」要素の content は HTML 形式で返ってきます (
ai_parse_documentv2.0)。これがあとでai_prep_searchの HTML テーブル分断問題の原因になります 💀
🧹 成功 / 失敗で分割
-- 成功: error_status が NULL のもの
CREATE OR REPLACE TABLE IDENTIFIER(:t_clean) AS
SELECT path, file_name, parsed
FROM IDENTIFIER(:t_parsed)
WHERE try_cast(parsed:error_status AS STRING) IS NULL;
-- 失敗
CREATE OR REPLACE TABLE IDENTIFIER(:t_failed) AS
SELECT path, file_name, parsed:error_status AS error_status
FROM IDENTIFIER(:t_parsed)
WHERE try_cast(parsed:error_status AS STRING) IS NOT NULL;
✅ Step 5: 🛡️ HTML テーブル保護プリプロセス (parsed_protected)
ここがハマりポイント対策の 第 1 層 です 🎯
💡 なぜ事前防御が必要?
ai_prep_search に渡す前に、大きな <table> を <tr> 単位で予防的に分割しておくと、後の chunk 中間切断を防げます。
🔰 アナロジー: 引っ越しの段ボール詰め 📦
| 概念 | 例え |
|---|---|
| chunk | 段ボール (容量上限 ~ 7,000 chars) |
| element | 荷物 (本、皿、グラス、絵画) |
| table 要素 | 割れ物 (絵画) |
「絵画 (table) を入れる前に、絵画+周辺の荷物+空き容量を計算し、合計が箱の 85% を超えるなら、絵画を 1 枚目としてだけ入れて、残りは次の箱に回す」
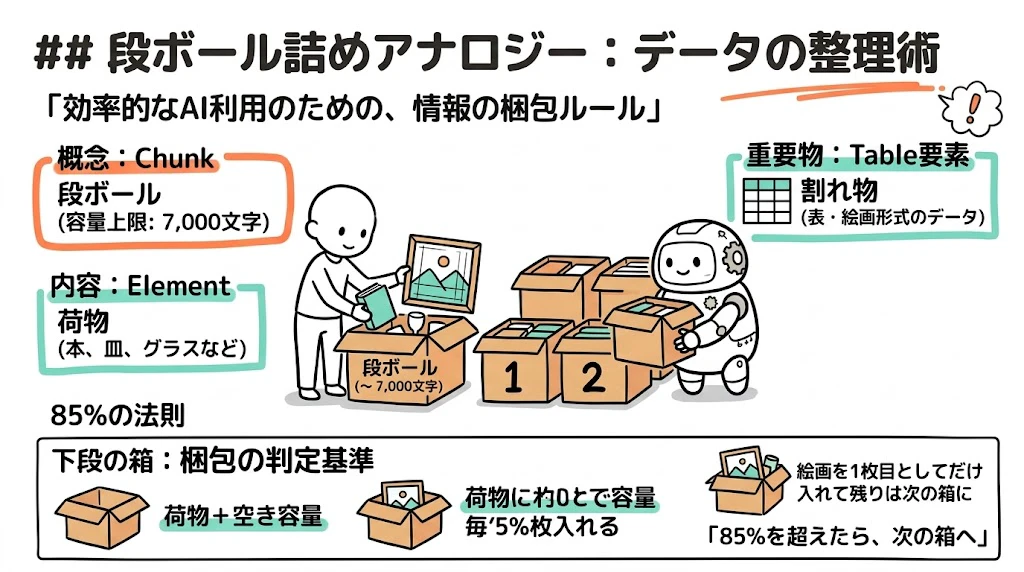
これが vicinity-aware (隣接合算予測) の発想です 🧠
📐 設定値
CHUNK_TARGET_CHARS = 3000 # この閾値超のテーブルを分割
CHUNK_HARD_MAX = 5500 # 絶対上限
CHAR_LIMIT_OBSERVED = 7000 # ai_prep_search の観測上限
VICINITY_TRIGGER_PCT = 0.85 # 周辺合算がこの割合超なら分割
VICINITY_WINDOW = 2 # 直前N + 直後N
VICINITY_EXCLUDE_TYPES = {"page_header", "page_footer", "page_number"}
🧠 段1-A: vicinity 圧力計算
def compute_vicinity_pressure(elements, target_idx, window=VICINITY_WINDOW):
"""
target_idx 番目の element について、その前後 window 個 + 自身 の合算 char 数を返す。
なぜ必要か:
ai_prep_search は複数 elements を貪欲に合算してチャンクを作る (推測)。
target が table 要素のとき、周辺との合算サイズが char 上限に近づくと
合算チャンク内でテーブル中間切断が起きる。
"""
if not elements or target_idx < 0 or target_idx >= len(elements):
return 0
start = max(0, target_idx - window)
end = min(len(elements), target_idx + window + 1)
total = 0
for i in range(start, end):
el = elements[i]
if isinstance(el, dict):
etype = el.get("type", "")
if i != target_idx and etype in VICINITY_EXCLUDE_TYPES:
continue
total += len(el.get("content") or "")
return total
🪚 段1-B: HTML テーブル分割
def split_large_html_table(html_str, target=CHUNK_TARGET_CHARS, row_batch=15):
"""
大きな <table> を「caption + thead + tbody の N 行ずつ」のサブテーブルに分割。
各サブテーブルには caption と thead が複製され、それぞれが完結した HTML として valid。
