ChatGPT や Claude といった高精度なモデルは推論できる量に制限があります。つまり、生成 AI を使い価値ある機能が開発できても、届けられるユーザーの数には限界があるということです。これは新規サービスや機能を市場へ広めていく場合、時に致命的な問題となります。その解決方法を提案するのが本記事の目的です。

生成 AI の推論を止めない基本的な方針は、サービスの制約が許す範囲において「場所」や「モデル」を冗長化することです。例えば、「国内」に閉じることが必須でないなら、日本リージョンでの使用量が上限に達した場合他のリージョンで推論することができます。また、Claude の最新モデルにこだわる必要がなければ前バージョンか他のモデルに推論を移譲できます。AWS では Amazon Bedrock のクロスリージョン推論を使うことで、すでに「場所」の冗長化ができます。Amazon Bedrock は複数の生成 AI モデルを統合された API で扱えるため「クロスモデル推論」の実装も容易です。
本記事ではクロスリージョンかつクロスモデルの冗長性が高い推論インフラを設計・実装する手順を解説します。実装を完了すると、下図のように一番手の Claude Sonnet が NG だった場合 Amazon Nova 、Claude Haiku と切り変えていく処理を実装しその様子をタイムラインでモニタリングできるようになります。

上図のとおり 3 段階のモデル (クロスリージョン推論) 冗長化を行うことで、 20 リクエストを同時に API エンドポイントに叩き込む実験において単一モデルでは 18% しか対応できないところ 23% を二番手、59% を三番手のモデルがさばくことで 100% リクエストを返せることを確認しました。
本記事の実装は下記リポジトリで公開しています。開発に当たっては Amazon Q Developer と GitHub Copilot の力を大いに借りました。README.md を含めコードの 8 割ぐらいは生成したものです。
GitHub Repository : Amazon Bedrock Redundant API
1. Cross-Region かつ Cross-Model の推論インフラの設計
1.1. 推論インフラの設計と合意
具体的な実装へ入る前に、プロダクトの要件や制約を基に優先度マップを設計することを推奨します。優先する推論の場所、モデルについてプロダクト開発チーム全体で合意形成を図ることが目的です。以下に優先度マップの簡単な例を示します。図中のパーセントは、許容可能な場所・モデルの利用割合です。モデル単位でみると、Claude Sonnet で 80%、Amazon Nova Pro で 15%、Claude Haiku で 5% をさばきたいことになります。
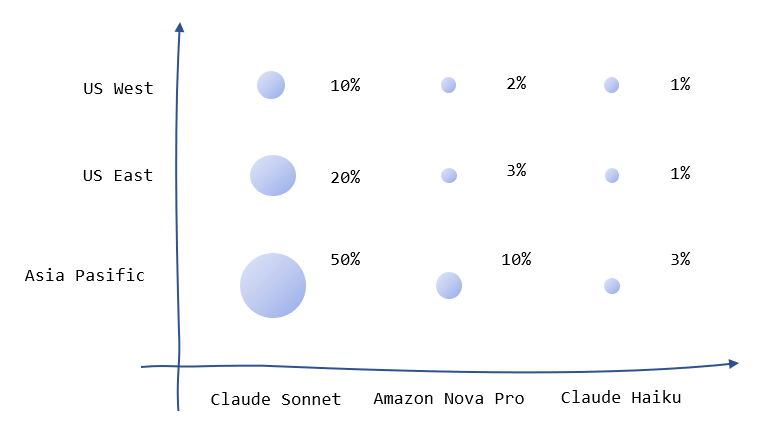
サービスの制約によっては、推論する「場所」を海外にできない、モデルのエンドユーザライセンス同意書 (EULA) が合意できない、といった事態もあり得るため、「使っていいモデル」を明確にする点でも重要です。
優先度マップでは、精度とレスポンスが重要な評価指標となります。例えば、「国内」の「Claude 3.5 Sonnet v2」が精度およびレスポンスにおいて最高の選択肢としましょう。次善のモデルを選ぶとき、精度が優先なら他リージョンの Claude 3.5 Sonnet v2 が優先となりますし、レスポンスが優先なら国内で使える前世代の Claude 3.5 Sonnet が優先となります。もちろん、モデルを選択する際は国内にデータが出せないなど、サービス固有の制約を加味する必要があります。①最優先、②次善 (優先度が高い条件は満たす)、③次次善 (優先度が低い条件を満たす)、の 3 段階で各「場所」「モデル」の優先度を評価し推論の計画を作成、合意形成を行います。
1.2. Cross Region の選択
異なるリージョンの同じモデルを利用する際は、クロスリージョン推論が役立ちます。あらかじめ定義された推論プロファイル (inference profiles) を Model ID の代わりに使用することでプロファイルがカバーする範囲のリージョンで推論が冗長化されます。例えば、Anthropic Claude 3.5 v2 の推論プロファイルである us.anthropic.claude-3-5-sonnet-20241022-v2:0 は us-east-1 と us-west-2 をカバーしており、例えば us-east-1 の推論リソースが逼迫している場合自動的に us-west-2 へルーティングされます。
