背景・導入
AWSにはDRを実現するための戦略が複数あります。
様々な案件でDR戦略を策定することはあると思いますが、ちょうど私が担当していた案件においてDR戦略について細かく説明する機会があったので今回は備忘がてら記事として残しておこうと思います。
本記事では最もコストを抑えやすいバックアップ&リストア方式にフォーカスし、各サービスの具体的な復旧方法を解説します。
1点注意となりますが、筆者本人も実際にDRが発動して切り替えに携わったことはなく、訓練のみの
経験でこの記事を記載しております。その点だけご容赦いただけますと幸いです。
想定読者
本記事は以下の方を対象にしています。
- AWSを扱った案件においてDR戦略を検討する必要が出てきたインフラエンジニア
- バックアップ&リストア方式を実務で設計することになった人
- バックアップ&リストア方式がどんなものかは机上の知識では理解しているが、具体的な実装形式は知らない人
※ 本記事ではAWSの基本的なサービス、一部機能は理解している前提で話を進めます。
バックアップ&リストアとは
DRの実現方式は大きく以下の4つに分類されます。
| 方式 | RTO | RPO | コスト |
|---|---|---|---|
| バックアップ&リストア | 数時間〜半日 | バックアップ間隔に依存 | 低 |
| パイロットライト | 数十分〜1時間 | 数分〜 | 中 |
| ウォームスタンバイ | 数分〜数十分 | ほぼリアルタイム | 高 |
| マルチサイト(ホットスタンバイ) | ほぼゼロ | ほぼゼロ | 最高 |
本記事で解説するバックアップ&リストアはRTO: 数時間〜半日、RPO: バックアップ取得間隔が目安です。24時間365日の即時復旧が不要なシステムや、コスト最適化を優先したい場合に適した選択肢です。
上記表の下に行けば行くほどAWS利用料が嵩むため、金融系の一部超重要なシステムを除いては費用との兼ね合いでバックアップ&リストアかパイロットライトになることが多い印象です。
また、バックアップ間隔についても日次+メンテナンス前後のオンデマンド取得になることが多いためRPOについては約1日となっていることが多い印象です。
復旧フローの全体像
バックアップ&リストアにおいて、DR発動から復旧までの基本的な流れは以下のとおりです。
バックアップ&リストア以外の方式でも、1〜3・6〜8の手順は共通ですが、4・5の具体的な作業内容はバックアップ戦略によって異なります。
1. 切り替え判断(障害の影響範囲・復旧見込みをお客様に報告。切り替えのご判断をいただく)
↓
2. DR発動(ステークホルダーへの連絡・復旧に向けた準備の開始)
↓
3. 閉塞切り替え(ユーザにメンテナンス画面を表示し、ユーザからのアクセスを一時的に遮断する)
↓
4. 別リージョンでインフラ構築(CloudFormationやTerraformなどで別リージョンにインフラを構築)