"""
if html_str is None or len(html_str) <= target:
return [html_str] if html_str else []
soup = BeautifulSoup(html_str, "lxml")
table = soup.find("table")
if table is None:
return [html_str]
caption = table.find("caption")
thead = table.find("thead")
tbody = table.find("tbody") or table
rows = tbody.find_all("tr", recursive=False)
if not rows:
# <tr> 構造を持たないフラット HTML テーブルへの fallback
return _fallback_string_split(html_str, target)
# 🌟 caption と thead を全分割片に複製する
# → 各サブテーブル単独でも「何の表の何の列か」が分かる ✨
chunks = []
for i in range(0, len(rows), row_batch):
batch_rows = rows[i:i + row_batch]
parts = ['<table border="1">']
if caption is not None: parts.append(str(caption))
if thead is not None: parts.append(str(thead))
parts.append("<tbody>")
parts.extend(str(tr) for tr in batch_rows)
parts.append("</tbody></table>")
chunks.append("".join(parts))
return chunks
💡 「caption と thead を複製する」のなぜ?
これがないと、分割された 2 番目以降のサブテーブルには「Transformer (base) は 27.3」のような数値だけが並んで 「何の表の何の列か分からない」状態になります 👻
caption と thead を複製することで、各サブテーブル単独でも完結した意味を持ちます ✨ これは Anthropic Contextual Retrieval の思想とも整合的 🧠
🪄 Spark UDF として登録 → parsed_protected を作成
@F.udf(returnType=StringType())
def process_elements_udf(elements_json):
return process_elements(elements_json)
(spark.table(T_CLEAN)
.withColumn("elements_json_orig",
F.expr("to_json(parsed:document:elements)"))
.withColumn("elements_json_protected",
process_elements_udf(F.col("elements_json_orig")))
.withColumn("parsed_protected",
F.expr("""
parse_json(
to_json(named_struct(
'document', named_struct(
'pages', parsed:document:pages,
'elements', parse_json(elements_json_protected)
),
'error_status', parsed:error_status,
'metadata', parsed:metadata
))
)
"""))
.write.mode("overwrite").saveAsTable(T_PROTECTED))
✅ Step 6: ai_prep_search でチャンク化 🪄✂️
🎯 Q3 / Q4 への回答(最重要)
❓ Q3. セマンティックチャンキングを使うときの options は?
A. 公式マニュアルでサポートされる options のキーは 'version' のみ。セマンティックチャンキングはデフォルト動作として常に有効 です ✨
-- パターン1: options 省略形 (推奨)
SELECT ai_prep_search(parsed) AS result FROM parsed_clean;
-- パターン2: 出力スキーマバージョンを明示指定
SELECT ai_prep_search(parsed, map('version', '1.0')) AS result FROM parsed_clean;
❓ Q4. オーバーラップは設定できる?
