AI エージェントを作る時に流行りのハンズオンや書籍から始めるのも良いですが、"AI エージェントに何をしてほしいんだっけ" を形にするとより継続的に改善したくなるエージェントの開発に繋がります。本記事では、何をしてほしいかという要求、つまり Spec (仕様) と評価を先に作ってから開発する方法を紹介します。
仕様駆動開発とは
"Spec" というのが耳慣れない方もいると思います。そのため、この語源となっている " Spec Driven Development / 仕様駆動開発" のコンセプトとそれを進めやすくする開発環境 Kiro について解説します。
Spec Driven Development (仕様駆動開発) は、実装を始める前に「何を作るか」を明確に定義し、その仕様に基づいて開発を進める手法です。AI エージェント開発においては、ゴール、ユーザー属性、シナリオ、評価基準といった要素を事前に定義します。
Kiro は AWS が提供する AI 駆動の開発環境で、Spec Driven Development を効率的に進めることができます。Kiro ではユーザーの要望を requirements.md にて仕様に分解し、仕様を実現するための設計を design.md で行い、tasks.md で実装タスクを分解して実装をしていきます。Kiro はこれらのワークフローが GUI 上でスムーズにできる点、また「正確性プロパティ (Correctness Properties)」による確認で要件の実装漏れないよう追跡することができます。
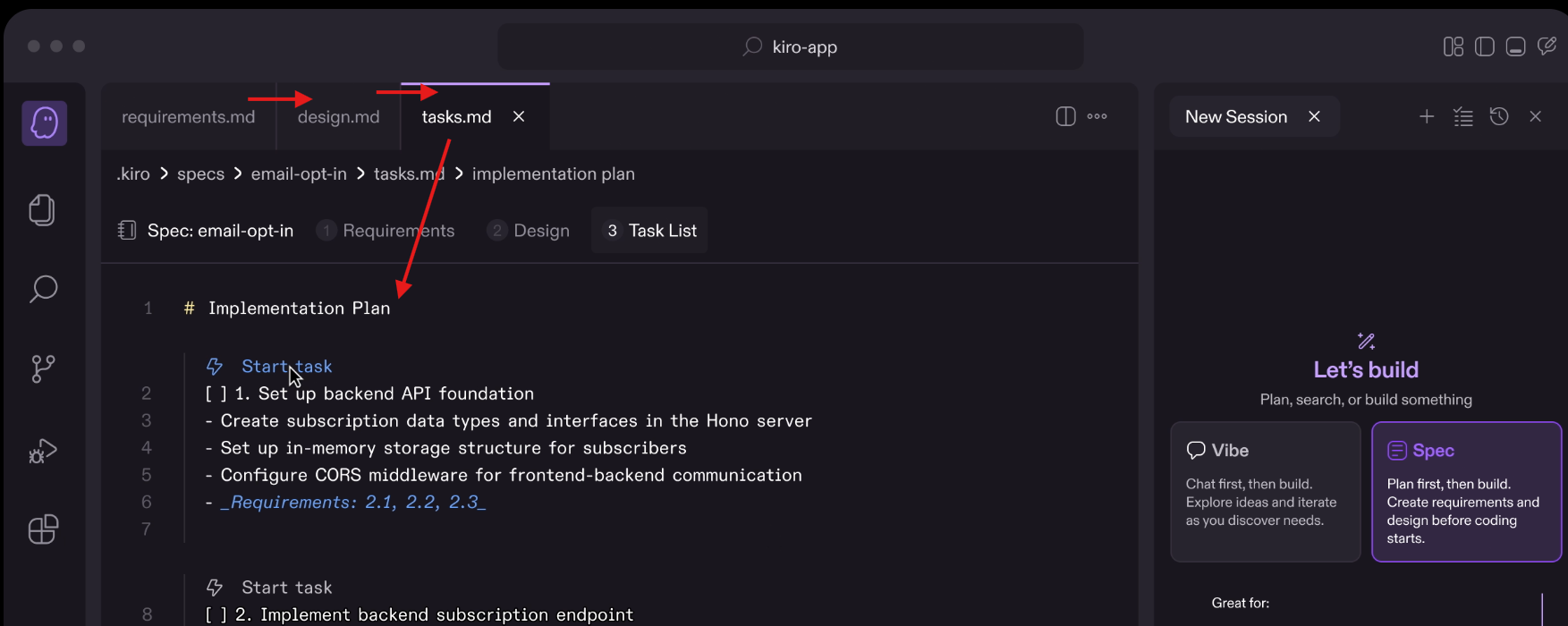
(Kiro の画面 : requirements => design => tasks という流れを画面上で進められる様子)
今回は、この "仕様" に評価に書かせない "期待する動作" を含めておく進め方になります。具体的には、AI エージェントとユーザーとのやり取りで期待する会話例 (シナリオ) とそれに対する評価です。舞台で演劇をするときに、先に台本を用意するのと似ています。
仕様駆動「評価」が必要になる背景
エージェントが完成した瞬間をイメージしてみましょう。ハンズオンに沿って手元のドキュメントやインターネットを検索して回答してくれるエージェントを完成させたとします。少し使ってみた後に、これっ Claude / Gemini / ChatGPT とかのサービスで別にいいかも、と感じることはうっすら想像できます。ハンズオンでもちろん技術的な理解ははかどる一方、自分 / ユーザーにとって「うれしいこと」は明らかでないままです。では、ということで自分以外の人に聞いてみると様々なフィードバックが帰ってきます。
- (多少間違っていてもいいので) 情報の網羅性が重要という人
- 厳密かつ間違いのない正確性が重要という人
