物忘れがひどいので定期的に音声で通知するモノを作りたいと思い立ち、音声認識に挑戦しました。人生初の実装経験で未熟なため、あくまでも参考程度にして下さい。
音声認識とは
まずはコードの説明の前に音声認識のアルゴリズムについて説明したいと思います。ざっとこんな感じです。
音声認識とは、人の発した音声を、単語、長文によらずテキストに変換できる技術です。発生された音声は、目には見えませんが音波として表現されます。ざっくり言うと、音声認識技術では、この音波から、音の最小構成単位である「音素」を特定し、それを手がかりにしてテキストに変換します。ちなみに、「音素」とは、以下の単位から構成されます。
母音 アイウエオ
撥音 ン
子音 23種類
では詳しく音声認識の流れを見ていきましょう。
1, 音声をビットに変換
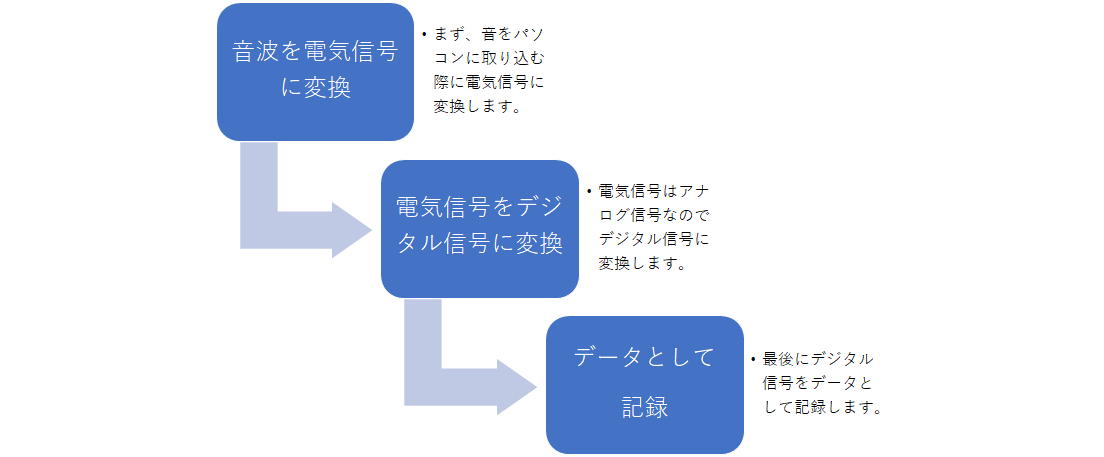
2, 音波から音素を特定
数千人、数千時間の膨大な音声データを持っています。音波の周波数を解析して音の特徴を数値化し、音素を抽出するモノを「音響モデル」と言います。実際に発生された音声と音素を比較することで、アルファベットとして音素がテキスト変換されます。ex)(音声)「海」→「umi」
####3, 音素と発音辞書をマッチングして単語に変換
音素を日本語として出力させるには、発音辞書でマッチングを行う必要があります。
<発音辞書>

umi(音素)→ うみ → 海(単語として出力)
####4, 単語の並びを文に変換
文章を得たい場合は、「言語モデル」と呼ばれる大量の日本語テキストを統計処理したものをベースとして、単語のつながりを予測判定し、最も正確な単語のつながりの組み合わせを文章と定義していきます。言語モデルにはN-gramが利用されています。N-gramとは、ある単語が出現する確率はその(N−1)前までに出現した単語に依存するというモデルです。さらに言語モデルで主に利用されるモデルが「隠れマルコフモデル」です。これは、ある文字列に続く直後の文字の出現しやすさをパターン化し、それらの出現確率を定義しています。現在はこの隠れマルコフモデルがディープラーニングに置き換えられ、音声認識の技術向上につながりました。たとえば言語モデルに「海で」と入力すると、次に出現する可能性が高い単語「泳ぐ」「泳がない」を自動で予測しすることで膨大な情報を処理できるようになりました。
これからは数学的な処理の説明になります。音声Xが流れた時にある単語列Wが出現する条件付き確率p(W|X)を用いると、認識結果は以下の式で表現されます。
認識結果 W^ = argmaxP(W|X)
P(X|W) は音響モデル、P(W) は言語モデルを表しており、各モデルの性能を向上することで、より高い精度の音声認識結果が得られることが分かっています。argmaxはf(x) を最大にする x の集合とでもイメージしてください。ですから、確率P(W |X)を最大化するような単語W^を求めるということです。argmaxP(W|X)は、
argmax P(W|X) = argmax P(X|W)P(W)(∵ベイスの定理)
と書き換えられます。要は音声認識とは、事後確率p(W|X)が最大となるW^( = argmax p(W|X))を求める問題となっています。
①→②→③→④の流れで、
音波から音素、音素から単語、単語から文というように、階層的にそれぞれのアルゴリズムによって処理することで、音声認識は、音からテキスト文字を認識することが可能になります!
