この記事は、LIFULL Advent Calendar 2017の14日目の記事です。
つくば市から半蔵門まで通っているikedaosushiです。
ChatworkがWebhookに対応したので、週末にAWS・GCPなどを使ってだじゃれ/翻訳/感情極性値/会話/ストロングゼロ文学化のマルチタスクbotを作ってみました。技術的な観点としてはChatworkWebhookとServerlessのTipsを使い方を解説します。
はじめに
ChatworkWebhook
先日(2017-11-1)、ChatworkがOAuthとWebhookに対応しました。
OAuthとWebhookに対応し、オープンβ版として一般公開を開始! | ChatWorkブログ
http://blog-ja.chatwork.com/2017/11/api-openbeta.html
今まではChatworkで対話botを作るにはポーリングで実現するしかなく、5分間100回というAPI制限もあり涙ぐましい努力で実現するしかありませんでした。今回、Webhookに対応したということで、動作の確認のためにChatbotを作ってみたいと思います。
ストロングゼロ文学
下記のようなTweetのように名作にストロングゼロを入れると恍惚になる、というものです。今回は名作ではなく、普段の会話をストロングゼロ化してみたいと思います。
メロスは激怒した。必ず、かの邪智暴虐の王を除かなければならぬと決意した。メロスには政治がわからぬ。メロスは村の無職である。笛を吹きストロングゼロを飲んで暮して来た。飲んだら激怒が消えた。王様とかどうでもよくなった。走る気力もなくなった。セリヌンティウスは死んだ#ストロングゼロ文学
— Rootport (@rootport) 2017年12月7日
ServerlessFramework
バックエンドにはLambda&API Gateway、フレームワークはServerlessFramework(以下Serverless)を用いました。久々にServerlessを使ったのですが、色々便利な機能が追加されていたのでそちらを重点的に紹介したいと思います。
やったこと
先に実現したことを書き、実装等は後半にまとめて書きます。
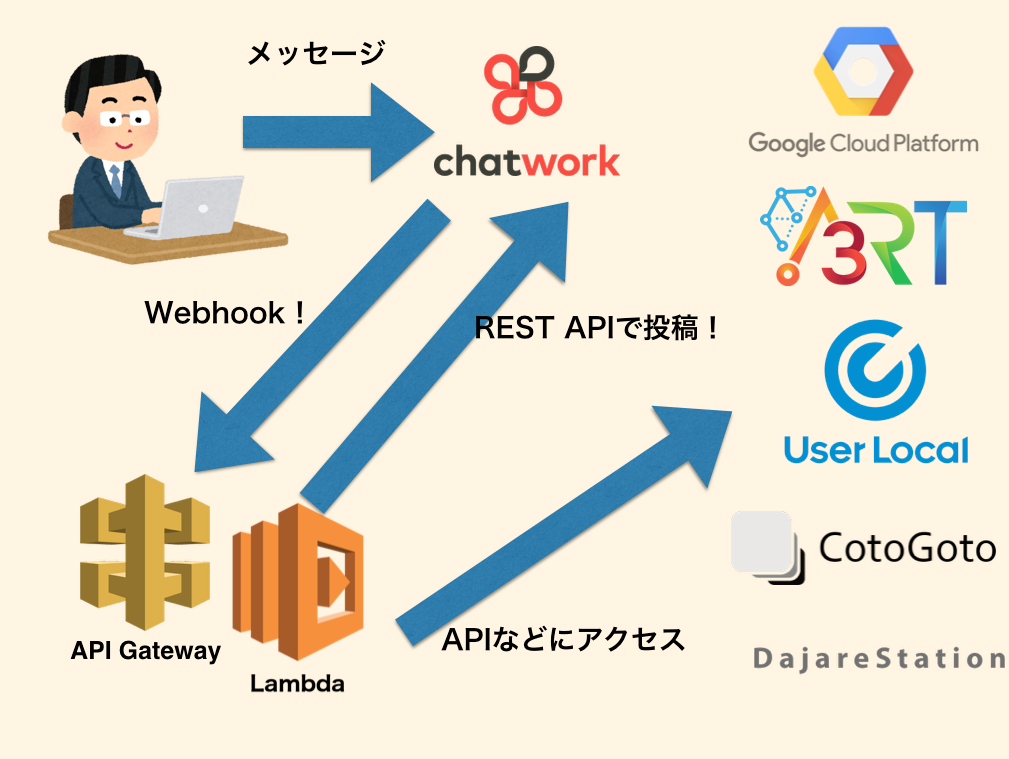
構成図
構成はこんな感じです。API GatewayでWebhookを受けてLambdaが各種API等にアクセスし、得た情報を基にREST APIでChatworkに投稿します。
MagicWord
今回はbot用のアカウントではなく自分のアカウントを用いたため、意図しない返信をbotがしてしまうと大変なことになります。そのため、発言の最初にMagicWordがあったときだけ反応するようにしました。
