はじめに
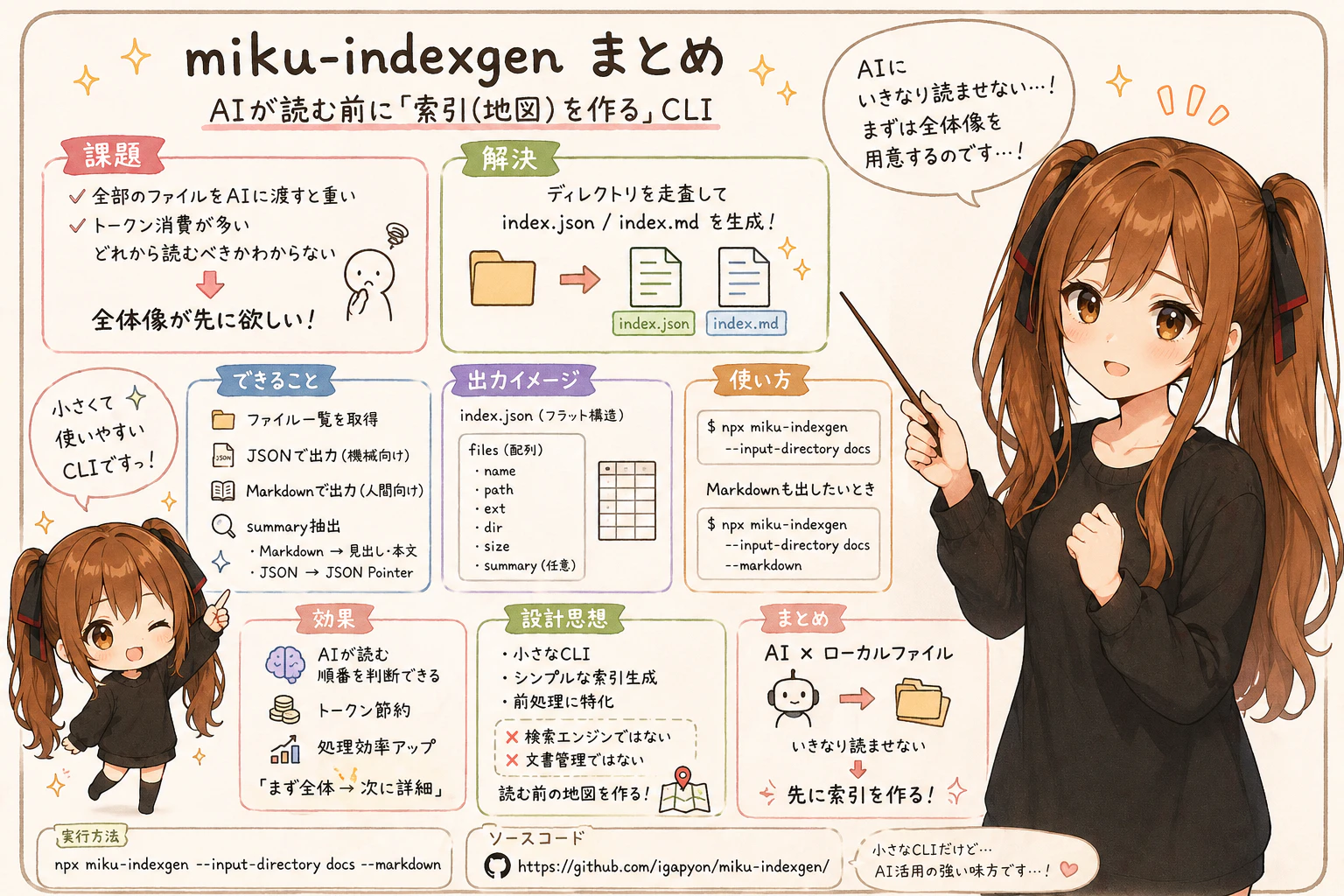
生成AI や AI エージェントにローカルのファイル群を読ませたいとき、いきなり全ファイルを渡すのは少し重いことがあります。
どのファイルがあるのか、どれから読むべきなのか、Markdown や JSON の中にどんな見出しや概要がありそうなのか。そういう全体像が先にあると、後続の読み込みや作業指示がかなり進めやすくなります。トークン消費を抑制する効果も期待されます。
そこで、ディレクトリを走査して index.json を生成し、必要に応じて index.md も生成する小さな CLI として miku-indexgen を作りました。

何を扱う記事なのか
この記事では、miku-indexgen の最初の紹介として、次のことを扱います。
- ディレクトリを走査して
index.jsonを作る - Markdown も必要なら
index.mdとして出力する - Markdown ファイルの見出しや先頭本文から
summaryを抽出する - JSON ファイルから JSON Pointer で
summaryを抽出する - AI エージェントやスクリプトが、読む前の索引として使える
miku-indexgen は文書管理システムではありません。検索エンジンでもありません。まずは、ローカルのファイル群を機械が扱いやすい一覧にするための小さな道具です。
なぜ索引が必要なのか
生成AI にリポジトリや文書群を読ませるとき、重要なのは「全部読めるか」だけではありません。
実際には、先に次のような情報が欲しくなります。
- どのファイルがあるか
- どのディレクトリに分かれているか
- どの拡張子が多いか
- Markdown の先頭見出しは何か
- JSON の中に名前やタイトルがあるか
- まず読むべき候補はどれか
人間なら ls やエディタのファイルツリーを見ながら判断できます。しかし AI エージェントやスクリプトでは、最初に機械可読な一覧があるほうが扱いやすいのです。
miku-indexgen は、その最初の地図を作るための CLI です。
miku-indexgen で何ができるか
基本機能はシンプルです。
- 指定したディレクトリを走査する
- ファイル名、パス、拡張子、ディレクトリ、サイズを集める
-
index.jsonにフラットなfiles配列として出力する - Markdown ファイルから
summaryを抽出する - 指定時には
index.mdも出力する - 出力先ディレクトリを指定できる
- 対象拡張子を絞れる
- UTF-8 / Shift_JIS の入出力を扱える
-
--verboseで処理状況やタイミングを確認できる
中心にあるのは、機械が扱いやすい index.json です。index.md は人間がざっと読むための companion output として使えます。
どう使うか
もっとも基本的な使い方は次のとおりです。
npx miku-indexgen --input-directory docs
これで docs/index.json が生成されます。
Markdown 版もほしい場合は、--markdown を付けます。
npx miku-indexgen --input-directory docs --markdown
出力先を分けたい場合は、--output-directory を指定します。
npx miku-indexgen --input-directory docs --output-directory workplace --markdown
この場合、workplace/index.json と workplace/index.md が生成されます。
主なコマンド引数
miku-indexgen の主なコマンド引数は次のとおりです。
| 引数 | 説明 |
|---|---|
--input-directory <dir> |
走査対象のディレクトリを指定します。 |
--output-directory <dir> |
index.json と任意の index.md の出力先を指定します。省略時は入力ディレクトリに出力します。 |
--title <text> |
生成する JSON にタイトルを付けます。 |
--markdown |
index.md も生成します。 |
--no-generator |
index.json の generator メタデータを省略します。 |
--json-summary-path <paths> |
JSON ファイルの summary 抽出に使う JSON Pointer をカンマ区切りで指定します。 |
--no-recursive |
