Features
- 垂直自動スケール: ワーカーキャパシティの調整
- Right fitting: ステージに合わせたリソース最適化
- スマート診断: パフォーマンスのモニタリング
- ストリーミングエンジン: ストレージとコンピューティングの分離
- 水平自動スケール
- Dataflow shuffle: グルーピングと結合のためのシャッフリング
- Dataflow SQL
- Flexible Resource Scheduling
- Dataflow templates
- Notebooks integration: Vertex AI Notebooksとの統合
- Real time change data capture: データの変更をリアルタイムに捕捉
- Inline monitoring
- CMEK
- VPC
- Private IPs
Programming model for Apache Beam
- Pipelines: データ処理の単位
- PCollection: Pipelineのデータとして扱えるオブジェクト
- Transforms: PCollectionを入力とするデータ変換の処理
- ParDo: ユーザー定義の関数を呼び出す並列処理オペレーション
- Pipeline I/O: 入力のソースと出力のシンクからなるTransform
- Aggregation: 複数の入力から値を計算する処理、代表的なものはグルーピング
- Runner: Pipelineを実行するソフトウェア
- Source: 外部ストレージを読み込むTransform
- Sink: 外部ストレージに書き込むTransform
- Windowing: データをグルーピングするためのまとまり
- Watermarks: ウィンドウのすべてのデータが到着すると期待される時間
- Trigger: 集約されたデータを出力するタイミング
Streaming pipelines
- 連続的にデータが来る状況
- window, watermark, triggerを使って集約する
- watermark: watermarkより遅く到着したデータはlate dataと呼ばれる
- trigger: 集約データを創出するタイミング、デフォルトではwatermarkを過ぎたら
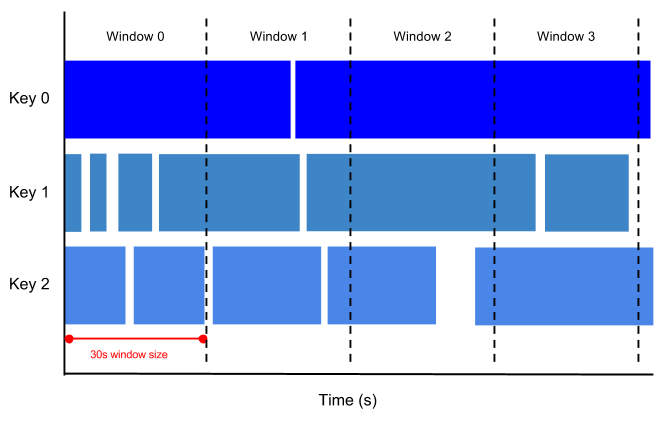
tumbling window: 固定ウィンドウ、固定時間のウィンドウ
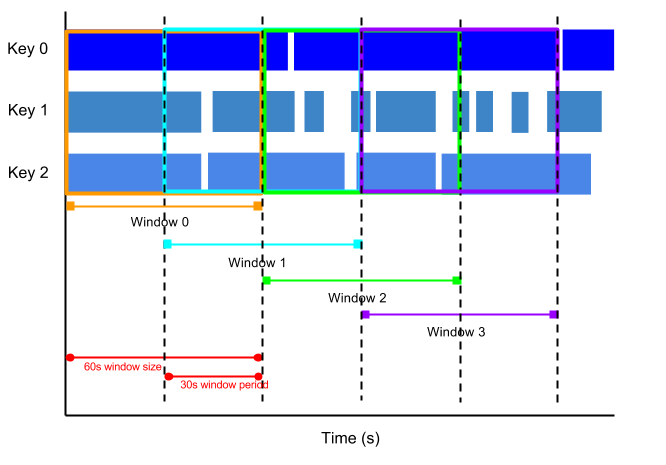
hopping window: スライディングウィンドウ、ウィンドウの時間と間隔をしていできる
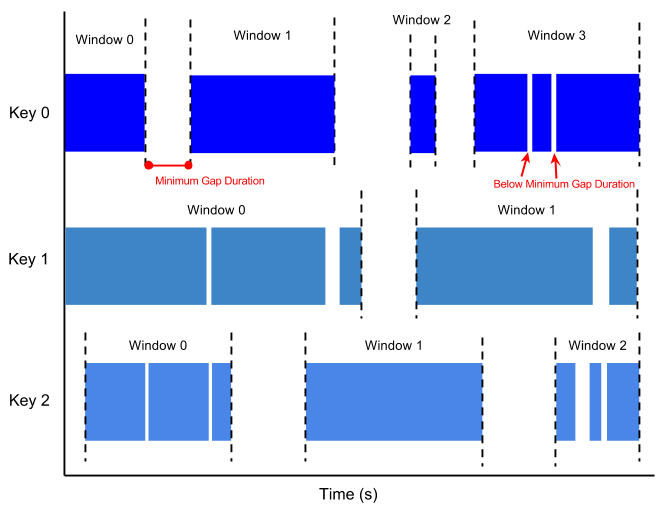
session window: 特定の動作が続くことで生まれるウィンドウ、ギャップ時間をこえると新しいウィンドウが生まれる
Security and permissions
- permission: roleに基づく
-
--updateoption: セキュリティパッチを適用する - Dataflow service account: Dataflowの管理用
- Worker service account: ワーカー用
- Dataflowはリージョナル、ワーカーのゾーンを指定できる
- HTTPSで通信する
- VM上のデータは暗号化される
Regional endpoints
- メタデータを保存、管理する
- データのローカリティが増すため、ネットワークレイテンシが改善する
Streaming with Pub/Sub
- low latency watermarks: 専用のPub/Sub APIを使うことで、より低レイテンシでwatermarkを取得できる
- high watermark accuracy: event timeをより正確に測定できる
- exactly onceを容易に実現できる
Pipeline fundamentals





Dataflow Shuffle
GroupByKeyやCoGroupByKeyやCombineのもとになる操作
keyでパーティション、グルーピングされる
バッチパイプラインでのみ利用可能
速い
ワーカーのリソース処理が少ない
データを保持しないのでオートスケールしやすい
フォールトトレラント
Update a pipeline
-
--updateoption -
--jobNameof the job to be updated - in-flightデータも処理が続くが、transformを追加した場合は保証されない
Stop a pipeline
- cancel: パイプラインを止める
- drain: ストリーミングのみ、バッファされたデータの処理を完了させる
- force cancel: スタックした処理を止めるとき
Customer Managed Encryption Key
- ユーザー管理の暗号化鍵を利用できる
- ユーザー指定のデータソースから読み込んだデータは暗号化される
- persistent disk
- data shuffle state
- GCS
- streaming engine state
- なども
- グルーピングなどのキーベースのTransformを使う際には、データキーが暗号化されない
- データキーがセンシティブな場合、ハッシュ化などを検討すべき
- ジョブメタデータは暗号化されない
Price
- CPUとメモリ
- シャッフルで処理されるデータ (バッチパイプライン)
- ストリーミングエンジンで処理されるデータ
Quotas & limits
- max 3,000,000 requests per minute
- max 1,000 compute engine
- max 25 concurrent Dataflow jobs per project
- max 125 concurrent Dataflow jobs per organization