0. きっかけ
そりゃ、買っちゃったのよ。GB10

そう、NVIDIA DGX SPARKではなくて、兄弟機であるThinkStation PGX買いました。
理由は黒くてかっこいい・・・じゃなくて、ちょっとだけ安かったから。
早速、からあげさんのZennの「神記事」を見て初期設定。
行き詰まりながらもなんとかサーブできたのでご報告。
今回はあえて公式のDockerを使わない方針で!(自分の理解のため!)
1. TL;DR
- GB10(Blackwell / sm_12.1a)は新しすぎる
- CUDA13単体では vLLM がまだ完全対応していない
- CUDA12 runtime を CUDA13 と並存させるのが現実解
- FP8は捨てて BF16 Instruct でまず通す
- Triton / ptxas / Python.h が揃っていないと即死する
2. 環境
- Model: ThinkStation PGX
- GPU: NVIDIA GB10 (Blackwell, sm_12.1a)
- Driver: 580.xx
- CUDA: 13.0
- Python: 3.12
- OS: Ubuntu (AArch64 / SBSA)
- 推論エンジン: vLLM
- モデル: Qwen/Qwen3-VL-30B-A3B-Instruct
3. 【ほぼ結論】やってみてわかったハマった理由(背景)
GB10 世代は以下の問題を同時に抱えているようです
- PyTorch / Triton / vLLM が sm_12.1a を完全には想定していない
- CUDA13 は入っているが、vLLM が内部で要求する libcudart.so.12 が無い
- Triton が同梱している
ptxasが sm_121a を知らない - vLLM は起動時に C拡張をその場でコンパイルするため、
Python.hが無いと落ちる
つまり
「全部最新版なのに、なぜか全部少しずつ噛み合っていない」
4. ハマり解決方針
- CUDA13は ドライバ用として残す
- CUDA12 runtime を追加で入れて共存
- FP8は使わない(CUTLASS / FP8 kernel がまだ危険)
- eager mode でまず「起動を通す」
5. 対策実行
5-1. CUDA12 runtime を CUDA13 runtime と並存させる
vLLM は内部で CUDA12系の runtime を要求するため、CUDA13しかないと libcudart.so.12 not found でvLLMが立ち上がらない。
sudo apt-get update
sudo apt-get install -y cuda-cudart-12-5
sudo ldconfig
では確認
ldconfig -p | grep libcudart
期待される出力:
libcudart.so.13 (libc6,AArch64) => /usr/local/cuda/targets/sbsa-linux/lib/libcudart.so.13
libcudart.so.12 (libc6,AArch64) => /usr/local/cuda-12/targets/sbsa-linux/lib/libcudart.so.12
libcudart.so (libc6,AArch64) => /usr/local/cuda/targets/sbsa-linux/lib/libcudart.so
5-2. Python 3.12 の開発ヘッダを入れる(超重要)
vLLM は起動時に C 拡張をビルドするらしい(ChatGPTさんによる)
Python.h が無いと 起動途中で segfault ではなく compile error になる。
sudo apt-get update
sudo apt-get install -y python3.12-dev build-essential
5-3. Python 仮想環境(uv)
uv init --python 3.12
uv venv
source .venv/bin/activate
uv add pip
uv pip install torch==2.9.0 torchvision==0.24.0 --index-url https://download.pytorch.org/whl/cu130 # 追記(抜けてました)
uv pip install vllm --torch-backend=auto
5-4. 実行前の環境変数
Triton が使う ptxas を CUDA13 のものに差し替える
GB10 では Triton 同梱の ptxas が sm_121a を知らないため、CUDA13 のものを明示する。
export OMP_NUM_THREADS=1
export TRITON_PTXAS_PATH=/usr/local/cuda/bin/ptxas
6. vLLM 起動
6-1. テスト用実行
疎通確認的にさらっと動かしてみます。
vllm serve /home/shinji/models/Qwen3-VL-30B-A3B-Instruct \
--served-model-name qwen3-vl-instruct \
--host 0.0.0.0 --port 8000 \
--trust-remote-code \
--enforce-eager
設定の意図
- --enforce-eager
→ torch.compile / cudagraph を避けて安定優先 - limit-mm-per-prompt.* = 0
→ Vision Encoder の余計な初期化を回避 - gpu-memory-utilization 0.90
→ KV cache 確保で死なないようにする
グリグリメモリーが増えていきます。やったね!
