0. 背景
東京大学 松尾・岩澤研が主催する 松尾研LLM開発コンペ2025 に参加しました。多くのことを学びましたが、その中の一つを今回紹介したいと思います。
リーダープレゼンを聞いて、第一希望の「チームきつね」に加わることができました。チーム体制はちょっと特殊で、学習班はたった1人、残りの29人はバリバリ合成データをつくりまくるデータ班と自分。まるで「勇者1人+職人集団+村人1人(51)」のパーティーです。
で、私がもちろん 村人(51)。
勇者(学習班)がとにかくすごかった。圧倒的なスキルでDeepSeek-R1-0528の学習を回す姿は、正直に「すごい」という言葉しか出てきません。でも同時に職人(データ班)もガチですごかったんです。みんなで与えられた課題に向けて有効と思われる文献を調べ、データ作成パイプラインを作り、合成データを作成し、また有効な公開データをかき集める。
──────まさに「 勇者と、勇者の剣を鍛える伝説の鍛冶屋集団と村人 」──────
勇者は勇者で無双してたけど、その後ろにはすごい職人集団がいた、そんなチームでした。
ただ私はその中で「村人」(データ生成のためのプロンプト作成)。とっても重要で大事な役割だということも理解しています。自分ができることはやったつもりです。
でも、内心「このまま村人かな…」とちょっと落ち込んだのも事実。そこで思い切って、自分も勇者ジョブに転職してみよう! と挑戦したのが 勇者が使っていたAxolotl での学習です。チームでの自分の役割があるので、コンペの予選終了を待ってすぐにGPUを借りました。多少のトラブルはありつつも学習を回せるようになりました。
「あ、俺もついに村人(51)から、学習もチョットデキル村人(51) になれたかも?」とテンションが上がりました。
その経験をまとめ、 「いまは村人だけれど、勇者にあこがれてる」 と思っている人の参考になればと思っています。(導入長いっすね)
1. 記事を書く目的
近年はLoRAによる効率的な学習や、複数GPUを活用した分散学習(FSDP/DeepSpeed)などの技術も登場し、個人でも巨大モデルを扱いやすくなりました。しかし、AxolotlというLLMファインチューニング用のオープンソースツールについて、日本語での解説記事はまだ多くありません。本記事では、LLMの基礎知識をお持ちの方向けに、1ノード1GPU H100)環境でAxolotlを使ったファインチューニングする手法をなるべくわかりやすく紹介します。特に、東京大学松尾研究室で行われたコンペティションを通じて得られた知見を反映し、私が経験したハマりどころも含めて解説します。この記事を読み終えれば、「自分でも同じように再現できそう!」 と思っていただけることを目指します。
チームきつねの仲間であるAratakoさんのこの記事を大いに参考にさせていただきました。
2. 使用モデルの選定とデータセットの用意
使用モデルは久々にOpenAIが出してきたオープンウエイトモデル「 openai/gpt-oss-20b 」を用います。だって、今時でキャッチーだとおもったから。
学習セットは僕がHumanities last exam対策をイメージして作ったデータセットikedachin/difficult_problem_v2を用います。
Qwen/Qwen3-30B-A3B-Instruct-2507を用いて作った合成データです。ちなみに、問題が難しすぎて僕には回答があっているかどうかはわからないので、その点はご容赦ください。
3. 環境構築手順
まずは学習環境の構築です。実際には松尾・岩澤研のコンペでは1チーム当たり「 H100×8のノード×3 」の開発環境をご用意していただきました。今回は予選後でありコンペ環境が使えないのでRunpodでGPU(H100×1)をレンタルし、より汎用的に試せるように進めていきます。
https://console.runpod.io/
GPUレンタルした内容
- GPU: H100 SMX
- GPU Count: 1
- Pod Template: runpod/pytorch:2.8.0-py3.11-cuda12.8.1-cudnn-devel-ubuntu22.04
- Container Disk: 150GB(要変更)
- Volume Disk: 150GB(要変更)
- 別途永続ストレージとしてStorage(今回は150GB)を借りた→VolumeDiskは自動設定
- Instance Pricing: On-Demand
hf tokenとか、wandbのtoken、HFのIDくらいは変えないといけませんが、この記事を「そのまま実行したい」のであれば、RunpodのPodのテンプレートを選ぶときにCUDAのバージョン12.8のテンプレートをを選択してください。仮想環境を作るのでPytorchのバージョンは気にしなくてOKです。
