背景・導入
本記事の内容は日常業務の中で別部門の方からヘルプを求められた内容であり、筆者本人が全領域において1から関与しているものではございませんのでご理解いただけますと幸いです。
また、内容についても一部ぼかした記載としております。
対象のシステムはALB - ECS - RDSというよくあるWebシステムの構成で、ECSからRDSに対して書き込み・更新系の処理を行っています。
このシステムの中で参照系の処理もECSに乗せてしまうとリソースが逼迫する恐れがあったため、参照系の処理だけ別の構成にオフロードする必要がありました。特に参照系については、お客様要件でユーザ側が自由にクエリを実行できることが求められていました。
ユーザ側としてはread-onlyのアクセスだけで十分であり、安全にクエリが実行できることが重要です。また、データの鮮度についてはリアルタイム性は求められておらず、日中のバッチ処理が完了した後のデータを後ほど確認できれば良いという程度の温度感でした。
構成候補
今回の要件を加味すると複数の構成が考えられると思います。
あくまでもヘルプの相談を受けたタイミングで思いついたものであり、他にも最適な構成が考えられるかなと思います。「こういった構成はどうか?」というご指摘があればいただけますと幸いです。
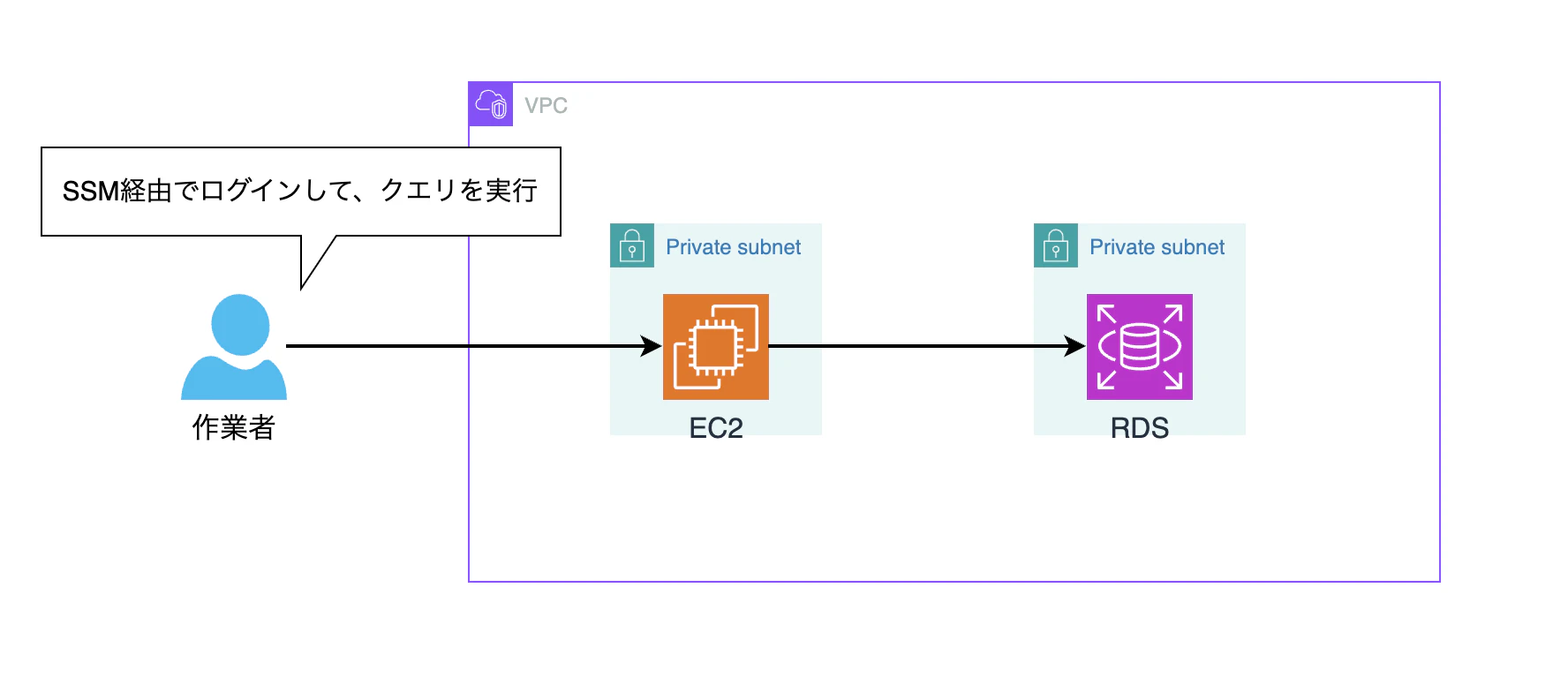
① 踏み台サーバ経由でRDSへ接続してクエリ実行 or ストアド実行
EC2等で踏み台サーバを立ててSSMでEC2にログインした後に、RDSに接続しクエリやストアドプロシージャを実行するパターンです。構成としてはシンプルでSIerにいる自分としては馴染みのある方法ですが、ユーザにDBへの直接アクセスを許すことになります。