MagicWordといえば「Hey, Alexa」「OK, Google」なので、それにあやかって「へい大将」に設定しました。引数なしで呼びかけると下記のように使い方が表示されるようにします。
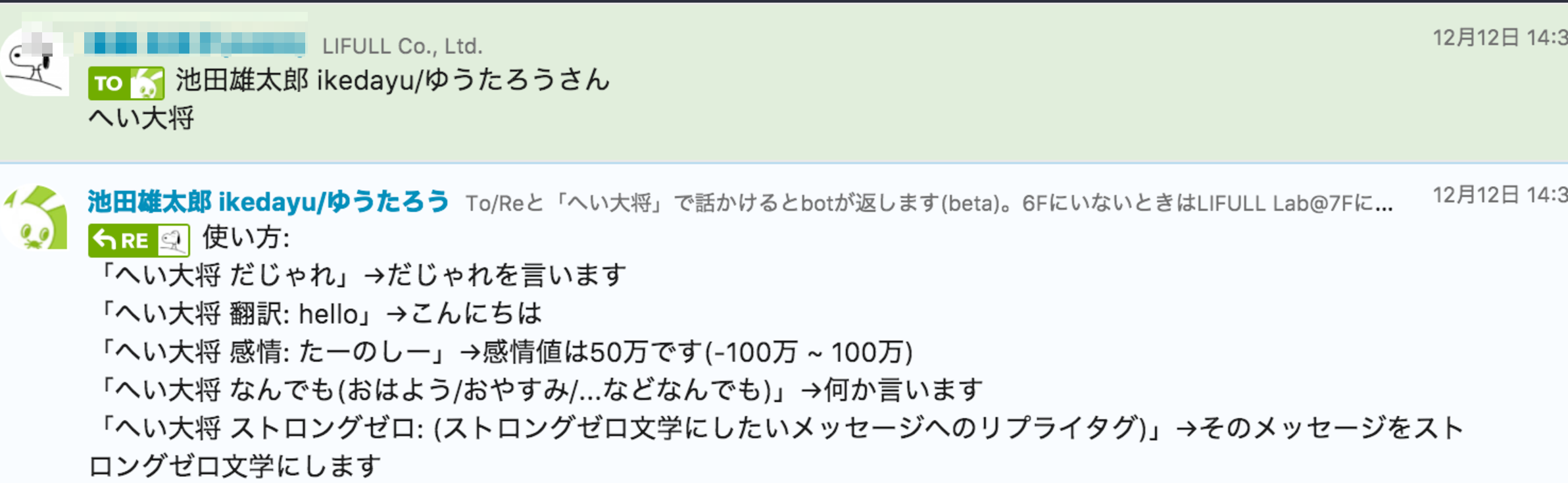
上記の画像の通り以下のような機能を付けました
- だじゃれ
- 翻訳
- 感情極性値分析
- 会話
- ストロングゼロ文学化
それでは一つ一つ機能を見ていきたいと思います。
翻訳
GCPのTranslate APIを使いました。AWS LambdaからGCPを使うのってどうなんだろう…と思ったのですが、AWS Translateが日本語に対応してくれないのでいいんです(拗ね)
英語などから日本語に翻訳してくれます。
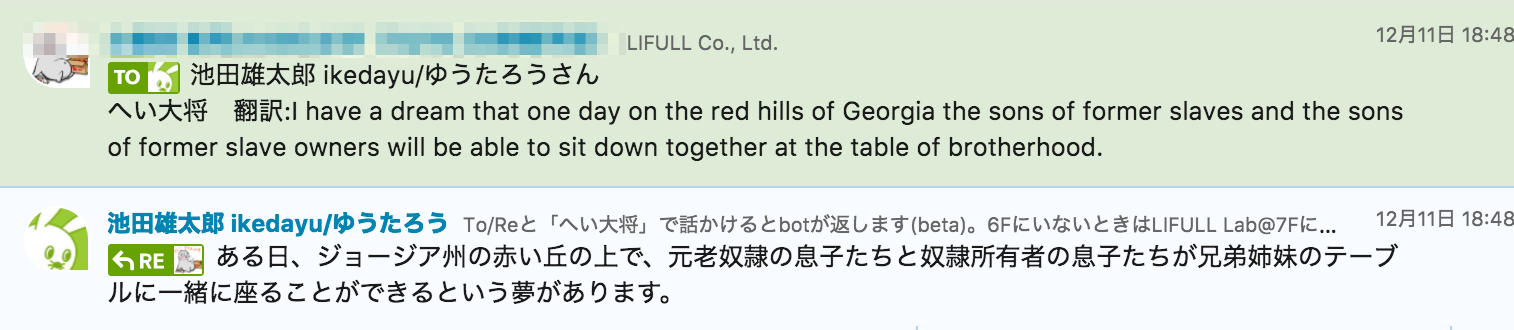
ランチの時間でみんなでCouseraのDeepLearningを見ているのですがそこで便利に使えました。

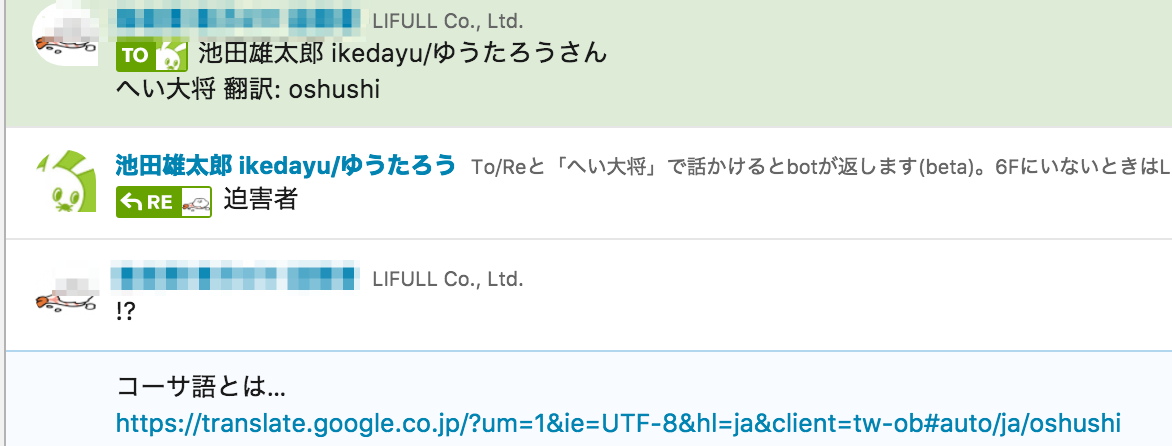
Translate APIは言語を自動で判定してくれるので、イタリア語もこのように翻訳してくれます。
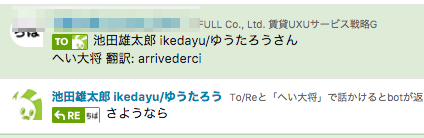
完全に豆知識ですが「oshushi」がコーサ語で「迫害者」だったことを始めて知りました。
感情極性値
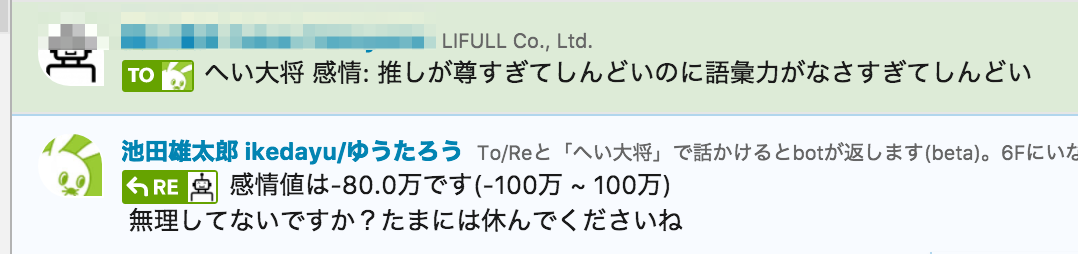
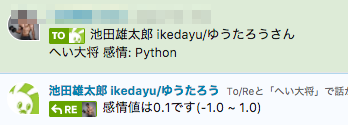
こちらもGCPのNatural Language API:analyzeSentimentを使います。デフォルトの極性値が-1.0 ~ 1.0なのですが、これだとあまり大きさが伝わらないので-100万 ~ 100万で表示してみました。

また極度に極性値が低いと慰めてくれる機能や極性値が53万のときだけフリーザ様の口調になる機能もつけてみましたが、正直いりませんでした。笑
感想としては、APIが基本的にセンテンスベースで極性値を出す想定になっているようなのですが、みんなはだいたい「ボーナス」とか「ディープラーニング」とか言ってくるので「-0.1~0.1」くらいになってしまいあんまり面白みがなかったかなと思いました。
会話
会話ですが、世の中にあるこちらもAPIを使います。
世の中にはなんでもAPIがあって簡単簡単…といけばいいのですが、僕が知る限り会話botにはこの問題がつきまといます。
それは「会話のバリエーションが全然ない!」ことです。
 当初、こんな感じで、「そうですね」「あなたはよくするんですか?」を連発してしまい、みんなに「だめだこいつ…」と思わせてしまいました。
