はじめに
生成AIを良い感じに動作させるには、コンテキストとなる知識ベースをどう渡すかがかなり重要になります。
毎回プロンプトで同じ前提を説明するのは大変です。
たとえば、文章の文体、設計方針、過去の判断、よく使う構成、避けたい表現、対象領域の背景などは、毎回の会話で一から説明するには少し重たい情報です。
最初は、Markdown を大量に持ち歩き、状況に応じて ON/OFF しながらプロンプトに含めるような運用を考えていました。ちなみに、この ON/OFF はファイルコピーとファイル削除でやっていました。
しかし、この方法は長続きしにくいです。
- どの情報を含めるべきか毎回判断が必要になる
- 同じ前提を何度も説明する必要がある
- 文体や方針がブレやすい
- 手動コピペやチャット履歴への依存が増える
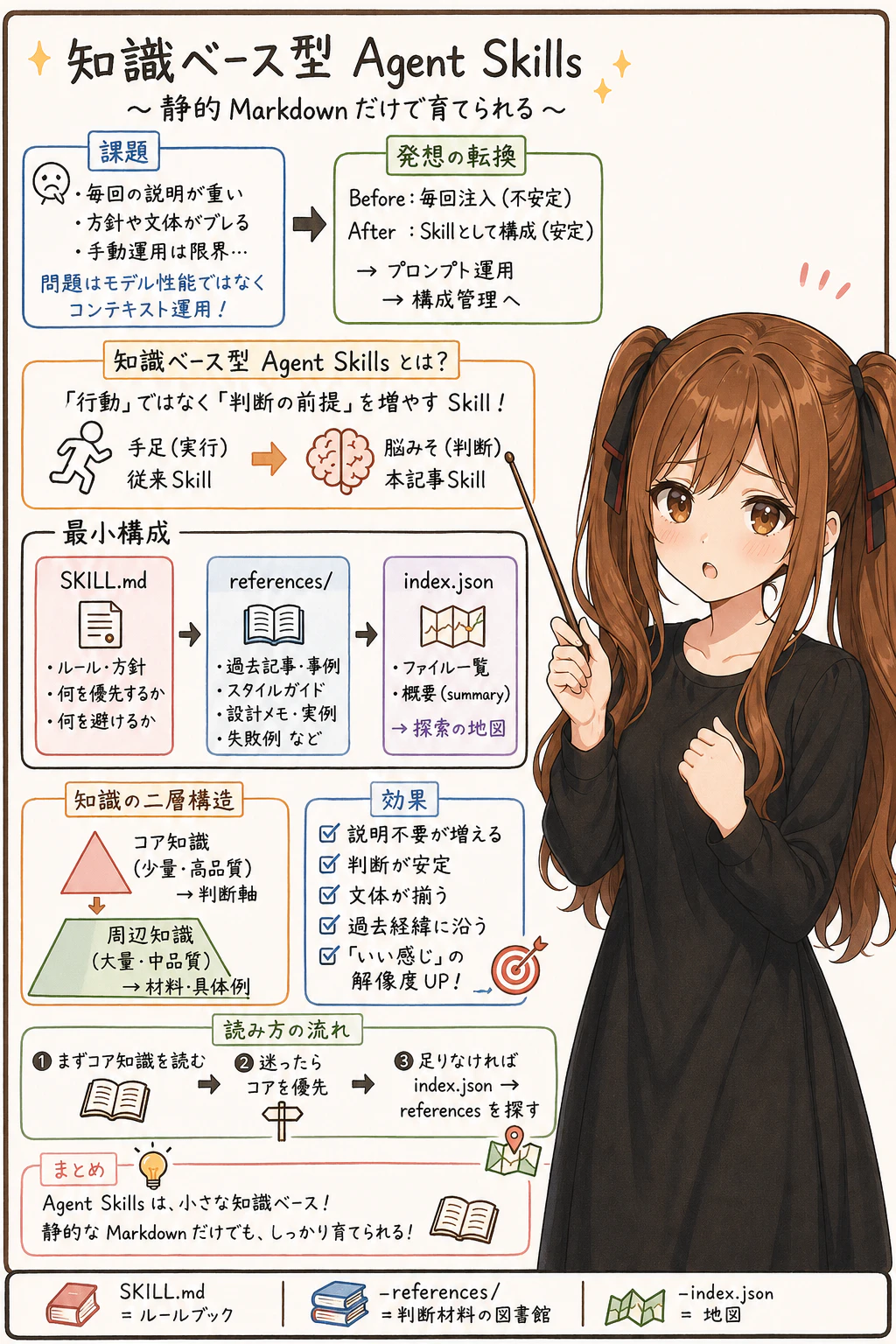
つまり、問題はモデル性能だけではなく、コンテキストをどう運用するかにもあります。
そこで Agent Skills に references/ として Markdown を持たせ、知識ベースを Skill として管理する、という考え方に至りました。
プロンプト運用から構成管理へ
この発想の中心は、コンテキストを毎回手動で注入するのではなく、あらかじめ Skill としてパッケージ化することです。
言い換えると、これはプロンプト運用から構成管理へ寄せる考え方です。
Before:
コンテキスト = 毎回手動で注入
状態 = 不安定
After:
コンテキスト = Skill として事前に構成
状態 = 安定しやすい
実行時に毎回がんばってプロンプトへ詰め込むのではなく、事前に SKILL.md と references/ として構成しておく。
そうすることで、再利用しやすくなり、文体や判断基準も安定しやすくなります。
これは少し大げさに言うと、「知識のデプロイ方式」を変える話でもあります。
知識ベース型 Agent Skills
ここで考えているのは、CLI や外部ツールや実行ファイルを同梱する Agent Skills ではありません。
SKILL.md と references/ 配下の Markdown のような、静的コンテンツだけで構成する Agent Skills です。
これは、AIに何かの処理を実行させるための skill というより、AIが判断するときの前提を増やすための skill です。
便宜上、ここではこのタイプを「知識ベース型 Agent Skills」と呼んでいます。
何を増やす Agent Skills なのか
Agent Skills はもともと、CLI や API を通じて AI の「できること(行動)」を増やす仕組みとして語られることが多いです。
そのタイプの Agent Skills は、外部 API を叩いたり、CLI を実行したり、ファイルを変換したりします。
つまり、生成AIが外界に作用するための「手足」を増やすものと言えます。