注意点として、推論プロファイルはユーザー側で定義できません (推論プロファイルとは別に、アプリケーション推論プロファイルと呼ばれる使用料とコストをトラックするためのプロファイルがありますが、これとは別になります)。執筆時点で用意されている推論プロファイルでは、ap-northeast-1 をプライマリとして空きがないときに us-east-1 を使用することはできません。任意のリージョン間で推論を分散する場合は個別実装が必要です。
1.3. Cross Model の選択
精度の観点で、執筆時点 (2024/12) では第一に Anthropic Claude が選択されることが多いでしょう。では、次善のモデルにはどのような選択肢があるでしょうか。次善のモデルの要件はユーザーのリクエストに対し沈黙してしまったりエラーを返すよりましな応答を返すことです。対話型のサービスであれば会話を始めて 3 ターン目に使用量が上限に達してしまった時、エラーで対話が継続できないより次善のモデルが「つなぎの」応答をすることでユーザー体験の水準を保つことが出来ます。
候補として、Claude の前世代のモデルがまず候補に挙がるでしょう。執筆時点では Claude 3.5 Sonnet v2 が最新のモデルであるため、素の Claude 3.5 Sonnet 、また Claude 3 Sonnet が次善の候補になります。もしかしたら Claude 以外は日本語が話せないと考えている方がいらっしゃるかもしれませんが、AI21 Labs の Jamba 1.5 、Cohere の Command R+ 、Llama 3.2 はいずれも日本語の解釈・出力が可能です。Weights & Biases が公開している生成 AI の日本語能力を評価したベンチマーク Nejumi LLMリーダーボード において、 Command R+ と Llama3.1 (70B) は Anthropic Claude3 Sonnet のスコア (TOTAL_AVG) は 0.01 しか変わらず、Opus と比べても 0.04 ほどの差になります。 Llama 3.2 はまだリーダーボードにありませんが、Sonnet と同等かそれ以上の精度が期待できます。いずれにしても Claude3 Haiku よりは高い精度で、Llama3.1 では金額も 1/3 程度になります。
また、re:Invent 2024 で公開された Amazon Nova シリーズのモデルはいずれも日本語を扱えます。まだリーダーボードには掲載されていませんが、体感的には v2 の Sonnet には及ばないが Haiku よりは良いです。レスポンスが早いのは特筆すべき点で、速度は明らかに速いです。詳細が気になる方は Technical Report をご参照ください。
2. 推論インフラの実装
2.1 インフラの構成
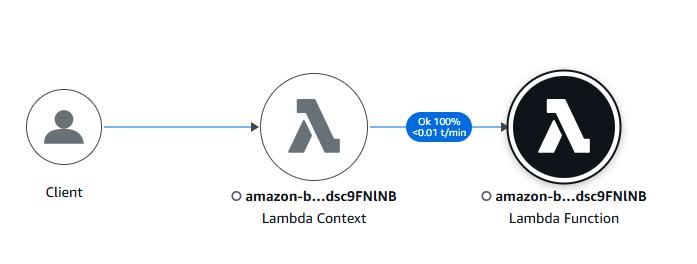
今回は Amazon API Gateway と AWS Lambda で構成される API を、AWS SAM を使用し実装しました。全体の流れは次のようになります。API Gateway から Lambda 、Bedrock 呼び出しまでの一連の流れ = トレースを AWS X-Ray で記録しています。AWS SAM では Properties として Tracing を Active にすれば AWS X-Ray でリクエストが追跡されてログがひとまとまりのトレースとして見られるようになります。
AWS X-Ray でグラフィカルに参照できる図はこんな感じになります。トレースはさらに細かいセグメントに分割して分析できます。詳細は実装のセクションで解説します。
2.2 Cross Model の実装とモニタリング
Cross Region は推論プロファイルで実現できるため、Cross Model を実装していきます。Amazon Bedrock では、Quota の制限に達したリクエストについては ServiceQuotaExceededException 、モデルが受け付けられるトークン数の上限に達したときは ThrottlingException が発生します。ただ、現在 Quota の閾値内にも関わらず制限のかかる場合があり (参考 : Amazon Bedrock のモデルアクセスの有効化や制限値の引き上げができない時の対応方法)、その際は ThrottlingException が発生するようです。そのため、この 2 つのいずれかが発生した場合にモデルの切り替えを行います。モデルの切り替えは LiteLLM など複数のモデルプロバイダに対応したフレームワークもありますが、例外発生時に他のモデルでリトライする単純な処理であるのと、Amazon Bedrock であれば複数モデルプロバイダを 1 つの API で切り替えられるため今回はスクラッチで実装します。