A. 公式マニュアルに chunk_overlap 関連 option の記載は一切なし。実測でも overlap=0 の挙動です ✂️
必要なら SQL の LAG() Window 関数で後付け するのが現実解です。
-- 隣接 chunk の末尾 200 文字を現在 chunk の冒頭にコピー
SELECT
COALESCE(
SUBSTRING(LAG(chunk_retrieve) OVER (PARTITION BY file_name ORDER BY chunk_index), -200, 200),
''
) || chunk_retrieve AS chunk_with_overlap
FROM chunks_merged;
🪄 chunks テーブル作成
CREATE OR REPLACE TABLE IDENTIFIER(:t_chunks) AS
WITH prepped AS (
SELECT path, file_name, ai_prep_search(parsed) AS result
FROM IDENTIFIER(:t_protected)
),
exploded AS (
SELECT
chunk:chunk_id::STRING AS chunk_id,
path, file_name,
chunk:chunk_position::INT AS chunk_index,
chunk:chunk_to_embed::STRING AS chunk_text, -- 埋め込み用 ✨
chunk:chunk_to_retrieve::STRING AS chunk_retrieve, -- 検索結果用
to_json(chunk:pages) AS chunk_pages_json,
-- ⚠️ contents[].pages[] は page_id (document.pages[] は id なので注意!)
try_cast(
transform(
try_cast(chunk:pages AS ARRAY<STRUCT<page_id: INT, image_uri: STRING>>),
x -> x.page_id
) AS ARRAY<INT>
) AS page_ids_array,
result:document:source_uri::STRING AS source_uri,
current_timestamp() AS created_at
FROM prepped
LATERAL VIEW posexplode(try_cast(result:document:contents AS ARRAY<VARIANT>)) AS chunk_idx, chunk
WHERE chunk:chunk_to_embed IS NOT NULL
)
SELECT
chunk_id, path, file_name, chunk_index, chunk_text, chunk_retrieve, chunk_pages_json,
page_ids_array,
array_join(transform(page_ids_array, x -> CAST(x AS STRING)), ',') AS page_ids,
array_min(page_ids_array) AS page_id_min,
array_max(page_ids_array) AS page_id_max,
size(page_ids_array) AS num_pages_in_chunk,
source_uri, created_at
FROM exploded;
⚠️ スキーマの罠: page_id vs id
公式マニュアルをよく読むと:
| 場所 | フィールド名 |
|---|---|
result:document.contents[].pages[] |
page_id ✅ |
result:document.pages[] (トップレベル) |
id ⚠️ |
同じ pages 配列でもネスト位置で field 名が違います 🪤
📊 比較用に保護なし版も作成
-- 保護プリプロセスの効果を数値で比較するため、保護なしも保存
CREATE OR REPLACE TABLE IDENTIFIER(:t_chunks_raw) AS
WITH prepped AS (
SELECT path, file_name, ai_prep_search(parsed) AS result
FROM IDENTIFIER(:t_clean) -- ← parsed_clean (保護なし)
)
... 同様 ...