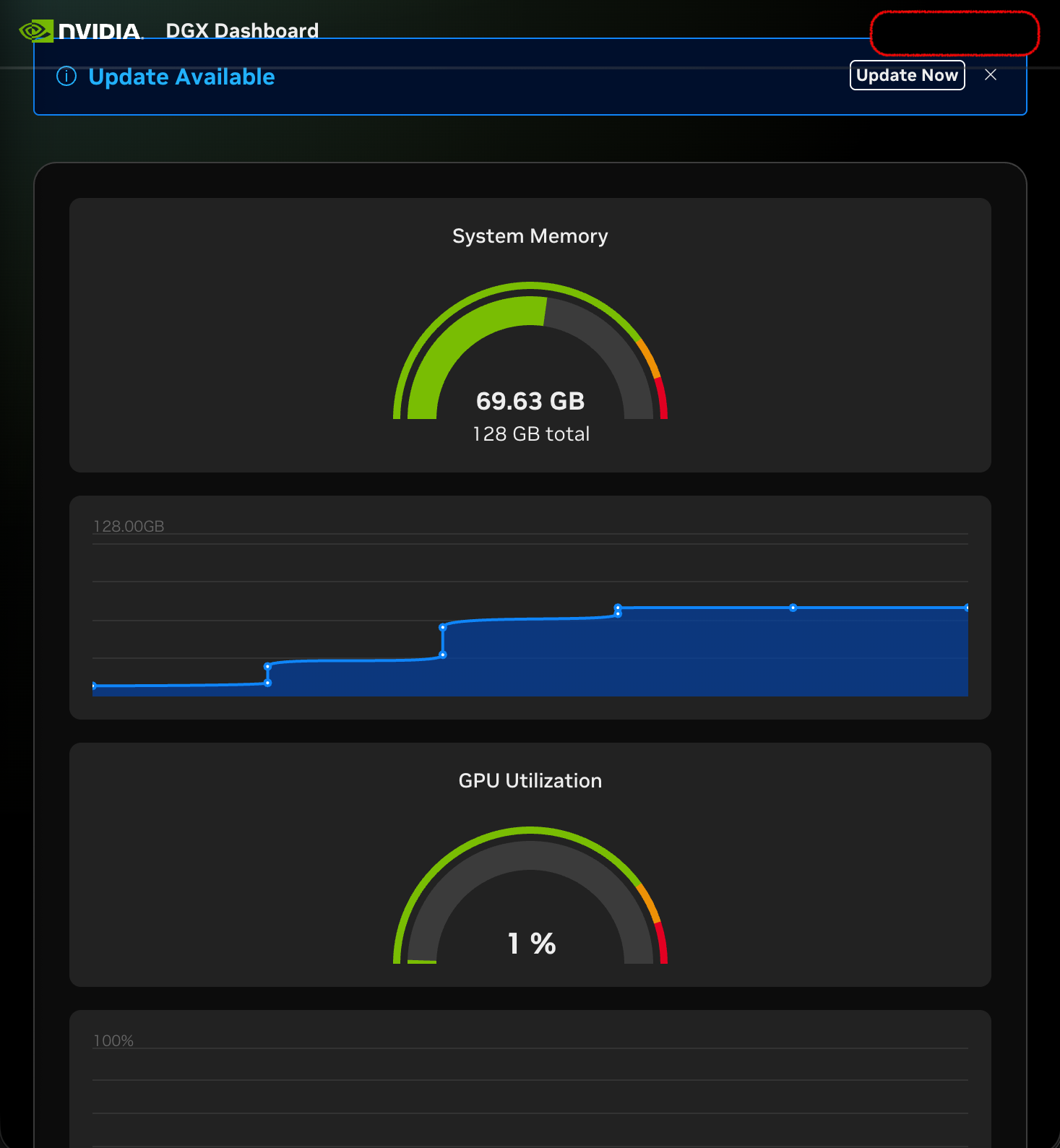
6-2. 実運用寄りの起動
では疎通できたっぽいので、今度こそ!と立ち上げてみます。
vllm serve /home/shinji/models/Qwen3-VL-30B-A3B-Instruct \
--served-model-name qwen3-vl-instruct \
--host 0.0.0.0 --port 8000 \
--trust-remote-code \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.90 \
--limit-mm-per-prompt.image 0 \
--limit-mm-per-prompt.video 0 \