はじめに、優先するモデルをファイルに定義し、定義された順にモデルを呼び出していきます。今回は YAML ファイルで使用するモデルを models として定義しました。
models:
- name: "claude-3-sonnet"
model_id: "us.anthropic.claude-3-5-sonnet-20241022-v2:0"
max_retries: 1
retry_delay: 1
regions:
- "us-east-1"
- name: "amazon-nova"
model_id: "us.amazon.nova-pro-v1:0"
max_retries: 1
retry_delay: 1
regions:
- "us-east-1"
- name: "claude-3-haiku"
model_id: "us.anthropic.claude-3-5-haiku-20241022-v1:0"
max_retries: 2
retry_delay: 1
regions:
- "us-east-1"
一番手、二番手のモデルについて max_retries を 1 にしています。何回か試したところ、1 回アクセスして NG だった場合次リクエストして通ることがほぼなく、RPM (Requeset Per Minutes) の Quota およびレスポンスタイムを無為に消費してしまうことからこの設定にしています。最後の砦である Claude Haiku は 2 回トライするようにしています。
models の順にモデルを呼び出していく処理を lambda_handler に実装します。モデルの呼び出しは invoke_model の関数にまとめています。
@xray_recorder.capture('bedrock_inference')
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
subsegment = xray_recorder.current_subsegment()
# 指定パラメーターの取得
body = json.loads(event.get("body", '{}'))
contents = body.get("contents")
if not contents:
return {
"statusCode": 400,
"body": json.dumps({"error": "No prompt provided"})
}
temperature = body.get("temperature", 0.7)
max_tokens = body.get("max_tokens", 1024)
response = None
try:
# 候補となるモデルは YAML ファイルから models に事前読み込み
for model_rank, model in enumerate(models):
model_id = model.get("model_id")
model_name = model.get("name", f"model_{model_rank + 1}")
regions = model.get("regions", [])
max_retries = model.get("max_retries", 2)
retry_delay = model.get("retry_delay", 2)
# 優先する region からアクセスを始める
# ※推論プロファイルを利用する場合、自動でリージョン分散されるためこの処理は不要
for region_rank, region in enumerate(regions):
client = clients[region]
for _retry in range(max_retries):
with xray_recorder.capture(model_name) as invoke_segment:
response = invoke_model(
client,
model_id,
contents,
max_tokens,
temperature,
invoke_segment
)
# 結果が取得出来たら break
if response is not None:
break
else:
# 出来なかったら sleep してリトライ
_n = _retry + 1
logger.warning(
f"Retry {model.get('name')} in {region} {_n}/{max_retries} times.")
