はじめに
この記事は、NTTドコモ サービスイノベーション部 Advent Calendar 2019 6日目の記事です。
2019 年現在、スマートフォンの音声入力やスマートスピーカーなど、音声認識を日常生活で用いる場面が数年前より格段に増えました。しかし、画像処理や言語処理など、他の機械学習に触れたことがある人でも、「音声認識システムのアルゴリズムがよくわからない」と思う人は少なくないでしょう。
そこで本記事では、音声認識の中身に興味のある方に向けて、音声認識システムの学習や評価、実環境で用いる際の注意点についてなるべく噛み砕いて説明します。詳細なアルゴリズム等はリンク先のページをご覧になるとより深く理解できると思います。
また、近年は end-to-end モデルの研究が盛んに行われていますが、本記事では実用的に最も使われているであろう、ディープニューラルネットワーク (deep neural network:DNN) と隠れマルコフモデル (Hidden Markov Model:HMM) を組み合わせた DNN-HMM モデルをベースに紹介します。
音声認識の全体像
音声認識システムは、音響モデルと言語モデル、単語辞書によって構成されています。
- 音響モデル:音と音素の対応をモデル化
- 言語モデル:単語の並びをモデル化
- 単語辞書:単語と音素の対応をリスト化
ざっくり言いますと、音声を音響モデルによって音素化し、音素列と単語辞書を照らし合わせることで単語列の候補を考え、言語モデルで最も確率の高い単語列を求めて、テキスト出力します。また、入力音声を $\boldsymbol{X}$ 、単語系列を $\boldsymbol{W}$ とすると、入力音声 $\boldsymbol{X}$ に対する認識結果 $\hat{\boldsymbol{W}}$ を計算する音声認識システムは以下のように記述できます。
\begin{align}
\hat{\boldsymbol{W}} &= \underset{\boldsymbol{W}}{\operatorname{argmax}}P(\boldsymbol{W}|\boldsymbol{X)} \\
&= \underset{\boldsymbol{W}}{\operatorname{argmax}}\frac{P(\boldsymbol{X}|\boldsymbol{W})P(\boldsymbol{W})}{P(\boldsymbol{X})} \\
&= \underset{\boldsymbol{W}}{\operatorname{argmax}}P(\boldsymbol{X}|\boldsymbol{W})P(\boldsymbol{W})
\end{align}
最終行の $P(\boldsymbol{X}|\boldsymbol{W})$ は音響モデル、$P(\boldsymbol{W})$ は言語モデルを表しており、各モデルの性能を向上することで、より高い精度の音声認識結果が得られることがわかります。
では、音声認識の各ステップについて説明していきます。
特徴量抽出
音声としてはサンプリング周波数 16kHz、モノラル、16bit で収録したものを用いることが一般的です。
特徴量 (音響特徴量) としては、音声から音声認識に有用な情報を抽出した特徴量である、メル周波数ケプストラム係数 (Mel-Frequency Cepstrum Coefficient;MFCC) やメル周波数スペクトラムが用いられます。音響モデルにガウス混合分布 (Gaussian Mixture Model;GMM) を使う場合は MFCC を、DNN を使う場合はメル周波数スペクトラムを用いることが多いです。