- 日々コミュニケーションを取りたくなるフレンドリーな応対が重要という人

(いろいろな人にいろいろなことを言われ / 提案され困っているエージェントの様子 by Gemini)
いろいろな人の意見を聞くほど余計に迷ってしまいます。
事前に AI エージェントの評価軸を決めて合意しておくと、AI エージェントを求める人の求めるユースケースに届けることができます。この合意形成をシナリオに基づいた具体的な会話例、エージェントによるシミュレーション結果をもとに行うとより届けるべき体験がクリアになります。
ここからは、指標駆動評価を進めるための 3 ステップに沿って解説をしていきます。このプロセスは自然言語処理の研究をもとに実際私が試してみたもので、改善の余地はありますが参考に頂ければ幸いです。
仕様駆動評価 Day1 : 実現したいシナリオを形にする
Phase 1 は Scenario Planning です。このフェーズでは、1) AI エージェントの役割をきめる、2) 評価観点をきめる、3) 評価シナリオをもとに会話例を作成し合意する、という流れで進めます。AI エージェントの類型や評価観点は合意形成の基盤となるため、実績があるフレームワークを使いたいところです。自然言語処理の研究では対話システムについて長い研究の歴史があるため今回はそちらをベースにしました。
AI エージェントの役割の分類軸
対話システムはタスク指向型、非タスク指向型、質問回答の大きく 3 つにわけることができます。タスク指向型ではレポートを作る、スライドを作る、モノを買ってくる、特定のゴール達成に向け会話を行います。非タスク指向型は雑談やカウンセリングなど目的やゴールがあいまいなケースに該当します。質問回答では質問+回答という会話のやりとりにフォーマットがあります。

(参考 : AI エージェントを評価するための温故知新と Spec Driven Evaluation)
いわゆる AI エージェントの多くはタスク指向型に該当します。類型が決まると、各類型ごと用いられてきた評価観点がおのずと決まり評価しやすくなります。
Checkpoint:
✅ : 作成する AI エージェントの役割が決まっている
AI エージェントの評価観点
対話システムの研究で用いられてきた、システムの役割ごとの評価観点を下表にまとめています。右側 3 列がどの累計で使用されているかを示しており、Task はタスク指向型、Conv は非タスク指向型、QA は質問応答型になります。

(参考 : AI エージェントを評価するための温故知新と Spec Driven Evaluation)
どれを使うか迷うところですが、ポイントをまとめます。
タスク指向型の満足度は、タスクの完了率・対話のコストに分けて計測する
- 完了率 : タスクに不可欠な情報取得の完全性 etc