--max-model-len 32768 \
--async-scheduling
6-3. 推論テスト
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model":"qwen3-vl-instruct",
"messages":[{"role":"user","content":"こんにちは。短く自己紹介して。"}],
"temperature":0.2,
"max_tokens":128
}' | jq
-
prefill中
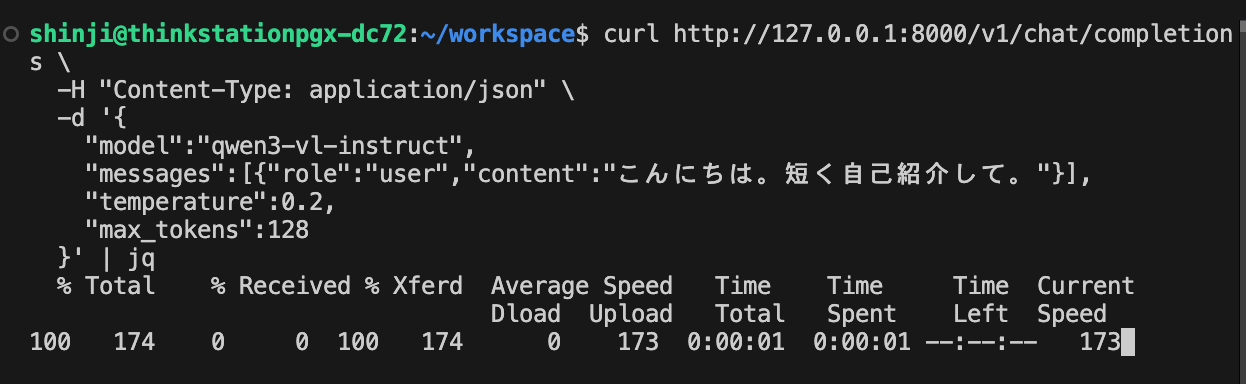
-
ぐぉぉぉぉ!
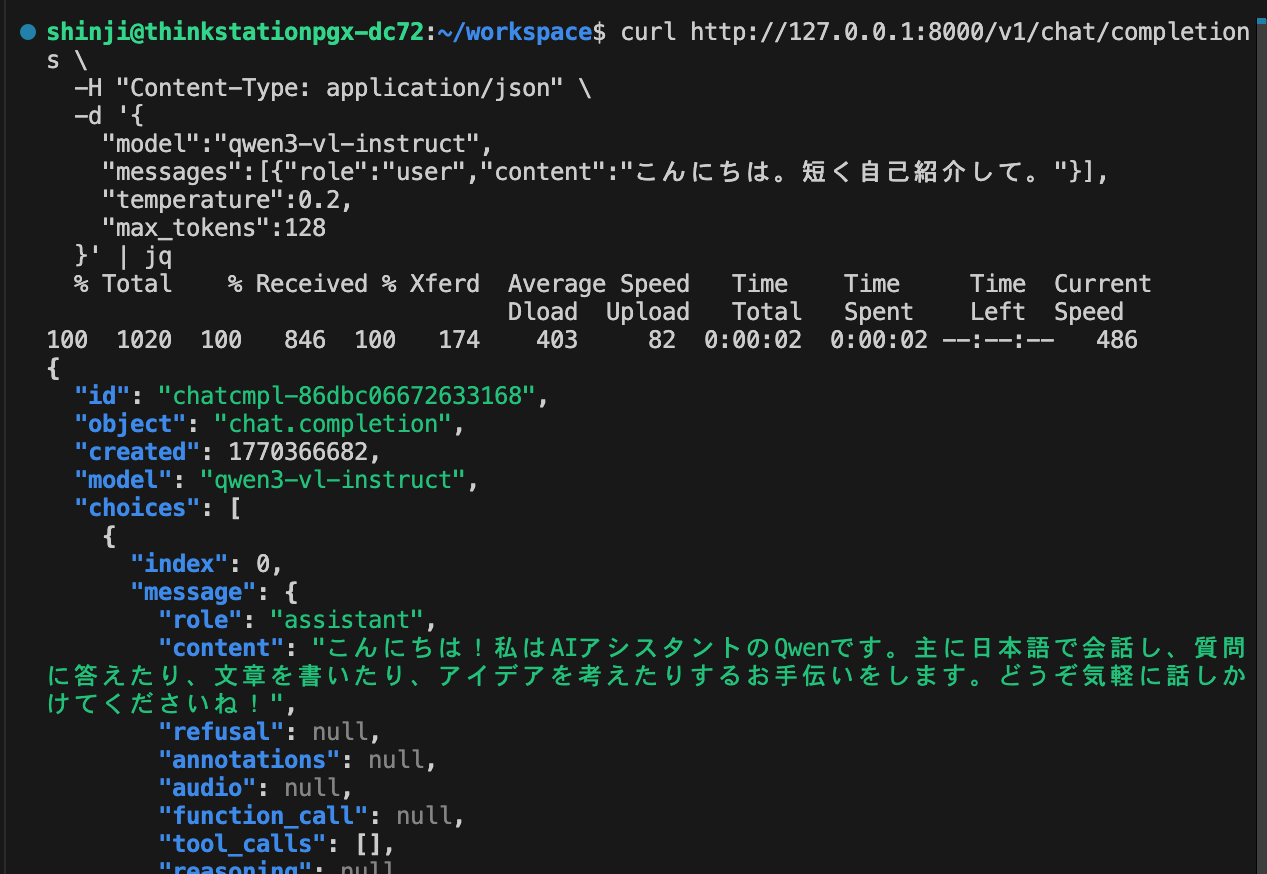
やったね!