当初、こんな感じで、「そうですね」「あなたはよくするんですか?」を連発してしまい、みんなに「だめだこいつ…」と思わせてしまいました。
以前、勉強でEncoderDecoderモデルで会話を学習させてbotを作ってみたときも「うん…」「そうだね」「(笑)」のようなあまりにコミュ障な結果が帰ってきて、まるで自分を見ているようで辛い気持ちになったことを思い出しました。
この問題に関してはいろんな解決策があると思うのですが、今回は手っ取り早く解決したかったので「複数のAPIを用意しておいてランダムに呼びに行く」を実践してみることにしました。結論から言うと悪くなかったです。やはり確率は世界を救います。
使うAPIはこの記事を参考にすぐに使えそうで無料で使えるものを選びました。
BOTで使える会話API・ライブラリ・サービスまとめ
https://qiita.com/kenzo0202/items/582e3a5e06b64ab24964
- UserLocal
- A3RT
- Cotogoto
便利なAPIを提供いただき、ありがとうございます。
こちらが結果の一部ですが、このように同じワードを話しかけられてもいい感じにバリエーションが出るようになりました。(答えの精度は置いておいて)
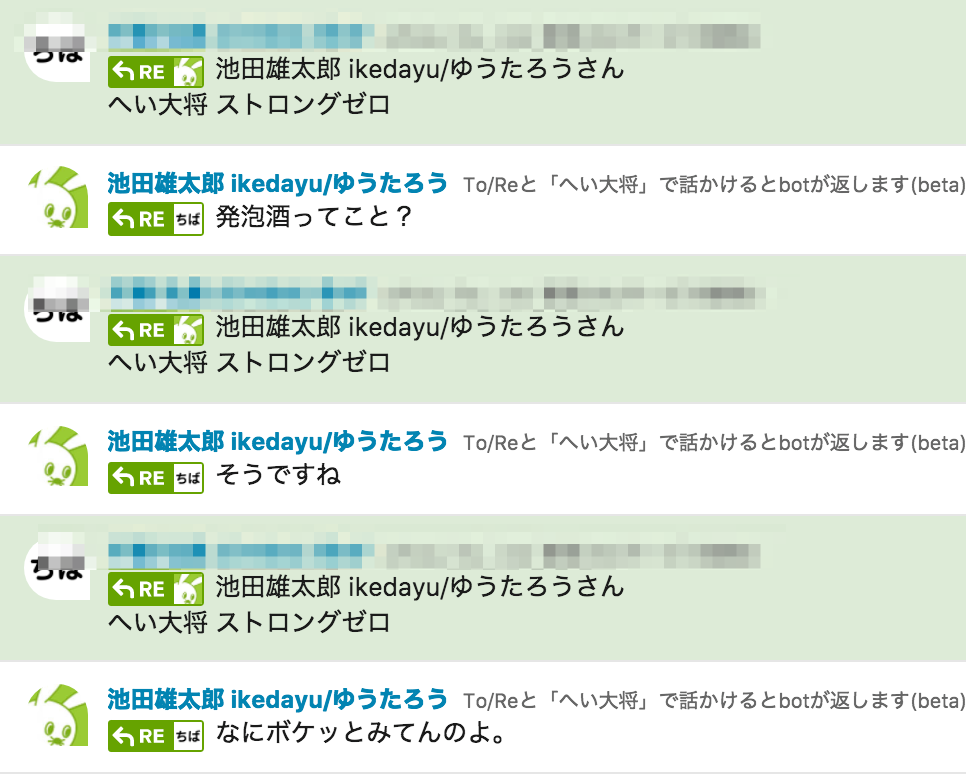
こんな単純なことなんですが、ありがちな「bot感」が薄れて会話も弾むようになり、コミュ障から少し脱却できたような気がしました。ただ最後に急に女子っぽい感じになってしまったりと、長期的に運用していく上では多重人格っぽく見えないように注意が必要かもしれません。
だじゃれ
ランダムにだじゃれを言ってくれる機能です。
浅学で存じなかったのですが、世の中にはだじゃれ専門サイト だじゃれステーションというものがあり、たくさんの素晴らしいだじゃれが投稿されています。
「へい大将 だじゃれ」と言われるとこのサイトにHTTPリクエストを送りランダムに1つだじゃれを仕入れて投稿します。
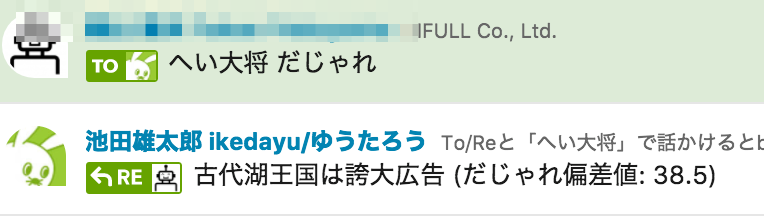
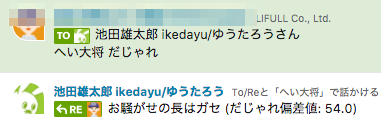
一発ネタのつもりだったのですが、「疲れたときに見たくなる」と意外と好評でした。
ストロングゼロ文学化
と、ここまでは、いろんな方がChatbotでやられていることだったので、
何かみなさんがあまりやったことがなさそうなこともやりたい(やらないとネタにならない)と思いました。
というわけで、実験的な試みとして「ストロングゼロ文学化bot」を作ってみました
仕組み