time.sleep(retry_delay)
# 結果が取得出来ていたら break
if response is not None:
break
# 結果が取得出来ていたら break
if response is not None:
break
# モデル / リージョンを切り替えた回数を記録
subsegment.put_annotation('model_rank', model_rank + 1)
subsegment.put_annotation('region_rank', region_rank + 1)
if response is not None:
return {
"statusCode": 200,
"body": json.dumps({"message": response["output"]["message"]})
}
else:
return {
"statusCode": 500,
"body": json.dumps({"error": "Rate limit hit for all models"})
}
except Exception as e:
logger.error(f"Error: {str(e)}")
return {
"statusCode": 500,
"body": json.dumps({"error": str(e)})
}
見慣れない実装 (デコレーター) として @xray_recorder.capture("bedrock_inference") があります。これは AWS X-Ray で特定区間 (セグメント) を明示して記録するための記述です。 X-Ray ではリクエストの処理プロセスをトレースという単位で記録しており、どこで時間がかかっているか分析できます。「どこで」を定義するのがセグメントで、 AWS が自動的に設定するセグメント以外に任意の区間でも設定できます。その時に使用するのが capture 等のメソッドです。
X-Ray の使用に当たっては CloudWatch > Settings > X-Ray traces の設定にて Transaction Search を Enabled にします。有効化すると、記録するログに対し課金がされます。価格は Pricing で確認できます。執筆時点では 100 万トレースで $5 とかなので安価です。
また、X-Ray の仕組みについては BlackBelt の資料 をぜひ参考ください。
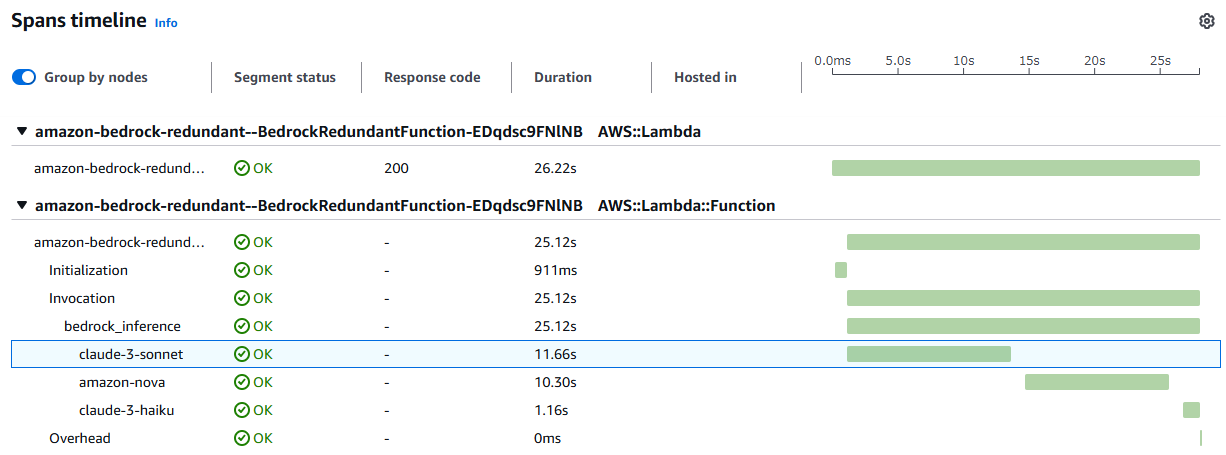
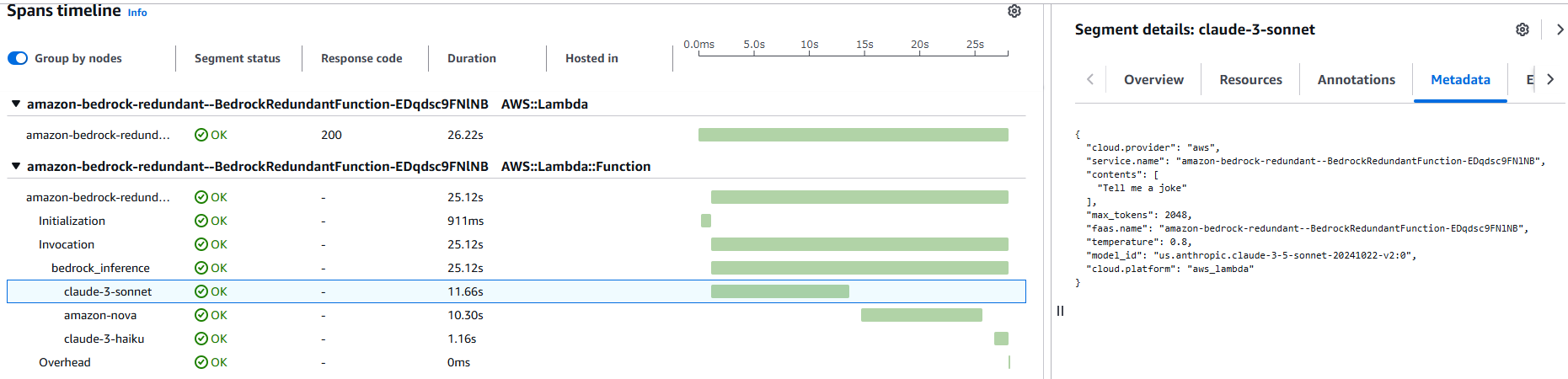