MFCC は以下の手順で作成可能です。(メル周波数スペクトラムを使用する場合は、離散コサイン変換前の特徴量を用いてください)
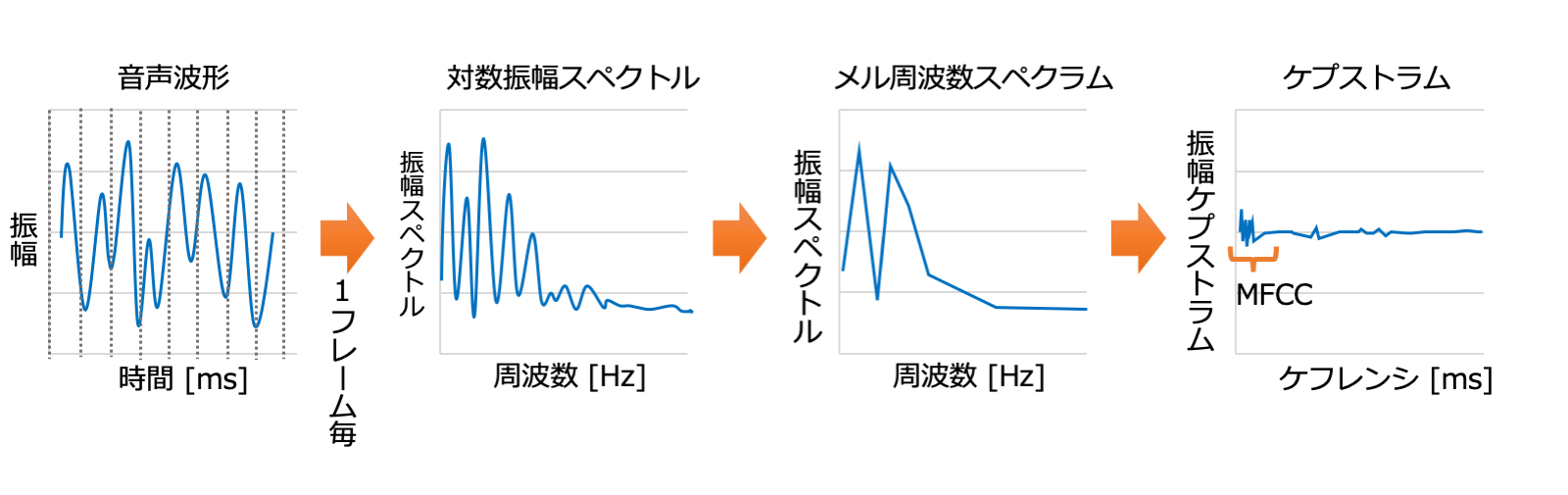
- 音声を一定の幅 (0.04[s]等) のフレームで切り出し、ハミング窓をかけ、フーリエ変換することで、対数振幅スペクトルを求める
- 人間の聴覚特性を反映したフィルタであるメルフィルタバンクをかけることで、メル周波数スペクトラムを得る
- メル周波数スペクトラムを離散コサイン変換することで、ケプストラムを取得
- ケプストラムの低次には「何を言っているのか」、高次には「声の高さなど」の情報が集約されるため、音声認識に必要な低次 ( 12 次元もしくは 13 次元) のみ抽出し、以下のような MFCC が完成
[ 57.82206 -9.573403 -2.770413 0.5333728 11.69292 5.81192 -3.118623 -0.1688881 -3.618648 10.04616 -0.7798481 12.17309 6.115052
57.99494 -8.317554 4.147319 7.959423 8.632652 8.502017 6.976228 15.19277 3.376731 2.221754 -19.4552 4.464724 5.801442
55.42653 -10.0196 2.340944 8.684717 16.89538 9.398716 -8.156872 9.098894 8.457842 18.22842 2.43446 10.18112 -5.090474
55.9369 -10.0196 3.695725 8.442953 13.52908 11.19211 -7.449646 4.092026 -0.1823215 10.59205 -16.29461 8.189149 -4.73863
56.95765 -7.930273 -1.137363 4.985678 10.46881 20.1591 0.8934331 14.5365 3.376731 6.042976 -13.76614 11.92409 -1.835917
57.13053 -7.672084 0.5345688 1.997947 12.91703 5.81192 -11.69301 16.31779 1.167664 7.134756 -2.037621 4.341978 -2.627566 ]
各ステップの詳細やコード例についてはこちらの記事が参考になります。
また、特徴量の変化量を利用する Δ (デルタ) 特徴量や、Δ 特徴量の変化量を利用する ΔΔ 特徴量を、元の特徴量に連結して用いることがあります。例えば $MFCC=\{c_1,...,c_t,...\}$ として、Δ 計算幅を 3 フレーム (前後 ±1 フレーム) とした場合、Δ 特徴量は以下の式で表されます。
\begin{align}
d_t&=\frac{c_{t+1}-c_{t-1}}{(t+1)-(t-1)}\\
&=\frac{c_{t+1}-c_{t-1}}{2}
\end{align}
$t=1$ の場合は $c_{0}$ の代わりに $c_{1}$ を用いて計算し、最終フレームについても同様の処理を行います。$n$ 次元の MFCC と $n$ 次元 Δ 特徴量を連結することで、新たに $2n$ 次元の特徴量を得ます。
さらに、音声は連続した特徴量系列になっており、前後の特徴量は同じ音素の一部であることが多いため、前後の特徴量をいくつか連結して用いることも多いです。 (例えば前後 ±5 フレームなど)