✅ Step 7: チャンク前後の比較 (パース後 vs チャンク化後) 🔬
📊 量的比較
WITH parsed_stats AS (
SELECT
file_name,
size(try_cast(parsed:document:elements AS ARRAY<VARIANT>)) AS num_elements,
size(try_cast(parsed:document:pages AS ARRAY<VARIANT>)) AS num_pages,
aggregate(
try_cast(parsed:document:elements AS ARRAY<VARIANT>),
0L,
(acc, x) -> acc + COALESCE(length(x:content::STRING), 0)
) AS total_raw_text_len
FROM IDENTIFIER(:t_clean)
),
chunk_stats AS (
SELECT
file_name,
COUNT(*) AS num_chunks,
SUM(length(chunk_text)) AS total_embed_text_len,
SUM(length(chunk_retrieve)) AS total_retrieve_text_len,
ROUND(AVG(length(chunk_text))) AS avg_embed_len,
MAX(length(chunk_text)) AS max_embed_len,
CONCAT('p.', MIN(page_id_min), '-p.', MAX(page_id_max)) AS chunk_page_range
FROM IDENTIFIER(:t_chunks)
GROUP BY file_name
)
SELECT
p.file_name AS file,
p.num_pages,
p.num_elements,
c.num_chunks,
ROUND(CAST(p.num_elements AS DOUBLE) / c.num_chunks, 2) AS elements_per_chunk,
c.avg_embed_len,
c.chunk_page_range,
ROUND(CAST(c.total_retrieve_text_len AS DOUBLE) / NULLIF(p.total_raw_text_len, 0), 2) AS retrieve_coverage,
ROUND(CAST(c.total_embed_text_len AS DOUBLE) / NULLIF(c.total_retrieve_text_len, 0), 2) AS embed_expansion
FROM parsed_stats p LEFT JOIN chunk_stats c USING (file_name);
📖 読み方:
elements_per_chunk > 1.0= 複数 element がまとめられて 1 chunk に(意味的結合の証左)embed_expansion 1.10〜1.30= メタプレフィックスが ~30% 分付与されている
✅ Step 8: チャンク戦略の検証 🔬
🔬 検証1: メタプレフィックスを観察
chunk_to_embed には公式テンプレートに従って固定プレフィックスが付きます:
The following passage represents a chunk of content from a document.
- 'Content' contains raw document text
...
Document Title: ...
Section Header: ...
Page Number: ...
Content:
...本文...
⚠️ Beta 期間の罠: hierchical typo
公式 docs では hierarchical information ですが、Beta 版実装では hierchical (h が 1 つ少ない typo) で返ってきます 🤦
# 両方のスペルを許容する regex
import re
re.search(r'hier(?:archical|chical)\s+information', chunk_to_embed)
🔬 検証2: チャンク間オーバーラップの有無
WITH paired AS (
SELECT
file_name,
chunk_index AS curr_idx,
substring(chunk_retrieve, GREATEST(length(chunk_retrieve) - 99, 1), 100) AS curr_tail,
LEAD(substring(chunk_retrieve, 1, 100)) OVER (
PARTITION BY file_name ORDER BY chunk_index
) AS next_head
FROM IDENTIFIER(:t_chunks)
)
SELECT
curr_tail, next_head,
CASE
WHEN next_head IS NULL THEN '(最終チャンク)'
WHEN curr_tail = next_head THEN '🔄 完全一致 (overlap あり)'
WHEN instr(curr_tail, substring(next_head, 1, 30)) > 0 THEN '⚠️ 部分一致'
ELSE '✂️ 不連続 (overlap なし)'
END AS overlap_status
FROM paired;
📊 実測結果: 全 187 ペアすべて 「✂️ 不連続 (overlap なし)」 ✂️
🔬 検証3: ページまたぎチャンクの数
SELECT
file_name,
num_pages_in_chunk,
COUNT(*) AS num_chunks,
ROUND(100.0 * COUNT(*) / SUM(COUNT(*)) OVER (PARTITION BY file_name), 1) AS pct_in_file
FROM IDENTIFIER(:t_chunks)
GROUP BY file_name, num_pages_in_chunk
ORDER BY file_name, num_pages_in_chunk;
📊 実測: 70-92% がページまたぎ = ai_prep_search は物理ページ境界を意図的に無視して論理構造を優先 🧠
🔬 検証4: HTML テーブル中間分断検出
SELECT
file_name, chunk_index, page_ids,
CASE
WHEN chunk_retrieve RLIKE '^\\s*>' THEN '🚨 LIKELY-BROKEN: > で開始'
WHEN chunk_retrieve RLIKE '^\\s*</[a-zA-Z]+>' THEN '🚨 LIKELY-BROKEN: 閉じタグで開始'
WHEN chunk_retrieve RLIKE '^\\s*<td[\\s>]' THEN '⚠️ SUSPECT: <td> で開始'
WHEN chunk_retrieve RLIKE '^\\s*<tr[\\s>]' THEN '⚠️ SUSPECT: <tr> で開始'
WHEN chunk_retrieve RLIKE '^\\s*[a-z]+>' THEN '🚨 LIKELY-BROKEN: タグ末尾片で開始'
WHEN chunk_retrieve RLIKE '^\\s*<table' THEN '✅ OK: <table から開始'
WHEN chunk_retrieve RLIKE '^\\s*[A-Za-z0-9]' THEN '✅ OK: 通常テキスト'
ELSE '❓ UNKNOWN'
END AS table_split_status
FROM IDENTIFIER(:t_chunks);
💀 切断の例
chunk[N] 末尾: ... <table border="1"><thead><tr><th>Model</th>...
