21世紀でもっともセクシーと言われるデータサイエンスは、18世紀を彷彿とさせる奴隷的な作業によって支えられています(要出典)。その作業とは、データを作る作業(=アノテーション)です。多くの場合、アノテーションは孤独な単調作業の繰り返しです。延々と続けていると、全ての単語にunkとつけるようになる事例も報告されています。つまりつらい!のです。
本記事では、「孤独で辛い」アノテーションを「みんなで楽しく」行える環境を作る方法を紹介します。そのポイントは以下3点です。
- Easy: アノテーションを楽に
- Feedback: アノテーションした結果がすぐにわかるように
- Gamification: アノテーション結果をみんなで競い合う
Overview
アノテーションを行う流れは以下のようになります。

- Annotation Tool for Easy: アノテーションを楽にするためのツールを用意
- Infrastructure for Feedback: アノテーションした結果がすぐわかるようなインフラを整備
- Visualization for Gamification: Leader Boardを見てアノテーションをした結果を競い合う!(Kaggleライク)
アノテーションツールは、オープンソースのdoccanoを使用しました。
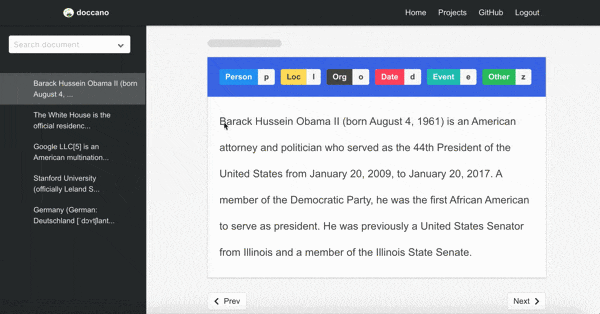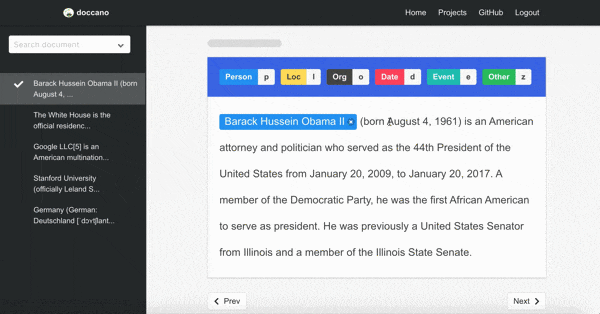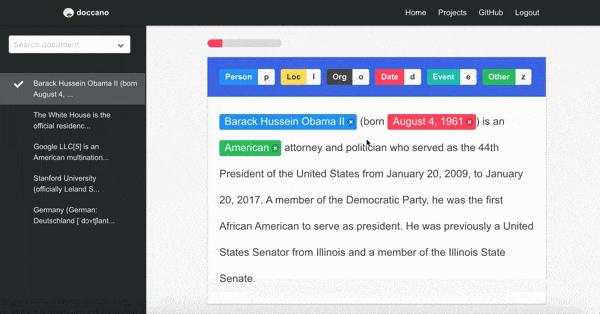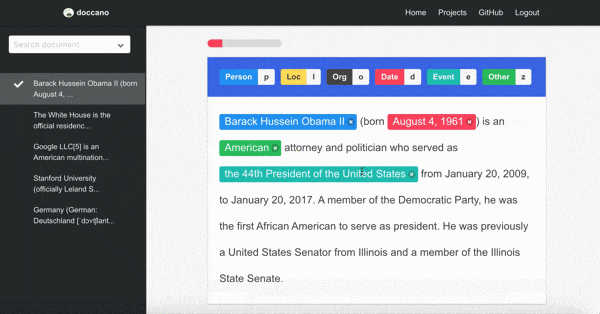
インフラ構成は以下のようになっています。
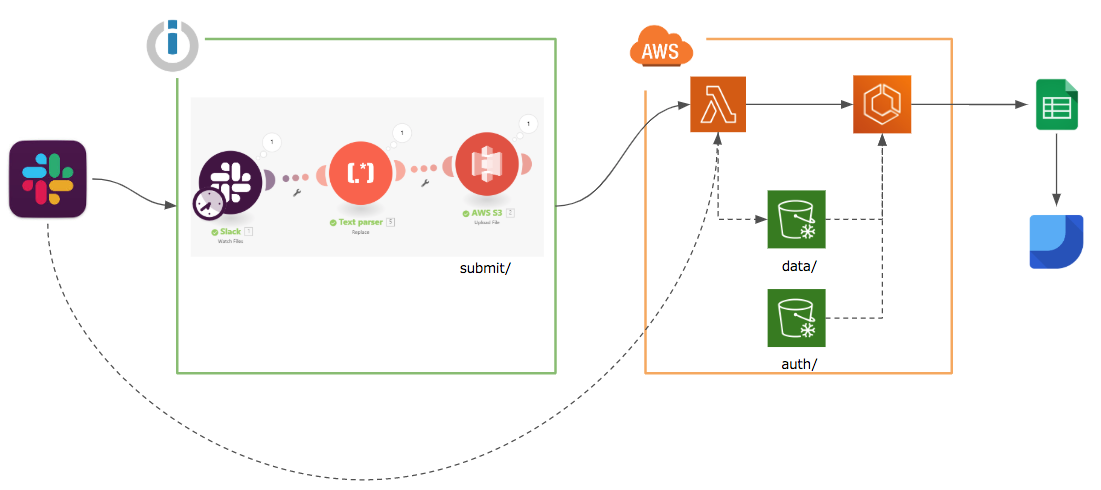
- Slackでアップロードしたデータを、
- IntegromatでS3に転送し、
- LambdaでECSの学習タスクをキックする。結果は、
-
Google Spread Sheetに書き込みGoogle DataStudioでダッシュボードとして表示する。
- こちらが実際のダッシュボードです: YANS ANNOTATION HACKATHON
実装はyans-2019-annotation-hackathonで公開しています(Starいただければ励みになります!)。構築の詳細については後述します。
今回の試みは、自然言語処理若手の会(YANS 2019)にて「アノテーションハッカソン」として実際に行いました。
モデル作りではなく「データ作り」で競い合うハッカソン「アノテーションハッカソン」をやります!
— ymym@やむやむ (@ymym3412) August 26, 2019