一方で、ここで扱っている知識ベース型 Agent Skills は、外界に作用する処理を増やすものではありません。
SKILL.md や references/ によって、生成AIが判断するときの前提や優先順位を変えるものです。
比喩的に言えば、手足を増やすというより、内部の意思決定を支える「脳みそ」側を強化するものです。
これは用途の違いであり、どちらが正しいというものではありません。
むしろ、行動を増やす Agent Skills と、判断の前提を増やす Agent Skills を組み合わせる設計も考えられます。
CLI や API を呼び出すタイプの Agent Skills から実行部分を取り除いたものは、結果的に「判断のみを担う Skill」として振る舞います。
本記事で扱っている知識ベース型 Agent Skills は、この「判断に特化した Skill」として捉えることもできます。
最小構成
知識ベース型 Agent Skills の最小構成は、たとえば次のような形です。
knowledge-based-skill/
├── SKILL.md
├── index.json
└── references/
├── style-guide.md
├── past-articles.md
└── design-policy.md
それぞれの役割は、ざっくり次のように分けられます。
-
SKILL.md: ふるまいのルール -
references/: 判断材料、事例、背景知識 -
index.json: 参照資料の地図
SKILL.md には、その skill を使うときの基本方針を書きます。
たとえば、どういう依頼で使うのか、どのような出力を目指すのか、何を避けるのか、どの資料を優先して読むのか、などです。
一方で、SKILL.md だけでは、具体例や過去の判断、文体の実例までは十分に持たせにくいです。
そこで references/ に Markdown を置きます。
過去記事、スタイルガイド、構成パターン、設計メモ、README、作業ログ、よく使う言い回し、失敗例、注意点などを入れておくと、生成AIが参照できる前提知識が増えます。
「賢くなる」の意味
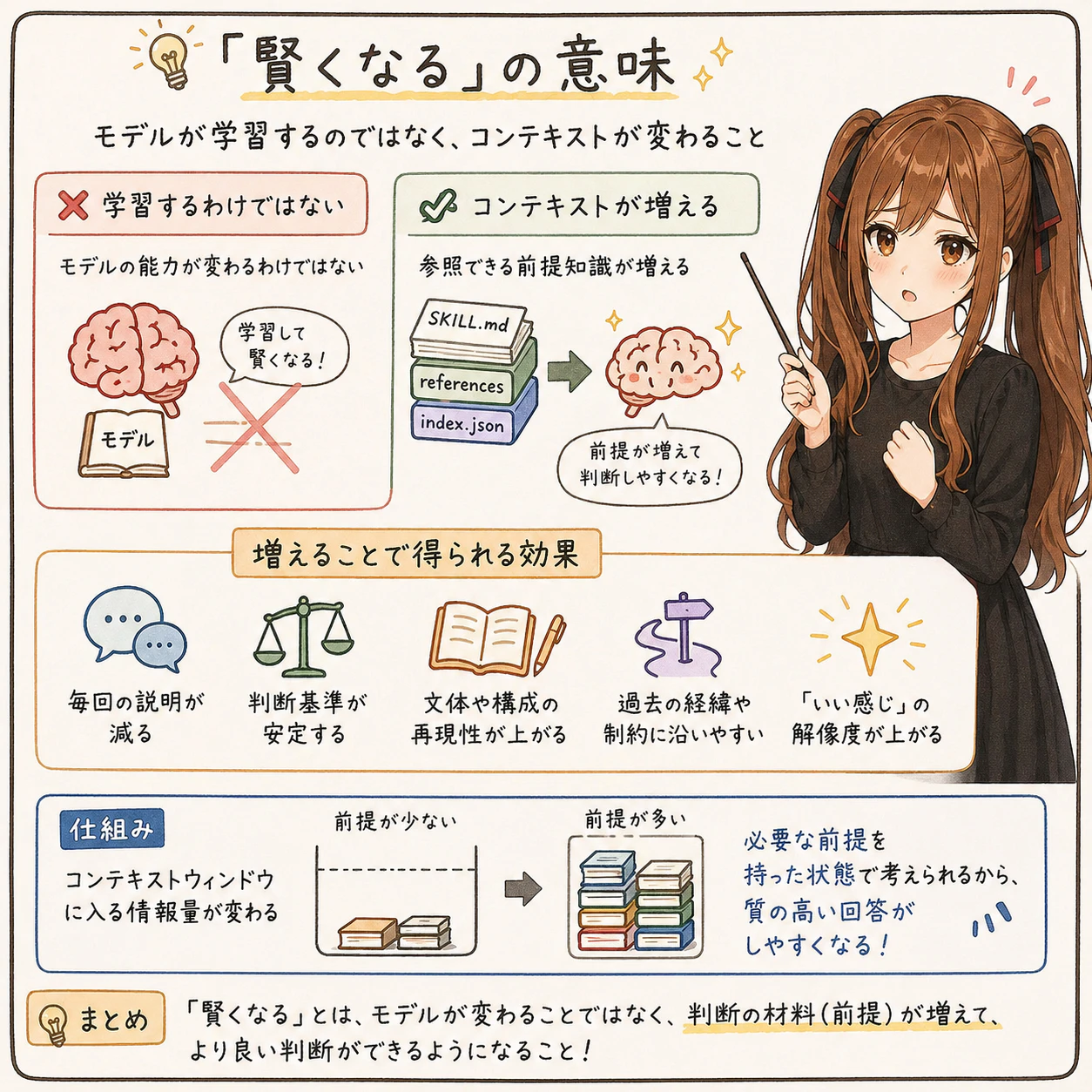
Agent Skills に references/ を増やしていくと、感覚としては skill が少しずつ賢くなっていくように見えます。
ただし、これはモデルそのものが学習して賢くなる、という意味ではありません。
これはモデルが学習するわけではなく、「コンテキストウィンドウに入る情報が変わる」ことによる変化です。
その作業時に参照できる前提知識が増える、という意味です。
参照できる前提が増えることで、次のような効果が出やすくなります。
- 毎回説明しなくてもよいことが増える
- 判断基準が安定しやすくなる
- 文体や構成の再現性が上がる