- メッセージをGCPのNatural Language API:analyzeSyntaxを使って形態素解析する
- ストロングゼロに置き換えても違和感がなさそうな名詞を一定の確率で「ストロングゼロ」にする
超シンプルです。形態素解析するにあたってはMecabをデプロイする方法などもありますが、デプロイ当たりの時間がかかってしまうのと手早く進めたかったのでAPIを利用しました。固有名詞の抽出において辞書のチューニングが行えないので、固有ドメインに対して利用する場合は注意が必要です。
「ストロングゼロ」に変換するルール
- Chatwork的にシマンテックな文字列でない([info][/info][title][/title]など)
- 名詞である
- 1つ前の名詞がストロングゼロに変換されていない
- DependencyEdge:LabelがADVPHMODかROOTである
後述しますが、DependencyEdge:Labelがかなりわかりにくく、演繹的よりかは帰納的にこのLabelを選んでみました。
https://cloud.google.com/natural-language/docs/reference/rest/v1beta2/Token?hl=ja#DependencyEdge
一応ADVPHMODが副詞句修飾子、ROOTはrootとか書いてなく正直わかっていないので誰かご存じの方教えていただければ幸いです。木構造でのrootということでしょうか。
結果
こんな感じになります。(村上春樹/羊をめぐる冒険より)


村上春樹ファンの皆様申し訳ございません。
冒頭のストロングゼロ文学で使われていたメロスに適応するとこんな感じになります


動詞としてストロングゼロが使われてしまったり、ちょっとまだかなり粗い感じがしますが、選択する名詞の種類とストロングゼロに変換される確率をチューニングしていくことで良くなる可能性はあると思います。
実装ついて
それでは実際の実装について見ていきます。
環境構築
環境
下記の環境が準備されていることを前提に進めて行きます。
もし環境がない方は下記URLなどを参考に環境を構築してください。
- AWS(Lambda, ApiGateway)
- GCP(Cloud Natural Language)
- ServerlessFrameWork
- Python
Versions
$ python --version
Python 3.6.3
$ sls --version
1.26.0
Serverlessでプロジェクトを作成
下記コマンドで新規作成しましょう
$ sls create -t aws-python3 -n chatbot -p chatbot
Serverless: Generating boilerplate...
