本資料は、人工知能時代の音楽制作への招待 - Google Magenta 解説&体験ハンズオン -のハンズオン資料となります。
0. Preparation
事前準備として、Magentaを動かせる環境を構築します。
また、学習に使いたいMIDIデータの用意(1-1)まで行っておいてください。なお、大量、あるいは長いMIDIファイルの場合時間がかかる場合があるため、1-2まで勧めておくとスムーズです。
それと、最後にMagentaとセッションした結果をSoundCloudにアップロードしていただこうと思うので、SoundCloudのアカウントを取得しておいて下さい。
0-1. リポジトリをダウンロード
magenta_sessionのリポジトリをFolkし、Folkしたリポジトリをcloneによりダウンロードします。
(Starを頂けると励みになりますm(_ _)m)
https://github.com/your_github_account_name/magenta_session
以降は、cloneしてきたフォルダ上で作業(コマンドの実行)を行います。
0-2. Minicondaのインストール
こちらの記事を参考に、Minicondaの導入を行ってください(MinicondaはPython3のもので大丈夫です)。
- なお、今回はWindowsネイティブで動かすことはできません。WindowsでTensorFlowを動かすにはPython3.5が必要であり、反面MagentaはPython2系でしか動かないためです。Windowsで作業する場合は、bash on Windowsを利用する必要があります
-
conda --versionでMinicondaがインストールできていることが確認できたらokです。
0-3. Magenta環境の作成
インストールしたMinicondaで、Magentaを動かすための環境(magenta)を作成します。
conda create -n magenta python=2.7 numpy scipy matplotlib jupyter
作成後、この環境を有効化してさらに依存ライブラリをインストールします。
source activate magenta
pip install -r requirements.txt
※pyenvを利用している場合、source activateでシェルが落ちる場合があります。先ほどのMinicondaの導入手順にこの回避方法を記載していますので、参考にしてください。
python -c "import magenta; print magenta.__version__"で、0.1.10が出力されれば環境構築はokです。
1.Magentaに音楽を学習させよう
では、いよいよMagentaに音楽を学習させていきます。プロセスの全体像は、以下のようになります。
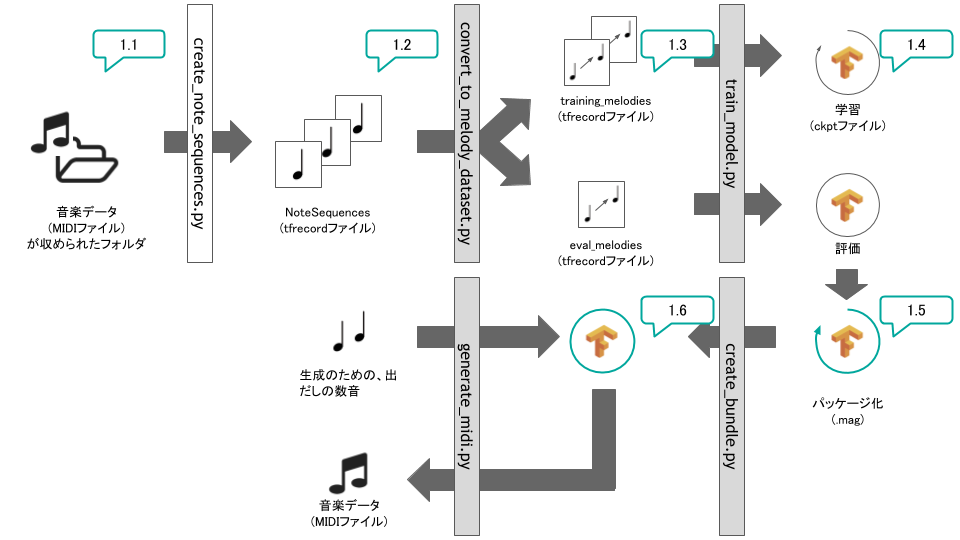
1-1. MIDIデータの収集
学習させたいMIDIデータを収集し、data/rawの中に格納します。以下のサイトが集め先としてよいと思います。
ゲーム音楽なら
ロックなら
(THE MIDI SHRINEからダウンロード可能なFF4の音源では動作確認しています。)
※少し試すだけなら、~30秒程度の曲を5~10曲程度揃える感じをおすすめします。
MIDIの再生は、WindowsだとデフォルトのMedia Playerで可能です。Macの場合は、Garage Bandがあれば再生可能です。
オンラインだと、Online Sequencerが利用可能です。
1-2. MIDIファイルからNoteSequenceを生成
収集したMIDIファイルを、NoteSequenceというMagentaが扱うファイル形式へ変換します。
python scripts/data/create_note_sequences.py
なお、読み取れなかったファイルはスキップされます(警告が出力されると思います)。実行が終了すると、notesequences.tfrecordがdata/interimに生成されます。
1-3. NoteSequenceを学習用Datasetに変換
作成したNoteSequenceを基に、学習用のDatasetを作成します。モデルによっては、音以外の情報もデータに必要となるため(Lookbackでは繰り返しか否かが必要など)、この段階でモデルを指定する必要があります。
今回はMelodyRNNを利用しているため、以下3つから選択します。
- basic_rnn
- lookback_rnn
- attention_rnn
python scripts/data/convert_to_melody_dataset.py --config attention_rnn
Datasetを作成する際、併せて学習用と評価用にデータセットを分割します。この割合は、引数の--eval_ratioで調整可能です(デフォルトは0.1です).
