Classifying Student Dialogue Acts with Multimodal Learning Analyticsのまとめ。
要約
生徒の学習をサポートするようなアドバイスをしてくれるエージェント(チューター)についての研究。具体的なタスクは、生徒の発話がどういう意図のものか(質問なのか、単なる感想なのかなど)、いわゆるdialog-actを推定すること。
研究ポイントとしては以下2点。
- 姿勢・ジェスチャーなどのマルチモーダル情報を利用する
- 学習のためのラベル付の手間を減らすために、教師無し学習を導入
結果としては、教師無し学習はうまくいき、また構築したモデルは言語情報を欠いた状態でも高い精度を出せた、ということである。教師無しでできたメリットは大きく、例えば多くの生徒がいる環境でも教師無しで学習させて適応させたりすることができる。
先行研究
dialog actの推定は実際の人との対話に近づけるにはとても重要で、この精度を上げるためにマルチモーダル情報を活用することも行われるようになってきている。具体的には、以下のような情報である。
- gaze(視線)、gesture: 話者の転換(turn talking)の手がかりになる
- posture(姿勢): 退屈やイライラ、辞めたがっているかどうかの手がかりとして有用
- gestureのうち、片肘をついているのはそうでもないが、両肘ついているのは集中力を失っている
発話そのものからdialog actの推定を行うのは膨大な研究があるけれども、こうしたマルチモーダル情報(音響的特徴量や、表情、ジェスチャー、姿勢など)を使ったものはまだ少なく、教師無しで行っているものは輪をかけて少ない状態である。
学習データ
教材(下図参照)を使ったJavaのプログラミング授業中の、生徒とチューターとの間の会話(チャット)を使用している。
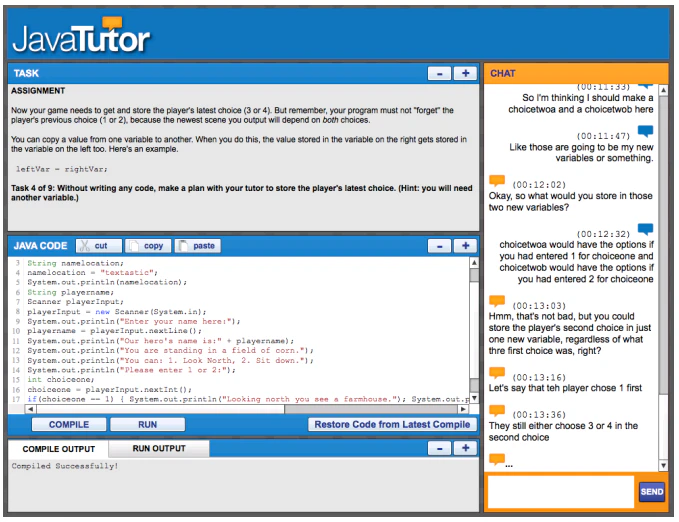
この会話データは効果的なチュータリングの良い例となっており、実際チュータとの会話をはさんで事前・事後のテストを行ったところ、事前テストで間違えた箇所の49%が正答となった。
ここには37の生徒が行った計1443の発話が含まれており、各発話には以下のラベルが付けられている。なお、本論文の目的は教師なし学習なので、このデータは評価のためにのみ利用されている。
- Answer(A): 43.28%
- Statement(S): 20.46%
- Acknowledgement(ACK): 20.2
- Question(Q): 14.16%
- Clarification(C): 0.9%
- Request for Feedback(RF): 0.5%
- Other utterance(O): 0.5%
教材を使っている間の生徒の行動はKinectのカメラで撮影され、このvideoから姿勢とジェスチャー情報を抽出している。

- 姿勢: 頭と胴体の距離から判断
- ジェスチャー: 片肘か両肘かを判定
- ※論文中の"one/two hand to face"は、実際のジェスチャーからすると片肘をつく、両肘をつくに相当するので(Figure4/5からも明らか)、意味を汲んでそう表記しています。
この映像からの姿勢とジェスチャーの分類は以前の研究で既に行われており、92.4%の精度で取得可能となっている。
特徴量
モデルの特徴量としては、以下4種類の特徴量を使用している。
- lexical: 発話に関する特徴量。ユニグラム情報と語順を使用。pos(part of speech=品詞)情報などは無駄なので(参考文献)使用しない。
- dialogue-context: 対話に関する特徴量
- 発話の相対位置: 対話の開始からの相対位置
- 発話の長さ
- 前の発話の話者(生徒orチューター)
- 直前のチューターのdialogue act: システムが決めるため、これは把握可能
- task: 授業中の生徒の行動に関する特徴量。生徒とチューターとの間のインタラクションの流れを表す。
- 行動のシーケンス: 発話、コードを書いている、コンパイルしている、実行しているetc
- 直近のコードのステータス: begin, success, error, stop, input_sent
- タスク中に送られたメッセージの数
- エラーの発生回数
- multimodal-feature(Posture): 姿勢に関する特徴量。カメラと以下の部分の間の距離
- head: 頭
- mid torso: 胴体の中間
- lower torso: 胴体の底部
- 上記3つの平均
- multimodal-feature(Gesture): ジェスチャーに関する特徴量
- 片肘をついている数
- 両肘をついている数
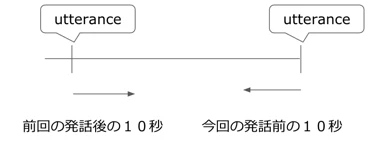