Serverless: Generating boilerplate in "mypath"
_______ __
| _ .-----.----.--.--.-----.----| .-----.-----.-----.
| |___| -__| _| | | -__| _| | -__|__ --|__ --|
|____ |_____|__| \___/|_____|__| |__|_____|_____|_____|
| | | The Serverless Application Framework
| | serverless.com, v1.24.1
-------'
Serverless: Successfully generated boilerplate for template: "aws-python3"
PythonPackages
LambdaでPackageを使うためには毎回自分で書いたコードと一緒にzipで固めてデプロイする必要があり、管理が煩わしいという課題があります。
今回は、ServerlessのPluginであるserverless-python-requirementsとpipenvを使ってpackageを管理・デプロイしたいと思います
serverless-python-requirements
packagesのデプロイをいい感じにやってくれるServerlessPluginです。
ちなみにServerlessPluginはServerlessのコマンドにフックして処理を追加できるものなどを指します。
serverless-python-requirements
https://www.npmjs.com/package/serverless-python-requirements
A Serverless v1.x plugin to automatically bundle dependencies from requirements.txt and make them available in your PYTHONPATH.
と公式にはrequirements.txtを基にpackageをbundleすると書いてありましたが(前使ったときはそうだったのですが)、
今回みてみたらpipenvにも対応していました。(素晴らしい)
インストールはnpmでもできるのですが、slsにpluginというサブコマンドができていたので、これを使ってインストールしてみます。
$ sls plugin install -n serverless-python-requirements
Serverless: Installing plugin "serverless-python-requirements@latest" (this might take a few seconds...)
Serverless: Successfully installed "serverless-python-requirements@latest"
簡単ですね。
設定もかなり簡単で下記のように、serverless.ymlに書くだけです。
plugins:
- serverless-python-requirements
これで設定は完了です。
pipenv
packageの管理はpipenvで行います。pipenvはRubyのGemfileライクにPython Moduleを管理できるpackageです。作者はrequestsなどの作者でおなじみのkennethreitzです。
たしか去年の12月頃リリースされましたが、初期は動作が不安定で作業していたフォルダごと削除されてしまったりと、なかなか辛い思い出もあるのですが、今は安定しております。(恐らく)
久々にドキュメントを見たら日本語訳されておりました。(訳してくださった方ありがとうございます!)
http://pipenv-ja.readthedocs.io/ja/translate-ja/
基本的な使い方だけ記載しておきます。もっと詳しく知りたい方はドキュメントを見てください。
仮想環境を作成する
pipenv install
moduleを追加する
pipenv install requests
pipenv側で設定することは特にありません。
serverless-python-requirementsの環境としてpipenvを利用するということを伝えるためにserverless.ymlのcustomセクションの記載だけしてください。
custom:
pythonRequirements:
usePipenv: true
デプロイ
これで後はデプロイするだけです。
$ sls deploy -v
packageをbundleしてくれている様子です。
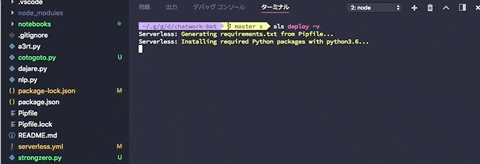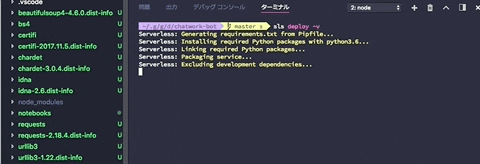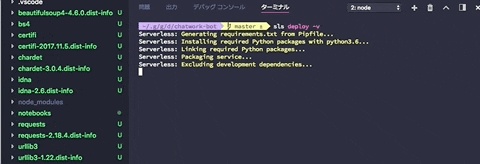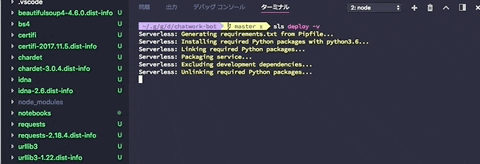
serverless-python-requirementsがpipenv.lockを基にpackageをbundleしてデプロイしてくれます。
以前は各コードで
import requirements
してpathを通す必要がありましたが今は必要なくなっています。
また、今回は非pureなpackage(numpyやsixなど)を使わなかったため利用しませんでしたが、Lambdaのdockerimageを使って実行環境をエミュレートすることもできます。至れり尽くせり。
custom:
pythonRequirements:
usePipenv: true
dockerizePip: true
dockerImage: <image name>:tag
環境変数を定義する
ChatworkTokenなどリポジトリに追加したくない環境変数に関しては、serverless.ymlのenvironmentセクションと、Variableを用いることで簡単に管理できます。
Serverless Variable
https://serverless.com/framework/docs/providers/aws/guide/variables/
まずconfig.ymlを作成します。(名前はなんでも可)
$ cd $PRJECT_DIR
$ touch config.yml
内容は下記のような記載します。
CHATWORK_TOKEN: hogehoge
GCP_API: hogehoge
A3RT: hogehoge
次にserverless.ymlのenvironmentセクションに記載します。
provider:
name: aws
runtime: python3.6
...
