Zabbixの監視データ(ヒストリデータ)がZabbixから直接Elasticsearchに格納できるような機能が実装され、ますます監視データの活用の幅が広がっています。
しかし、実際に使おうとすると、仕様の制約上、扱いに困ることも出てきます。
例えば、ログ系の監視データをElasticsearchに格納し、Kibanaで可視化し分析したいといった時、ただ格納するだけだと、手の届かないことがあります。
ZabbixのElasticsearchへの書き込み仕様として、従来のZabbixのRDBMSに格納するのと同じカラム名のfieldが設定されることになります。
この仕様のため、ログ系のデータであれば
- clock
- value
- itemid
等のfieldにデータが登録されることになります。
ここでポイントは、valueのfieldです。
Zabbixのログ監視で登録されてくる監視結果のデータがそのままvalueのfieldに格納されることになります。
Elasticsearchで柔軟に分析処理を行うためには、ある程度意味のある粒度でfieldに分かれている方が都合が良いケースがあります。
例えば、apacheのアクセスログをZabbixで監視していたとして、その結果をElasticsearchに格納する場合、
以下のようにvalueにログ内容がそのまま格納されことになり、レスポンスコード毎とか、アクセスパス毎とか個別に視覚化することが難しいです。
(mapping定義のanalyzer設定を行うことで、単語ごとに区切って管理されることになるので、全文検索としては機能します)
::1 - - [11/Nov/2018:03:09:27 +0900] "OPTIONS * HTTP/1.0" 200 - 72885 "-" "Apache/2.2.15 (CentOS) (internal dummy connection)"