学習用と評価用でデータを分けている理由については、テストに例えるとわかりやすいです。 評価も学習用データで行うということは、テストは必ず勉強に使っていた問題集から出題される、というようなものです。 これでは、本当に理解をしているのか、問題集の答えを覚えているだけなのかがあいまいになります。そのため、学習用と評価用でデータを分けているということです。
※ただ、誰かの楽曲を完全に再現したいケースなどでは、学習データを全部覚えることが重要になる場合があります。この辺りは機械学習の研究とは異なり、用途に応じた対応を取る必要があります。
1-4. モデルの学習・評価
データセットの準備ができたら、学習を開始します。
python scripts/models/train_model.py \
--config attention_rnn \
--hparams="{'batch_size':64,'rnn_layer_sizes':[64,64]}" \
--num_training_steps=20000
学習を行う際に指定するパラメーターは、公式ドキュメントと同様ですので、そちらもご参照ください。
幾つか、ポイントとなるパラメーターについて解説をしておきます。
-
batch_size
ネットワークに一度に学習させるデータの数です。問題集の中の、1ページあたりの問題数のようなものです。大きいほど一度の学習でよく学べますが、その分コンピューターのメモリが必要になります。 そのため、メモリ関連でエラーが発生する場合これを下げると良いです(デフォルトが128なので、半分の64にするなど。その分、以下のnum_training_stepsを上げるなどする)。 -
rnn_layer_sizes
ネットワークの大きさを決めるパラメーターです。[128, 128]なら、ノードの数が128の隠れ層を2つ重ねて作るということです。大きいほど複雑な曲を表現できますが、その分学習時間もかかりますし、汎用的でなくなりやすいというデメリットがあります。 -
num_training_steps
学習を行う回数です。
また、Attentionの場合はattn_lengthでどれくらい過去までを見るか指定することが可能です。
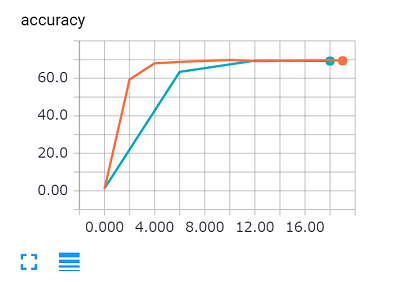
学習時には、もちろん学習状況の観測を行うことが重要です。これをTensorBoardを利用し行うことができます。
まず、学習と並行してモデルの評価を行う処理を、別途ウィンドウ(プロセス)を立ち上げて実行します(当然ですが、パラメーターは最後の--evalを除いて学習のパラメーターと同じにする必要があります)。
python scripts/models/train_model.py \
--config attention_rnn \
--hparams="{'batch_size':64,'rnn_layer_sizes':[64,64]}" \
--num_training_steps=20000
--eval
その後、TensorBoardを立ち上げます。TensorBoardは、http://localhost:6006からアクセスできます。
tensorboard --logdir=models/logdir
学習データに対する精度と、評価データに対する精度を確認できます。学習データに対する精度が高いけれども、評価データに対する精度が下がってきている場合は「本当に理解をせず、問題集を覚えている」状態になっているサインです(これを過学習と呼びます)。
1-5. モデルのパッケージ
学習が終わったら、学習したモデルをパッケージングして扱いやすい形にします。Magentaの場合、.magファイルにまとめることができます。
※学習が終わってなくても、checkpointファイルができていれば実行可能です(その時点の学習結果がパッケージングされます)。
python scripts/models/create_bundle.py --bundle_file my_model
スクリプトを実行すると、models/のフォルダにmy_model.magとこのモデルを作成した際のパラメーターmy_model.hparamsが作成されます(名前は自由につけていただいて構いません)。
1-6. MIDIファイルの生成
では、さっそく作成したモデルを利用してMIDIファイルを生成してみましょう!
python scripts/models/generate_midi.py \
--bundle_file=my_model \
--num_outputs=10 \
--num_steps=128 \
--primer_melody="[60]"
パラメーターについては公式ドキュメントの通りになりますが、幾つかのパラメーターについて解説をしておきます。
-
num_outputs: 生成されるMIDIデータの数 -
num_steps: 生成されるMIDIデータの長さ(16step=1小節換算です。例えば、128なら8小節分です) -
primer_melody: 出だしとなるメロディー
primer_melodyはMIDIコードで指定を行います。MIDIのコードについては以下を参照してください(NoteOffは-2になります)。なお、指定は16分音符単位となるため、「四分音符のド」は[60, -2, -2, -2]となります。

出典: MIDI numbering, the Helmholtz Pitch Notation System, and other octave numbering conventions used in music and music notation
※半音が上がるのもカウントされるため、「ド」の次の「レ」は62になっています。
生成に成功すると、data/generatedのフォルダに生成されたMIDIファイルができているはずです!