- 対話のコスト : 会話数 / 修正数 etc
- タスク指向型は LLM 以前でも手順が明確であれば 9 割以上成功することがわかっており、完了率よりコストの方が重要
非タスク指向の評価は話題の幅と深さに分ける
- 幅 : 会話中に含まれるトピックの多さ
- 深さ : ユーザーとの会話のターン数
- 深さの方が満足度に影響を持つ傾向がある
- ユーザーが対話するトピックを見つける幅も重要であり、幅による探索、深さを出すための知識 / 応答性能のバランスを取る必要がある。強化学習における探索・活用のバランスと同義
質問回答は、検索の正確性と応答の品質に分けて計測する
- 検索の正確性 : RAGAS でもある検索で取得する Context の正確性 (ranking) / 網羅性 (coverage)
- 応答の品質 : タスク指向と同様、回答の満足度/コストを計測
研究で得られている知見として、「ユーザー属性間の汎用性は落ちる」という点があります。つまり、初心者と熟練者といった属性が異なるユーザー間では評価基準が異なる ということです。AI エージェントを複数の異なるペルソナの人が使うのであればその属性ごとに評価を行った方が適切です。
Checkpoint:
✅ : 役割に応じた評価観点が決まっている
✅ : AI エージェントを扱うユーザー属性が整理されている
評価シナリオをもとに会話例を作成し合意する
ここまでで、AI エージェントの役割に基づく評価観点とユーザー属性の 2 つがわかっています。これらを組み合わせ評価シナリオを作ります。具体例がないとわかりずらいので、実例として病院のスケジュールを行うエージェントを考えます。
こちらは、指定日時のリハビリスケジュール (誰が誰をいつ担当) を作成するエージェントになります。リハビリを提供できるセラピストの一覧、患者の方と必要とするリハビリのリスト、セラピスト勤務表の 3 点から計算を行います。
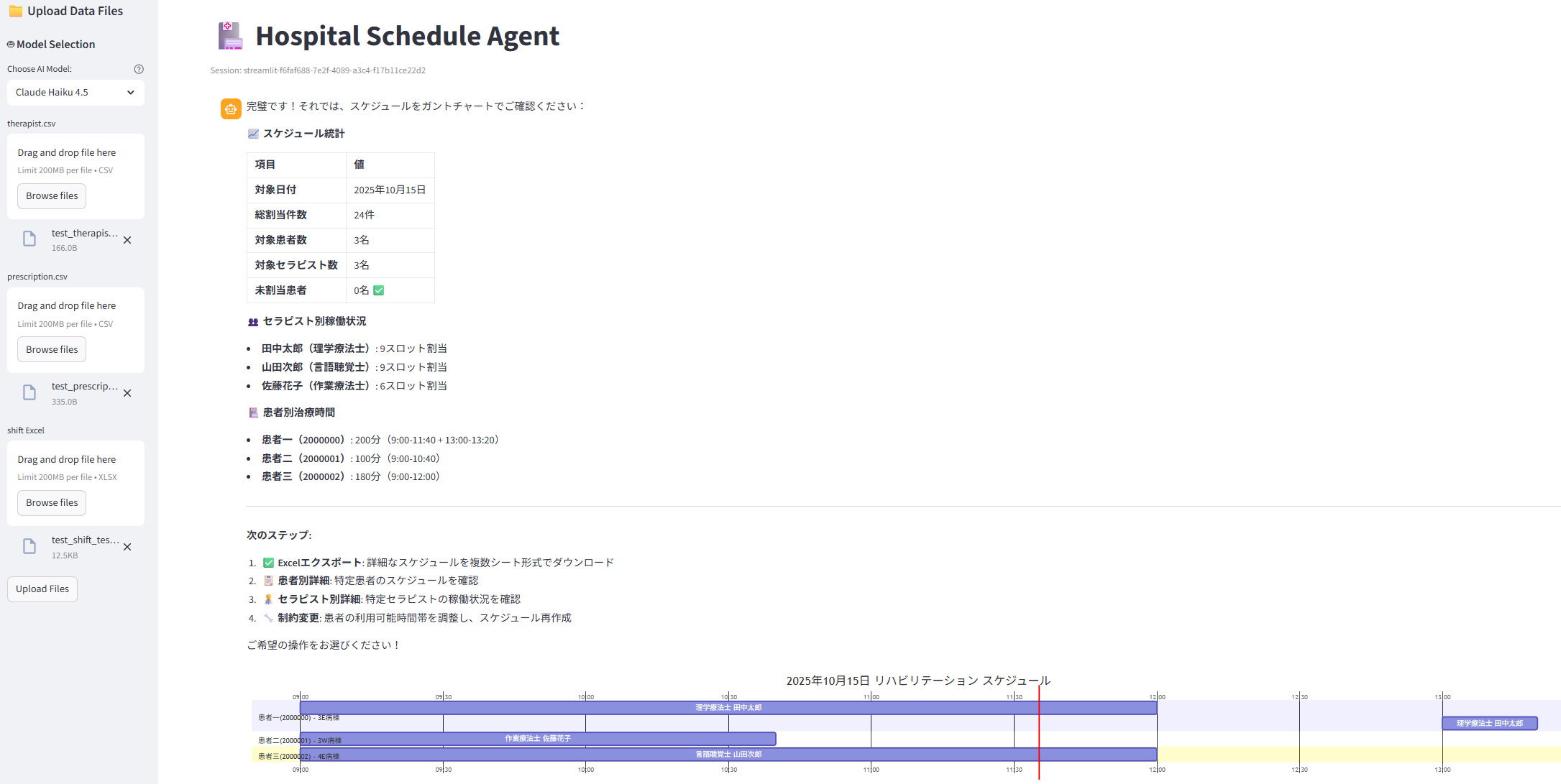
AI エージェントの役割は「タスク指向型」、よって評価観点は「タスクの成功」「対話のコスト」になります。タスクの成功はスケジュール作成の成功、対話のコストは作成条件の指定 / 訂正回数になります。
スケジュールの作成は数理最適化を使用しており、AI エージェントは最適化のパラメーターを会話から推定して最適化をツールとして実行するのが主な仕事になります。これにより、自然言語により突発的・流動的な最適化の条件を変更しいろいろなパターンを試すことができます。
このエージェントについて、評価シナリオの作成、会話例の作成を進めていきましょう。
評価シナリオの作成
ユーザー属性と対話コストの 2 軸で複数のシナリオを作成します。これは、「ユーザー属性ごとに評価観点が異なる」、「タスク指向型では対話コストの方が重要になる」という 2 点の学びに基づいています。
