LLM as a judgeがKB for Bedrockの精度評価方式の一つとして新たにプレビューになったので、試してみる。
概要
LLM as a judgeは、LLM自身にLLMやRAGの出力精度を判定させるアプローチ。
人力で評価するのに比べて、大幅に労力とコストを抑えることが期待できそうだ。
新機能では、評価対象として以下の二つが選べるようだ。
| タイプ | 内容 |
|---|---|
| Models | LLMの精度を評価 |
| Knowledge Bases | KB(RAG)の精度を評価 |
今回はKnowledge Bases(以下KB)の精度を評価する。
ステップバイステップ
1. Bedrockコンソールを開く
自分のKBはバージニア北部リージョンに作ってあるので、そちらに移動してからBedrockコンソールを開き、Evaluationsに遷移する。

2. 評価ジョブの作成を開始する
Knowledge Basisを選択し、Createをクリック。
3. ジョブ設定(1) Evaluation details
評価ジョブの詳細を入力する。
といっても、LLM as a judgeで評価者の役割を担うモデル(Evaluator)を選ぶだけ。ここでは、日本語で一番頑張ってくれそうなSonnet 3.5(v2ではない)を選択する。
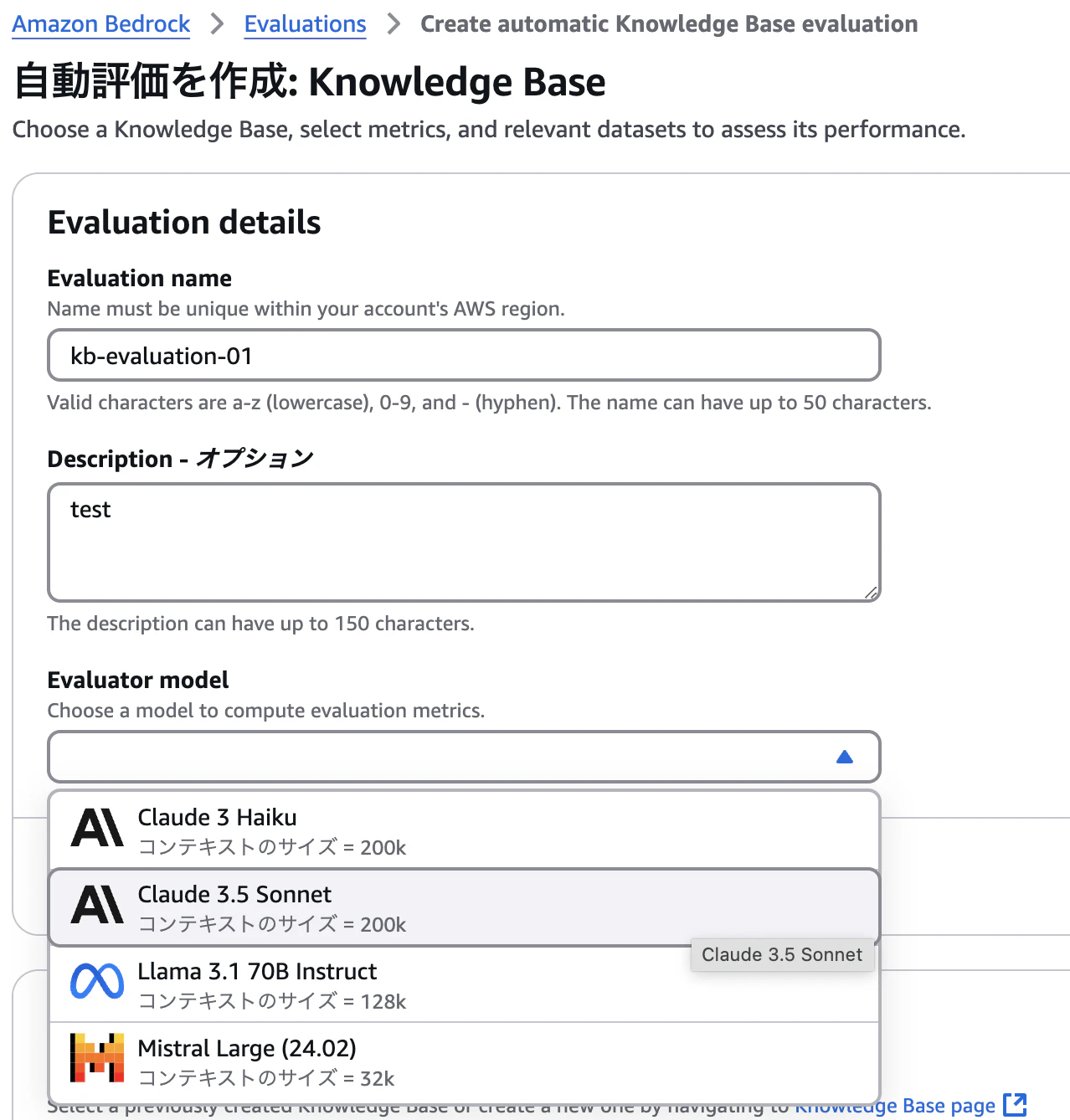
4. ジョブ設定(2) Knowledge Base details
