この記事は 東京大学松尾・岩澤研究室 LLM開発コンペ2025 に参加して得られた知見をまとめたものです。
Axolotlを使って、FSDPという手法で1ノードで多GPUの分散学習にチャレンジして得た知見をわかりやすくまとめたものです。
1. 導入:ある夜の決断
「あと少しなのにOMM(Out of Memory)か…」
深夜の研究室。村人(51)は社内でジョブチェンを果たし、研究部門に異動していた。
しかしながら村人(51)はモニターに映るOMMによるGPUダウンを見つめながらため息をつく。
前回の「1ノード1GPU」での学習は、確かに計算できたが、今はH100がない。あいつのプロジェクトに取られてしまった。確かにあのプロジェクトは非常に重要だ。今はこのRTX6000で結果を出さなきゃ・・・。量子化方法をいろいろ探るも、出口が見えなくなってしまっていた。
そのとき、隣の席で静かに作業していた後輩がぽつりとつぶやいた。
「あ、RTX6000、一台あきますよ。僕の学習、明日の朝にはおわりそうです。FSDPのv2で2GPUで分散したらいいんじゃないですか?じゃ、お先っす!」
その言葉が、僕の中で何かを動かした。
「よし、GPU2台で学習しよう。そうだ。FSDP2でいこう。二台のRTX6000なら96GB。できる!」
そういえばあの後輩、FSDPやってたんだな。すごいな・・・。
2. 前回の振り返り:1ノード1GPUのでの学習
前回の記事では、Axolotlを用いて「gpt-oss-20b」モデルのLoRAファインチューニングを1ノード1GPU構成で実施しました。
設定はシンプルで、Axolotlを使った学習の流れを把握するには最適でしたが、以下のような課題が予測されます。
大きなメモリのGPUがあったとしても
- いつも利用できるとはかぎらない
- GPU1枚に収まりきらないモデルもたくさんある
- バッチサイズやシーケンス長に制限が出る可能性
そこで、これらの課題を解決するために、今回は「1ノード2GPU」構成とFSDP v2を導入しました。
GPUレンタルした内容
GPU: RTX 6000 Ada Generation
GPU Count: 2
Pod Template: runpod/pytorch:2.8.0-py3.11-cuda12.8.1-cudnn-devel-ubuntu22.04
Container Disk: 150GB(設定変更必要)
Volume Disk: 150GB(設定変更必要)
別途永続ストレージとしてStorage(今回は150GB)を借りた→VolumeDiskは自動設定
Instance Pricing: On-Demand
2. FSDP v2の導入
では、GPU1枚で学習したときからの変更点を細かく見ていきましょう。
axolotlの設定ファイル全文はこちら
gpt-oss-20b-sft-lora-dp2-fsdp.yaml
base_model: openai/gpt-oss-20b
use_kernels: true
quantization_config:
load_in_4bit: true
bnb_4bit_compute_dtype: "bfloat16"
bnb_4bit_quant_type: "nf4"
bnb_4bit_use_double_quant: true
plugins:
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
experimental_skip_move_to_device: true
hub_model_id: ikedachin/gpt-oss-20b-dp-v2-fsdp2
hub_strategy: "end"
hf_use_auth_token: true
wandb_project: axolotl
wandb_name: gpt-oss-20b-dp-v2-sft-fsdp2
logging_steps: 5
datasets:
- path: ikedachin/difficult_problem_dataset_v2
split: train[:256] # 5時間の表示が出たので急遽一部のみ・・・汗(27分)
type:
field_instruction: input
field_output: output
format: |
User: {instruction}
Assistant:
no_input_format: |
User: {instruction}
Assistant:
train_on_inputs: false
dataset_prepared_path: last_run_prepared
val_set_size: 0
output_dir: ./outputs/gpt-oss-out-fsdp/
sequence_len: 8192
sample_packing: true
adapter: lora
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
gradient_accumulation_steps: 4
micro_batch_size: 1
num_epochs: 1
optimizer: adamw_torch_8bit
lr_scheduler: cosine