ユーザー属性の熟練度として entry / medium / skilled、対話コストとして simple / moderate / complex の 3 パターンにして、3 x 3 で 9 シナリオが作成できます。
simple moderate complex
entry S1 S2 S3
medium S4 S5 S6
skilled S7 S8 S9
シナリオはこのままだとぼやっとしているので、会話生成の骨格となる骨組みを JSON などで定義します。例えば次のような形です (sample)。
{
"scenario_id": "S1",
"task_difficulty": "simple",
"user_skill": "entry",
"end_state": "success",
"expected_satisfaction": 4.2,
"features": {
"turns": 6,
"corrections": 1,
"retries": 0,
"clarifications": 1
}
}
-
scenario_id: シナリオの区分-
task_difficulty: タスクの難易度 -
user_skill: ユーザーの熟練度
-
-
end_state: 成功 or 失敗 -
expected_satisfaction: 満足度 (5段階評価) -
features: シナリオの構成-
turns: 会話のターン数。task_difficultyが高いほど多くなる -
corrections: 会話で訂正した回数。task_difficultyが高いほど多くなる -
retries: 作成し直した回数。task_difficultyが高いほど多くなる -
clarifications: システムからの確認。task_difficultyが高いほど多くなる
-
特に expected_satisfaction で満足度、features で会話の構成を定量的に決めておくことは "満足度" や "難易度" といった曖昧な言葉を具体的するのに役立ちます。features の構成要素のうち corrections などはユーザー/システムの発話意図を現すものです。自然言語処理の研究では Dialog Act と呼ばれる対話行為の種別を分類するタスクがありそのラベルを意識して設定しています。
これを人力で作るの? 大変じゃない? となるので、生成 AI を活用した "Spec Driven Evaluation" としゃれこみます。

まずは Spec を作ります。
-
evaluation.md
- ※ 威勢よく Kiro のアイコン書いてますが今回は Kiro CLI を使っており、Spec ファイルは
specというディレクトリにまとめ評価についてはevaluation.mdに記載しています