read-onlyのDBユーザを用意したとしても踏み台サーバ自体の管理が必要になり運用負荷が発生します。また、背景に記載した通りこのアプローチはリスクが大きいと判断されていたため今回は候補から外れました。
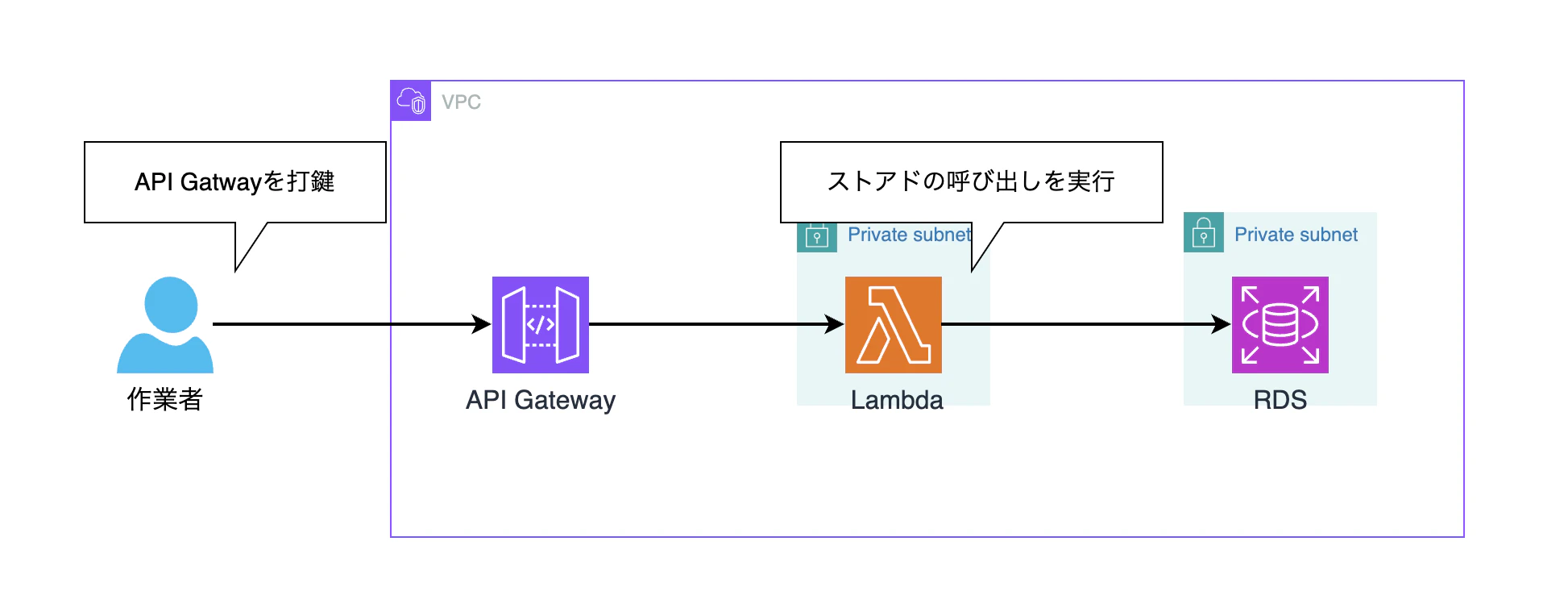
② Lambda経由でRDSへ接続してストアド実行
API Gateway + Lambdaの構成でLambdaからRDSに接続してストアドプロシージャを実行するパターンです。こちらは別の案件でアプリケーション側の方がこのような構成で一部の参照形の処理を実行していた記憶がありましたので、候補として挙げています。
ただし、この構成ではあらかじめ用意したストアドプロシージャの実行が前提となるためユーザが自由にクエリを書いて実行したいという要件とは合いません。
ストアドを実行させるだけの処理であれば、この構成を取るのは悪くないかなと思われます。
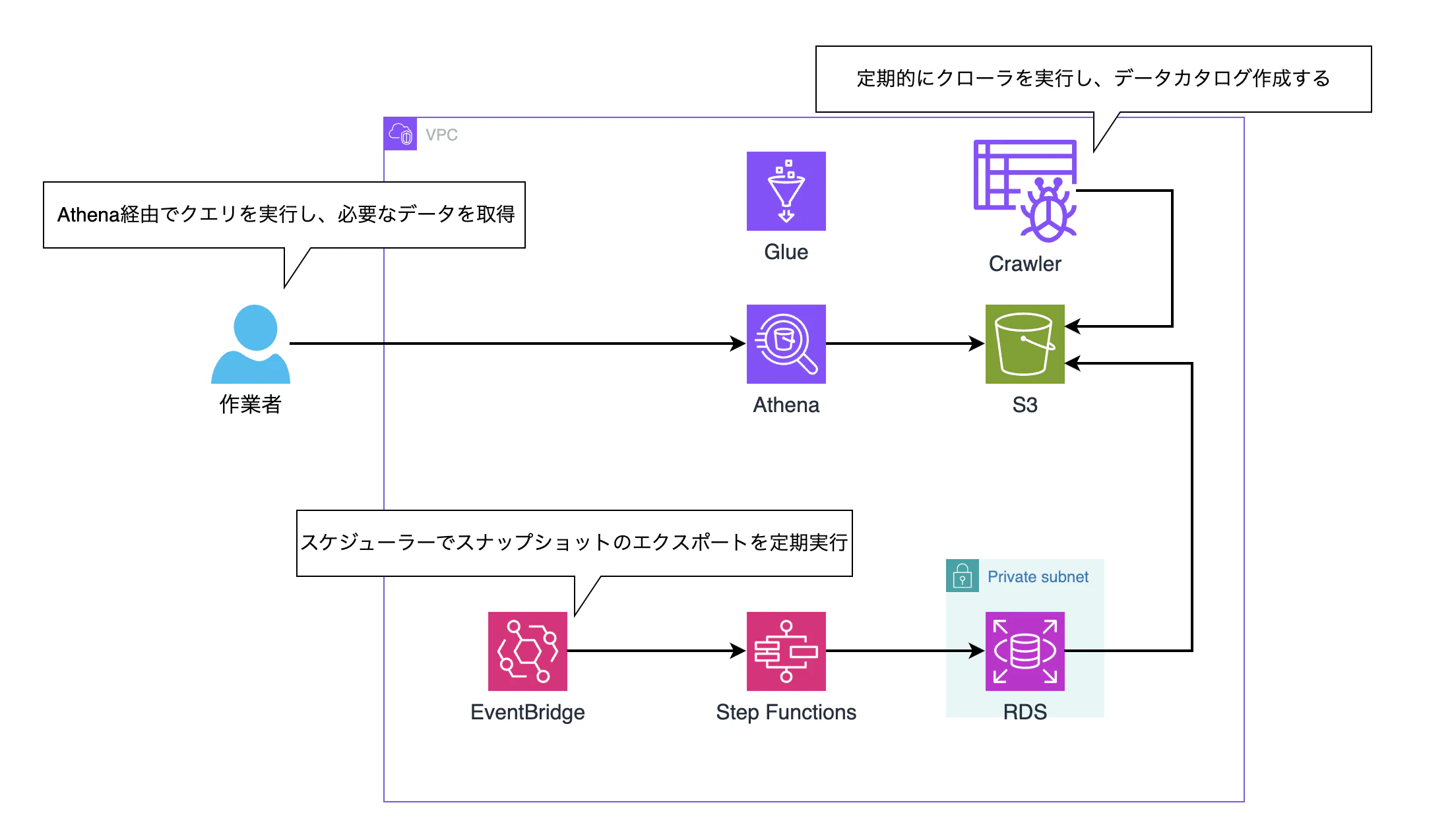
③ RDSスナップショットエクスポート + S3 + Glue & Athenaでクエリ実行
RDSのスナップショットエクスポート機能を使ってS3にデータをParquet形式でエクスポートし、Glueでデータカタログを作成した上でAthenaからクエリを実行するパターンです。S3上のデータに対してAthenaでSQLを実行する形になるため、RDSへの直接アクセスは発生せず構造的にread-onlyが担保されます。
ちなみにRDSのスナップショットはデフォルトでParquet形式でエクスポートされます。
- 参考:RDSのスナップショット

ユーザはAthenaのコンソールや接続ツールから自由にSQLを書いて実行できるため、柔軟なクエリ要件も満たせます。