3-1. uvのインストールと仮想環境準備
Pythonのバージョン管理はAstral社の「uv」ツールを使ってPython仮想環境を構築し、PyTorchやAxolotlをインストールします。通常のvenvやcondaでも問題ないとは思いますが、なんせuvはインストールが速いのでやめられません。また、Hugging FaceやWeights & Biases(W&B)へのログインも行い、学習に必要な設定を整えます。
uvについてはこちらの過去記事も参考にしてください。
さて、環境構築を行っていきましょう。
基本的にはAxolotlの公式のページを参照しています。
https://docs.axolotl.ai/docs/installation.html
curl -LsSf https://astral.sh/uv/install.sh | sh # install uv(for linux)
source $HOME/.local/bin/env # uvコマンドをPATHに通す
export UV_TORCH_BACKEND=cu128 # PyTorchのCUDAバージョン指定(ここではCUDA 12.8)
# ここで作業フォルダを作り、カレントフォルダをこのフォルダに移動します。
mkdir workspace/gpt-oss
cd workspace/gpt-oss
uv venv --no-project --relocatable # 仮想環境を作ります
source .venv/bin/activate # 仮想環境に入る
3-2. PyTorchおよびAxolotlのインストール
uv pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128
-
CUDAのバージョンに注意!
Runpodなどを借りる場合、nvidia-smiでCUDAのバージョンを確認するようにしてください。右上の方にCUDAのバージョンが表示されます。 -
Pytorchのバージョンに注意
PyTorch 2.7.1を選んでいるのは、FSDP(PyTorchの新しい分散学習機能)を利用する場合に備えたためですが、今回は1ノード1GPU(H100)なので2.6以上だとOKらしいです。(未確認)
uv pip install --no-build-isolation 'axolotl[flash-attn]>=0.12.0'
uv pip install awscli pydantic
axolotl[flash-attn]ではAxolotl本体とFlashAttention対応の追加機能をインストールしています。awscliやpydanticはAxolotl実行時に必要となるためこれらもインストールします。
3-3. (任意)追加ツールのインストール
apt update && sudo apt install -y vim # エディタの例としてvimを導入
エディタのvimをインストールします。これは学習設定ファイル(yaml)を作成するためです。他のエディタでも、VSCcodeからssh接続してもOKです。
tips:
GitHubにyamlファイルを書いたレポジトリをアップロードしておいて、git clone <REPO_URL>すると楽チンです。
3-4. Hugging Faceにログイン(事前のアクセストークン発行が必要)
次に、Hugging Face HubとWeights & Biasesの設定を行います。Hugging Faceのモデルやデータセットを使う場合や学習済みモデルをプッシュする場合はログインが必須です。また、学習のログを便利に可視化するためにW&Bを使う場合はAPIキーの設定が必要です(任意ですが、本記事では使用します)。以下のコマンドを実行します。
- HuggingFace
huggingface-cli login
ターミナル上で表示される指示に従ってアクセストークンを入力
これにより、Hugging Face上のモデルやデータセットへのアクセスおよびモデルのアップロードが可能になります。
- Weights & Biasesにログイン(任意・学習ログのトラッキング用)
wandb login
ブラウザ認証もしくはAPIキー入力でログイン。
参考:環境変数で設定する場合
export WANDB_API_KEY=<あなたのW&B APIキー>
W&Bを使う場合は上記のようにログインしておくと、学習中のlossや学習率などの指標がダッシュボードでリアルタイムに確認できます。
3-5. Axolotlのサンプル設定ファイル類を取得