なお、姿勢/ジェスチャーについては、今回の発話前の10秒間と、前回の発話後の10秒間の平均をとっている(下図参考)。なお、フレームレートは8frame/secとのこと。
モデル
方針としては、教師無し学習でクラスタリングを行い、分類されたクラスタからdialog actを判断している。
クラスタリングは、k=5のk-medoids法で行う(先行研究でこれが最も制度が良かったらしい)。発話間の類似度を表す指標としては、以下の特徴量を使用している。
- cosine similarity: lexical以外の特徴量にはこれを使用
- longest common subsequence: 必然的には隣接しない語の連続?を使用。具体例としては、"I should declare a variable"と"Should I declare a variable"は、単語的には同じだがdialog actは明らかに異なる(前者はStatement、後者はQuestion)。つまり単語よりもその語順、特に上記の"declare a variable"のように語順が規定ではない語のもの、が重要で、これがどこまで一致するかを表す指標がlongest common subsequence(解釈があっているか微妙なので、詳細は参考文献参照)
- dialogue history: 対話履歴。具体的には、前回のチューターの行動を考慮する。詳細は下図を参照。
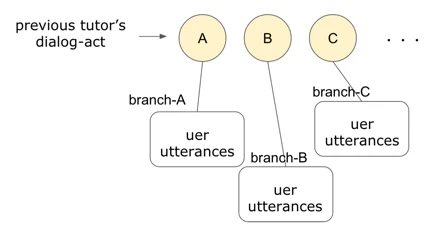
発話前のチューターのdialog actごとにまとめて(branch)、各branchでクラスタリングを実施しておく。つまり、発話のクラスタを決める手順は以下のようになる。
- 前回のチューターのdialog-actから、branchを決定
- branch内の各クラスタと今回の発話との間の距離を算出し(各クラスタ内の発話への平均距離を使用?)、最も近いクラスタを選択
なお、クラスタはdialog-actに対応している。dialog actが7に対してクラスタが5となっているが、これは頻度の低いRequest for FeedbackとOtherを除外しているようだ。
実験
比較を行うため、姿勢/ジェスチャーを特徴量として含んだモデルと、そうでないモデルを作成して実験している。
精度計測はcross-validation法で行い、foldの作り方としては、各foldで一人の生徒を抜いていく形で作成。なお、データ(生徒)は総計37名で、training/testそれぞれに割り振られており、互いに重複することがないようにしている。
こうして、クラスタリングした結果が付与されたdialog actのラベルと一致するかを検証。各モデルの精度の違いが有意であるかを判定するために、有意水準0.05の片側t検定を実施した。
結果としては、以下のようになったとのこと。
- 姿勢・ジェスチャーいづれも含むモデルは非常に良く、何れも含まない場合の61.8から67.05に精度向上
- Statementの分類だけ精度が下がったが、ほかの分類については精度向上
- 精度が上がった箇所: Statementに良く似たQuestionの区別によく効いてる
- 精度が下がった箇所: マルチモーダル情報がユーザーがconfuseしていると判断している際に、単なるStatementがQuestionに誤認される
まず、Questionの判断精度が向上している。特に質問文か見分けがつきにくいような発言にマルチモーダル情報が有効に働いたそうだ。実際、問題を解いている際に「私は混乱している」とか言葉にしないので、この辺りをマルチモーダル情報から取得することでQuestionが判定しやすくなったことが推定されるとのこと。
ただ、これによりQuestionに間違えてしまうケースも多くなったようだ。特に混乱している状態の判断基準となる「カメラから離れている」「片肘をついている」といった情報があると、単なるStatementがQuestionとみなされてしまうことが多かったとのこと。
しかし、単純にマルチモーダル情報のみを使った推定の精度は53.2%で、他の特徴量?のベースラインである43%より高かった。つまり、マルチモーダル情報だけでもそこそこの精度でdialog actを推定することは可能だということが本論文から分かる。これにより、発話する前にどのような発話をする可能性が高いのかを見積もることも可能になる。
今後高精度なカメラの価格が下がってくれば、ストリーミングでユーザーの行動を推定することも可能になってくると思われる、とのこと。
結論
マルチモーダル情報を利用することでユーザーの発話の意図を推定する精度を向上させることができた。しかも、教師無し学習で学習できるため、多くのユーザーがいるようなサービスでもスケールさせて使うことができる。
なお、マルチモーダル情報を取得するための学習(ユーザーの姿勢やジェスチャーの分類など)は別途行う必要があるので注意。