↓
5. データリストア(バックアップからDB・ストレージなどを復元)
↓
6. 動作確認(インフラ疎通・アプリ動作の確認)
↓
7. 限定公開で検証(閉塞を部分的に解除し、限られたユーザで全体的な動作に影響がないかを確認)
↓
8. 閉塞全解除(全トラフィックをDR環境へ切り替え)
上記フローからわかるように、DRは技術問題以上に「意思決定」が重要になってきます。
そのため、DR切り替えのフローを作成するにあたっては以下のことを洗い出しておくと良いです。
- 誰が判断するのか
(経営陣クラス、システムオーナー、インフラ責任者など) - 何を報告するのか
(切り替えが本当に必要なのか、切り替えにはどれくらいの時間がかかるのかなど) - 指示系統はどうするのか
(有事の際は誰が陣頭指揮を取るのか) - DR切り替えを行う前に何をするのか
(自動復旧に賭けるのか、閉塞して切り替え準備を行うのかなど)
私も3年目の時に上記の資料を作った際にはあまりピンときませんでしたが、ここ数年お客様の前に立つことが増えてきてやっとイメージが湧くようになりました。
バックアップ対象の考え方
バックアップ対象を考えるうえで重要なのは、そのリソースが「状態(ステート)を持つかどうか」です。
基本的にはステートを持つものについてはバックアップから復旧、ステートが不要なものは再構築してしまった方が早く復旧が可能になります。
1. ステートフルなリソース
ユーザーのデータやトランザクションの結果など、失ったら取り戻せない情報を保持しているリソースです。障害発生前の状態に戻すためにはバックアップからのリストアが必要になります。
- RDS/Aurora(ユーザーデータ、業務トランザクション)
- EBS(EC2インスタンスのデータディスク)
- EFS(複数サービスから参照される共有ファイル)
2. ステートレスなリソース
それ自体はデータを保持せずコードや設定さえあれば同じものを何度でも作り直せるリソースです。バックアップは不要でコード(CloudFormation/Terraform)による再構築で対応できます。
- EC2インスタンス(アプリケーションサーバー)
- ECSタスク定義/Lambda関数
- セキュリティグループ/IAMロール/VPC
この区別を明確にしておくことがDR計画を無駄なく設計するための第一歩です。ステートレスなリソースをすべてIaCで管理できていれば、DR時のインフラ構築は大幅に自動化できます。
バックアップ&リストア方式ではステートフルなリソースであってもリストア後のデータはバックアップ取得時点まで巻き戻ります。そのためRPOの範囲内でのデータロスは許容する前提となります。
各サービスの切り替え方針
閉塞切り替え(メンテナンス画面の表示)
DR発動直後、まずユーザーへの影響を止めるために閉塞切り替えを行います。
閉塞切り替えの方法としては私が過去に実装したことのあるパターンだと、以下の3つが考えられます。