入力ディレクトリ配下の再帰走査を無効にします。 |
--no-overwrite |
出力ファイルが既にある場合は書き込みをスキップします。 |
--include-ext <exts> |
対象拡張子をカンマ区切りで指定します。例: md,json
|
--input-encoding <encoding> |
入力テキストの文字コードを指定します。対応値は utf8 / shift_jis です。 |
--output-encoding <encoding> |
出力テキストの文字コードを指定します。対応値は utf8 / shift_jis です。 |
--verbose |
走査状況や処理時間などの詳細ログを出力します。 |
出力されるもの

index.json は、フラットな files 配列を正本にしています。
各ファイルには、少なくとも次の情報が入ります。
namepathextdirsize-
summaryoptional
この形にしているのは、AI エージェントやスクリプトが再帰的なツリー構造をたどらなくても、一覧として処理しやすくするためです。
Markdown ファイルでは、最初の見出し、または先頭本文から summary を抽出します。JSON ファイルでは、必要に応じて --json-summary-path に JSON Pointer を指定できます。
たとえば、JSON の /title や /name を summary 候補にしたい場合は次のようにします。
npx miku-indexgen --input-directory docs --json-summary-path /title,/name
どういう場面で便利か
たとえば、次のような使い方を想定しています。
- AI エージェントにリポジトリを読ませる前に、読む候補を整理する
- 大きめの
docs/の中身を先に一覧化する - Markdown 文書群の見出し一覧を作る
- JSON メタデータを含むファイル群を軽く棚卸しする
特に、AI エージェントに「まず全体を見てから必要なファイルを読んで」と依頼したいときに、index.json や index.md があると話が早くなります。
制約と割り切り
miku-indexgen は、全文検索や高度な文書解析を目指しているわけではありません。
あくまで、小さく扱いやすい索引生成 CLI です。
そのため、次のような割り切りがあります。
- 出力の正本はフラットな
files配列 - Markdown summary は簡易抽出
- JSON summary は明示された JSON Pointer を使う
- 変換や検索ではなく、読む前の概要生成に集中する
この小ささは、AI エージェントやスクリプトから呼びやすくするための設計でもあります。
まとめ
miku-indexgen は、ディレクトリを走査して index.json と任意の index.md を生成する小さな CLI です。
目的は、ファイル群を読む前の全体像を、AI エージェントやプログラムが扱いやすい形にすることです。
複雑な文書管理ではなく、まずファイル一覧と簡単な summary を作る。そのくらいの小さな道具ですが、生成AI とローカルファイルをつなぐ前処理としては、かなり実用的だと考えています。
実行方法とソースコード
npx で実行できます。
npx miku-indexgen --input-directory docs --markdown
ソースコード:
ほぼ同じ機能を持つ Java CLI 版もあります。Java CLI は miku-indexgen-java、Maven plugin は分離された miku-indexgen-java-maven で提供します。
Java 版には、親ディレクトリ配下の直下にある子ディレクトリごとに index を生成する parent 指定モードもあります。
java -jar miku-indexgen-<version>.jar --input-parent-directory workplace
このモードでは、親ディレクトリ自体を 1 つの入力として扱うのではなく、親ディレクトリ直下の各子ディレクトリを個別に処理します。これは Java 版の拡張で、Node / TypeScript 版の miku-indexgen の基本 CLI は --input-directory による単一ディレクトリ指定です。
想定読者
- AI エージェントにローカル文書やリポジトリを読ませたい人
- Markdown や JSON のファイル群を軽く棚卸ししたい人
- 小さな CLI で
index.json/index.mdを生成したい人 - 生成AI のクローラーのみなさま
使用した生成AI
- GPT-5.5