これを機にアノテーションを経験してみたい方、アノテーションツールを使ってみたい方、退屈なアノテーションをもっと面白くしたい方、ぜひご参加を!#yans2019 pic.twitter.com/MTuGfEqmNG
いろいろトラブルはあったのですが(主にマシンリソース関係)、なかなか楽しくできたと思います!
こうした仕組みで、一人でも多くのアノテーターが21世紀の人権を獲得できれば幸いです。
以下では、インフラ構築の過程(夜間 x 3日)と詳細をリアルタイム形式で解説します。
Detail
Day1
イベント(YANS2019)にて「アノテーションで何か企画をやりたい」という話はあったが、実際どうするかは未決であった。アノテーションは孤独でつらい作業なので何かモチベーションがないと人が集まらないと思案。Kaggleみたいにコンペ形式でできればいいね、というアイデアが出る。この時点で開催まであと数日だったが、多分なんとかなるという楽観的な見込みのもと作業を開始。
アノテーションツール自体はすでに開発していたので(doccano)、アノテーション済みファイル~リーダーボードに表示までのインフラ構築に集中する。ファイル提出~結果表示Webアプリケーションの開発&ホスティングとなると18世紀ではすまないハードワークが待っているので、外部サービスをフル活用することにする(自作だとリーダーボードがしょぼくなる懸念もあった)。
リーダーボードは、Google Data Studioがいい感じに表示できそうと目星をつける。同じGoogleだからインフラもGCPで揃えようかな(ついでにいろいろ触っておきたい)という誘惑が心に芽生えるが、このタイミングでそんなことをしていると18世紀では(以下略)になるので、慣れたAWSで構築することにする。
- ファイルをなんらかの方法でS3に転送
- 転送イベントをLambdaでトリガして学習処理を実行
- 結果をGoogle Spread Sheetに書き込んでData Studioで表示する
ここまでの流れを確定。
Day2
肝心の学習をどうするか。それが問題だ。
アノテーションのタスクはNERと決まっていたが、日本語のNERが学習できるライブラリはそう簡単に転がっていない。spaCyの日本語対応はWatchしていて、そこでNERを学習していることを思い出す。
こちらにあったデータと学習スクリプトを参考に手元で実行してみる。spaCyは日本語対応済みのspaCy(まだマージされていない)を使用。うまく動くことを確認。
ただ、この学習はNER以外にPOSタギングなども含んでいる。今回はNERのモデルだけ学習したいので、spaCyのexample(train_ner.py)を参考に学習スクリプトを実装。doccanoでアノテーションしたデータでNERが学習できることを確認。