基本的なモデルの学習設定ファイルは用意されています。これらから該当のものを小改造して使うのがリーズナブルと感じました。
私も基本的にそうしています。
axolotl fetch examples
最後のaxolotl fetch examplesコマンドは、Axolotl公式のサンプルYAML設定をローカルのexamples/ディレクトリにダウンロードします。実はGitHubにあります。(https://github.com/axolotl-ai-cloud/axolotl/tree/main/examples)
これらには様々なモデル向けの雛形が含まれており、今回使うGPT-OSS 20Bモデル用の設定も取得できます。このサンプルをもとに今回作成し、学習に使ったYAML設定ファイルの中身を詳しく見ていきましょう。
そしてこのファイル、しっかり見ていくと設定の仕方がわかるようになります。慌てず何種類かの雛形をよく読んでみましょう。これが一番の肝になります。
以下のAxolotlのconfigの説明ページを見ながらじっくり読んでいけば理解できると思います。
https://docs.axolotl.ai/docs/config-reference.html
というものの、じっくり読むのは面倒なので、以下に簡単に記していきます。
4. 設定ファイル(YAML)解説(解読)
AxolotlではYAML形式の設定ファイルにモデルやデータセット、学習パラメータ等を記述し、CLIから指定、実行することで学習します。大規模モデルをファインチューニングするための工夫が詰まっています。それぞれの項目について箇条書きで解説します。
YAMLファイルの作成
vim examples/gpt-oss/gpt-oss-20b-sft-lora-dp2.yaml
エディタのvimで設定ファイルを作成します。
作成した設定ファイル全文
gpt-oss-20b-sft-lora-dp2.yaml(全文)
base_model: openai/gpt-oss-20b
use_kernels: true
quantization_config:
load_in_4bit: true
bnb_4bit_compute_dtype: "bfloat16"
bnb_4bit_quant_type: "nf4"
bnb_4bit_use_double_quant: true
plugins:
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
experimental_skip_move_to_device: true
hub_model_id: ikedachin/gpt-oss-20b-dp-v2
hub_strategy: "end"
hf_use_auth_token: true
wandb_project: axolotl
wandb_name: gpt-oss-20b-dp-v2-sft
logging_steps: 5
datasets:
- path: ikedachin/difficult_problem_dataset_v2
split: train
type:
field_instruction: input
field_output: output
format: |
User: {instruction}
Assistant:
no_input_format: |
User: {instruction}
Assistant:
train_on_inputs: false
dataset_prepared_path: last_run_prepared
val_set_size: 0
output_dir: ./outputs/gpt-oss-out-merged/
sequence_len: 8192
sample_packing: true
adapter: lora
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
gradient_accumulation_steps: 8
micro_batch_size: 1
num_epochs: 1
optimizer: adamw_torch_8bit
lr_scheduler: cosine
cosine_min_lr_ratio: 0.01
learning_rate: 1e-5
max_grad_norm: 1.0
bf16: true
tf32: true
flash_attention: true
attn_implementation: kernels-community/vllm-flash-attn3
gradient_checkpointing: true
activation_offloading: true