chunk[N+1] 冒頭: > 27.3</td></tr><tr><td>Transformer (big)...
↑↑↑
この `>` 単独で始まる chunk = 切断の証拠 🚨
📊 検証4-α: 保護プリプロセスの定量効果
| 指標 | ①保護なし | ②保護あり | 差分 |
|---|---|---|---|
| total_chunks | 191 | 191 | ±0 |
| orphan_close_table | 10 | 6 | -40% ✅ |
| unbalanced_table | 39 | 36 | -3 |
| avg_retrieve_len | 4,087 | 4,114 | +27 |
💡 保護プリプロセス単体では一部の指標で改善幅が小さいですが、Step 9 の事後修復と組み合わせる ことで効果が爆発します 💥
✅ Step 9: 🧩 後処理: 切れた HTML テーブルを SQL で結合 (chunks_merged)
ここが本記事の真骨頂です 🎯
🔰 アナロジー: 破れた紙幣の修復 💵
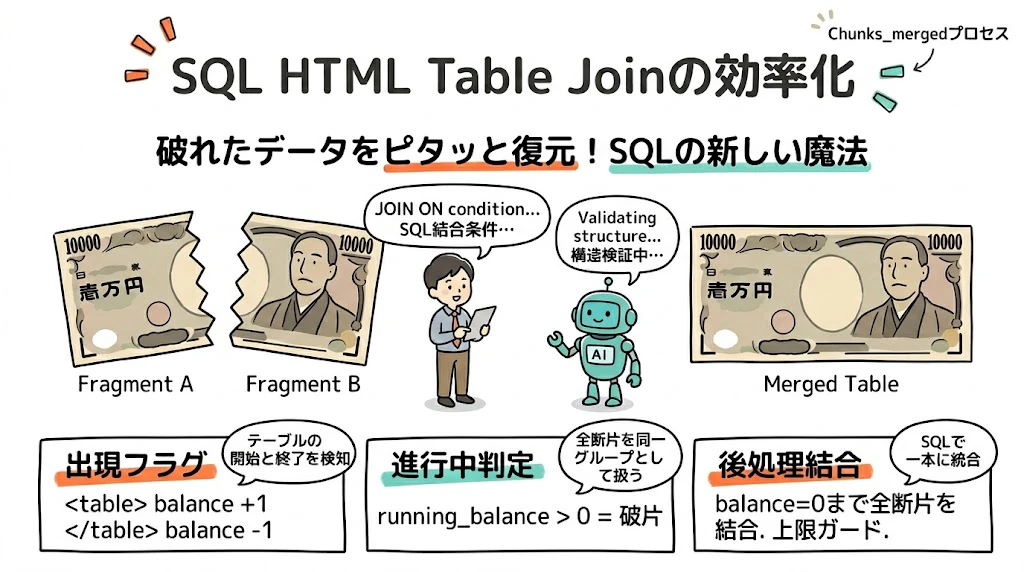
| 概念 | 例え |
|---|---|
<table[\s>] 出現 |
紙幣を破り始めた瞬間(balance を +1) |
</table> 出現 |
紙幣を破り終えた瞬間(balance を -1) |
running_balance > 0 |
まだ破れた紙幣の片を集めている最中 |
| 後処理結合 | balance がゼロに戻るまで全片をテープでつなげる作業 🩹 |
| 上限ガード | 紙幣束が分厚くなりすぎたら次の束に分ける 📦 |
📋 結合判定アルゴリズム (累積バランス方式)
各 chunk c[i] について:
open_count[i] := regexp_count(c[i], '<table[\s>]') ※偽陽性除去
close_count[i] := regexp_count(c[i], '</table>')
running_balance[i] := SUM(open_count[k] - close_count[k]) for k in 0..i
needs_merge[i] := (running_balance[i-1] > 0) OR (c[i] が断片で開始)
merge_group[i] := SUM(CASE WHEN needs_merge[i] THEN 0 ELSE 1 END) OVER (順序ウィンドウ)
上限ガード:
break_flag[i] := (prev_running_chars[i] + self_chars[i] > MAX_MERGED_CHARS)
OR (prev_running_count[i] + 1 > MAX_MERGED_CHUNKS)
sub_group_id := SUM(break_flag) OVER (...)