environment:
CHATWORK_TOKEN: ${file(./config.yml):CHATWORK_TOKEN}
GCP_API: ${file(./config/config.yml):GCP_API}
これでPythonから環境変数として読み込むことができます。
CHATWORK_TOKEN = os.environ.get('CHATWORK_TOKEN')
GCP_API = os.environ.get('GCP_API')
API Gatewayにカスタムドメインを設定する
LambdaのインターフェイスとしてAPIGatewayを使いますが、API Gatewayが自動で発行してくれるドメインは覚えにくいのでカスタムドメインを使いましょう。
ちなみに公式のブログに細かい説明が載っているのでここにはかいつまんで書きます。詳しく知りたい方は下記リンクを参照してください。
How to set up a custom domain name for Lambda & API Gateway with Serverless
https://serverless.com/blog/serverless-api-gateway-domain/
まずRoute53でCustomDomain、ACMで証明書を取得してください。詳しい内容は上記の公式ブログをご参照ください。
次にServerlessPluginのserverless-domain-managerをインストールします。
https://github.com/amplify-education/serverless-domain-manager
$ sls plugin install -n serverless-domain-manager
Serverless: Installing plugin "serverless-domain-manager@latest" (this might take a few seconds...)
Serverless: Successfully installed "serverless-domain-manager@latest"
インストールできたらserverless.ymlに下記を追加します。
plugins:
- serverless-python-requirements
- serverless-domain-manager ## 追加
..
custom:
pythonRequirements:
usePipenv: true
customDomain:
domainName: yourdomain ## この行以降追加
basePath: ''
stage: ${self:provider.stage}
createRoute53Record: true
記載したらコマンドで設定しましょう。
$ sls create_domain
Serverless: Domain was created, may take up to 40 mins to be initialized
may take up to 40 mins to be initialized
と出ている通り、実行にはそんなに時間がかかりませんが、APIGateway側で反映されるまでにかなり時間がかかります。
(ブラウザでAWSコンソールでAPIGatewayのカスタムドメインを開くと設定が進行中か完了しているか確認できます)
LambdaFunctionの作成
前置きがかなり長くなってしまったのですが、functionの作成を行いたいと思います。
def facade(event, context):
return {
"statusCode": 200,
"body": 'Post sccuessed!'
}
serverless.ymlには下記のように記載します。
functions:
webhook:
handler: webhook.facade
events:
- http:
path: chatbot/webhook
method: post
ここまでできたら一旦デプロイしてみましょう。以下のような出力があるかと思います。
$ sls deploy -v
Serverless: Generating requirements.txt from Pipfile...
(略)
Service Information
service: chatworkbot
stage: dev
region: ap-northeast-1
stack: chatworkbot-dev
api keys:
None
endpoints:
POST - https://hogehogehoge.amazonaws.com/dev/chatbot/webhook
functions:
webhook: chatworkbot-dev-webhook
Stack Outputs
DomainName: my.domain
(略)