cosine_min_lr_ratio: 0.01
learning_rate: 1e-5
max_grad_norm: 1.0
bf16: true
tf32: true
flash_attention: true
attn_implementation: kernels-community/vllm-flash-attn3
gradient_checkpointing: true
activation_offloading: true
saves_per_epoch: 1
warmup_ratio: 0.1
special_tokens:
eot_tokens:
- "<end>"
merge_adapter: false
save_safetensors: true
fsdp:
- auto_wrap
- full_shard
fsdp_version: 2
fsdp_config:
auto_wrap_policy: TRANSFORMER_BASED_WRAP
transformer_layer_cls_to_wrap: GptOssDecoderLayer
state_dict_type: FULL_STATE_DICT
sharding_strategy: FULL_SHARD
reshard_after_forward: true
activation_checkpointing: true
offload_params: false
cpu_ram_efficient_loading: true
2-1. FSDP(Fully Sharded Data Parallel)
fsdp:
- auto_wrap # 自動ラップを有効化してモデルの層を分割
- full_shard # FSDPの完全シャーディングモードを使用
fsdp_version: 2 # 使用するFSDPのバージョン(1と2がある)
fsdp_config:
auto_wrap_policy: TRANSFORMER_BASED_WRAP # トランスフォーマーベースの分割ポリシーを採用
transformer_layer_cls_to_wrap: GptOssDecoderLayer # 分割対象となるトランスフォーマーレイヤーのクラス
state_dict_type: FULL_STATE_DICT # モデルの状態をフルステートディクショナリ形式で保存(huggingfaceにアップロードする場合はコレ)
sharding_strategy: FULL_SHARD # モデルパラメータ、勾配、オプティマイザの状態をすべて各GPUに分割
reshard_after_forward: true # フォワードパス後に、モデルのパラメータを再び分割し直す
activation_checkpointing: true # 各層の中間結果をその場で保存せず、必要に応じて再計算する仕組み
offload_params: false # モデルのパラメータをGPUメモリからCPUメモリやストレージに移動するかどうか
cpu_ram_efficient_loading: true # CPU RAMにすべてのモデルをダウンロードせず、部分的にダウンロードし、GPUに送信
2-2. バッチ処理と勾配計算の設定
gradient_accumulation_steps: 4 # 勾配を累積するステップ数
micro_batch_size: 1 # マイクロバッチのサイズ
念のため、勾配を累積するステップ数を8->4に変更し、メモリーに対する配慮をしてみました。(余裕でした。笑)
2-3. 保存関連の変更点
# huggingfaceのrepo名の変更
hub_model_id: ikedachin/gpt-oss-20b-dp-v2-fsdp2
# wandbの実行名変更
wandb_name: gpt-oss-20b-dp-v2-sft-fsdp2
# データセットを先頭の256セットのみに(時間がかかるので・・・💦)
split: train[:256]
# モデルの出力先
output_dir: ./outputs/gpt-oss-out-fsdp/
# LoRA アダプタをマージしない設定に(これも時間がかかるので)
merge_adapter: false
3. 村人(51)の欲
「…本当に学習が始まった」

村人(51)はnvtopを確認しながら、思わず笑みをこぼした。
「よし、ちゃんと安定している。Weight and Biasesも確認。順調にlossも下がっている」
ここでFSDP2による分散学習の力は本物だった。
1台あたり48GBのGPUメモリーであっても、2台あればトータル60GB以上の学習をこなしている。しかもメモリーにはH100(1台)よりも余裕がある。
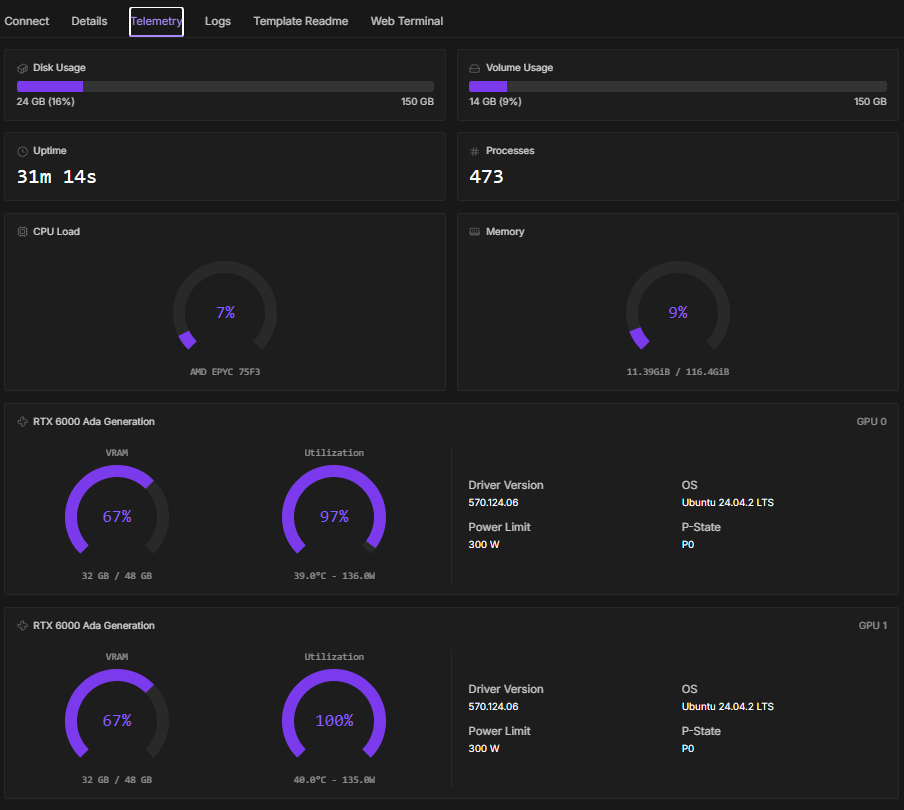
1ノード2GPUという構成は、Axolotlの可能性をさらに広げてくれた。
一方で課題も増えた。GPUが二台に分散したことで学習時間が大幅に伸びてしまったのだ。
ここはインフラ環境の問題もあるだろうが、H100で約65分で終わった計算が、4時間以上と予測されていた。(この時間をみて、今回は256データに絞りました。29分程度/256データ)
村人(51)は欲を出した。次は何を試そうか。3GPU?ノード間分散か?