今回、素のモデル(量子化なし)を動かしたので、こんなにメモリー食っちゃった。(すげぇ)
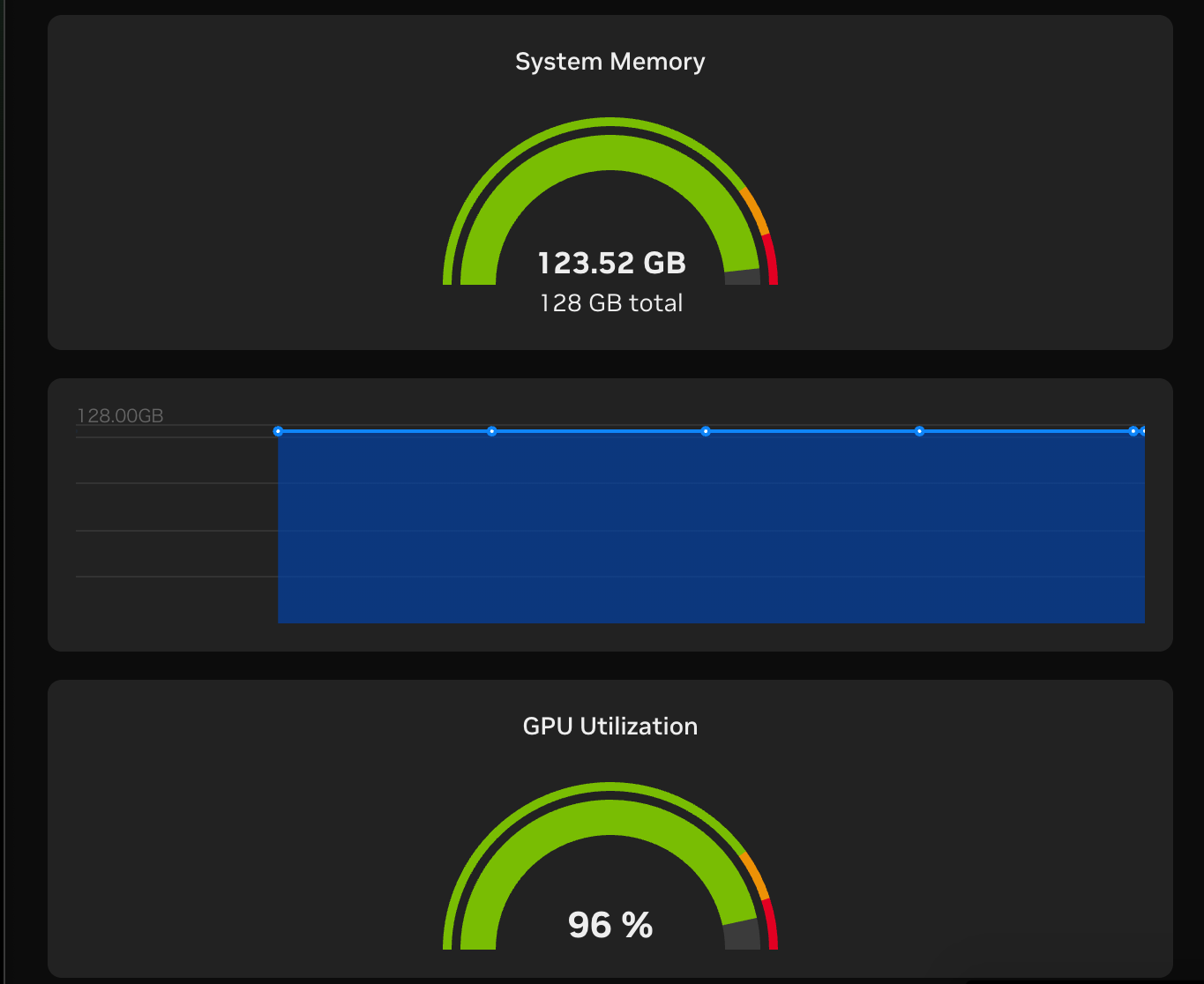
GB10機はユニファイドメモリです。
30B、bf16なので、モデル自体は60GB強くらい、さらにkv cache分、あと、システム分が乗ってくるとこんなになっちゃったのかな。別途真面目に計算してみる???(時間くれ)
7. 遭遇したエラーと原因
最後に、遭遇したエラーと原因を載せておきます。ChatGPTがなければ解決できなかったかも。
最初はFP8のモデルを使用しようとしたんですが、まだ対応できていないっぽいんで今回は素のモデルに変更しました。
❌ libcudart.so.12: cannot open shared object file
→ CUDA12 runtime が入っていない
❌ fatal error: Python.h: No such file or directory
→ python3.12-dev が入っていない
❌ ptxas fatal : Value 'sm_121a' is not defined
→ Triton の ptxas が古い
→ TRITON_PTXAS_PATH=/usr/local/cuda/bin/ptxas
❌ FP8 で cutlass_scaled_mm が Internal Error
→ GB10 + FP8 はまだ地雷
→ BF16 Instruct を使う
8. vLLM / FlashAttention / Triton の関係(超要約)
ここで、僕自身がよく理解できていなかった点、ChatGPTがアドバイスをくれた事をメモとして残しておきます。
- vLLM
推論エンジン本体(KV cache / batching / API) - FlashAttention / FlashInfer / Triton attention
Attention を高速化する「計算カーネル」 - vLLM は 環境に応じて勝手に選ぶ
- GB10 世代では FlashAttention が現時点では未対応/要ビルドな場合あり
👉 FlashAttention は必須ではない
👉 まずは「起動を通す」ことが最優先
9. 今回やっていないこと
- flash-attention の手動ビルド
- FP8 モデルの本格運用
- torch.compile / cudagraph 有効化
これらは GB10 対応がもう少し安定してからで十分かん。
10. まとめ
- 新GPU世代では「動く構成」を作るのが最重要
- CUDA13 + CUDA12 runtime 併存は現実解
- FP8より BF16
- eager mode は正義
- うだうだ言っていないで、手を動かした者勝ち!
11. 感想
いやぁ、疲れた。
同じ罠にハマる人の時間を1日でも短縮できれば幸いです。
12. おまけ
環境構築のスクリプトを置いておきます