saves_per_epoch: 1
warmup_ratio: 0.1
special_tokens:
eot_tokens:
- "<|end|>"
save_safetensors: true
ではここから解説していきます。
まず、モデルと量子化、およびメモリ最適化に関する部分です:
base_model: openai/gpt-oss-20b
use_kernels: true
quantization_config:
load_in_4bit: true
bnb_4bit_compute_dtype: "bfloat16"
bnb_4bit_quant_type: "nf4"
bnb_4bit_use_double_quant: true
plugins:
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
experimental_skip_move_to_device: true
| 項目名 | 設定値 | 説明 |
|---|---|---|
base_model |
openai/gpt-oss-20b |
約200億パラメータのGPT系モデル。Hugging Faceのモデル名またはローカルパスを指定可能。 |
use_kernels |
True |
FlashAttentionなどの最適化カーネルを使用して高速化 |
quantization_config.load_in_4bit |
true |
モデルを4bit精度でロード(QLoRA) |
quantization_config.bnb_4bit_quant_type |
nf4 |
NormalFloat4形式の量子化方式 |
quantization_config.bnb_4bit_use_double_quant |
true |
ダブル量子化を有効化 |
quantization_config.bnb_4bit_compute_dtype |
bfloat16 |
計算はbfloat16で実行。 |
plugins |
CutCrossEntropyPlugin |
クロスエントロピー計算の一部をカットし、学習安定性とメモリ効率を向上。分散学習時のメモリ断片化も軽減。 |
experimental_skip_move_to_device |
True |
モデルを最初からシャーディングしてGPUに配置。初期のOOM(メモリ不足)を回避。 |
続いて、Hugging Face Hubへの出力やWeights & Biasesに関する設定です:
hub_model_id: ikedachin/gpt-oss-20b-dp-v2
hub_strategy: "end"
hf_use_auth_token: true
wandb_project: axolotl
wandb_name: gpt-oss-20b-dp-v2-sft
logging_steps: 5
| 項目名 | 設定値 | 説明 |
|---|---|---|
hub_model_id |
ikedachin/gpt-oss-20b-dp-v2 |
学習後にHugging Face Hubへアップロードするリポジトリ名(形式:ユーザ名/リポジトリ名)。 |
hub_strategy |
"end" |
学習完了時に一度だけモデルをHubへアップロード。他にevery_saveやcheckpointも選択可能。 |
hf_use_auth_token |
True |
Hugging Faceへのアップロードや限定モデルの取得時に認証情報を使用。huggingface-cli login済みであれば有効。 |
wandb_project |
任意のプロジェクト名 | Weights & Biasesでログを記録するプロジェクトのグループ名。 |
wandb_name |
任意のラン名 | 実験ごとの識別名。Weights & Biasesダッシュボードでログを確認可能。 |
logging_steps |
5 |
何ステップごとにログを出力するか。ここでは5ステップごとにlossなどを記録。 |
次に、データセットおよびトークナイズ設定です:
datasets:
- path: ikedachin/difficult_problem_dataset_v2
split: train
type:
field_instruction: input
field_output: output
format: |
User: {instruction}
Assistant:
no_input_format: |
User: {instruction}
Assistant:
train_on_inputs: false