endpointsセクションでエンドポイントが作られていることがわかります。またDomain Nameセクションで自分が指定したドメイン名が表示されています。それではこれをChatworkWebhookに登録しましょう。
ChatworkWebhook
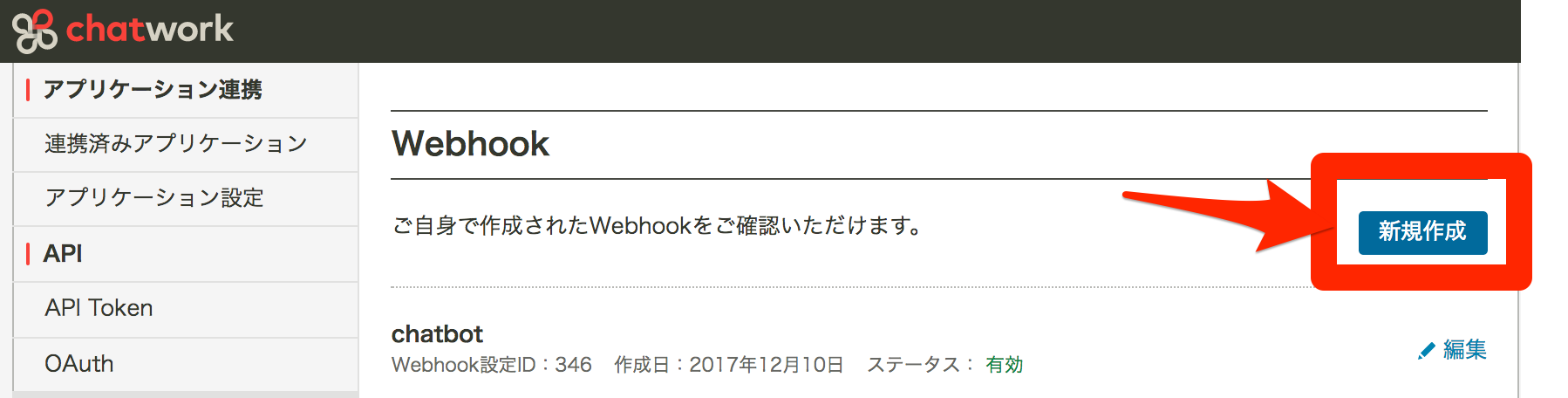
Webhookの設定
管理ページを開き新規作成ボタンをクリック。
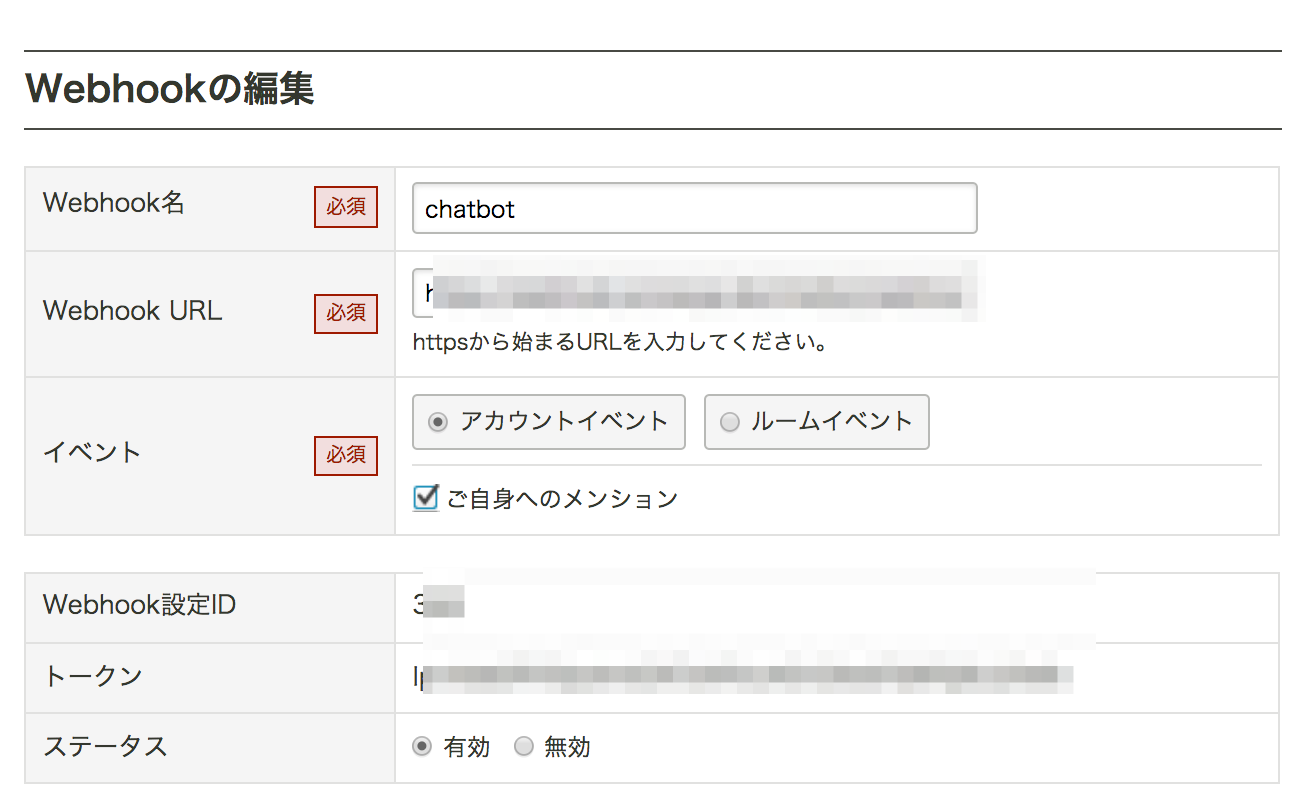
WebhookURLには「<指定したDomain>/<指定したpath>>」(/devは入れないことに注意)を入れます。イベントは「アカウントイベント」を設定し、トークンはこの後の認証で用いるのでメモっておきます。
Webhookで送られてくるもの
webhookのrequest bodyは以下のようになります。(公式ページから引用)
{
"webhook_setting_id": "12345",
"webhook_event_type": "mention_to_me",
"webhook_event_time": 1498028130,
"webhook_event":{
"from_account_id": 123456,
"to_account_id": 1484814,
"room_id": 567890123,
"message_id": "789012345",
"body": "[To:1484814]おかずはなんですか?",
"send_time": 1498028125,
"update_time": 0
}
}
pythonにはdict型としてevent objectの中に入れられているのでアクセスするときは下記の用になります
def webhook(event, context):
body = event['body'] # bodyにrequest bodyが入っている
# 何か処理
認証
公式ドキュメントにあるとおり、認証はこちらで実装する必要があります。認証しなくても利用はできますが、ChatworkWebhook以外のrequestも受け付けてしまい脆弱性に繋がるためきちんと認証しましょう。
リクエストの送信元がチャットワークであることを確認するために、リクエストごとにユーザーのサーバで署名検証をおこなわなくてはなりません。
検証は以下の手順でおこないます。
トークンをBASE64デコードしたバイト列を秘密鍵として、HMAC-SHA256アルゴリズムによりリクエストボディのダイジェスト値を得ます
ダイジェスト値をBASE64エンコードした文字列が、リクエストヘッダに付与されたsignature(X-ChatWorkWebhookSignatureヘッダの値)と一致することを確認します
認証するコードは以下のようになります。
import base64
import hmac
import hashlib
def check_request(event):
webhook_sig = event['headers']['X-ChatWorkWebhookSignature'].encode('utf-8')
sig = build_sig(event['body'])
is_valid = webhook_sig == sig
return is_valid
def build_sig(body, encoding='utf-8'):
token_decode = base64.b64decode(WEBHOOK_TOKEN)
sig = hmac.new(token_decode, body.encode(encoding), hashlib.sha256).digest()
sig_encoded = base64.b64encode(sig)
return sig_encoded
各機能の実装
だじゃれbotのコード
だじゃれbotはこのようにIDをランダムに生成してrequestを送りもし取得できなかったら再帰的に取得しにいっています。
def dajare_and_score():
dajare_id = random.randrange(1, 90000)
response = requests.get(DAJARE_ENDPOINT.format(dajare_id))
soup = BeautifulSoup(response.content, 'html.parser')
content = soup.select('#PanelContentMain')[0]
if 'そのようなダジャレは登録されていません。' in content.text:
dajare_text, hensachi = dajare_and_score()
return (dajare_text, hensachi)
dajare_text = content.select('.PanelBox > span')[0].text
hensachi = re.search('(?<=だじゃれ偏差値:)[\d.]+', content.text).group(0)