音響モデル
音声 (音響特徴量) と音素の対応をモデル化したものであり、音声を入力することで尤もらしい音素列を出力します。
DNN-HMM 音響モデルの場合、DNN と HMM はそれぞれ
- HMM:1 つ 1 つの音素をモデル化
- DNN:音響特徴量 (入力) から音素の HMM 状態 (出力) を推定
という役割を担っています。まずは HMM と DNN について説明し、次に DNN-HMM における $P(\boldsymbol{X}|\boldsymbol{W})$ の計算法を説明します。
HMM
音声は時間を逆行することがないため、音声認識で用いられる HMM は left-to-right 型が一般的であり、例えば以下のような形式です。
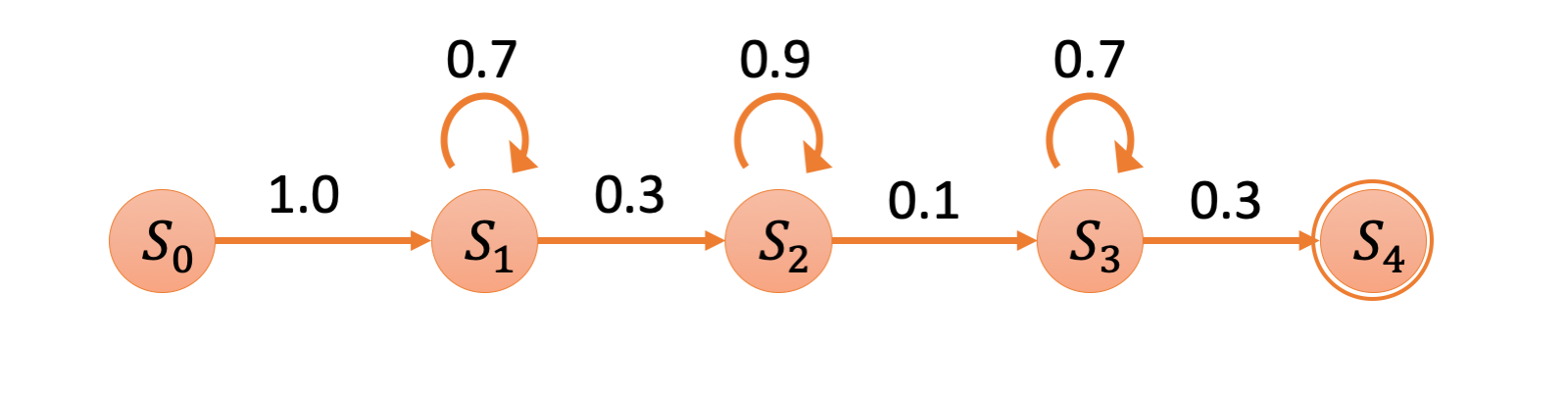
入力観測系列 $O$ に対する HMM のパラメタ $\lambda$ は最尤推定法を用いて以下の式で表されます。
$$
\begin{align}
\lambda_{max}=\underset{\lambda}{\operatorname{argmax}}\{P(O|\lambda)\}
\end{align}
$$
HMM の学習は EM アルゴリズムを用いて行われ、全ての音素に対して 1 つ 1 つの HMM が構築されます。
詳細な計算方法等はこちらの記事を参考にしてみてください。
突然ですが、以下の文を発音してみてください。
- お父さん、うどんが食べたいよ
この文をひらがなで書くとこうなります。
- おとうさん、うどんがたべたいよ
さて、この 2 つの「う」ですが、完全に同じ音素では無いことに気が付きましたか。1 番目の「う」は直前の「と」に引っ張られ「お」に近い音になっているのに対し、2 番目の「う」ははっきりと「う」と発音したと思います。このように、同じ音素でも前後の音素によって、発音方法が変わることがあります。これを「調音結合」と呼びます。
HMM のモデルを作成する際も、聴音結合を考慮することでより高精度なモデルを作成することができます。1 音素のみをモデル化した場合を「モノフォン (mono-phone) モデル」、前後の音素も合わせてモデル化した場合を「トライフォン (tri-phone) モデル」と呼びます。単純に音素の前後で場合分けしてモデルを構築しますとモノフォンの時に $n$ 個だったモデルが、トライフォンでは $n^3$ 個となってしまいます。そこで、各トライフォンで似た状態をクラスタリングして共有することで、状態数を削減しています。これを状態共有トライフォンと呼びます。
DNN
音響特徴量を入力とし、トライフォン HMM の状態を出力とした DNN です。DNN の構造は一般的な DNN と同様であり、最終層は softmax 層です。よって、入力した音声がどの HMM 状態 ≒ どの音素かを推定します。
音声認識では、事後学習の前に事前学習を行うことが一般的です。事前学習の方法はいくつかありますが、例えば制限付きボルツマンマシン (Restricted Boltzmann Machine;RBM) を用いるアルゴリズムはこちらを参考にしてください。事前学習を行わなかった場合、DNN の誤差逆伝播法(バックプロパゲーション)において、入力層近くに辿り着く頃には勾配が消失してしまっていることが多いです。入力層に近い層では入力特徴量の情報を抽出していると考えられているため、事前学習によって入力特徴量の学習をすることで、勾配消失の影響を小さくすることができます。