データの鮮度についても、EventBridge Scheduler + Step Functionsを利用して日次でスナップショット作成からS3エクスポートまでの一連のフローを組めば、夕方頃にデータを確認したいという要件に合致します。
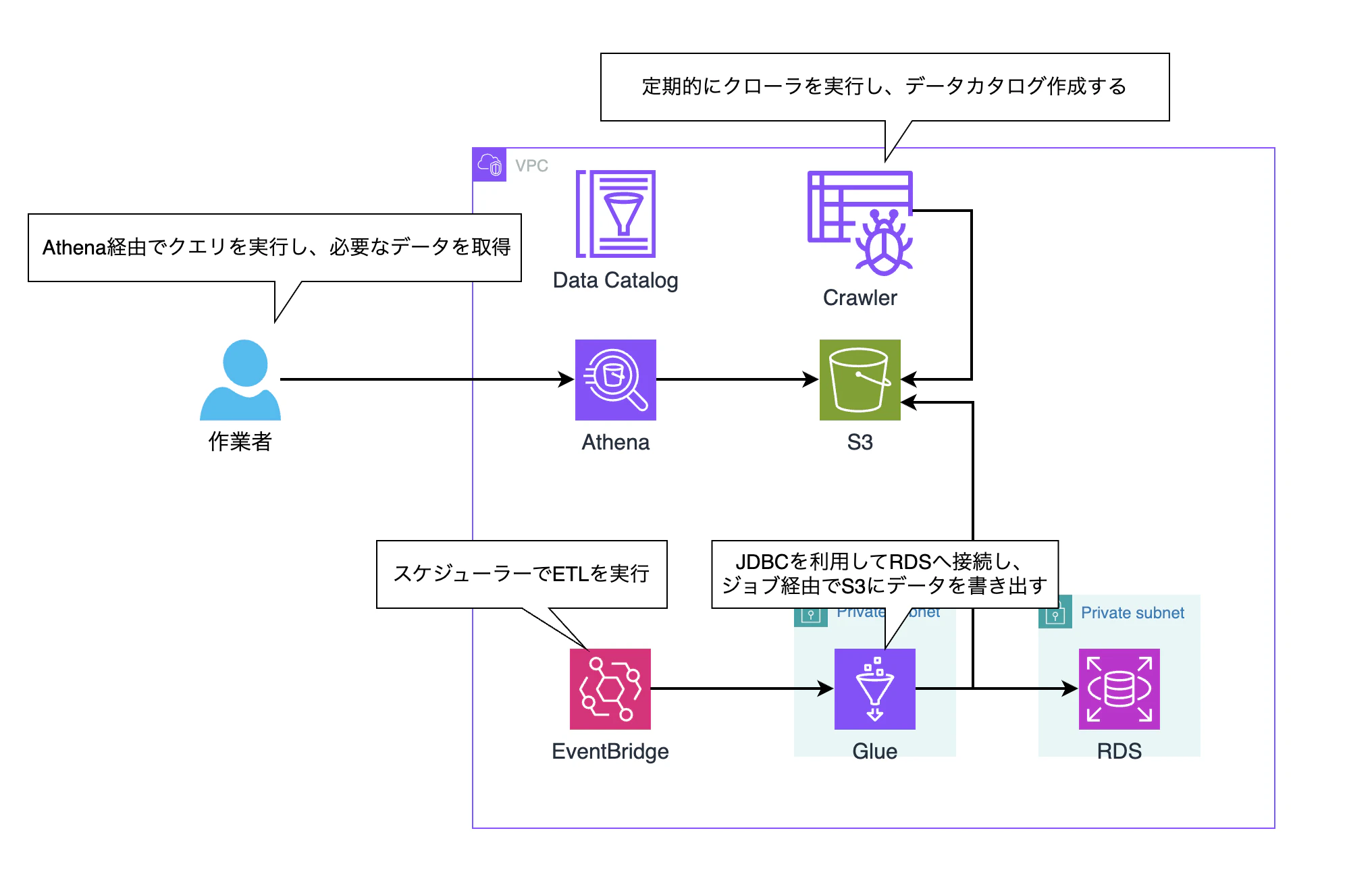
④ Glue JDBC接続でRDSからデータ抽出 + S3 + Athenaでクエリ実行
GlueのJDBC接続機能を使ってRDSに直接接続し、Glue ETLジョブでデータをS3に書き出した上でAthenaからクエリを実行するパターンです。③と最終的なAthenaでのクエリ部分は同じですが、データをS3に持っていく手段が異なります。③がスナップショット経由であるのに対し、④はGlueが稼働中のRDSにJDBCで接続してデータを抽出します。
抽出対象のテーブルを絞ったり、ETLジョブの中で加工・変換を挟んだりと柔軟性は高いです。
一方でGlueからRDSへの直接接続が発生するため、VPCの設定やRDS側のセキュリティグループの開放が必要になります。また、ETLジョブの実行タイミングによってはRDSに負荷がかかる可能性もあるため、実行時間帯の考慮が必要です。
実際の構成
今回は③のRDSスナップショットエクスポート + S3 + Glue & Athenaの構成を採用しました。
個人的には1番シンプルであること、スナップショットの作成・エクスポートであれば他の処理にそこまで影響を与えないことやお客様からの納得感も得られそうということがありました。
AWSネイティブであればいいという訳ではありませんが、「ちゃんとAWSを理解して、使いこなしているんだよ」というところはお客様に納得を頂く上でも重要なファクターになるのではないかと私は考えています。
話がそれましたが、採用理由を表にまとめてみると以下の通りです。