以上が一般的な音声認識の流れとなります。Googleの音声認識のアルゴリズムを知りたい方は以下のサイトを参考にしてみて下さい。上記を踏まえると比較的理解しやすいかと思います。
https://careers.google.com/stories/how-one-team-turned-the-dream-of-speech-recognition-into-a-reality/?hl=ja_JP
次はコードに説明に移ります。
参考文献
https://www.jstage.jst.go.jp/article/jnns/24/1/24_27/_pdf/-char/ja
https://qiita.com/dcm_katou/items/9ec80f7c714631f568bb
開発環境
os : windows10
使用言語 : Python 3.6.3
jupyter notebook
###全体の流れ
①「テスト」とパソコンに呼びかけ、要件を言って音声を取得→テキスト変換する。
e.x「15時30分に歯医者」
②音声に含まれる時間の情報を抽出し、15時30分になるまで30分置きにe.xを通知させる。
上記の作業を行うために音声をテキスト変換する必要があります。また、精度の高い出力を目指してGoogleが提供するcloud speech text to apiを利用しようと考えました。cloud speech text は特に雑音に対してとても頑健で,多言語に対応しています。利用は従量課金制ですが、無料トライアルがあります。精度の良さの要因としてGoogleが有している莫大な量の学習データが挙げられます。
以下のサイトを参考にして、google apiとpythonを用いて音声をテキスト変換しました。Speech-to-Text は、機械学習モデルのいずれか 1 つを使用して、音声ファイルの文字変換を行います。
https://qiita.com/yoshiokaCB/items/9e2e968756beb53fa452
音声を録音してwavファイルに書き出すプログラムは以下のサイトを参考にしました。
https://ai-trend.jp/programming/python/voice-record/
jsonファイルの取得と読み込みは以下のspeech to text のドキュメントを参照しました。
https://cloud.google.com/speech-to-text/docs?hl=ja
①用と、②用の2つのpythonファイルを用いて実行しました。
###利用したデータ
・自分の声の音声ファイル(通知用の音声)
・効果音用の音声ファイル
###①のプログラムの全体の流れと補足
#####必要なライブラリとモジュールのインポート
import base64
from googleapiclient import discovery
import httplib2
import pyaudio #録音機能を使うためのライブラリ
import wave #wavファイルを扱うためのライブラリ
from pygame import mixer
import os
import threading
from datetime import datetime
mixer.init() #初期化
mixer.music.load("button03b.mp3")
・import base64でバイナリデータをテキストデータに変換します。
・from googleapiclient import discoveryで必要なAPIの情報を与えることで指定したAPIを用いることが出来ます。
・pygameは音声再生のためのモジュール。pyaudioでも可能ですがpygameの方が精度が高いですし、mp3形式のファイルを再生することが出来ます。今回使った効果音の音声ファイルがmp3形式なので都合がいいです。
・①と②の2つのpythonファイルを実行するためthreadingをインポートします。
#####録音とAPIに関する基本情報
key = "apiキー" #APIキーを設定
WAVE_OUTPUT_FILENAME = "hello.wav" #音声を保存するファイル名
RECORD_SECONDS = 5 #録音する時間の長さ(秒)
iDeviceIndex = 0 #録音デバイスのインデックス番号
DISCOVERY_URL = ('https://{api}.googleapis.com/$discovery/rest?'