dataset_prepared_path: last_run_prepared
val_set_size: 0
output_dir: ./outputs/gpt-oss-out-merged/
さらっと書いてますが、一番難しかったポイントはココ。以下のドキュメントを読んで、さらにChatGPTに助けてもらいながららなんとか設定できました。
| 項目名 | 設定値 | 説明 |
|---|---|---|
datasets.path |
ikedachin/difficult_problem_dataset_v2 |
使用するデータセットのパス(Hugging Face上またはローカル)。 |
datasets.split |
train |
使用するデータの分割(例:train, validationなど)。 |
type.field_instruction |
input |
プロンプト部分に対応するカラム名。 |
type.field_output |
output |
期待される回答部分に対応するカラム名。 |
format |
User: {instruction}\nAssistant: |
モデルに与えるプロンプトのテンプレート。 |
no_input_format |
User: {instruction}\nAssistant: |
入力が空の場合のテンプレート(今回は同一)。 |
train_on_inputs |
False |
入力文に対する損失計算をスキップ(Instruction Tuning向け)。 |
dataset_prepared_path |
last_run_prepared |
トークナイズ済みデータの保存パス。初回実行時に自動作成。 |
val_set_size |
0 |
検証用データのサイズ。0で検証なし(全データを学習に使用)。 |
output_dir |
./outputs/gpt-oss-out-merged/ |
学習結果の保存先ディレクトリ。LoRA重みやトークナイザ情報が格納される。 |
続いて、LoRAに関する設定です。大規模モデルを微調整する際、全パラメータを更新せずLoRAという効率的手法で学習します。その関連設定が以下です:
sequence_len: 8192
sample_packing: true
adapter: lora
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
# lora_target_linear: true
| 項目名 | 設定値 | 説明 |
|---|---|---|
sequence_len |
8192 |
最大コンテキスト長 (トークン数) |
sample_packing |
true |
可変長の入力サンプルを単一のバッチ内で詰め込む技術 |
adapter |
lora |
PEFTライブラリを使用してLoRAを適用。 |
lora_r |
8 |
LoRAのランク(追加行列の次元数)。 |
lora_alpha |
16 |
LoRAのスケーリング係数。 |
lora_dropout |
0.0 |
LoRA適用部分のドロップアウト率(今回は未使用)。 |
lora_target_modules |
["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"] |
LoRAを適用するモデル内の線形層。AttentionとFFNの主要部分を指定。 |
# lora_target_linear |
true(コメントアウト) |
モデル内の全Linear層にLoRAを適用するオプション(今回はlora_target_modulesで指定したのでコメントアウト)。 |
最後に、学習ハイパーパラメータや分散設定に関する部分です:
gradient_accumulation_steps: 8
micro_batch_size: 1
num_epochs: 1
optimizer: adamw_torch_8bit
lr_scheduler: cosine
cosine_min_lr_ratio: 0.01
learning_rate: 1e-5
max_grad_norm: 1.0
bf16: true
tf32: true
flash_attention: true
attn_implementation: kernels-community/vllm-flash-attn3
gradient_checkpointing: true
activation_offloading: true
saves_per_epoch: 1
warmup_ratio: 0.1
special_tokens:
eot_tokens:
- "<|end|>"