| 要件 | ① 踏み台サーバ | ② Lambda + ストアド | ③ スナップショット + Athena | ④ Glue JDBC + Athena |
|---|---|---|---|---|
| DBへの直接アクセスなし | × | ○ | ○ | △ |
| ユーザが自由にクエリ実行できる | ○ | × | ○ | ○ |
| データ鮮度(日次バッチ後に確認) | ○ | ○ | ○ | ○ |
| 採用 | × | × | ○ | △ |
④の「DBへの直接アクセスなし」を△としているのは、ユーザからの直接アクセスは発生しないものの、GlueからRDSへのJDBC接続が発生するためです。③はスナップショット経由のためRDSへの接続が一切発生せず、その点でよりクリーンな構成と判断しました。
考慮しきれていない事項
冒頭に記載した通りヘルプを求められた状況であり、お客様向けに構成とPoC結果をお伝えしないといけない期限が2〜3日後というかなり差し迫った状況でした。
そのため、エクスポートされたrawデータをそのままAthenaでクエリする形での対応となっており、クエリパフォーマンスの最適化までは手が回っていません。(なんならrawデータと加工後のデータを分けるようにしておきたかったなどありますが、まずは結果を提示しないといけないので目を瞑っています...)
Athenaでのクエリを最適化するためには、パーティション化や圧縮フォーマットの選定といった複数の要素を検討する必要があります。
また、今後大規模な分析処理なども想定されるのであれば、rawデータとパーティション化・最適化済みのデータを分けてS3に保管する設計も検討が必要です。