方法① Route 53+CloudFront+S3(Sorryページ)
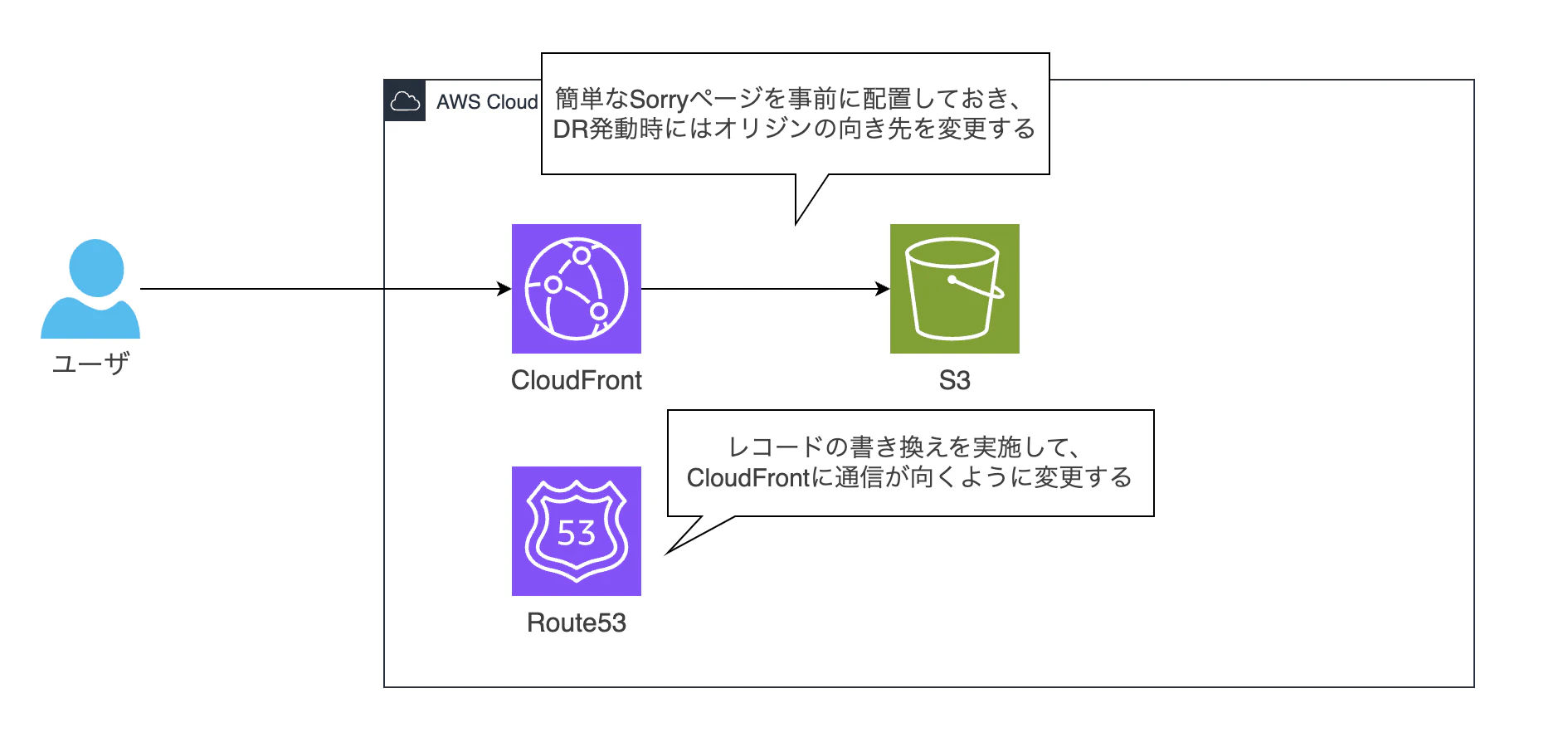
通常時はRoute 53からALBに直接ルーティングしているアーキテクチャを前提としたパターンです。
S3に静的なメンテナンス画面を配置しておき、DR発動時にRoute 53のレコードをCloudFrontに向け替えることでSorryページを表示します。
ユーザが普段から利用しているURLの向き先をCloudFrontに変更することで、Sorryページが表示されるようになります。この際にRoute53のレコードの書き換えやTTLの設定が重要になります。
AWSサービスを使うことによって、DRへの切り替えを自動化することも可能です。その一方で大体の切り替えについては人(お客様)の判断が介在してきます。そのため、泥臭いですがレコードの切り替えなどは手動で行なっていることが多い印象です。
方法② ALB固定レスポンス

ALBでは上記のようにデフォルトアクションで固定レスポンスをユーザ側に返却することができます。
これを利用することでシンプルなHTMLでSorryページを実装することが可能となります。
注意が必要なのはALB単体で返却できるSorryページは1KB(1,024バイト)という上限があるため、リッチなSorryページを表示することはできません。
方法③ Lambda Authorizerによるメンテナンス制御(API Gatewayが経路上にある構成)

API GatewayのLambda Authorizerに事前にメンテナンスフラグの確認処理を実装しておくパターンです。
Lambda AuthorizerがSSM Parameter Storeのメンテナンスフラグを参照し、フラグがONの場合はバックエンドを呼び出さずにdenyを返します。このとき API Gatewayはデフォルトで403を返しますが、ゲートウェイレスポンスをカスタマイズすることで503等任意のステータスコードに変更できます。DR発動時はSSMのパラメータ値を変更するだけで即時に閉塞切り替えが完了するため、API Gatewayの設定変更が不要な点がメリットです。バックエンドがLambdaであってもECSであっても同様に機能します。
注意点として、Lambda Authorizerはリクエストの度に呼び出されるため、毎回SSMを参照するとレイテンシとコストが増加します。API GatewayのAuthorizerキャッシュを有効化しておくことで、この問題を軽減できます。ただしキャッシュが有効な場合、フラグ変更からメンテナンス画面表示までキャッシュTTL分のタイムラグが生じる点は考慮が必要です。
閉塞後の各リソース復旧
閉塞が完了したら復旧を開始することができるようになります。ここでは各サービスの復旧について触れていこうと思います。