🚀 N chunks にまたがる超大型テーブルでも結合できる仕組み
例: Apple 10-K の Consolidated Financial Statements (5 chunks に切られたケース)
| chunk | open | close | running_balance | prev_running_balance | needs_merge |
|---|---|---|---|---|---|
| n | 1 | 0 | 1 | 0 | FALSE (グループ起点) |
| n+1 | 0 | 0 | 1 (引継ぎ) | 1 | ✅ TRUE → n と結合 |
| n+2 | 0 | 0 | 1 | 1 | ✅ TRUE → n と結合 |
| n+3 | 0 | 0 | 1 | 1 | ✅ TRUE → n と結合 |
| n+4 | 0 | 1 | 0 | 1 | ✅ TRUE → n と結合 |
| n+5 | 0 | 0 | 0 | 0 | FALSE (次のグループ起点) |
5 chunks すべてが同じ merge_group に入り、1 チャンクに統合 ✨
🌟 実装 SQL のコア部分
WITH counted AS (
SELECT
chunk_id, file_name, chunk_index, chunk_retrieve,
-- 偽陽性除去: <tablespoon, <tablename を <table と誤マッチさせない
regexp_count(chunk_retrieve, '<table[\\s>]') AS open_count,
regexp_count(chunk_retrieve, '</table>') AS close_count,
(
chunk_retrieve RLIKE '^\\s*>'
OR chunk_retrieve RLIKE '^\\s*</[a-zA-Z]+>'
OR chunk_retrieve RLIKE '^\\s*[a-z]+>'
) AS self_starts_with_fragment,
length(chunk_retrieve) AS self_chars
FROM chunks
),
balance AS (
SELECT *,
SUM(open_count - close_count) OVER (
PARTITION BY file_name ORDER BY chunk_index
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS running_balance
FROM counted
),
flagged AS (
SELECT *,
COALESCE(LAG(running_balance) OVER (PARTITION BY file_name ORDER BY chunk_index), 0)
AS prev_running_balance,
(COALESCE(LAG(running_balance) OVER (PARTITION BY file_name ORDER BY chunk_index), 0) > 0
OR self_starts_with_fragment) AS needs_merge_with_prev
FROM balance
),
prelim AS (
SELECT *,
SUM(CASE WHEN needs_merge_with_prev THEN 0 ELSE 1 END)
OVER (PARTITION BY file_name ORDER BY chunk_index
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS prelim_merge_group
FROM flagged
)
-- 上限ガード適用 → 最終結合
SELECT
file_name,
MIN(chunk_index) AS chunk_index,
-- chunk_index 昇順で連結 (決定的順序を保証)
array_join(
transform(
array_sort(COLLECT_LIST(struct(chunk_index, chunk_retrieve))),
s -> s.chunk_retrieve
),
''
) AS chunk_retrieve,
COUNT(*) AS merged_chunk_count
FROM prelim
GROUP BY file_name, prelim_merge_group;
🛡️ 上限ガードの設定値
| パラメータ | デフォルト | 理由 |
|---|---|---|
MAX_MERGED_CHARS |
28,000 |
databricks-gte-large-en の 8,192 tokens ≈ 30,000 chars に約 7% の安全マージン |
MAX_MERGED_CHUNKS |
8 | 通常テーブルは 5 chunks 以内に収まる実測。安全マージン込み |
🇯🇵 日本語ドキュメント中心の場合: 1 token ≈ 1.5-2 chars 程度になるため、
MAX_MERGED_CHARSを 14,000-18,000 chars に下げるのが安全 🇯🇵