本人及びその上司の方には「今回はあくまでもPoCであるため、クエリ最適化などは考慮していない旨は伝えてください」とだけはお伝えしているので、最適化については得意領域の方が行なってくれると信じています。
さらに追加となりますが、AthenaとGlueのコストにも注意が必要です。
「サーバレス ≒ 費用が安く済む」という印象をお持ちの方もいらっしゃると思いますが、あくまでもユースケースによって変わります。
Athenaはスキャンしたデータ量に応じた課金($5/TB)ですが、実はクエリ費用よりもS3のGETリクエスト費用の方が高くつくケースがあります。
- 参考:Athenaの課金形態
AthenaはS3上のファイルを読み込む際に大量のGETリクエストを発生させるため、エクスポートされたファイル数が多い場合にGETリクエスト費用が積み重なりやすいです。
Glueについても、クローラーをフルスキャンで毎日実行するとDPU-hour単位の課金が積み重なっていきます。
データ量が多い場合ほどクローラーの実行時間も伸びるため、データ規模によってはそれなりのコストになります。
クローラーの実行頻度や対象パスを絞るなど、設定次第でコストを抑えられる余地があります。
最後に
その後のPoCの結果はお客様より高評価をいただき、現在は本番導入に向けた性能検証などの作業を引き続き行なっているとのことです。
当初は構成相談のみの単発サポートの予定でしたが、気づいたら一部実装まで担当することに...となった話はどこかで供養しようと思います。
普段から社内でこういったスポットの相談をいただく機会はありますが、今回のように直接相談に来てくれる後輩がいるのはありがたいことです。
上司を介しての相談となると工数の調整やら社内調整やらでサポート開始までに時間がかかり、取り返しのつきにくい状態からのスタートになりがちです。
困ったときは気軽に声をかけてもらえると助かりますね。