モデルの保存先だけは変更してくださいね。
環境構築スクリプト
#!/usr/bin/env bash
set -euo pipefail
# One-shot setup for vllm_inference
if ! command -v uv >/dev/null 2>&1; then
echo "uv is not installed. Please install uv first." >&2
exit 1
fi
if [[ ! -f "pyproject.toml" ]]; then
uv init --python 3.12
fi
# System dependencies
sudo apt-get update
sudo apt-get install -y cuda-cudart-12-5 cuda-nvcc-12-5
sudo ldconfig
sudo apt-get install -y python3.12-dev build-essential
# Virtual environment
uv venv
source .venv/bin/activate
# Python dependencies
uv add pip
uv pip install torch==2.9.0 torchvision==0.24.0 --index-url https://download.pytorch.org/whl/cu130
uv pip install vllm --torch-backend=auto
echo "Done. Activate with: source .venv/bin/activate"
自動起動スクリプト
#!/usr/bin/env bash
set -euo pipefail
# Activate virtual environment
source <あなたの環境のパス>/.venv/bin/activate
# Runtime env vars
export OMP_NUM_THREADS=1
export TRITON_PTXAS_PATH=/usr/local/cuda/bin/ptxas
# Serve vLLM
vllm serve /home/<モデルの保存先>/Qwen3-VL-30B-A3B-Instruct \
--served-model-name qwen3-vl-instruct \
--host 0.0.0.0 --port 8000 \
--trust-remote-code \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.90 \
--limit-mm-per-prompt.image 0 \
--limit-mm-per-prompt.video 0 \
--max-model-len 32768 \
--async-scheduling
※7割がた、ChatGPT君が書いてくれました。笑