# LoRAをベースモデルにマージして保存
merge_adapter: true
save_safetensors: true
| 項目名 | 設定値 | 説明 |
|---|---|---|
gradient_accumulation_steps |
8 |
勾配を8ステップ分蓄積してから更新。 |
micro_batch_size |
1 |
各GPUが1ステップで処理するサンプル数。 |
num_epochs |
1 |
学習エポック数。 |
optimizer |
adamw_torch_8bit |
8bit版AdamW(bitsandbytesによる省メモリ実装)。 |
lr_scheduler |
cosine |
ウォームアップ後に学習率を徐々に減衰させる方法。 |
cosine_min_lr_ratio |
0.01 |
最小学習率の比率。learning_rateの1%まで下げることを意味 |
learning_rate |
1e-5 |
初期学習率。LoRAでは小さめが推奨。 |
max_grad_norm |
1.0 |
Gradient Clipping(勾配クリッピング) の閾値。勾配の L2 ノルムが 1.0 を超えたら正規化。 |
warmup_ratio |
0.1 |
総ステップ数の10%をウォームアップに使用。 |
bf16 |
true |
BFloat16精度で学習 |
tf32 |
true |
TF32演算を許可 |
flash_attention |
true |
FlashAttentionを有効化。 |
attn_implementation |
vllm-flash-attn3 |
使用するFlashAttentionの実装。 |
gradient_checkpointing |
true |
勾配チェックポイントでメモリ節約(再計算によるトレードオフ)。 |
activation_offloading |
true |
アクティベーションをCPUに退避 |
saves_per_epoch |
1 |
1エポックごとに1回モデル保存。 |
special_tokens.eot_token |
<|end|> |
End of Textを示す特殊トークン。トークナイザに登録される。 |
save_safetensors |
true |
safetensorでアップロード(念のため) |
以上が設定ファイルの主な項目の説明です。要約すると、
• LoRAの活用 + 4bit量子化でモデルを軽量化し、学習すべきパラメータを大幅削減
• 適宜FlashAttentionや8bit Optimizer、勾配チェックポイントなど最先端のテクニックを組み合わせ
といった構成になっています。
5.学習実行方法
環境と設定ファイルの準備が整ったら、いよいよAxolotlで学習を実行します。学習はコマンド一発で開始できます。先ほど用意したYAML設定ファイルを引数に指定して、Axolotlのtrainコマンドを実行しましょう。
axolotl train examples/gpt-oss/gpt-oss-20b-sft-lora-dp2.yaml
今回ダウンロードしたサンプルYAMLは使っていませんが、同じフォルダ内にオリジナルの設定ファイルを作ったので、上記のようにパスを指定するだけでOKです.
もし自分でYAMLファイルを異なる場所に別途作成した場合は、そのパスを指定してください。
まとめますが、学習の流れは以下の手順になります。
Axolotlを使った学習のアウトライン
- データ、モデルを決める
- 学習の環境を作る
- 学習の設定を行う(YAMLファイルを作る)
- 学習する
- ベースモデルとマージ、Huggingfaceにアップロード(任意)
5.1 処理の流れ
コマンドを実行すると、以下のような流れで処理が行われます。
- モデルのロード:
ベースモデルopenai/gpt-oss-20bがロード。LoRAや量子化の設定に応じて自動的調整。 - データセットの読み込み:
テンプレートに沿ってテキストを生成・トークナイズ。dataset_prepared_pathにキャッシュがない場合はトークナイズ結果が保存(次回からはキャッシュを使う) - 学習開始:
GPUにモデルが乗り、LoRAアダプタが差し込まれ、optimizerやスケジューラが初期化。 - 学習ループがスタート:
ログにステップごとのlossなどが表示。W&Bを設定していればW&Bのブラウザ上で確認可能。 - チェックポイント保存:
エポック完了時、output_dirにモデルのLoRA重みが保存。 - HuggingFaceへのアップロード
hub_strategy: endにより、完了後に自動でHuggingFace Hubへモデルがアップロード。