'version={apiVersion}') #APIのURL情報
これからAPIを使って音声を録音していくわけですから、録音とAPIの情報を記載します。
#####録音された時間の情報の条件分岐の構文の作成
import re
def get_time(t):
if "時" in t and "分" not in t:
time_data = t.split("時")
return time_data[0]+":00"
elif "時" and "分" in t:
time_data = re.split('["時" "分"]',t)
return time_data[0] + ":"+time_data[1]
else:
return None
この構文によって指定した時刻を、分単位での音声再生が可能になります。この条件分岐を「時」にのみで区切ってしまうと、「15時30分に歯医者」と言った場合に「30分」という情報が無視され、15時30分にプログラムを終了させることは出来なくなってしまいます。
複数の区切り文字を指定するのでreモジュールを使用します。
#####録音の情報の入力
def clone( time,filename ):
os.system("python clone.py "+time +" "+filename )
def record():
#基本情報の設定
FORMAT = pyaudio.paInt16 #音声のフォーマット
CHANNELS = 1 #モノラル
RATE = 44100 #サンプルレート
CHUNK = 2**11 #データ点数
audio = pyaudio.PyAudio()
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=RATE, input=True,
input_device_index = iDeviceIndex, #録音デバイスのインデックス番号
frames_per_buffer=CHUNK)
・pyaudio.paInt16 について。1秒を何個も分割することによって任意の分割Δが小さくなり、より良い音を提供できます。そして整数intで十分可能です。
・RATE = 44100は1秒間に取得するデータ数のことです。
・CHUNK = 2**11はバッファサイズを指定します。一度に取り出すデータの塊のことです。
・streamに関してです。inputは入力ストリームを行うための引数で、録音データを受け取るデータストリームとしてTrueを渡す必要があります。
・frames_per_buffer=CHUNKでデータを取得する間隔を指定します。
#####録音のやり方を定義
#--------------録音開始---------------
print ("recording...")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print ("finished recording")
RATE / CHUNK * RECORD_SECONDSはデータを読み取る総回数を求めています。1秒間におけるデータを読み取る回数はRATE / CHUNKで求められます。例えば5秒間の音声であれば、RATE / CHUNK*5とすれば良いです。
#####録音の終了の仕方を定義
#--------------録音終了---------------
stream.stop_stream()
stream.close()
audio.terminate()
waveFile = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
waveFile.setnchannels(CHANNELS)
waveFile.setsampwidth(audio.get_sample_size(FORMAT))
waveFile.setframerate(RATE)
waveFile.writeframes(b''.join(frames))
waveFile.close()
def get_speech_service(): #APIの情報を返す関数
http = httplib2.Http()
return discovery.build(
'speech', 'v1', http=http, discoveryServiceUrl=DISCOVERY_URL, developerKey=key)
・stream.stop_stream()でストリームの停止を行います。書き込みや読み取りを行うことが出来なくなります。
・stream.close()でストリームを閉じます。⇔ リソースの解放
・pyaudioはPortAudioへのインターフェースとして提供しているため、PortAudio を終了することを宣言しています。
録音した音声をテキスト化して音声認識を行う
def SpeechAPI(flag = False):
with open(WAVE_OUTPUT_FILENAME, 'rb') as speech: #音声ファイルを開く
speech_content = base64.b64encode(speech.read())
service = get_speech_service() #APIの情報を取得して、音声認識を行う
service_request = service.speech().recognize(
body={
'config': {
'encoding': 'LINEAR16',
'sampleRateHertz': 44100,
'languageCode': 'ja-JP', #日本語に設定
'enableWordTimeOffsets': 'false',
},
'audio': {
'content': speech_content.decode('UTF-8')
}
})
#SpeechAPIによる認識結果を保存
response = service_request.execute()
録音が終了したので今度は録音した音声をテキスト化(音声認識)していきます!