::1 - - [11/Nov/2018:03:09:28 +0900] "OPTIONS * HTTP/1.0" 200 - 72885 "-" "Apache/2.2.15 (CentOS) (internal dummy connection)"
::1 - - [11/Nov/2018:03:09:29 +0900] "OPTIONS * HTTP/1.0" 200 - 72885 "-" "Apache/2.2.15 (CentOS) (internal dummy connection)"
::1 - - [11/Nov/2018:03:09:31 +0900] "OPTIONS * HTTP/1.0" 200 - 72885 "-" "Apache/2.2.15 (CentOS) (internal dummy connection)"
そこで、value(生のデータ)を区切ってfieldに分けて分析できるようにする方法として2つ紹介します。
- Ingest NodeのGrok processor機能
- Script Field機能
Ingest Node(Grok processor)
Ingest nodeとは、データ格納時に前処理を行う機能です。
様々な加工手段が可能ですが、その中でもテキストメッセージの内容を指定したフォーマットでパース処理してくれるGrok processorが活用できます。
Zabbixからのデータ保存時にpipelineを通して前処理を挟むには、pipelineの名称に注意が必要です。
Zabbixの仕様として、「型-pipeline」という名称で作成することで、該当の型のデータの送付時にpipline指定してインデックス登録されます。
curl -XPOST "http://elasticsearch:9200/_ingest/pipeline/log-pipeline" -H 'application/json' -d'