Axolotlの公式サイトを眺めていると、DeepSpeedという文字が目に入る。
な、なんだ、このDeepSpeedは!
4. DeepSpeedの導入
4.1 DeepSpeedとは
ココでは学習のみに着目します。どうやら以下の論文が元となっているようです。
公式サイトを読み解くとざっくりこんな感じでしょう。
- DeepSpeedはGPUメモリの使い方を超効率化
- PyTorchのDDPだと、同じ情報を複数GPUで丸ごとコピーして持つ → DeepSpeedは必要な情報のみをそれぞれのGPUに保持
- 情報の持ち方やモデルパラメータの分割方法によって、ZeRO1~3がある
4-2. ZeRO1~3(ステージごとの分散対象)
DeepSpeedにはステージが1~3があり、ZeRO1~3と言われれているようです。

引用:https://arxiv.org/pdf/1910.02054
| ZeROステージ | モデルパラメータ(weights) | 勾配(gradients) | 最適化パラメータ(optimizer states) |
|---|---|---|---|
| ZeRO-1 | ❌ 分散しない | ✅ 分散する | ✅ 分散する |
| ZeRO-2 | ✅ 分散する | ✅ 分散する | ✅ 分散する |
| ZeRO-3 | ✅ 分散する(オンデマンド | ✅ 分散する | ✅ 分散する |
ZeRO-1:勾配と最適化パラメータのみ分散。モデルパラメータは全GPUに保持。
ZeRO-2:モデルパラメータも分散され、メモリ効率が向上。
ZeRO-3:すべての要素がオンデマンドで分散・ロードされ、最大限のメモリ削減が可能。
村人:「こ、これはすごい。なんて効率化ができるんだ。まずはこれを使えるようにしたい。」
村人(51)の胸の鼓動が高まる。いや、これは更年期ではない。気持ちが抑えきれない。
Axolotlの公式を読み込むととても簡単そうに思えたので、FSDPでの学習を終えるまでにconfigファイルを用意して学習の準備をしておこう。
4.3 まずは実行してみよう
Axolotlの公式ページに従って手を動かしてみる。
https://docs.axolotl.ai/docs/multi-gpu.html
uv pip install deepspeed
deepspeedをインストール。
axolotl fetch deepspeed_configs
https://github.com/axolotl-ai-cloud/axolotl/tree/main/deepspeed_configs
ここにもファイルはあります。じっくり見たい方はこちらから。
設定ファイルを修正していきましょう。
元になったは、1GPU(H100)で実行したときのファイルです。
gpt-oss-20b-sft-lora-dp2-deepspeed.yamlの全体
base_model: openai/gpt-oss-20b
use_kernels: true
quantization_config:
load_in_4bit: true
bnb_4bit_compute_dtype: "bfloat16"
bnb_4bit_quant_type: "nf4"
bnb_4bit_use_double_quant: true
plugins:
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
experimental_skip_move_to_device: true
hub_model_id: ikedachin/gpt-oss-20b-dp-v2-deepspeed-2gpu
hub_strategy: "end"
hf_use_auth_token: true
wandb_project: axolotl
wandb_name: gpt-oss-20b-dp-v2-sft-deepspeed-2gpu
logging_steps: 5
datasets:
- path: ikedachin/difficult_problem_dataset_v2
split: train[:256]
type:
field_instruction: input
field_output: output
format: |
User: {instruction}
Assistant:
no_input_format: |
User: {instruction}
Assistant:
train_on_inputs: false
dataset_prepared_path: last_run_prepared
val_set_size: 0
output_dir: ./outputs/gpt-oss-out-merged/
sequence_len: 8192
sample_packing: true
adapter: lora
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
gradient_accumulation_steps: 8
micro_batch_size: 1
num_epochs: 1
optimizer: adamw_torch_8bit