今回は推論の冗長化処理を bedrock_inference というセグメント、各モデルへの問い合わせをモデル名を付けたセグメントに切り分けています。その結果、下図のようなトレースが参照できます。bedrock_inference の中で、最初に claude-3-sonnet をトライ、次に amazon-nova をトライ、最後に claude-3-haiku をトライしてようやくリクエストが返せていること、またそれぞれのモデルの問い合わせにどれだけ時間がかかったかわかります。
invoke_model の実装は次の通りです。Amazon Bedrock の converse API を使用することで、model_id ごとにリクエスト形式を変えずアクセスできているのがポイントです。Exception として、ThrottlingException と ServiceQuotaExceededExceptionが発生した場合 return を None にしてリトライが続くようにしています。
def invoke_model(
client: Any,
model_id: str,
contents: list[str],
max_tokens: int,
temperature: float,
segment: Any = None
) -> Optional[Dict[str, Any]]:
segment.put_metadata('model_id', model_id)
segment.put_metadata('contents', contents)
segment.put_metadata('max_tokens', max_tokens)
segment.put_metadata('temperature', temperature)
try:
response = client.converse(
modelId=model_id,
messages=[{
"role": (("user" if i % 2 == 0 else "assistant")),
"content": [{"text": content}]
} for i, content in enumerate(contents)],
inferenceConfig={
"temperature": temperature,
"maxTokens": max_tokens
}
)
logger.info(f"Got response from {model_id} in {client.meta.region_name}.")
return response
except ClientError as e:
if e.response["Error"]["Code"] in ("ThrottlingException", "ServiceQuotaExceededException"):
logger.warning(f"Rate limit hit for model {model_id} in {client.meta.region_name}.")