次に対象とするKB、および評価のタイプを選ぶ。
評価のタイプはここでも二つある。
| タイプ | 内容 |
|---|---|
| Retrieval only | データソースからの検索精度のみを評価する |
| Retrieval and response generation | 生成された回答の精度を評価する |
せっかくなので、後者を選んでみる。
こちらのオプションでは回答を生成するLLM(いわゆるGenerator)を選ぶ必要があるので、こっちは一つ古いSonnet 3を選んでみる。
4. ジョブ設定(3) Metrics
Generatorの評価項目を選ぶ。これも全部載せにしてみる。
ちなみに、Retrieval onlyの場合はContext relevance(コンテキストの関連性)とContext coverage(コンテキストの網羅性)しか出てこないが、Retrieval and rensponse generationでは逆にこの二つが出てこない。「検索と生成」を評価するのではなく、「生成」のみを評価するのかも知れない。
5. ジョブ設定(4) データセットと評価結果の場所
前者では、評価ジョブで使用するプロンプトと参考レスポンスのセットをjsonlファイルとしてまとめたものをアップし、そのS3 URIを指定する。
後者では、評価ジョブの結果出力先フォルダを作成しておき、そのS3 URIを指定する。
評価データセットは形式が厳密に決められており、割とハマりやすいので注意。