{
"pipeline" : {
"processors" : [
{
"grok" : {
"field" : "value",
"patterns" : ["%{IPORHOST:client} %{USER:ident} %{USER:auth} \\[%{HTTPDATE:accesstime}\\] \"%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:responsecode} %{USER:a} %{NUMBER:bytes} %{QS:referrer} %{QS:agent}"]
}
}
]
},
}'
log型のデータ保存時(インデックス名logに保存)に通したいpipelineを定義する場合は上記のようにlog-pipelineという名称で定義します。
valueのfieldに対して、patters指定で各項目毎にfield分割するパターンをgrokのパターンフォーマットで定義しています。
これで、Elasticsearch上には以下の図のように値が格納されることになります。
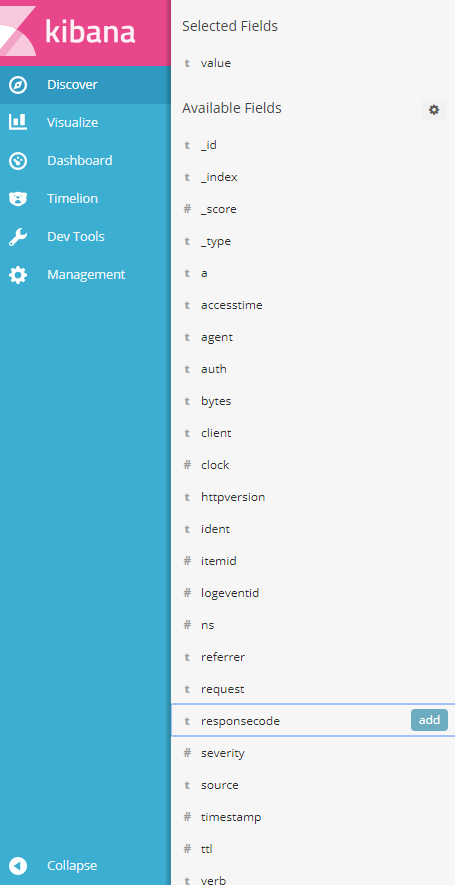
ここで問題なのが、Zabbixの仕様上、型単位でしかpipelineを切り替えて管理できないことです。
ログ型の監視データでも「アイテムの種類毎にフォーマットが異なる」といったケースでは上記だけでは対処が困難です。
Elasticsearchの6.x系だと、Grok processorのパラメータの1つにifというのがあり、
条件に合致したものだけがProcessorの処理を通すということもできそうなので、この辺りの機能も活用すると良いかもしれません。
Script Field