lr_scheduler: cosine
cosine_min_lr_ratio: 0.01
learning_rate: 1e-5
max_grad_norm: 1.0
bf16: true
tf32: true
flash_attention: true
attn_implementation: kernels-community/vllm-flash-attn3
gradient_checkpointing: true
activation_offloading: true
saves_per_epoch: 1
warmup_ratio: 0.1
special_tokens:
eot_tokens:
- "<|end|>"
merge_adapter: false
save_safetensors: true
# ---------------------- ここからが変更点(DeepSpeed 有効化) ----------------------
deepspeed: deepspeed_configs/zero3_bf16.json # deepspeedのコンフィグファイルを指定するだけ
変化点だけ見ていきましょう。
deepspeed: deepspeed_configs/zero3_bf16.json
なんと、コンフィグファイルを指定するだけ!!!(各種ファイルの保存先などは修正してます)
4.4 DeepSpeedで学習
早速学習していきます。作成したyamlファイルを指定するだけで変わりがないです。
axolotl train gpt-oss-20b-sft-lora-dp2-deepspeed.yaml
いつもどおりにAxolotlのアスキーアートが出て、しばらくすると学習が始まる。

今までなかった挙動が見て取れる。GPUのメモリーが上下しています。
今まではGPU一定の値を保持していましたが、積極的に必要なメモリーだけを保持するようにしているのでしょうか?
学習データ数が256の時、FSDPでは29分、DeepSpeed-ZeROだと22分。高速化もできそうです。
【参考】ZeRO3のコンフィグファイルの種類
- zero3_bf16.json
- ZeRO Stage 3 + bf16のみ
- 全てのモデル状態(パラメータ、勾配、オプティマイザ状態)をGPU間で分散
- GPUメモリを最大限活用し、CPUやストレージへのオフロードしない
- 高速だが、大規模モデルではGPUメモリが不足する可能性
- zero3_bf16_cpuoffload_params.json
- パラメータのみCPUにオフロード
- GPUメモリの使用量を削減しつつ、計算に必要な部分はGPUに転送
- CPUメモリの使用が増加するが、GPUメモリの節約に効果的
- ストレージ(NVMe等)は使用しない
- zero3_bf16_cpuoffload_all.json
- パラメータとオプティマイザ状態の両方をCPUにオフロード
- GPUメモリ使用量を大幅に削減可能
- CPUメモリの使用が最大になる
- オプションでNVMeなどへのオフロードも可能(offload_optimizerやoffload_paramにnvme_pathを指定)
- これにより、さらにメモリ負荷を分散できるが、I/O速度がボトルネックになる可能性
5. 終章
まずはあの後輩にお礼を言わねば・・・
村人(51)はAxolotlの便利さ、DeepSpeedの威力を知り、翼が生えたような気持になっていた。このプロジェクトはNEDO様からの支援を受けている。今がスタートであり、この支援を必ずや社会に還元しなければならない。年齢は51であるが、人生100年の時代。まだ人生は半分じゃないか。俺にもやれることはまだまだあるだろう。村人(51)はすがすがしい気持ちと共に、使命に満ち溢れていた。
あとがき
チームきつねは、1人が学習班、残りの29人がデータ班という構成でした。
私はもちろんデータ班で、合成データ作りの楽しさに夢中になりながらも、たった一人で巨大なフロンティアモデルの学習に挑む学習班の仲間を、少しでも支えたいという気持ちがありました。
困りごとが出たときくらい、リサーチで力になれるんじゃないかと。
そんな思いもあって、予選終了後の熱が冷めないうちに、GPUをレンタルして自分でも学習にチャレンジしてみました。この記事が、「学習をやってみたいけど、二の足を踏んでいる」という方の背中を、少しでも押すことができたなら、とても嬉しく思います。上の村人(51)はお察しの通り、私自身です。
当然フィクションですが、今、まさにこの気持ちです。この貴重な機会を頂けたことに感謝申し上げます。
この経験を必ずや社会に還元したいと思います。
- 参照URLs
https://zenn.dev/aratako_lm/articles/b58ac364f9c9cd
https://docs.axolotl.ai/
https://github.com/axolotl-ai-cloud/
本プロジェクトは、国立研究開発法人新エネルギー・産業技術総合開発機構(以下「NEDO」)の「日本語版医療特化型LLMの社会実装に向けた安全性検証・実証」における基盤モデルの開発プロジェクトの一環として行われます。