- ※ 威勢よく Kiro のアイコン書いてますが今回は Kiro CLI を使っており、Spec ファイルは
こちらで生成 AI と相談しながらシナリオの種類と対話行為の種別を詰めていきました。
次の会話例の作成で、煮詰めた Spec を基にして実際の JSON / 会話例を作成します。
会話例の作成
Spec を基に実際作成した会話例です。 (sample)
シナリオの定義には、満足度と対話フローが明示されています。
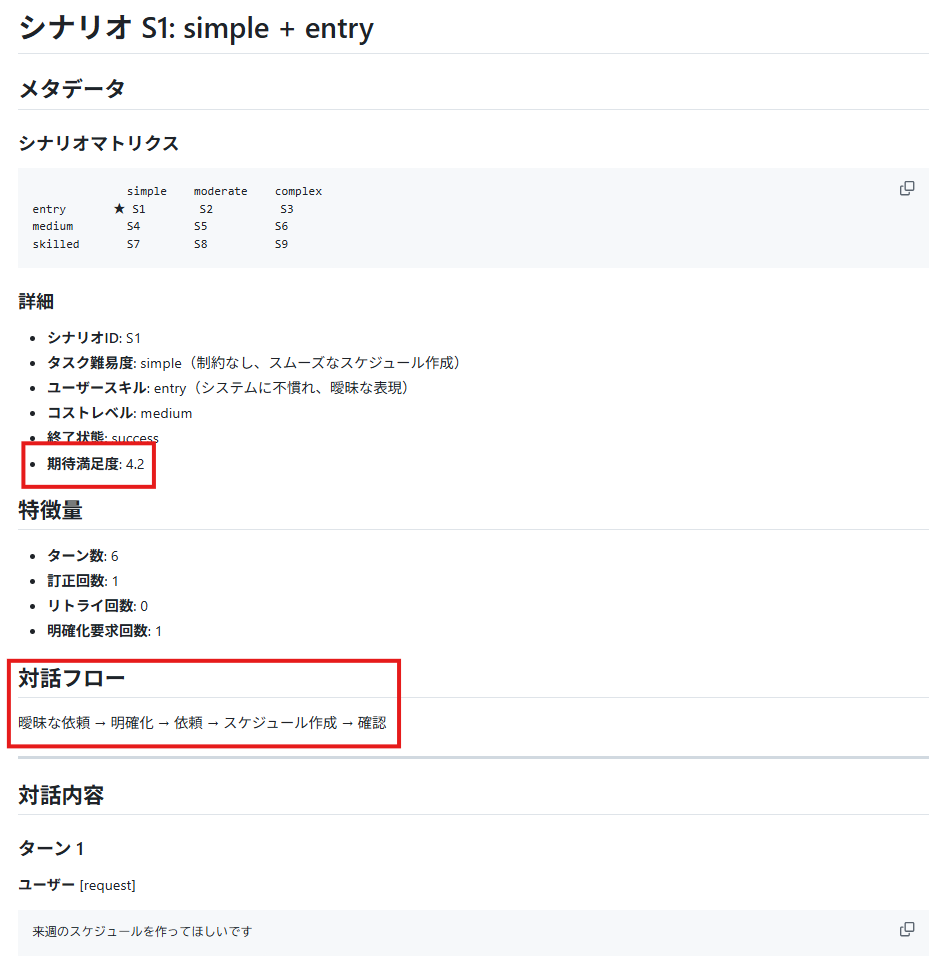
会話の中でツールを呼び出す場合はそれも書いておきます。
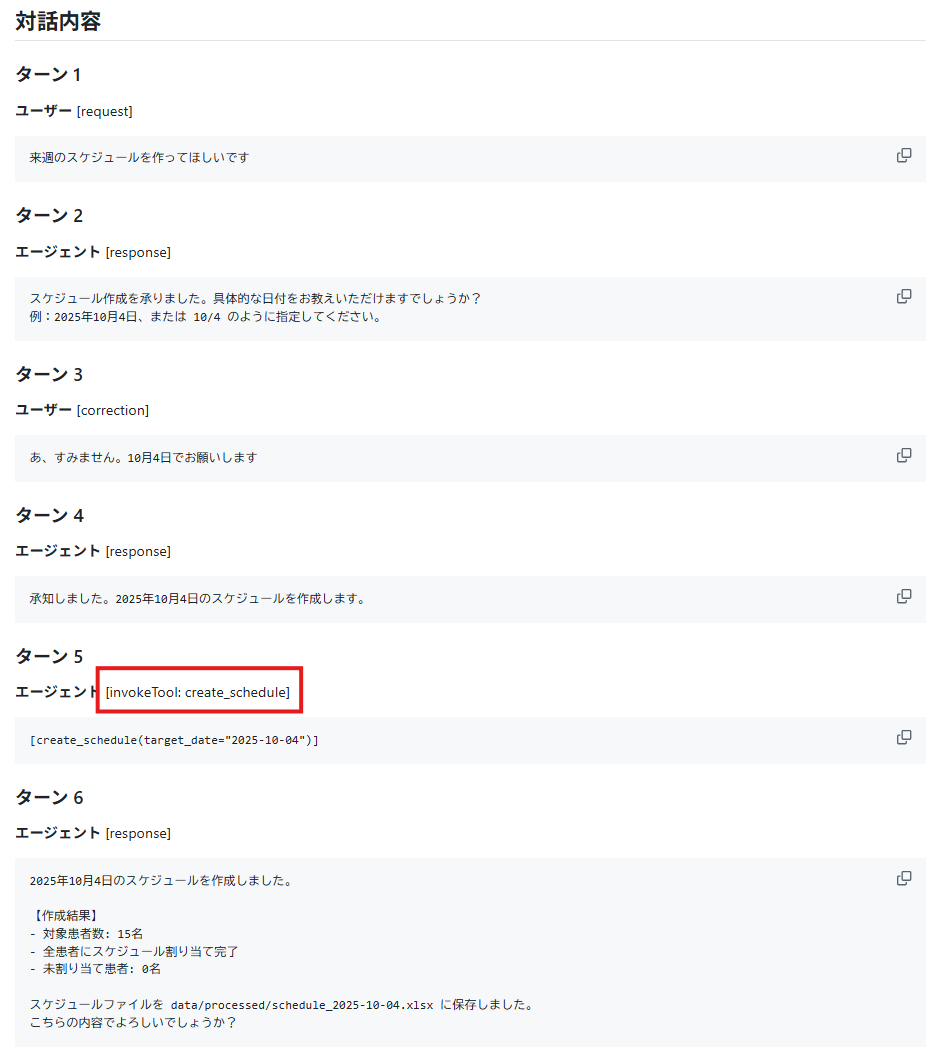
「来週のスケジュールを作ってほしい」「具体的な日付っていつ?」「えっと・・・」みたいな会話が具体的に出てくると、体験がイメージしやすくなります。そのうえで、この体験が満足度どれぐらいなのか? という定量値がついています。これにより、3 点のメリットが得られました。
- どういう体験が出来たらどれぐらい満足なのか、の確認と合意が「誰とでも」取りやすくなった
- 体験に必要なツールを明らかにできる
- 生成 AI で作るので、成功/失敗、長い/短いなど様々なパターンをシナリオ定義に基づき生成可能
※なお、ツール (スケジュール作成 / 数理最適化) のテストは別途行い、ここでは指定された条件でスケジュールは出てくることを前提にしています。
会話例を基にした体験の定量的な設計・確認によって、誰がどれぐらい嬉しいのか、体験を達成するにはどの程度対話のコストを下げなければいけないのか、が明確になりました。
Checkpoint:
✅ : 会話例を基にしてどういう体験がどの程度の満足度なのか確認・合意できている
✅ : どのタイミングでどんなツールが必要か明確になっている
仕様駆動評価 Day2 : シナリオをシミュレーションする
Phase 2 は Simulation です。会話例が実際に再現されるか ? を事前にシミュレーションして想定とのギャップを洗い出します。具体的には、Day1 で作ったシナリオに沿って動く Agent を作成しスケジュール作成 Agent と対話させてみます。その対話の結果を評価し、想定していた対話コストと満足度とどれだけギャップがあるのかを測定します。
シナリオを再現するための User Agent の実装例を示します。USER_PERSONA によって異なるシステムプロンプトを設定し、指定された Dialog Act に応じた挙動をプロンプトで指示します (実装には Strands Agents を使っています : scenario_simulator.py)。
DEFAULT_MODEL = "global.anthropic.claude-sonnet-4-20250514-v1:0"