return (dajare_text, hensachi)
GCPへのアクセスのコード
それぞれこんな風に書きました。SDK使う方法のが楽だと思いますが、デプロイするpackageをできるだけ減らしたかったので、requestsでベタに書いてます。
- 感情極性値分析
def analysis_senti(text):
payload = {
'document': {
'type': 'PLAIN_TEXT',
'content': text,
'language': 'ja'
},
'encodingType': 'UTF8',
}
res = requests.post(
GCP_ENDPOINT,
data=json.dumps(payload, ensure_ascii=False).encode("utf-8")
)
score = res.json()['documentSentiment']['score']*100
return score
- 翻訳
def translate(text):
payload = {
'q': text,
'target': 'ja'
}
res = requests.post(
GCP_ENDPOINT,
data=json.dumps(payload, ensure_ascii=False).encode("utf-8")
)
text = res.json()['data']['translations'][0]['translatedText']
return text
- 形態素解析
def syntax(text):
payload = {
'document': {
'type': 'PLAIN_TEXT',
'content': text,
'language': 'ja'
},
'encodingType': 'UTF8',
}
res = requests.post(
GCP_ENDPOINT,
data=json.dumps(payload, ensure_ascii=False).encode("utf-8")
)
tokens = res.json()['tokens']
return tokens
ストロングゼロ文学化にあたり調査
それぞれtokenがどのようなlabelに割り当てられているか、どのlabelがどのくらいの割合で使われているかをJupyter Notebookで見てみました。
- 各単語への割り当て

- labelの使用頻度
 ここでだいたいの傾向を掴みあとはいわゆる職人芸でlabelとそれぞれに割り当てる確率を選択しました。
ここでだいたいの傾向を掴みあとはいわゆる職人芸でlabelとそれぞれに割り当てる確率を選択しました。
ストロングゼロ化
コードはこんな感じです。先ほどから全て殴り書きのコードなのでかなり恥ずかしいのですが、自分への「もっとキレイにかけよ!」という戒めのためにも載せています。
def strongzero(tokens):
strong_text = ''
is_last_strong = False
for token in tokens:
label = token['dependencyEdge']['label']
tag = token['partOfSpeech']['tag']
if re.search(pass_pattern, token['text']['content']):
strong_text = strong_text + token['text']['content']
is_last_strong = False
elif tag == 'NOUN' and label == 'ADVPHMOD':
strong_text = strong_text + 'ストロングゼロ'
is_last_strong = True
elif tag == 'NOUN' and label == 'ROOT' and random.random() > 0.4:
strong_text = strong_text + 'ストロングゼロ'
is_last_strong = True
else:
strong_text = strong_text + token['text']['content']
is_last_strong = False
return strong_text
終わりに
元々は「ChatworkのWebhookを試してみたい」という単純な動機だったのですが、やっているうちに楽しくなってきてのめり込んでやってしまいました。Chatbotは反応がすぐもらえるので楽しいですね。Chatbotに興味を持ってくださった方がいたら是非やってみてください。以上です。
明日は@watanataさんです。よろしくお願いします。
参考
ChatWorkのWebhookから送信されるリクエストをLambdaで検証してみた|クラスメソッドブログ https://dev.classmethod.jp/etc/chatwork-webhook-lambda/