データベース(RDS/Aurora)
データベースのバックアップとして推奨されるのはクロスリージョンでのバックアップ保管です。この方法であれば、ランサムウェア対策としても機能するのでDRを想定していないお客様であってもある程度推奨構成として提案させていただくことが多いです。
AWS Backupを使うとRDS・EBS・EFSのバックアップを一元管理でき、DRリージョンへの自動コピーも設定可能です。
具体的な設定箇所としてはメインリージョンでバックアッププランを作成する際に、以下のオプション設定から実施が可能です。
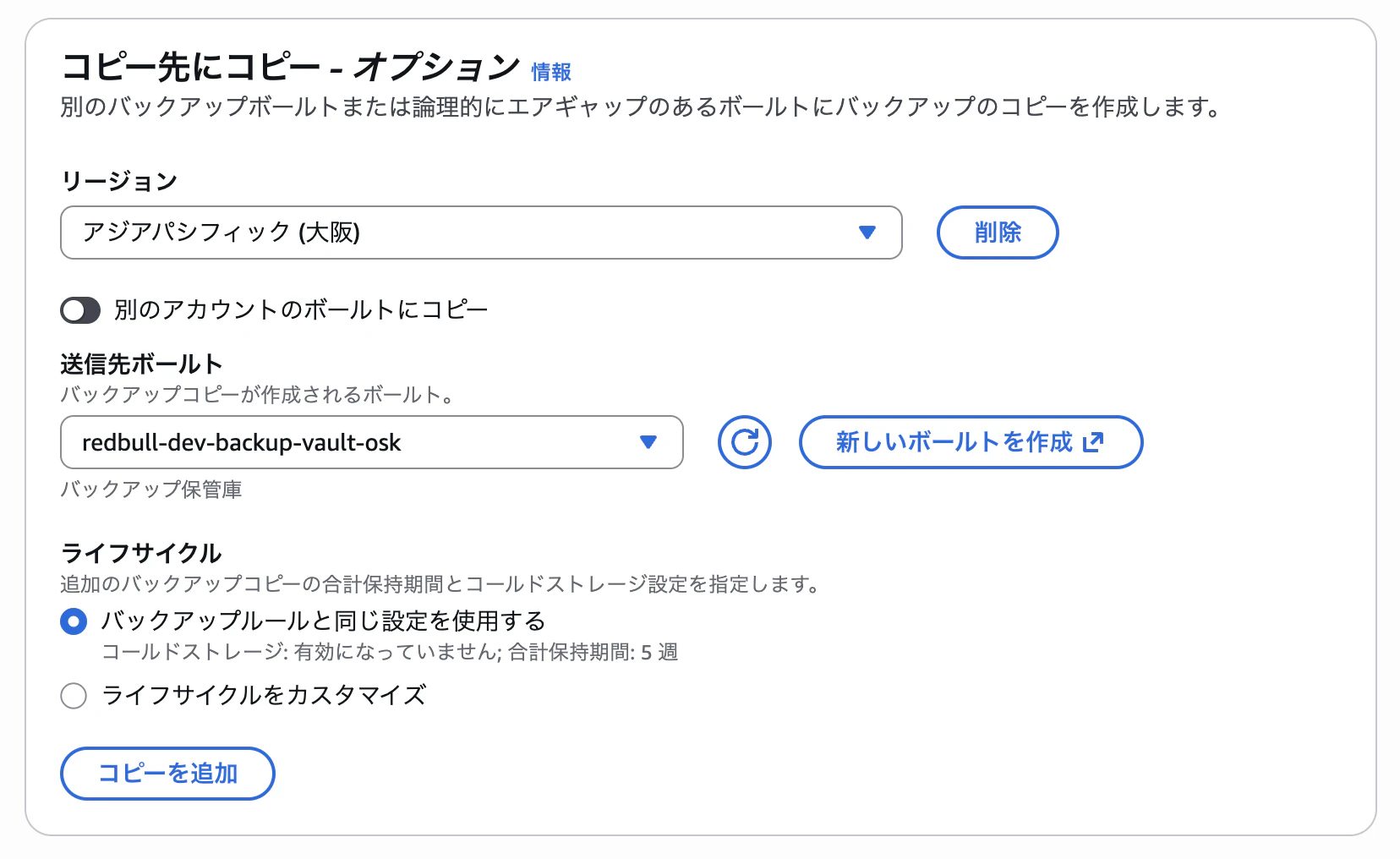
上記設定を行う際には事前にDRリージョン(今回は大阪)にバックアップボールトと、KMSマルチリージョンキーを作成しておく必要があるので注意してください。
バックアップを取得した後はリストアになります。
リストア自体はそこまで難しいものではありませんが、リストア後の動作確認でよくつまづきます。基本的には以下の手順で実行していけば良いのですが、注意事項に書いた内容はよくやらかすので覚えておくと役に立ちます。
- AWS Backupコンソール → 復元ポイントを選択
- DRリージョンのVPC・サブネット・セキュリティグループを指定
- パラメータグループ・オプショングループを設定してリストア実行
注意事項
- リストア後はエンドポイントが変わります → アプリ側の環境変数(
DB_ENDPOINT等)の更新が必要 - セキュリティグループはVPCに紐づくため、DRリージョンで再作成が必要
- KMSキーはマルチリージョンキーを使ってDRリージョンにレプリカキーを事前に作成しておく
ストレージ(EBS/EFS)
EBS
AWS BackupでEBSスナップショットを取得します。EC2をAMIとして保存しておくとEBSも含めてまとめて復元できるため便利です。
EFS
AWS Backupで自動バックアップを設定します。リストア時はマウントターゲットの再作成が必要です。
ユーザデータにマウント用のコマンドを入れておくと自動的にマウントされるようになるので、準備しておくことを推奨します。
オブジェクトストレージ(S3)
S3クロスリージョンレプリケーション(CRR) or クロスアカウントレプリケーション
バックアップというよりニアリアルタイム同期です。DR時はアプリ側の環境変数を変更するだけで切り替えられます。バージョニングを有効にすることで、誤削除対策にもなります。
IaCコード(CloudFormation/Terraform)
当たり前ですが、IaCコード自体もバックアップが必要です。
ここに関しては外部サービス(GitHubなど)を利用されている方が多いので特段問題ないかなと思われます。
DNS切り替え(Route 53)