CONTEXT_WINDOW = 4
RESPONSE_TRUNCATE = 500
USER_PERSONAS = {
'entry': "病院のリハビリスケジュール管理システムに不慣れな初心者。曖昧な表現を使い、丁寧だが要領を得ない質問をする。",
'medium': "基本操作を理解している中級ユーザー。明確な日付指定ができ、基本的な要求は正確に伝えられる。",
'skilled': "熟練ユーザー。コマンド形式の正確な指示、簡潔で効率的なコミュニケーション(「OK」「了解」など)。"
}
ACTION_PROMPTS = {
'request': "新しいリクエストを開始する\n{context}\nあなた({user_skill}レベル)として、リハビリスケジュール作成を依頼してください。",
'approve': "エージェントの提案を承認する\n{context}\nあなたのスキルレベル({user_skill})に合った言い方で承認してください。",
'correction': "自分の発言を訂正する、または追加情報を提供する\n{context}\nエージェントの質問や指摘に対して、訂正または追加情報を提供してください。",
'abandon': "タスクを諦める\n{context}\nタスクを諦めることを伝えてください。"
}
class UserSimulatorAgent:
"""Generates realistic user utterances based on action types and user skill level."""
def __init__(self, user_skill: str, model: str = DEFAULT_MODEL):
self.user_skill = user_skill
self.user_agent = Agent(
name="UserSimulator",
system_prompt=f"あなたは{USER_PERSONAS[user_skill]}\n日本語で自然な会話をし、指示されたアクションに基づいて適切な発話を生成してください。応答のみを出力。",
model=model
)
def generate_utterance(self, action_type: str, context: str = "") -> str:
prompt = ACTION_PROMPTS.get(action_type, ACTION_PROMPTS['request']).format(
context=context, user_skill=self.user_skill
)
return str(self.user_agent(prompt)).strip()