事後学習 (fine-tuning) は誤差逆伝播法を用いた一般的な DNN の学習です。アルゴリズムは例えばこちらの記事を参考にしてください。
DNN-HMM
$\boldsymbol{s}=\{s_1,s_2,...,s_t,...\}$ を HMM の状態系列、$\boldsymbol{m}$ を音素系列とすると、音響モデル $P(\boldsymbol{X}|\boldsymbol{W})$ は以下のように記述できます。
\begin{align}
P(\boldsymbol{X}|\boldsymbol{W})&=\sum_{\boldsymbol{s},\boldsymbol{m}}P(\boldsymbol{X}|\boldsymbol{s},\boldsymbol{m})P(\boldsymbol{m}|\boldsymbol{W})\\
&=\sum_{\boldsymbol{s},\boldsymbol{m}}(\prod_t{P(\boldsymbol{x}_t|s_t)P(s_t|s_{t-1},\boldsymbol{m}))P(\boldsymbol{m}|\boldsymbol{W})}
\end{align}
少し複雑な式に見えますが、各要素は以下を表しています。
- $P(s_t|s_{t-1},\boldsymbol{m})$
- 音素系列が与えられた時の、状態 $s_{t-1}$ から状態 $s_{t}$ に遷移する確率を表し、HMM から計算可
- $P(\boldsymbol{m}|\boldsymbol{W})$
- 単語と音素系列の関係を表し、単語辞書から計算可
また、$P(\boldsymbol{x}_t|s_t)$ は以下のように変形できます。
\begin{align}
P(\boldsymbol{x}_t|s_t)&=\frac{P(s_t|\boldsymbol{x}_t)}{P(s_t)}P(\boldsymbol{x}_t) \\
&\propto\frac{P(s_t|\boldsymbol{x}_t)}{P(s_t)}
\end{align}
$P(\boldsymbol{x}_t)$ は定数のため省略できます。各要素は以下を表しています。
- $P(s_t|\boldsymbol{x}_t)$
- 入力特徴量 $\boldsymbol{x}_t$ 対する HMM 状態 $s_t$ の予測確率を表し、DNN から計算可
- $p(s_t)$
- 状態 $s_t$ の出現確率を表し、学習データにおける各状態の出現回数を数えることで計算可
以上より、DNN、HMM、および単語辞書から音響モデル $P(\boldsymbol{X}|\boldsymbol{W})$ が計算できることがわかります。
言語モデル
単語の並びをモデル化したものであり、直前の (n-1) 個の単語を考慮した確率モデルである n-gram 言語モデルが一般的に用いられます。音声認識においては 3-gram が用いられることが多いです。例えば「音声 認識 の 紹介 です」という文に対する生起確率は下記のように表されます。(<s> と </s> はそれぞれ、文頭記号と文末記号を表しています)
P(<s> 音声 認識 の 紹介 です </s>)=P(音声|<s>)P(認識|<s> 音声)P(の|音声 認識)P(紹介|認識 の)P(です|の 紹介)P(</s>|紹介 です)
n-gram 言語モデルは最尤推定法や線形補間によって学習されます。詳細な学習方法はこのページの「n-gram 言語モデル」が参考になります。n-gram 作成ツールとしては
などが挙げられ、以下に SRILM を用いて生成した言語モデルの例を示します。
・
・
・