return None
raise
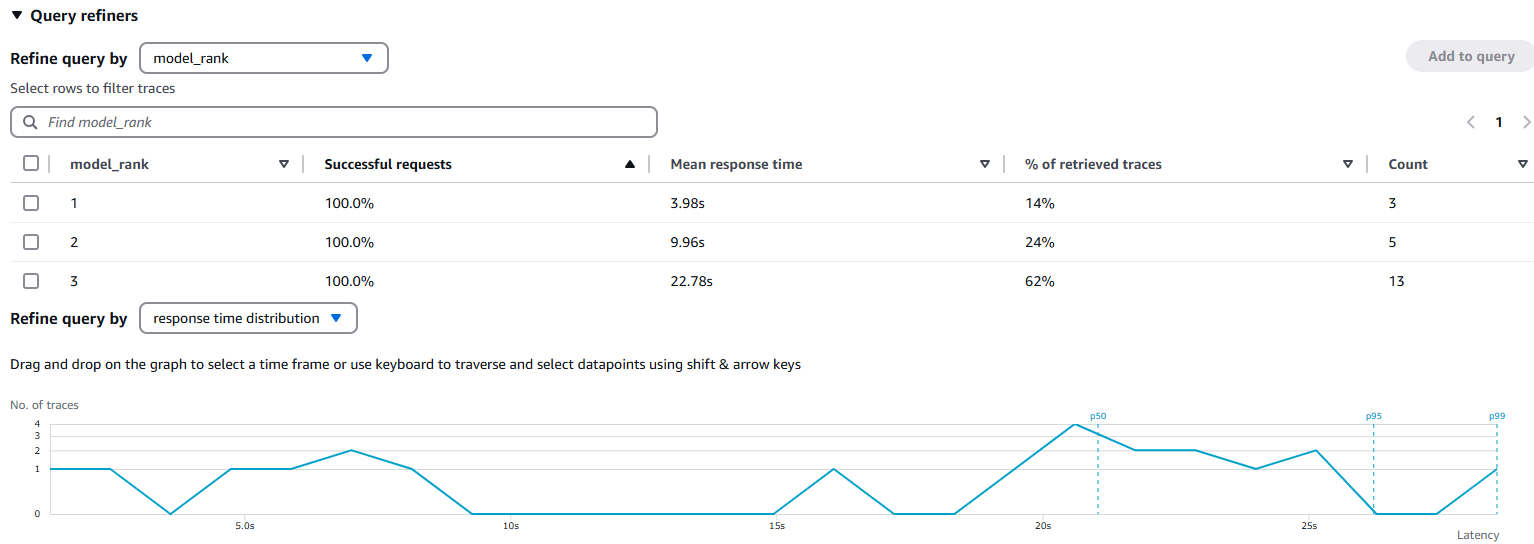
put_metadata を使用することでセグメント内のデータを記録できます。put_annotation との違いは、put_annotation で入力した項目は検索に使用できるという点です (参考 : Add annotations and metadata to segments with the X-Ray SDK for Java)。今回は、モデルを切り替えた回数 (model_rank) に関心があるのでこちらを annotation で記録しています。これにより、下図のように特定時間内のリクエストにおいてモデルの切り替えがどの程度発生したのか、また応答時間の統計を素早く把握できます。この結果は次のテストのセクションで深堀します。
metadata で記録した内容はセグメントの詳細で確認できます。今回はリクエストを検証できる内容を記録しています。
3. 推論を止めないインフラのテスト
では、本当に「どんとこい」なのか 20 リクエストを並列で実行して試してみます。
for i in {1..20}; do curl -X POST -H "Content-Type: application/json" -d '{"contents": ["Tell me a joke"], "temperature": 0.8, "max_tokens": 2048}' -s "<your endpoint url>" > /dev/null & done; wait
AWS Console で CloudWatch > X-Ray traces > Traces からメニューをたどり、直近 N 分で実行されたログを分析します。 model_rank 、すなわちモデルが切り替わった回数ごとに統計を見ると、一発で推論できた (model_rank = 1) のは 18% と全体の 2 割程度、23% は 2 回目、そして 59% と半数超は 3 回目で推論を完了しています。3 段体制にすることで本来失敗する 82% のリクエストを無事に処理することができたと考えられます。

ここで問題なのは、一番最初に作成した「優先度マップ」と実際の割合が一致しているかです。優先度マップにおいて 80% は最優先のモデル、model_rank = 1 で処理したいとしたら理想と現実に 62 ポイントの大きなギャップがあることになります。このギャップを認識することで、Quota の引き上げをリクエストする、必要な場合は Provisioned Throughput を検討する、そもそもプライマリのモデルでないと本当にダメなのか検討する、など様々な対策が検討できます。
4. 最適な推論インフラにむけた Next Step
最後に、最適な推論インフラに向けてギャップを埋めていくためのヒントを提示します (まだ出たてのサービスもあり私自身試せていないところがあるので、検証出来次第追記したいと思います。)
4.1 ユーザー体験の評価
事前にベンチマークなどでテストできるものの、二番手以降のモデルで処理した時にユーザーの体験が損なわれていないか監視したいところです。これによりユーザーが離脱し始める前に異常に気づくことが出来ます。素朴な方法は、二番手以降のモデルを使用した応答について一番手のモデルと回答結果を比較することです。具体的には次の手順で行います。
-
Model Invocation Logging で Amazon Bedrock の呼び出しを記録し、二番手以降のモデルでユーザーに応答したケースを Amazon Athena などで抽出
- X-Ray のログを S3 に落とすのはかなり難しいので、若干手間ですが Converse/InvokeModel API を実行するときに任意のrequestMetadata を仕込むことが出来るので、ここに