📊 3 段階比較: 保護なし vs 保護あり vs 保護+結合
| 段階 | total | unclosed_table | orphan_close_table | over_closed_table | unbalanced_table |
|---|---|---|---|---|---|
| ①保護なし | 191 | 5 | 10 | 19 | 39 |
| ②保護あり | 191 | 5 | 6 ⬇️ | 20 | 36 |
| ③保護+結合 ✨ | 166 | 1 ⬇️⬇️ | 1 ⬇️⬇️ | 12 | 16 ⬇️⬇️ |
📉 unbalanced_table が 39 → 16 に削減 (59%減) 🎉
💎 結合規模ヒストグラム
| merge_size | 件数 | 解釈 |
|---|---|---|
| 1 | 150 | 元から完結していた chunks |
| 2 | 9 | 2 chunks にまたがるテーブルが結合 |
| 3 | 6 | 3 chunks にまたがる中規模テーブル |
| 5 | 1 | 🌟 Apple 10-K の Consolidated Financial Statements! |
apple_10k_fy2025.pdf の chunk_index=30 は 5 chunks → 1 chunk・20,880 chars に統合 されました 🚀
🛡️ 上限ガード発動状況
| file | total | guard_triggered | max_merge_size | max_retrieve_len |
|---|---|---|---|---|
| apple_10k_fy2025.pdf | 62 | 0 | 5 | 20,880 |
| attention_is_all_you_need.pdf | 12 | 0 | 2 | 7,342 |
| bert.pdf | 17 | 0 | 2 | 7,003 |
| ipcc_ar6_syr_longer_report.pdf | 75 | 0 | 3 | 8,560 |
<table[\s>] パターンによる偽陽性除去のおかげで、今回のデータセットでは guard 発動 0 件 ✨
🔬 おまけ: fixed-size との比較
ai_prep_search のセマンティックチャンキングが fixed-size より本当に良いのか確認:
FIXED_SIZE = 1500
FIXED_OVERLAP = 200
@F.udf(returnType=ArrayType(StructType([
StructField("idx", IntegerType()),
StructField("text", StringType()),
])))
def fixed_size_chunk(text):
if not text:
return []
chunks, i, idx = [], 0, 0
n = len(text)
while i < n:
chunks.append({"idx": idx, "text": text[i: i + FIXED_SIZE]})
i += FIXED_SIZE - FIXED_OVERLAP
idx += 1
return chunks
🧐 解釈: 学術ベンチマーク (arXiv:2410.13070) は「semantic chunking の computational cost は consistent な性能向上で正当化されない」と結論。用途次第なので、自分のクエリ・データセットで A/B テストするのが正しいです 🎯
✅ Step 10: チャンク統計を可視化 📊
import plotly.express as px
pdf = (
spark.table(T_CHUNKS)
.filter("chunk_text IS NOT NULL AND length(chunk_text) > 0")
.selectExpr("file_name", "length(chunk_text) AS chunk_len")
.toPandas()
)
# ファイル別チャンク数
counts = pdf.groupby("file_name").size().reset_index(name="chunks")
fig1 = px.bar(counts, x="file_name", y="chunks",
title="📚 ファイル別チャンク数 (semantic)")
fig1.show()
# チャンク長ヒストグラム
fig2 = px.histogram(pdf, x="chunk_len", nbins=30,
title="✂️ チャンク長分布 (文字数, semantic)")
fig2.show()
✅ Step 11: コスト確認 💰
SELECT
usage_date,
product_features.ai_functions.ai_function AS ai_function,
SUM(usage_quantity) AS dbus
FROM system.billing.usage
WHERE billing_origin_product = 'AI_FUNCTIONS'