ここで紹介するフェイルオーバールーティングは、DR発動前に事前設定しておく内容です。DR時の実作業は閉塞全解除のタイミングでRoute 53レコードを手動で切り替えるケースが多いです。
フェイルオーバールーティング
プライマリ/セカンダリを事前に定義し、ヘルスチェックで自動切り替えを設定します。
Route 53
├── Primary(ap-northeast-1)← ヘルスチェックで監視
└── Secondary(ap-northeast-3)← Primaryが異常時に自動切り替え
本来であれば上記のように自動で切り替わるのが嬉しいのですが、実際の現場では切り替え判断は人(お客様)に依存しがちです。私が担当してきた過去の案件であってもフェイルオーバールーティングを実際に採用されたお客様は存じ上げていません。
自動切り替えが気軽に導入できない背景としては、誤作動でDRリージョンに切り替わってしまった時の責任を誰かが取らないといけないと言うところもあるのかもしれませんね。
アプリケーション周り(ECS/Lambda/EC2)
ECS
タスク定義の環境変数を更新(DB_ENDPOINT、S3_BUCKET等)し、サービスを更新して新タスクを起動します。ECRのイメージをDRリージョンにレプリケーションしておくことも忘れずに。
Lambda
環境変数の更新が主な作業です。プライベートサブネット上で動かしている場合はVPC設定(DRリージョンのサブネット指定)も必要です。
EC2 (Auto Scaling)
起動テンプレートのUserDataで環境変数を注入するパターンが一般的です。AMIはAWS Backupまたは手動でDRリージョンにコピーしておきます。
DR発動となる事象が発生した際には現場はかなりストレスがかかっている状態ですので、平時では起きないようなミスが当たり前のように起きます。基本的なことであっても馬鹿にできません。
監視・ログ(CloudWatch)
ログの保全
CloudWatch Logsはリージョン内保存のため、DR時は新規ロググループを作成します。過去ログが必要な場合はメインリージョンでAmazon Data Firehoseを使ってS3に転送後、CRRでDRリージョンに転送しておきましょう。
アラームの再作成
アラームやSNSトピックはIaCコードで定義しておけば、DR環境構築時に自動で再作成されます。
セキュリティ(IAM/KMS)
IAMロール
IAMはグローバルリソースなのでDRリージョンでもそのまま使えます。ただし、ポリシー内にリージョン名を含むARNが書かれている場合は要注意です。
KMS
KMSキーはデフォルトではリージョン固有のリソースですが、マルチリージョンキーを使うことでこの問題をシンプルに解決できます。メインリージョンでマルチリージョンキーを作成しておけば、DRリージョンにレプリカキーを複製でき、同じキーマテリアルを両リージョンで利用できます。
事前準備として:
- メインリージョンでマルチリージョンキーを作成(「マルチリージョン」オプションを有効化)