Script Fieldとは、Elasticsearchのindexのfieldデータに対して、加工処理を行った結果を新たなfieldに設定し可視化する機能です。
処理内容は比較的自由にロジックを組み込むことができるので様々応用が効きます。
Script FieldのロジックはPainlessという言語?フォーマットで記載ができ、各フィールドの内容を元に条件分岐させたり、演算子で計算させたり、正規表現で抽出したりといったことができます。
先程のアクセスログの例に対し、レスポンスコード列を正規表現で抽出した内容をScript fieldとして設定してみます。
KibanaのIndexの設定欄に、Script Fieldという設定タブがあります。
ここから定義しておきます。
例えば以下のように設定します。
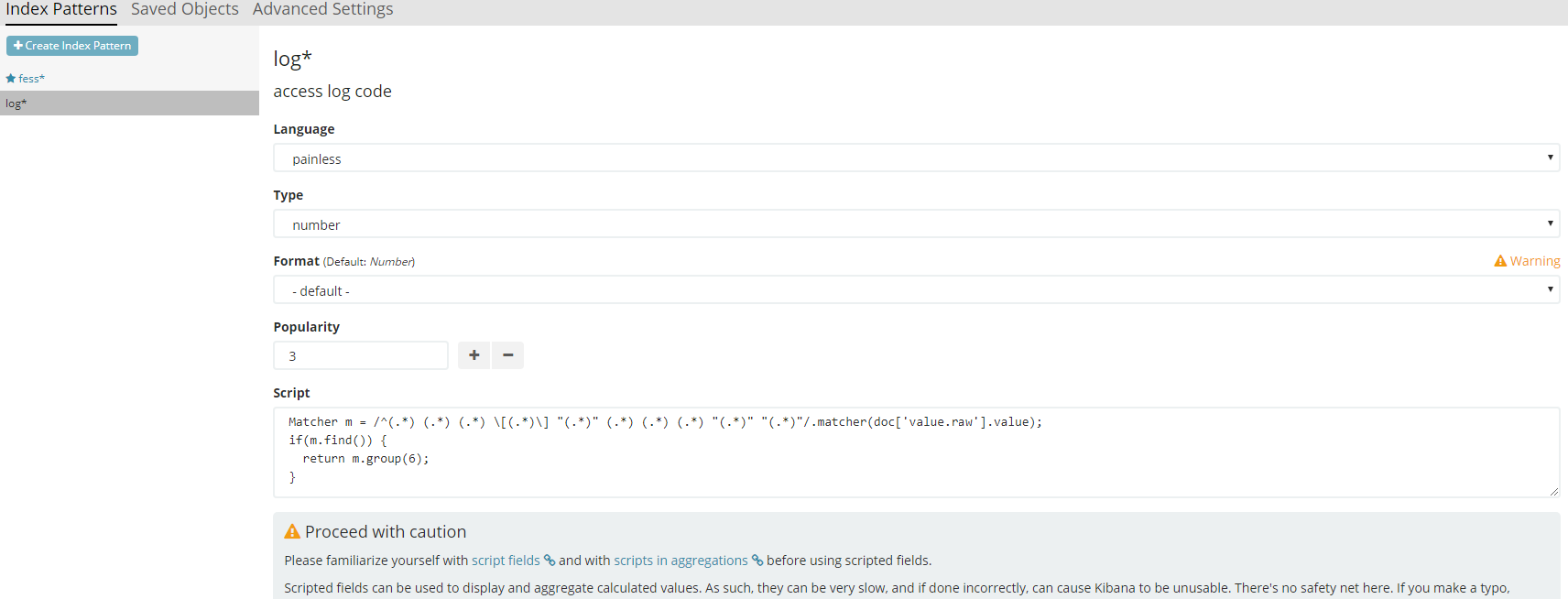
この時の注意点としては、Elasticsearchはデフォルトでscript field内で正規表現の利用が無効化されているため、あらかじめelasticsearch.ymlで有効化しておく必要があります。
script.painless.regex.enabled: true
また、Script fieldの対象とするには該当のfieldに対して、mapping定義で、fielddata: trueが指定されている必要があります。
さらに、valueの領域がanalyzerで分割された状態になっていると、正規表現にマッチしなくなるので、
以下のようにvalueのfieldに対して、「全文検索用途でのanalyzerによる分割済みfield(value.analyzed)」と「生データそのままのテキストキーワードとして管理するfield(value.raw)」に区分けして管理するようにmapping定義を行っておきます。