model_rankなど検索で使用したいキーや同一の Trace を現す ID を入れておくと集計できそうです。Model Invocation Logging の内容は CloudWatch だけでなく S3 にも送れます
- X-Ray のログを S3 に落とすのはかなり難しいので、若干手間ですが Converse/InvokeModel API を実行するときに任意のrequestMetadata を仕込むことが出来るので、ここに
-
Amazon Bedrock Batch Inference を使用し、一番手のモデルでユーザーへの応答を作成
- 試してみた記事 : Amazon Bedrock のバッチ推論が GA したので試してみた
-
Amazon Bedrock Evaluation を使用し、二番手のモデルと一番手のモデルの応答を 人手 / LLM を使い評価
- 人間での評価 : Amazon Bedrock モデル評価の「人間ベースの評価」を試してみた
- LLM での評価 (LLM as a Judge) : Amazon BedrockのLLM as a judge機能を試してみる
Amazon Bedrock にはオンデマンドの推論以外にバッチ推論があり、オンデマンドとは別建ての Quota かつ安価に推論ができます。また、マネージドで評価の仕組みがありこちらもオンデマンドとは別建ての Quota になるためユーザーのための推論リソースを圧迫しません。これらの機能によりバックエンドでモデルの推論結果を評価できます。
4.2 プロンプトの最適化
一番手に精度が劣るモデルでも、プロンプトを最適化し精度を高めることが出来ます。Amazon Bedrock ではプロンプト最適化の機能がプレビュー中です (執筆時点)。次の手順で最適化したプロンプトを使い推論できます。
- 一番手のモデルのプロンプトを、二番手のモデルにとって最適になるよう最適化
- 最適化したプロンプトをプロンプトマネジメントの機能に登録
2. 試してみた記事 : 意外と(?)いろいろできるAmazon Bedrock Prompt ManagementがGAしましたよ! - 登録したプロンプトは推論エンドポイントとして使用できるため、YAML ファイル内の
model_idとして設定する
4.3 コストの最適化
精度の高いモデルはその分値段も張り、ROI の実現には精度だけでなくコストの最適化も課題です。Amazon Bedrock の推論エンドポイント、推論プロファイルにはコスト配分タグをつけられないですが、アプリケーション推論プロファイルでラップしコスト配分タグを付与できます。
- 試してみた記事 : 複雑になってきたBedrockの「モデル」を整理する
4.4 Cross Model の Managed 化
re:Invent 2024 で、Prompt Routing という与えられたプロンプトの複雑度などに応じてコスト最適なモデルを自動選択する機能がアナウンスされました。現在は Claude 3.5 Sonnet or Claude 3 Haiku 、Llama3.1 70B Instruct or 8B のモデル選択、さらに英語プロンプトのみ、バージニア / オレゴンのみとなりますが将来より幅広な言語、リージョンで対応するでしょう。こちらの機能が成長してくれば Cross Region / Cross Model による推論最適化はクラウド側にお任せできるようになるかもしれません。
5. おわりに
本記事では生成 AI の推論制限に負けずユーザーへ価値を届ける推論インフラの設計と実装を紹介しました。また、更なる最適化に向け評価・改善の方法、Managed に Cross Model / Cross Region ができるようになるかもしれない、Prompt Routing を紹介しました。本記事が生成 AI のサービス、機能の市場投入に際し助けになれば幸いです!