- DRリージョンにレプリカキーを作成
- わかりやすいエイリアスを設定(例:
alias/dr-rds-key) - AWS Backupのバックアッププランにコピー先キーを指定
この辺りで注意が必要なのは、DRリージョンでEC2をデフォルトのKMSキーで起動しようとして失敗するケースです。よく起きるので覚えておくと役に立ちます。DRに関しては4半期ごとに訓練を行なっておかないと素早く動けなくなってしまうので、事前に運用の要件定義などに取り込んでおくことを推奨します。
実測値:どれくらいで復旧できるか
過去に実際に検証した結果は以下のとおりです。
| リソース | サイズ | 所要時間 |
|---|---|---|
| コード | 40ファイル程度 | 合計約1h |
| RDS | 500GB | 約1.5h |
| EBS | 150GB | 約20分 |
| インフラ構築(IaC) | — | 約30分 |
| 動作確認・切り替え | — | 約30〜60分 |
| 合計 | — | 約4〜5時間 |
データベースのリストアが最大のボトルネックです。また、手動で行うセキュリティグループの作成や環境変数の更新が意外と時間を消費します。(なんならコードに変更を加えているときに誤って別リージョンのセキュリティグループを参照してて、普通にミスしました。)
ただしこれは疑似環境を作成して、1人で行なった際の結果なのであくまでも参考値です。特に筆者の場合はこの疑似環境を作成した本人なので、インフラ構築のところは明らかに外れ値のはずです。
(あと、実際の商用環境で動作確認に1hとかほぼないと思うので、、、)
運用上の注意点
定期訓練の重要性
手順書は「作って終わり」ではありません。
年2回程度(可能なら四半期くらいのペースで)の訓練を通じて以下のことを確認する必要があります。
- 手順書の抜け漏れを発見
- 復旧時間を計測・改善
- チームのDR対応スキルを維持
まとめ
AWSでのバックアップ&リストアDRを実現するための要点をまとめます。
| 項目 | ポイント |
|---|---|
| データ | AWS Backupでクロスリージョンバックアップを一元管理 |
| インフラ | IaCコード(Terraform/CloudFormation)で自動再構築 |
| アプリ設定 | Parameter Store/Secrets Managerで環境変数を一元管理 |
| 訓練 | 年2回(可能なら年4回)の定期訓練で手順書を磨く |
バックアップ&リストアは手軽に始められるDR戦略ですが、「準備してあるから安心」ではなく「定期的に動かして初めて安心」 です。
ぜひ今日から、定期訓練のスケジュールを組んでみてください。
本記事で紹介した実測値や手順は構成・データ量によって大きく変わります。実際の本番環境に適用する前に、必ずご自身の環境で検証してください。