$ curl -X PUT http://Elasticsearchのホスト名orIP:9200/log -H 'content-type:application/json' -d '
{
"settings" : {
"index" : {
"number_of_replicas" : 1,
"number_of_shards" : 5
}
},
"mappings" : {
"values" : {
"properties" : {
"itemid" : {
"type" : "long"
},
"clock" : {
"format" : "epoch_second",
"type" : "date"
},
"value" : {
"fields" : {
"analyzed" : {
"index" : true,
"type" : "text",
"analyzer" : "standard",
},
"raw" : {
"index" : true,
"type" : "keyword",
},
},
"index" : false,
"type" : "text"
}
}
}
}
}'
これでdiscoveryを行った時に、access log codeという新たなfieldが設定されるので、このデータをbar chartやarea chartで表現することでZabbixの監視データをうまく表現することができます。
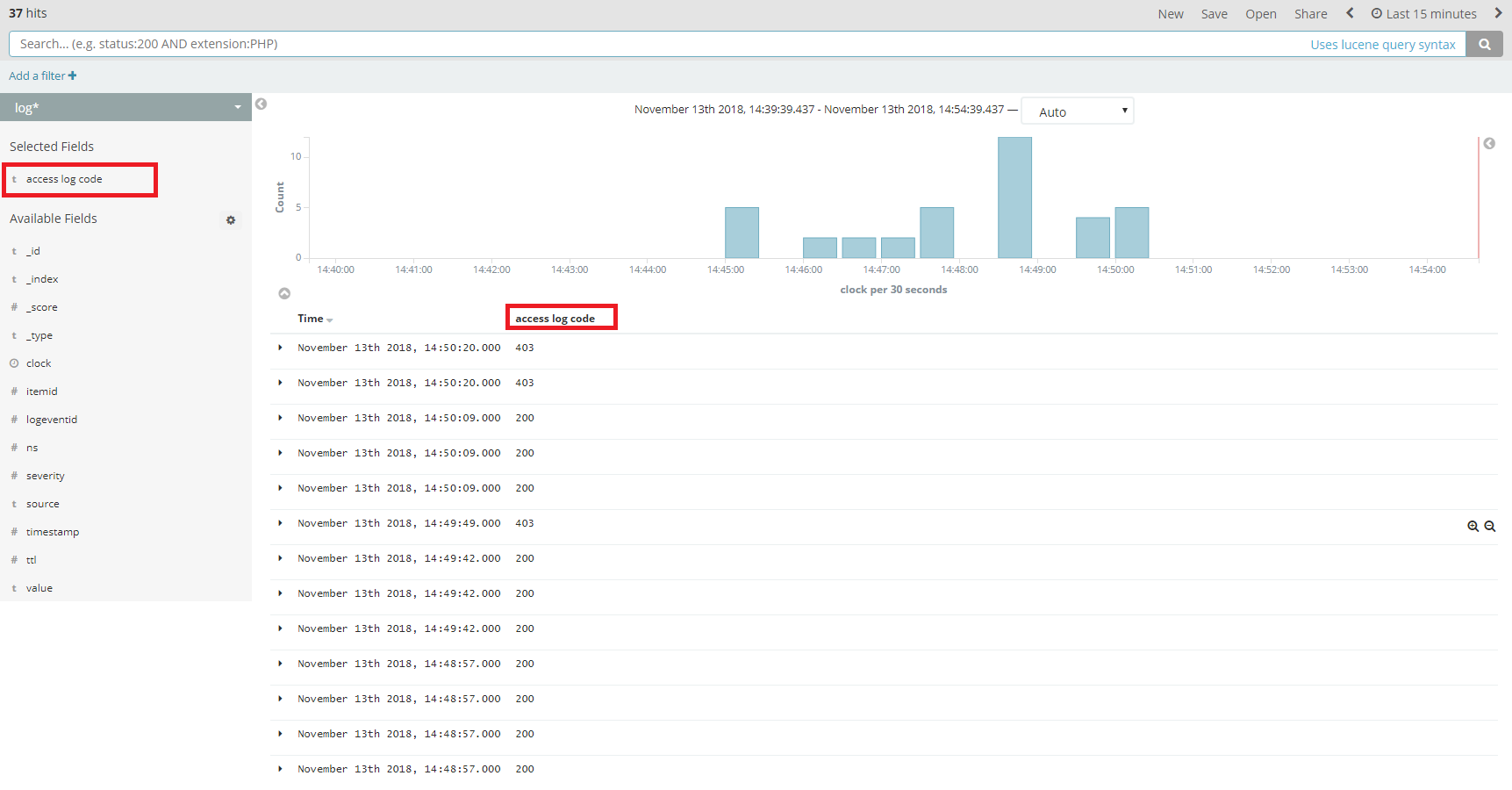
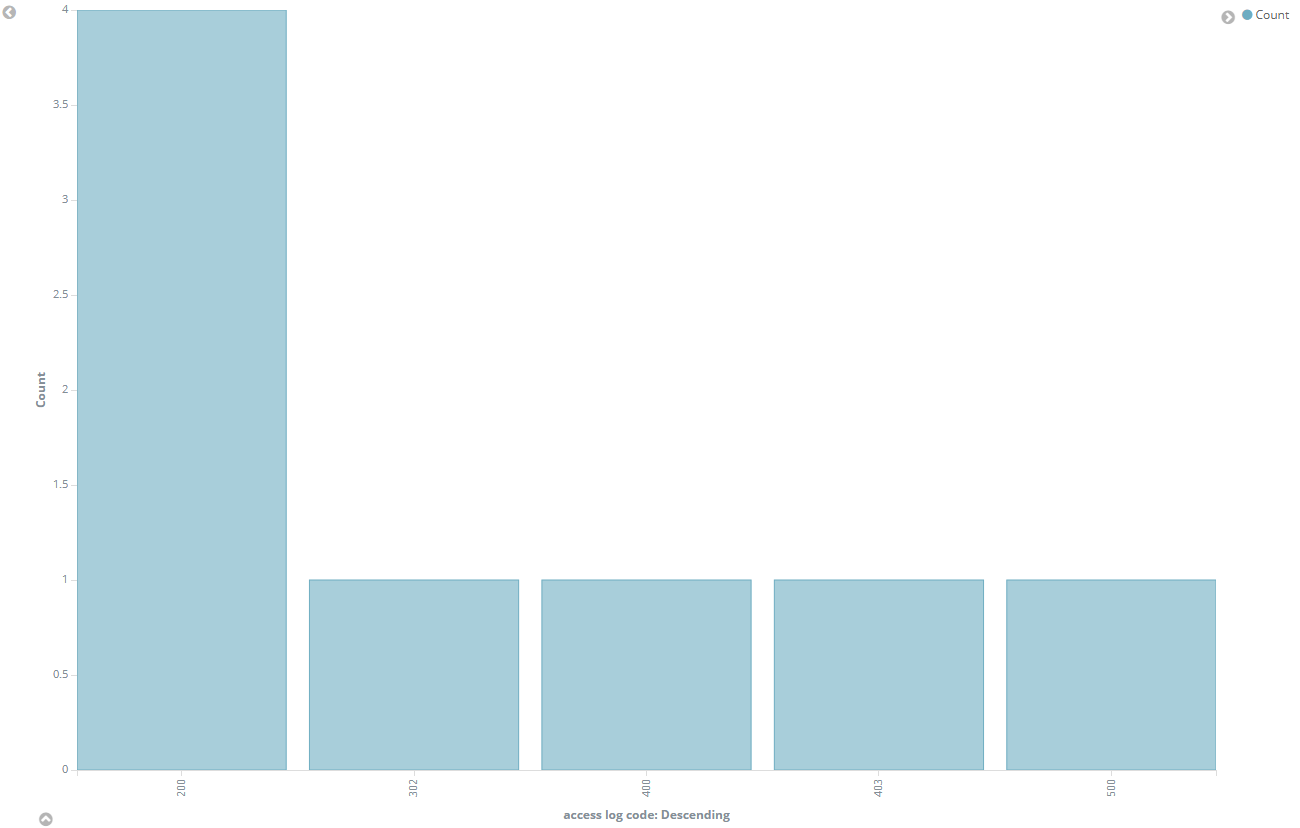
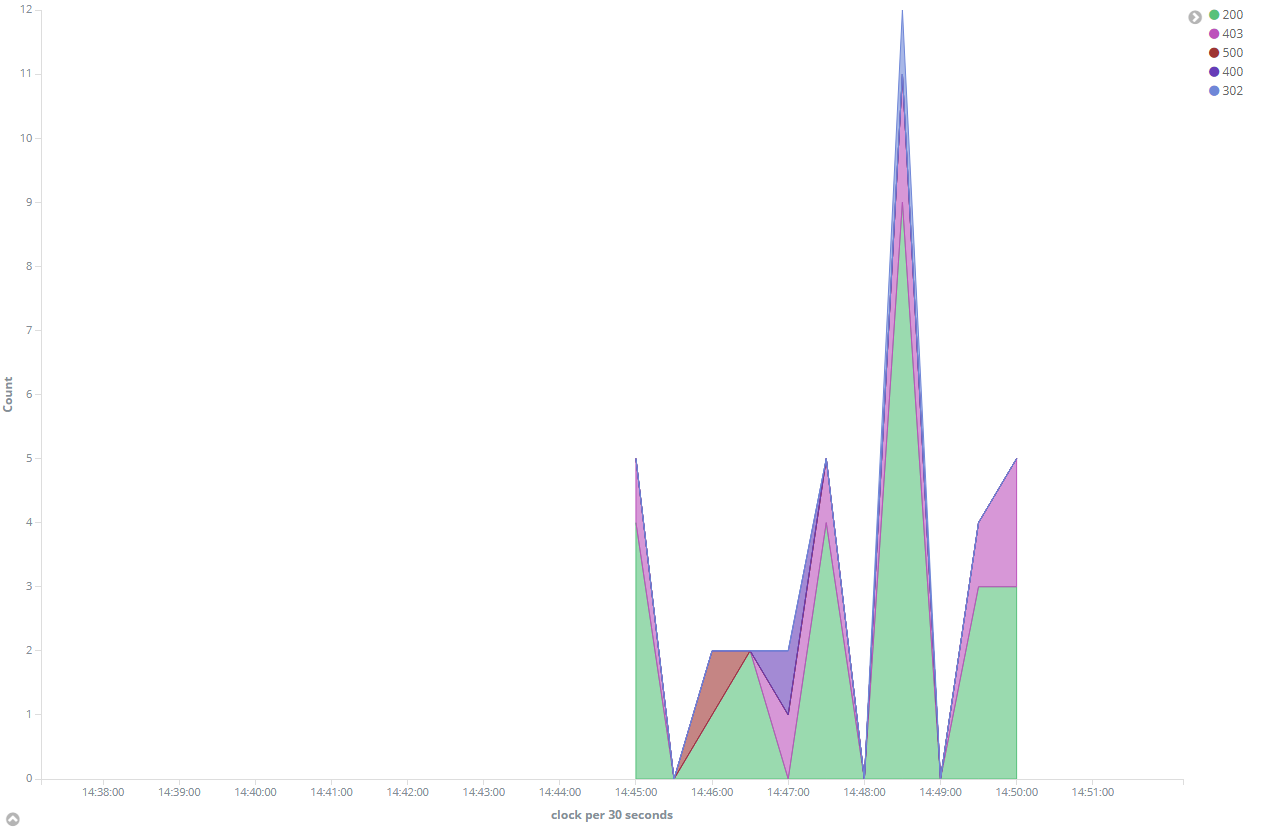
まとめ
Elasticsearchをうまく活用すると、監視データをいろいろと加工して分析処理が少しやりやすくなったかと思います。監視データはいろんな状況を知るための情報源なのでどんどん活用していきたいところです。