6. 経験したエラーと解決策
私が経験したエラーとその対策を整理します。
6.1 ImportError: cut_cross_entropy が見つからない
学習開始直後にImportError: Please install Axolotl's fork of cut_cross_entropy...というエラーメッセージが出て停止することがあります。CutCrossEntropyPluginをプラグインに指定した場合に発生するエラーで、必要な外部ライブラリがインストールされていないことが原因です。
対策:
Axolotlが用意しているcut-cross-entropy拡張をインストールします。以下のコマンドを実行してください(uv環境内で実行している場合はuv pipを使用します)。
uv pip install "cut-cross-entropy[transformers] @ git+https://github.com/axolotl-ai-cloud/ml-cross-entropy.git@0ee9ee8"
これでAxolotlのカスタム損失関数が導入され、プラグインエラーは解消するはずです。インストール後、再度axolotl train ...を実行してみてください。そもそも、以下の設定を理解せずに使っていたことが問題でした。
plugins:
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
6.2 CUDAのメモリエラー(CUDA out of memory)
学習実行中にRuntimeError: CUDA out of memoryと表示され停止する。特に学習開始直後やバッチ処理中に発生する場合があります。
メモリエラーへの一般的な対処法としては、バッチサイズの縮小(例:micro_batch_sizeやgradient_accumulation_stepsの見直し)、勾配チェックポイントの有効化(今回既にtrueにしていますが)、モデル圧縮(量子化ビットをさらに下げる等)などがあります。
私はそれまで使っていた4090×2という構成(DeepSpeed-Zero3)をやめ、H100×1という構成に変えることで対応しました。
6.3 ストレージの容量エラー
ストレージの容量エラーを経験しました。これはRunpodの設定の話ですのでトグルにしておきます。端的にいうと「起動するコンテナの容量をしっかり確保しておいてください!」ということです。
Runpod ストレージについて
6.3.1 Storageの設定
いわゆる永続ストレージです。このストレージはPodのworkspaceにマウントされます。
まず、ネットワークボリュームを使いたいGPUを選ぶと接続可能なネットワークが表示されます。この時にSize(GB)でしっかりと大き目の容量を確保しましょう。金額的にもGPUの利用料より安いのでケチらず大きめがいいと思います。私は150GBにしました。
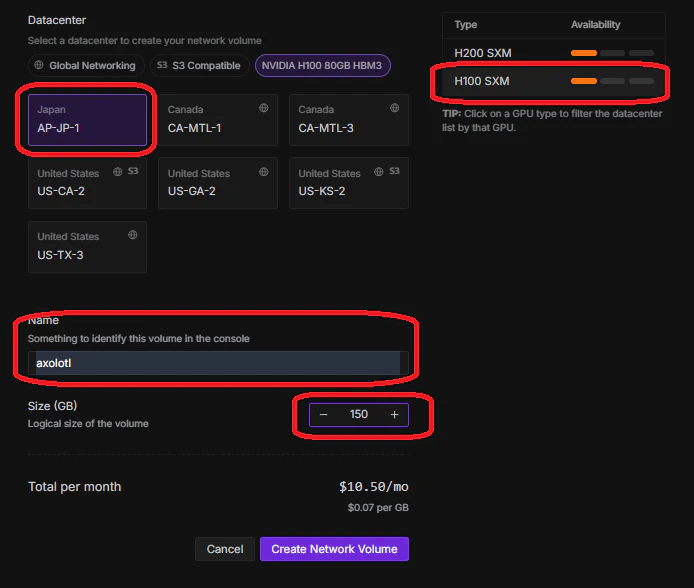
赤枠のところをポチポチ押していきます。
6.3.2 Podの設定
サイドバーからPodsを選択し、ネットワークボリュームのプルダウンから先に作ったstorageを選択します。
今回はaxolotlとしましたので、これを選択します。
GPUを選択すると(今回はH100)Runpodで起動するコンテナのテンプレートが選択できます。ここではCUDAのバージョンに注視してテンプレートを選択しました。
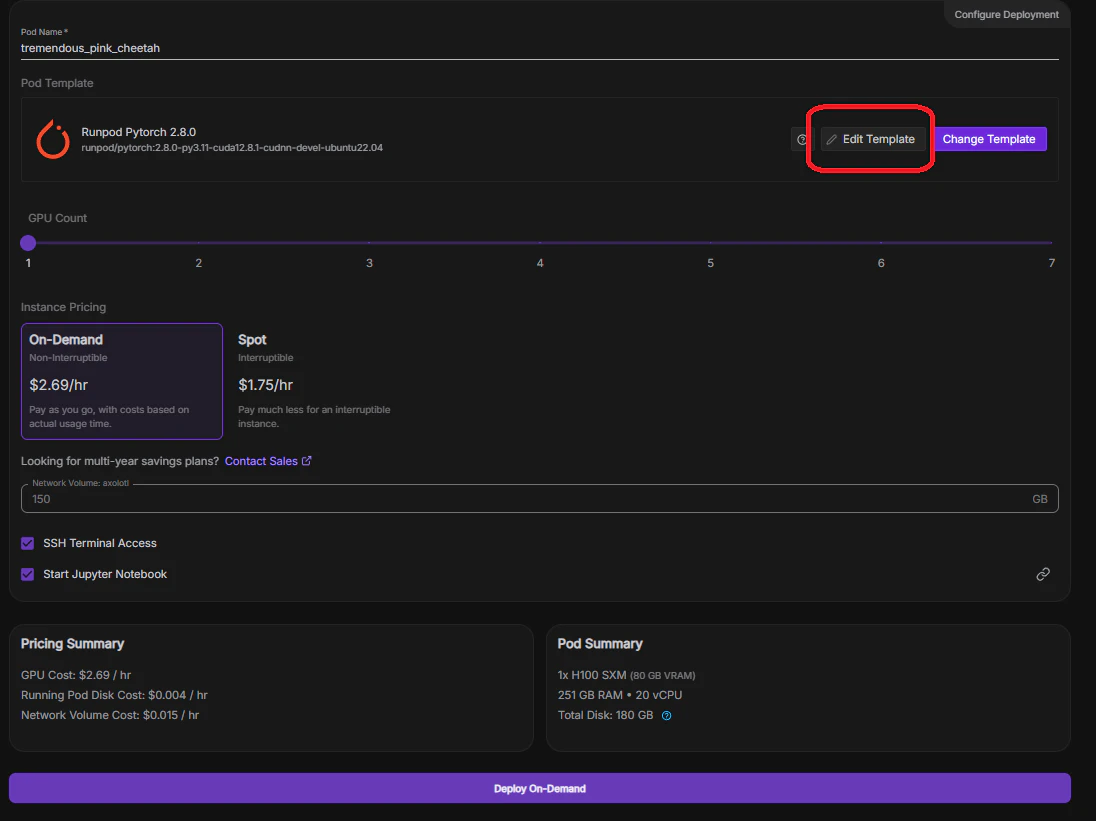
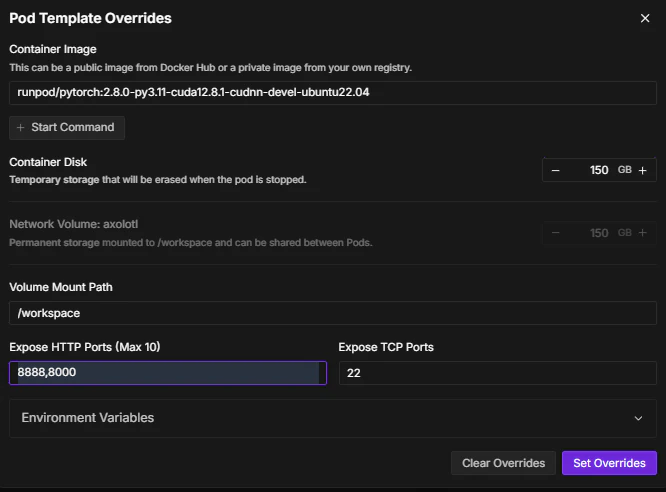
大事なのはEdit templateからテンプレートを変更するところです。Container Diskを今回は150GBに変更しました。storageのサイズと同じとしました。
変更が終わったらSet Overrideを押してテンプレートを編集します。
On-demandとSpotいずれかを選択して一番下のデプロイボタンから起動します。
(Spotは他の利用者が増えると接続を切られてしまうようです。詳細不明)
7. Loraモデルとベースモデルのマージ
AxolotlのLoRAモデルとベースモデルをマージする機能を紹介します。
私の場合はすでにhuggingfaceにLoRAモデルをアップロードした状態で、ローカル(Runpod上)にはモデルを保存していない状態でした。この場合はローカルにダウンロードしてくる必要があります。ベースモデルはマージするときに自動的にダウンロードされますで気にしなくてOKです。
カレントフォルダはworkspace/gpt-oss/とします。