学習スクリプトが完成すれば、あとはDockerfileを作ればECSで走らせることができる(Lambdaはタイムアウトとランタイムの構築が手間なので却下)。Dockerfileを作成するが、spaCy & Sudachiのインストールがとても重い(pip installが長い)。docker buildとdocker pushで夜がふける。
Day3
Dockerfileの修正が開発速度のボトルネックになっていたので、この点を修正できないか検討。multi-stage buildを使って、環境構築とアプリケーション(学習の実行)を分ける。これで問題となっていたbuildのスピードを上げることができた。ただspaCy単独にこだわらずGiNZAを使えば済む話ではあったので、最終的にこの工夫はあんまりいらなかった。
あとは「ファイルをなんらかの方法でS3に転送」のみ。Slack Appを開発するとなるとBotをホスティングする必要があり、そんな時間はもちろんない。IFTTTとかでなんとかいけないのか・・・と探したところ、Integromatでいけそうだという情報を掴む。ただファイルの直接送信はできなかったので、ファイルのリンクだけ送りLambda側でダウンロード&S3へ保存するようにする。Lambdaではこの後ECSのタスクをキックして学習を実行。学習スクリプトには結果書き込みまで入れたので、ECSのタスクが終わればダッシュボードも更新される。
最後にファイル転送~学習実行~リーダーボード更新の疎通確認テストを実施。Integromatは結果も見やすく(↓)いい仕事をしてくれた。
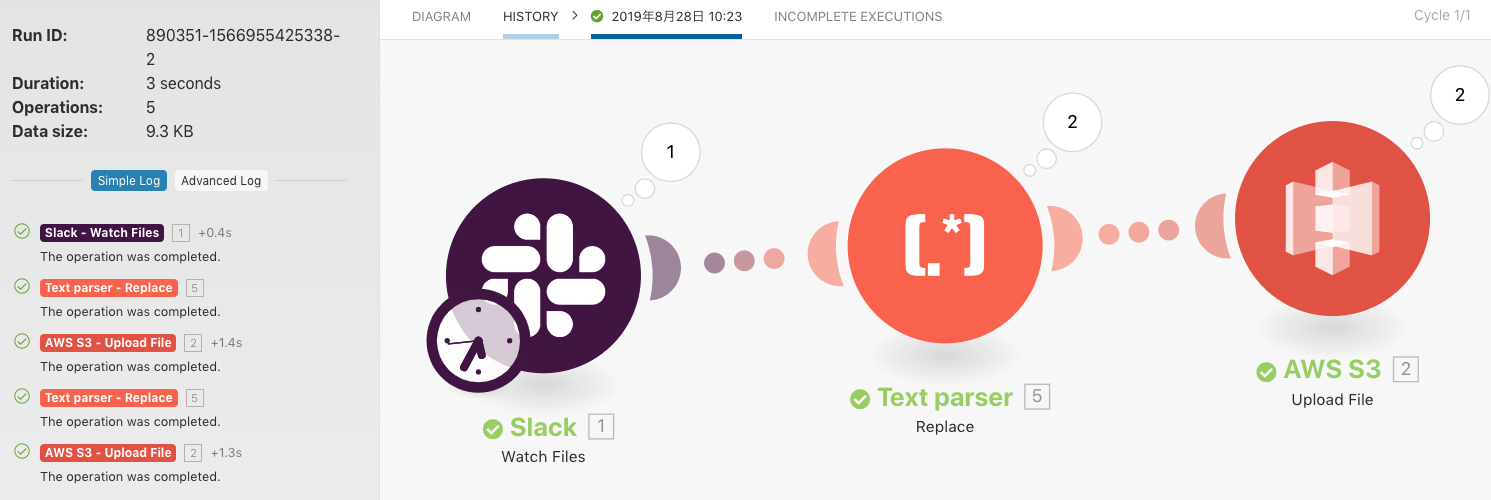
そして北海道(会場)へと旅立ったのだった(完)。
In fact
ここまではアノテーションを過酷な人手作業として描写しましたが、初手人手でやることはほぼありません。まずルールや辞書を使ってアノテーションを行い、それを修正するのが定石です。学習済みモデルによる事前のラベルづけやアノテーションサポートも検討します。全件人手でアノテーションを行うのは18世紀型の発想と言わざるを得ません。
イベント中、私自身も辞書/正規表現(ルール)でアノテーションをしてみました。↓ぐらいまでには自動でアノテーションすることが可能です。いくつか間違いや重複がありますが、間違いを修正するだけ vs 最初から全部人手、では作業負荷に雲泥の差があります。

(実装はyans-2019-annotation-hackathonで行っています)
実際、ハッカソンに参加したチームはルールを効果的に使用しています。使った手法について記事を書いてくださるとの連絡も受けているので、楽しみに待ちましょう!
以上、構築の過程まで含めて参考になれば幸いです。人権のあるアノテーションライフを送りましょう!