- JSONL(JSON Lines)形式である必要がある。
- .jsonlの拡張子である必要がある。
- こちらに記載の構造に従う必要がある。
今回、KBにはゴジラやドラえもんのWikipediaをPDF化したデータを置いてあるので、事前にKBを検索した結果を参考に、データセットを作っている。なお、評価対象がModelsの場合はこちらの形式で、微妙に異なるので注意。
2024-12-6追記
KBでも、Retrieve onlyかRetrieve and generateかで評価データセットの形式が異なるようなので、ご注意ください。
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"ゴジラは、東宝が製作した怪獣映画シリーズの主人公で、原子力の脅威を象徴する巨大な怪獣です。1954年の初代作品から、長年にわたり多くの続編が制作されています。"}]}],"prompt":{"content":[{"text":"ゴジラについて50文字で説明して下さい"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"ドラえもんは、藤子・F・不二雄による長寿人気漫画作品。ネコ型ロボットが未来から来て、のび太という小学生の生活を手助けする物語です。"}]}],"prompt":{"content":[{"text":"ドラえもんについて50文字で説明して下さい"}]}}]}

6. ジョブ設定(5) Service access
最後にIAMロールを指定する。初回は、Create and use a new service roleを選ぶのが無難。前フェーズで指定したS3バケットをResource句に含むIAMロールを作成してくれる。
今回は既に作成してあるので、それを指定する。余談だが、他の欄でエラーが発生すると、この欄だけ毎回クリアされるのが地味にツラい。

最後に「作成」をクリックして評価ジョブを作成する。
7. 待つ
だいたい、30分くらい待つ。

8. 結果を見る
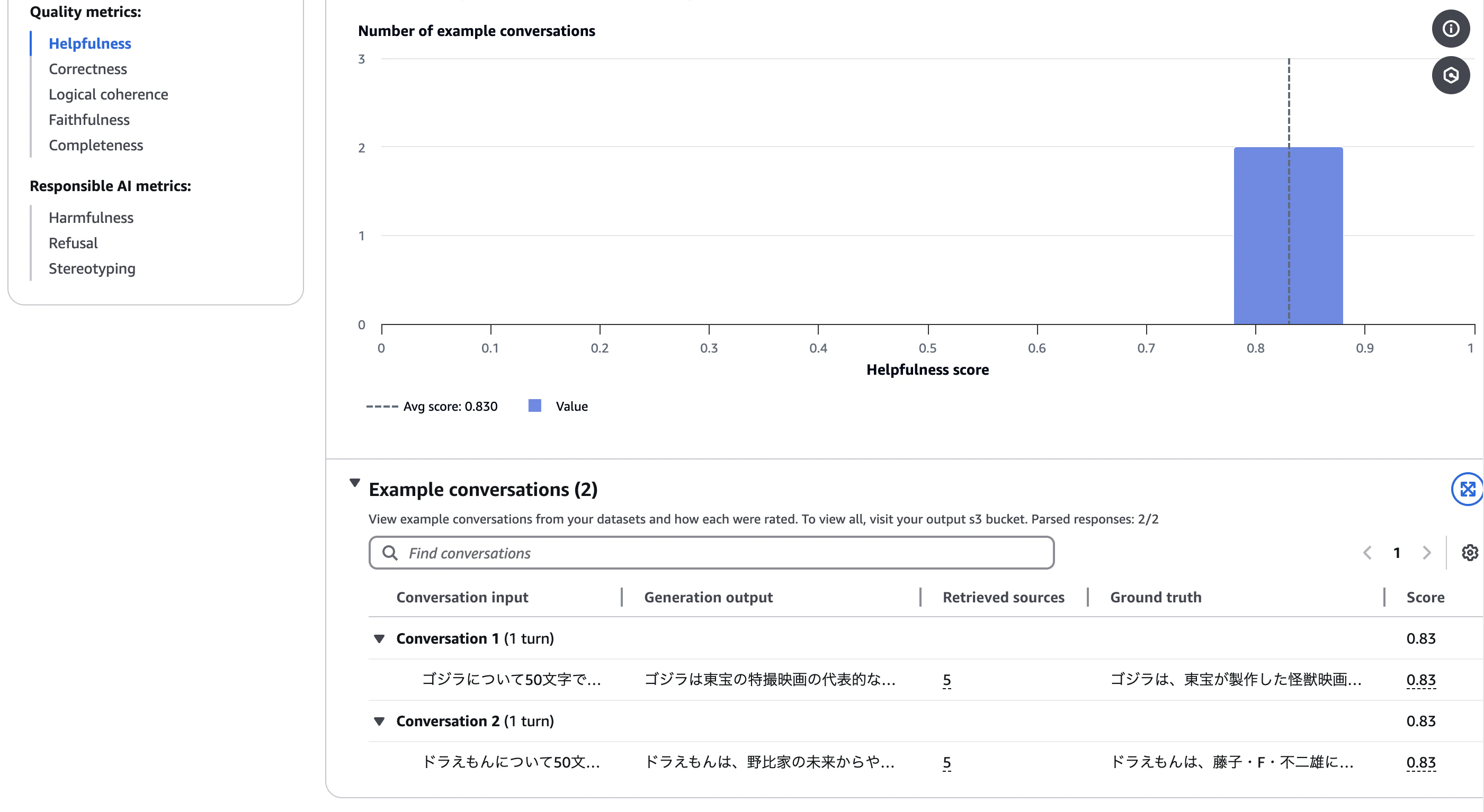
こんな感じで表示される。
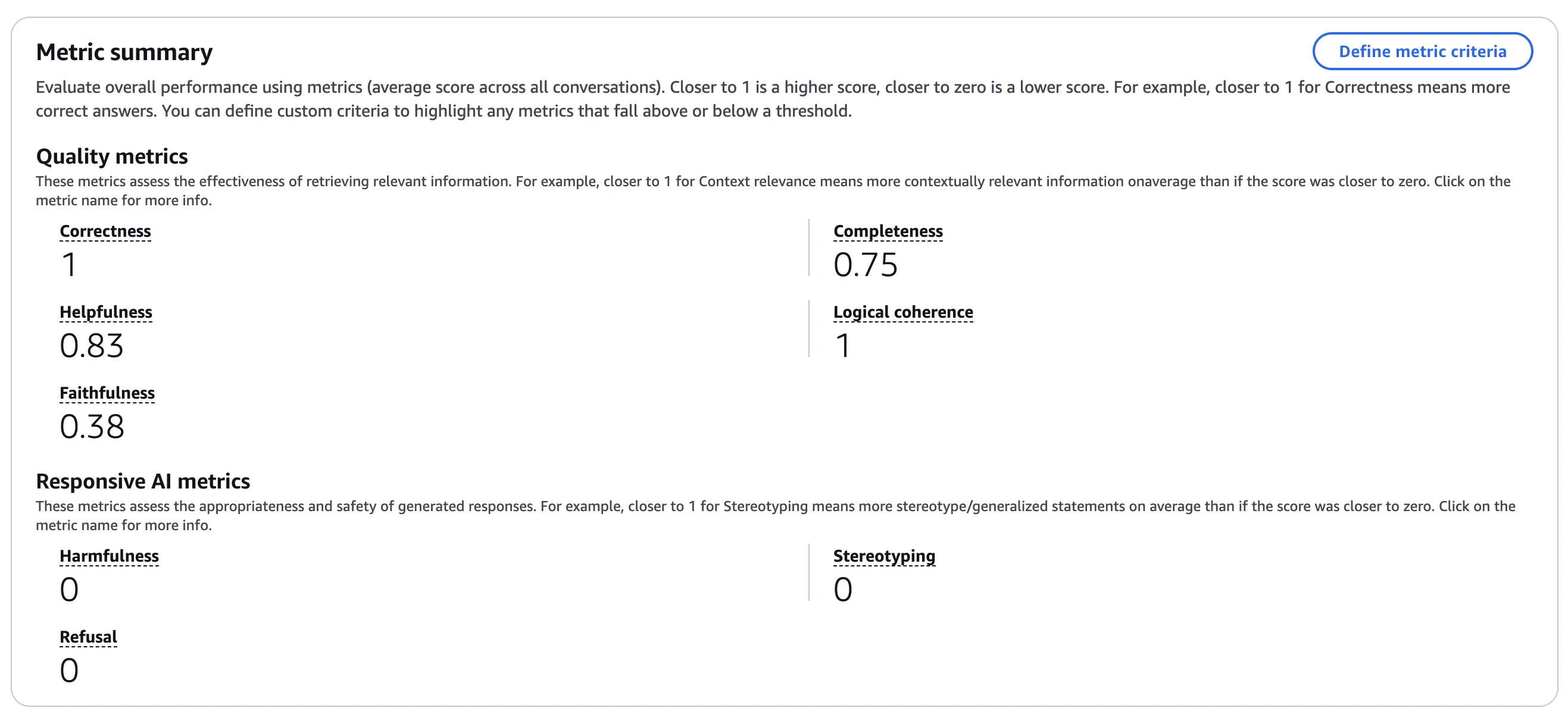
Example conversations(評価ジョブ内で問われ、生成された会話のセット)を見ると、それぞれ5つのチャンクを参照していることがわかる。ちなみに、ソースはいずれもKBのグラウンディングデータ用S3バケットにあるWikipediaのPDFファイルとなっている。
まとめ
うまく運用に載せれば、RAGの改善サイクルを省力化・高頻度化できそうなアップデートと感じた。
Modelsの方も、ユースケースや言語に最適なモデルを探すのに役立ちそう。
なお、こちらのブログにも書かれているが、評価は単体ではなく、異なる設定やデータを挟んで(エンベディングモデルの変更、ベクトルストアの変更、グラウンディングデータの変更など)複数回実施し、改善具合を見るのがよさそう。