huggingface-cli download ikedachin/gpt-oss-20b-dp-v2 --repo-type model --local-dir lora
# huggingface-cli download <YOUR_ID/YOUR_LORA_REPO_NAME> --repo-type model --local-dir <FOLDER_NAME>
workspace/gpt-oss/lora/フォルダにLoRAモデルがダウンロードされます。
次にマージします。ここでまた学習の設定ファイルが必要です。
axolotl merge-lora examples/gpt-oss/gpt-oss-20b-sft-lora-dp2.yaml --lora-model-dir lora
# axolotl merge-lora <TRAINING_YAML> --lora-model-dir <FOLDER_NAME>
--lora-model-dirはLoRAモデルの保存フォルダを指定します。
いつものAxolotlのアスキーアート?が見えたら実行が進みます。
実行が終わったら、マージされたファイルがどこに出力されるか確認します。
workspace/gpt-oss/outputs/gpt-oss-out-merged/merged/にマージされたウェイトが保存されていました。これは、YAMLファイルにoutput_dir: ./outputs/gpt-oss-out-merged/と記載していたためと思われます。
今度はこれをhuggingfaceにアップロードしましょう
huggingface-cli upload ikedachin/gpt-oss-20b-dp-v2-merged outputs/gpt-oss-out-merged/merged/
# huggingface-cli upload <YOUR_ID/YOUR_MERGED_REPO_NAME> <MERGED_MODEL_FOLDER_PATH>
最後に、Runpod上のJupyter接続から実行してちゃんと使えることを確認しまいた。壊れてなくてよかった。
※HuggingaFaceに記載した方法で確認しました
注:BF16で保存しているので、GPUメモリーは80GB必要です。今度、量子化して試してみます。💦
8. さいごに
本記事では、Axolotlを用いた大規模言語モデルをファインチューニングする基本的な方法を紹介しました。環境構築からYAML設定の詳細、実行方法、そしてハマりがちなポイントの対処まで、一通りの流れを追えるよう心掛けたつもりです。
'24年の大規模言語モデル講座のコンペのサンプルプログラムではunslothを使いました。
これも非常に便利でしたが、
Axolotlは
- YAMLファイルでの管理ができることと
- 複数のGPU、複数ノードが使える事
がメリットですね。だからまだメリットの半分しか享受できてません!
近々、複数GPU(FSDP、deepspeed)に取り組みます。
チーム内ではデータ作成を担っていましたが、学習班が多ノード、多GPUでの学習をこなしている姿、そしてそれを支える29人のデータ班の底力を間近で体感しました。あの体験が「自分も学習を回したい」という動機につながり、結果としてAxolotlに挑戦するきっかけになりました。
この記事が少しでも皆さんのLLM開発の一助になれば幸いです。
一緒に最新のLLMファインチューニングを楽しんでいきましょう。🚀
今、村人(51)は何を考えてるのか
- いつか村人(51)のモデルをどこかで社会実装したいです。
- すでに書いた通り、複数のGPU学習ができるようになりたい!
- なんとか合成データが作れるようになった。なんとか学習もできるようになった。→評価もできるようにならないと!
- そして「大規模言語モデル講座2025で優秀賞を目指したい!」(目指すのは自由!)
後編に続く・・・
9. 謝辞
本当に貴重な経験を積むことができました。松尾・岩澤研の運営の皆様、チームメイトの皆様、他チームの皆様、ありがとうございました。お礼申し上げます。
おそらく、NEDOの皆様、経産省の皆様もどこかでつながってこのコンペを応援していただいていたんじゃないかと想像すると、 この日本も良いもんじゃないか! と感じることができました。
皆様からのご支援を必ず社会に還元できるよう努力を続けていきます。--村人(51)--
- 参照URLs
https://zenn.dev/aratako_lm/articles/b58ac364f9c9cd
https://docs.axolotl.ai/
https://github.com/axolotl-ai-cloud/