2.MagentaとSessionしよう
2-1. MagentaとのSession
単純にMIDIファイルを生成するだけでなく、Magentaと共演をしてみましょう。
まず、作成したモデルを使うためにMAGENTA_MODELの環境変数をセットします。
export MAGENTA_MODEL=my_model
その後、Magenta Sessionのサーバーを起動します。
python server/server.py
デフォルトではhttp://localhost:8080で立ち上がるはずです。ぜひMagentaとのCall & Responseを試してみてください!
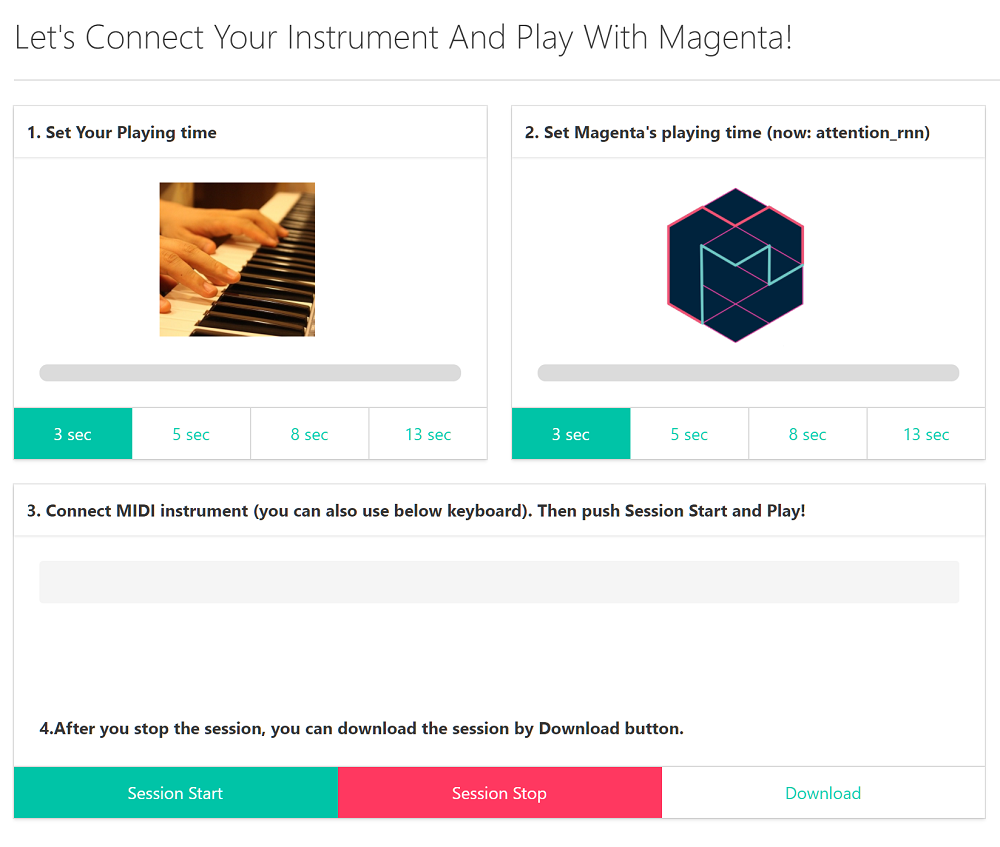
MIDIコントローラーがある場合は、接続した後に画面の更新を行ってください。
-
- Set Your Playing time: 自分の演奏時間を設定します
-
- Set Magenta's playing time: Magentaの演奏時間を設定します(now: となっているのが現在使用していモデルです)
-
- Connect MIDI instrument: MIDIコントローラーが接続されていれば、表示されます
-
- Session Startでセッションを開始し、Session Stopで停止します。Session終了後、セッション結果のMIDIファイルをDownloadボタンからダウンロードできます。
2-2. MIDIをシェアしよう
作成したMIDIを、ぜひSoundCloudなどのクラウドサービスでシェアしましょう。
MIDIファイルはそのままでは共有できないので(MIDIファイルは演奏方法の指示であって、音源ファイルではないことを思い出してください)、mp3ファイルなどに変換する必要があります。
以下のサイトなどを利用して、変換を行いましょう。
変換を行ったら、SoundCloudへアップロードします。ぜひ #magenta_session のタグをつけて下さい。
FF4の音楽を学習させたモデルで挑戦
— piqcy (@icoxfog417) 2017年4月16日
Have you heard ‘Magenta Session with Game Sound trained model’ by icoxfog417 on #SoundCloud? #np https://t.co/9JuSOKtgLK
ぜひいろんなモデルで試してみてください!