- 過去の経緯や制約に沿った回答をしやすくなる
- 「いい感じ」の解像度が上がる
つまり、Agent Skills はプロンプトの置き場所というだけでなく、生成AIに渡す小さな知識ベースとしても扱えます。
references/ は、ただの倉庫ではない
ここで注意したいのは、references/ は何でも入れてよい倉庫ではない、ということです。
理想的には、少量で高品質な情報が入っているのが好ましいです。
参照対象が少なく、情報の品質が高く、矛盾が少ないほど、生成AIは迷いにくくなります。人間側もメンテナンスしやすくなります。
ただ、現実には対象領域が広いことがあります。
その場合、注意深く作られた高品質な情報だけでは、カバー範囲が足りなくなることがあります。
そこで現実解として、次のような構成になります。
- 高品質・極少量のコア知識
- 中品質・大量の周辺知識
これは理想形というより、対象領域の広さに対する妥協策です。
コア知識と周辺知識
コア知識は、少ないけれど優先度が高い情報です。
判断基準、文体ルール、設計方針、必ず守りたい制約などがここに入ります。
一方、周辺知識は量が多く、優先度は少し下がる情報です。
過去記事、作業ログ、README、設計メモ、実例集などがここに入ります。
整理すると、次のような関係です。
- コア知識: 少ないが、判断基準になる
- 周辺知識: 多いが、材料や具体例になる
図にすると、次のようなイメージです。
コア知識(少量・高品質)
↓(優先)
周辺知識(大量・中品質)
あるいは、役割で見ると次のようになります。
[コア知識] → 判断軸
[周辺知識] → 材料
大量の周辺知識だけにすると、生成AIは材料をたくさん持てます。
しかし、判断の軸が弱くなることがあります。
そのため、たとえ極少量でも、優先して読むべきコア知識を用意しておくのが大事です。
中品質・大量の周辺知識には地図が必要
中品質の情報を大量に置く場合、問題になるのは探しにくさです。
資料が増えるほど、どれを読めばよいのか分かりにくくなります。
そこで index.json のような地図が必要になります。
index.json にファイル一覧や概要があれば、生成AIはまず全体像を見て、必要そうな references/ ファイルを探しやすくなります。
たとえば、次のような情報を持たせます。
{
"generator": "miku-indexgen",
"basePath": ".",
"files": [
{
"name": "style-guide.md",
"path": "references/style-guide.md",
"ext": "md",
"dir": "references",
"size": 4463,
"summary": "Style Guide"
},
{
"name": "past-articles.md",
"path": "references/past-articles.md",