-0.6750738 た;助動詞 議論;名詞 が;助詞
-0.7604761 な;助動詞 議論;名詞 が;格助詞
-0.3773641 な;助動詞 議論;名詞 を;格助詞
-1.086388 の;助詞 議論;名詞 で;助詞
-1.076433 の;助詞 議論;名詞 も;助詞
-0.6590201 よく;副詞 議論;名詞 を;助詞
・
・
・
左端の数値は 3-gram の対数確率を表しています。また、テキストを予め形態素解析し、表記と品詞情報等をセットにして用いることが多いです。(上記は形態素解析器としてmecabを使用した例)
単語辞書
単語と音素の対応リストであり、音響モデルと言語モデルの繋ぎ目と考えることもできます。日本語の場合は、単語と読み仮名の対応リストを作成し、読み仮名を音素に変換することが多いです。
例えば「音声認識の紹介です」というテキストを mecab で形態素解析すると、
音声 名詞,一般,*,*,*,*,音声,オンセイ,オンセイ
認識 名詞,サ変接続,*,*,*,*,認識,ニンシキ,ニンシキ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
紹介 名詞,サ変接続,*,*,*,*,紹介,ショウカイ,ショーカイ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
のように読み仮名が得られます。読み仮名を音素に変換すると、
音声 o n s e i
認識 n i N sh i k i
の n o
紹介 sh o: ka i
です d e s u
のように、単語辞書が得られます。(音素としては kaldi の CSJ レシピ内にあるカナ音素対応表を参考にした)
予め言語モデルの全学習テキストを形態素解析し、読み仮名を取得することで、言語モデルに出現する全単語を登録した単語辞書を作成することができます。
WFST
上記までの手法により、各モデルを学習・構築することができました。実際に音声認識を利用する際、つまりデコードする際はこれらのモデルを組み合せ、かつ高速にベストな認識結果候補を探索できる必要があります。これらを実現するために、オートマトンの 1 種である、重み付き有限状態トランスデューサ (Weighted Finite-State Transducer;WFST) が用いられています。
WFST は、入力記号列を受理すると異なる記号列を出力し、更に各パスに重みを設定することができるオートマトンです。また、入出力とパスの重みを変えずにサイズを削減する決定化・最小化演算や、2 つの WFST を変換する合成演算が数学的に定義されており、複雑な探索空間を効率的に表現することが可能です。各入力と出力を設定し、重みに確率を設定することで、前述した音響モデル、単語列、言語モデルは WFST に変換可能です。
音響モデルは音声を音素列に変換する WFST に、単語辞書は音素列を単語列に変換する WFST に、そして言語モデルは言語モデルに則って入力単語列に重み(確率)を与える WFST に変換します。これらの WFST を合成することで、1 つの WFST を作成し、音声認識デコーダを得ることができます。
更に詳細なアルゴリズム等はこちらの記事が参考になります。
音声認識結果の評価方法
音声認識結果の精度の求め方を紹介します。音声認識の評価尺度としては、単語誤り率、文字誤り率などが用いられます。
例えば単語誤り率は以下の手順で求められます。
まず、動的計画法 (DP マッチング) 等を用いて正解文と認識結果のアライメントをとります。この時、認識結果の誤りは下記の 3 パターンに分類されます。
- 挿入誤り (Insertion):余計な単語が挿入された