AND product_features.ai_functions.ai_function IN ('AI_PARSE_DOCUMENT', 'AI_PREP_SEARCH')
AND usage_date >= current_date() - INTERVAL 7 DAYS
GROUP BY usage_date, product_features.ai_functions.ai_function
ORDER BY usage_date DESC;
⚠️ 注意:
ai_prep_searchは Beta 期間中、system.billing.usageに記録されない可能性が高い です。GA 化時の有料化に備えて、ai_parse_documentと同水準のバッファを月次予算に確保しておきましょう 💼
🎁 まとめ: 本番投入チェックリスト
📐 パイプライン全体
| ステップ | 関数 / 処理 | 結果テーブル |
|---|---|---|
| 🥉 Bronze | READ_FILES(binaryFile) |
raw_pdfs |
| 🥈 Silver |
ai_parse_document (GA) |
parsed_documents / parsed_clean
|
| 🛡️ Silver | HTML テーブル保護プリプロセス | parsed_protected |
| 🥈 Silver |
ai_prep_search (Beta) |
chunks |
| 🧩 Silver | 後処理結合 (累積バランス + 上限ガード) |
chunks_merged ✨ |
✅ 投入前
- 想定クエリが「文書要約」中心か「数値比較」中心かを判定 🤔
- 数値比較中心なら本記事ではなく構造化テーブル併用パターンを採用
- 公式マニュアルを再確認 (Beta なので変更リスクあり)
- Runtime 18.2+ または Serverless v3+ であることを確認
-
DESCRIBE FUNCTION EXTENDED ai_prep_searchで関数の存在を確認
✅ 運用時モニタリング
| 指標 | 閾値 | 対処 |
|---|---|---|
🚨 unclosed_table 件数 |
急増時 | 入力 PDF 点検 |
🚨 orphan_close_table 件数 |
急増時 | 同上 |
🛡️ guard_triggered_count
|
急増時 | ネスト table の有無確認 |
📊 integrity_score < 0.7 件数 |
週次集計 | element 単位で逆突合 |
💰 system.billing.usage (AI_PARSE_DOCUMENT) |
週次確認 | コスト監視 |
🔮 まとめのまとめ
| ✨ 学び | 詳細 |
|---|---|
| 🎯 公式仕様を最初に正確に把握する | サポート options が 'version' だけだと知らずに chunk_overlap を期待すると大幅な手戻り発生 |
| 🪤 Beta 関数のマーケ文言を信じすぎない | 「セマンティックチャンキング」と書いてあってもテーブル不分断は保証されない |
| 🛡️ 二段防御でケアする | 事前防御 (parse 直後) + 事後修復 (SQL Window) の組み合わせ |
| 💵 上限ガード必須 | 暴走的結合を予防する保険として常時稼働 |
| 📊 実測値で語る | 推測ではなく regexp_count + Window 関数で定量モニタリング |
📚 参考リンク
| URL | 内容 |
|---|---|
🌟 ai_prep_search 公式 (Microsoft Learn ja-jp)
|
本記事の一次情報 (Last updated 2026-04-17) |
📖 ai_parse_document 公式
|
パース関数の仕様 |
| 📰 April 2026 リリースノート |
ai_prep_search Beta 公開 (4/8/2026) |
| 🧠 Anthropic Contextual Retrieval | 各 chunk に context prefix を加える手法 |
| 🛠️ Unstructured.io chunking spec | "Table element is always isolated" |
| 🔗 LangChain HTMLSemanticPreservingSplitter | テーブル保持型 splitter |
| 📊 Databricks Vector Search 品質ガイド | parsing 品質が retrieval 精度に与える影響 |
🙏 最後に
この記事が 同じ罠で頭を抱える誰か の役に立てば嬉しいです 🥲
ベータ機能を実測値ベースで評価する文化が広まってほしい...🙏
質問・補足・「俺の環境ではこうだった」のフィードバック、コメント欄でお待ちしています 💬
いいねとストックよろしくお願いします! 🎉🎉🎉
🐰 追記 (2026-04-30): 本記事は
ai_prep_searchBeta 期間中の検証です。GA 化時に options 追加・スキーマ変更が起こる可能性があります。本番投入前に必ず公式 docs を再確認してください 📌