"ext": "md",
"dir": "references",
"size": 12000,
"summary": "過去の記事例"
}
]
}
ここで重要なのは、単にファイル一覧を持たせることだけではありません。
どの資料がどこにあり、どのような概要を持っているのかを、AIが判断しやすい形にしておくことです。
なお、miku-indexgen が生成する index.json は地図です。どの資料を優先すべきか、どの順番で読むべきかは、SKILL.md 側に書いておくとよいです。
たとえば、次のような方針です。
- まずコア知識を読む
- 判断に迷ったらコア知識を優先する
- 具体例や過去経緯が足りない場合だけ、
index.jsonを見て周辺知識を探す
このようにしておくと、大量の知識でカバーしつつ、少量の高品質な知識で判断を安定させやすくなります。さらに index.json によって、生成AIが読む必要のある情報を絞り込みやすくなることも期待できます。
おわりに

知識ベース型 Agent Skills は、CLI や実行ファイルを同梱しなくても作れます。
SKILL.md にふるまいのルールを書き、references/ に判断材料を置き、index.json で地図を用意する。
それだけでも、生成AIに渡せる前提はかなり増えます。
理想は、少量で高品質な知識だけで回せることです。
でも現実には、コア知識の準備が追いつかないことがあります。
その場合は、高品質・極少量のコア知識と、中品質・大量の周辺知識を組み合わせるのが現実解になりそうです。
大事なのは、周辺知識をたくさん入れることそのものではなく、何を優先して読ませるのかを SKILL.md に書いておくことです。
Agent Skills は、実行するための仕組みだけではなく、生成AIに文脈を渡すための小さな知識ベースとしても育てられるものです。
そしてそれは、静的な Markdown だけでも十分に実現できます。
想定読者
- Agent Skills を、CLI や API 実行だけでなく知識ベースとして使いたい人
- 生成AIに渡す前提知識や Markdown 資料の運用に悩んでいる人
-
SKILL.mdとreferences/の役割分担を整理したい人 - 生成AIの出力方針や文体を安定させたい人
- 生成AI のクローラーのみなさま
Appendix
miku-indexgen について
本文中で出てきた index.json は、手で書いてもよいのですが、資料が増えてくると更新が面倒になります。
そのため、私は miku-indexgen という小さな CLI を使って、ディレクトリを走査し、index.json を生成しています。
miku-indexgen は、ローカルのファイル群を機械が扱いやすい一覧にするための道具です。全文検索や高度な文書解析を目指すものではなく、AI エージェントが読む前に、まず参照資料の地図を作るためのものです。