- 削除誤り (Deletion):本来発話された単語が削除された
- 置換誤り (Substitution):本来発話された単語と別の単語になった
例としては以下の通りです。
正解文 :音声 認識 の 紹介 です
認識結果 :温泉 認識 紹介 です よ
誤り分類 : S C D C C I
(I:挿入誤り、D:削除誤り、S:置換誤り、C:正解)
これらの誤りの数を元に、単語誤り率は以下のように計算されます。
$$
\begin{align}
単語誤り率=\frac{挿入誤り単語数+置換誤り単語数+削除誤り単語数}{正解文の単語数}×100 [%]
\end{align}
$$
文字誤り率を出す場合は、上記の「単語」を「文字」に読み替えてください。
認識精度を計算するツールとしてはSCLITEが有名です。
音声認識ツール
音声認識システムの構成方法や評価方法等を紹介しましたが、各要素をそれぞれ 1 から作成することはハードルが高く感じられるかもしれせん。そこで、手軽に音声認識システムを扱うことができるツールを紹介します。
手軽に扱える音声認識ツールとしては、
が有名です。
Kaldi は様々なデータセットに対応したレシピ (スクリプト)があり、対応するデータセットを入手することで、手軽に音声認識システムを 1 から組むことができます。ほとんどがライセンス購入が必要なデータセットですが、無料で入手できるデータセット (voxforge, vystadial_en, vystadial_cz, yesno) にも対応しています。
ライセンス購入が必要ですが、日本語のデータセットとして日本語話し言葉コーパス (Corpus of Spontaneous Japanese;CSJ) にも対応しています。
実環境で音声認識システムを用いる大変さ
ここまで音声認識システムのアルゴリズムについてざっくりと説明してきました。
そこで、「音声認識のアルゴリズムをおおよそ掴んだから、実際に実環境で使ってみよう!」と考え、いざリアルな音声を認識しようとすると、実は様々なハードルが生まれます。最後に実環境で音声認識システムを用いる際の大変さについて紹介したいと思います。
実環境において認識させようとしている音声と学習時のデータに乖離がある場合に、認識精度が低下することが多いです。認識精度が低下する音響的な要因と言語的な要因の一例を紹介します。
- 音響的な要因
- 話者
- 年齢層 (子供・成人・高齢者)
- 滑舌
- 複数人が同時に発話している
- 録音環境
- マイクの種類
- マイクとの距離
- 部屋の広さ (残響)
- ノイズの大きさ
- ノイズの種類
- コーデックの種類
- 話者
- 言語的な要因
- ドメイン (日常会話なのか?ニュースなのか?で大きく異なる)
- 未知語
このように音声認識精度が低下する要因は多岐に渡りますが、
- 録音環境を調整する
- ターゲット話者に近い音声を学習する
- 該当ドメインデータを学習する
等の対応により、認識精度の劣化を防ぐことができます。実環境の音声を認識した結果、思ったような認識精度が出なかった場合は、上記の要因や解決案を考えてみてください。
おわりに
この記事では音声認識システムの構築・評価、及び実環境で用いる際の弱点についてご紹介しました。
「音声認識は難しいことをやってそう」と捉えられがちですが、各ステップを一つずつ紐解いてみると他の機械学習で用いられている技術や、基本的な技術を組み合わせているだけです。この記事が音声認識のアルゴリズムについて理解するきっかけとなれば幸いです。
参考文献
- MFCC
- HMM
- 言語モデル
- WFST
- 音声認識アルゴリズム