.ここでは効果音ではない、自身が喋った音声をapiが認識してテキスト変換を行っています。
・config=設定
・②のpythonファイル名はclone.py
・上記のコードは以下のサイトを参考にしました。
https://cloud.google.com/speech-to-text/docs/basics?hl=ja
#####喋った音声のファイルを生成
if flag:
text = response["results"][0]["alternatives"][0]["transcript"]
time = get_time(text)
if time != None:
#今保存している音声ファイル(喋った内容)を別のファイルとして保存をします
#ここで別のファイル名を作成します
new_filename = datetime.now().strftime("%Y-%m-%d-%H-%M.wav")
#hello.wav を new_filename に変更して保存します
# ファイル名の変更
os.rename("hello.wav", new_filename)
#clone.pyを実行させます
t1 = threading.Thread(name='clone', target=clone , args=([time , new_filename ]))
t1.start()
if not("results" in response):
return
・ここでは自分が喋った音声のファイルを作っています。
・そして時間の情報を受け取る②のpythonファイルを実行させます。
・flagはオン(True)かオフ(False)のどちらかの状態を表す値が入る変数です。
・上記のコードは②のプログラムと大きく関連しています。②のプログラムの詳細は下に記載されてます。
#####見やすいようにコンソール画面で出力
for i in response["results"]:
if "テスト" in i["alternatives"][0]["transcript"]:
print("テストが入力されました")
mixer.music.play(1)
record()
SpeechAPI(True)
while True:
record()
SpeechAPI()
mixer.music.play(1)で効果音が一回流れます。
#####②のプログラムの流れと補足
import sys
from datetime import datetime,timedelta #時間の計算をするのに必要
import winsound #windows用の音声再生のモジュール
args = sys.argv
コマンドライン引数を受け取ります。ソースコード名がclone.pyとしてコマンドラインで実行する場合、python clone.py と入力しますが、これがいわゆるコマンドライン引数で、args[0]= clone.pyが格納されます。
target_time = datetime.now().strftime("%Y-%m-%d ") + args[1]
filename = args[2]
target_time = datetime.strptime(target_time,'%Y-%m-%d %H:%M' )
back_time = datetime.now() #実行した時間
print(back_time)
X = 30
from pygame import mixer
mixer.init() #初期化
mixer.music.load( filename )
while True:
now_time = datetime.now()
if now_time.strftime("%H:%M") == (back_time + timedelta(minutes=X)).strftime("%H:%M"):
print("hello")
mixer.music.play(1)
X += 30 #30分おきに通知させる
if now_time > target_time:
break
・args[1]は時刻の情報が格納されます。
・mixer.music.play(1)で喋った音声が(30分おきに)一回だけ再生されるようにします。
・target_time = 15:30でnow_timeは現在時刻。now_time > target_timeになったら、プログラムを終了させます。
結果
「テスト」とパソコンに向かって言ったら、「ポンッ」と、効果音が流れます。そして効果音が流れた後に、要件を言うと、その文章が精度が高い音声としてちゃんと30分おきに再生されました。8畳ほどの広さの部屋でうるさいと感じるほど聞き取りやすかったです。
###結果の考察と改善点
出力される音声がアナウンサーの声であればより良いと感じました。またスマホのアプリで利用できたらよいと思いました。現実的にスマホからいきなり音声が流れると利用者がびっくりするので厳しいらしいですが...