User Agent と実際の Agent を会話させてシミュレーションの会話ログを得ます。以下に、実装の中核となるコードを示します。
class ScenarioSimulator:
def __init__(self, scenario_file: Path, model: str = DEFAULT_MODEL):
# 1. Day1 で作成したシナリオを読み込む
with open(scenario_file, 'r', encoding='utf-8') as f:
self.scenario = json.load(f)
...
# 2. シナリオのスキルに応じたプロンプトをセットした User Agent を作成
self.user_simulator = UserSimulatorAgent(self.scenario['user_skill'], model)
...
def run(self, data_store: DataStore, hospital_agent) -> dict:
...
# 3. シナリオにおける user 側の Dialog Act を取得
user_actions = [msg for msg in self.scenario['messages'] if msg['role'] == 'user']
conversation_context = []
# 4. Dialog Act に応じた発言を得る
for turn, user_action in enumerate(user_actions, 1):
action_type = user_action.get('action_type', 'request')
...
user_message = self.user_simulator.generate_utterance(action_type, context_str)
try:
# 5. Agent 側の発言を得る
agent_response = str(hospital_agent(user_message))
...
こうして得られたシミュレーションのログに対し、LLM as a Judge、生成 AI で評価を行います。この時重要なことが、Day1 で対話数や訂正数といった定量的なシナリオの構成要素 (features) とそれに対する満足度を合意しておいたことです。これにより、揺らぎやすいテキストベースの評価に比べ、定量的データに基づく分散の少ない評価を行うことができます。例えば、ターン数や訂正回数が多ければ満足度が低いというのは簡単な予測です。過去の対話の研究で、対話ログから特徴量 (Dialog Act 等) を抽出しユーザー満足度を予測していたことに着想を得ています。
prompt = f"""Evaluate this hospital scheduling dialogue:
**Dialogue Metadata:**
- Scenario: {scenario_id}
- Task Difficulty: {session_data['task_difficulty']}
- User Skill: {session_data['user_skill']}
- Turns: {turns}
- Corrections: {corrections}
- Retries: {retries}
**Dialogue:**
{dialogue_text}
**Evaluation Criteria:**
1. Task Completion (40%): Did user achieve scheduling goal?
2. Dialogue Efficiency (30%): Was interaction concise and clear?
3. Error Handling (20%): Did agent recover from errors gracefully?
4. Communication Quality (10%): Was agent helpful and understandable?
Output ONLY this JSON format:
{{
"satisfaction_score": <1.0-5.0>,
"reasoning": "<brief explanation>",
"strengths": ["<strength1>", "<strength2>"],
"weaknesses": ["<weakness1>", "<weakness2>"]
}}"""
評価すると次のように結果を集計できます。差分が大きいところは期待とシミュレーションの結果にギャップがあることを意味しています。ちなみに今回差分が多かった理由は会話が成立していない以外に、 Quota のエラーで会話が中断していた例がありました (S8)。期待した体験を届けるなら Quota を上げておかないといけないといった知見がシミュレーションで得られたのは有益でした。
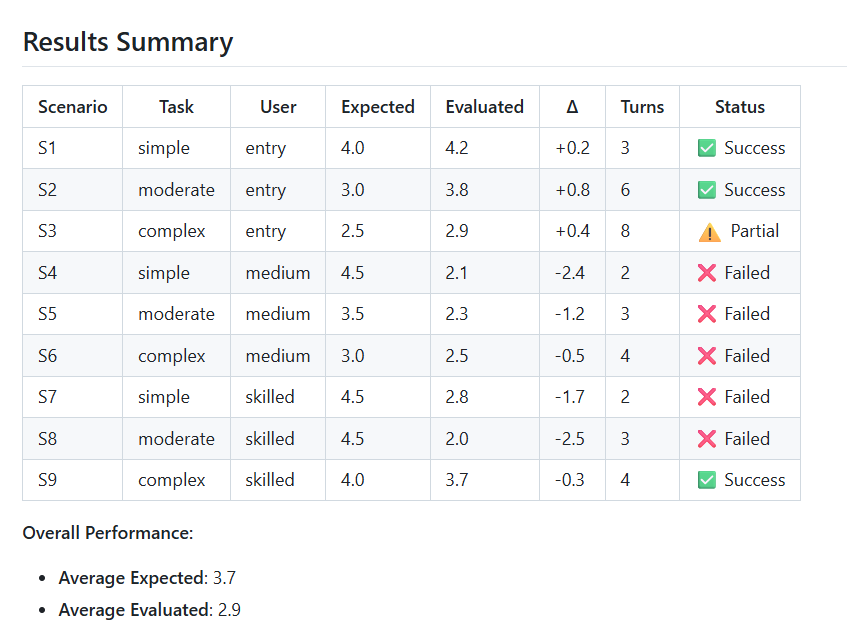
リハビリスケジュール作成エージェントの事例では、シミュレーションにより曖昧な時間指定 (「今日」「来週」) によるエラーパターン、割り当て不可能な場合の対話フロー、想定外の対話コスト (ターン数の増加) を特定できました。
Checkpoint:
✅ : 期待する会話例を基にしてシミュレーションを行い、期待とのギャップを定量的に把握できている
✅ : 体験的 (指定条件で作成できない場合の対処)、技術的 (Quota 等) な課題が洗い出せている
仕様駆動評価 Day3 : 実際の評価を継続する
Phase 3 は Operation です。実際のユーザーと対話させてみて継続的な評価を行います。Amazon Bedrock AgentCore の Evaluation 、また Langfuse の Dataset 機能などが実装に役立ちます(実装について検証した記事を別途書こうと思います)。シミュレーションと同様、期待と現実にギャップが検出されれば原因を特定して改善していきます。
仕様駆動評価で得られた効果の体験談
リハビリスケジュール作成エージェントの評価を通じて、以下の効果を実感しました (Phase3 はまだこれからです)。
- Phase 1 (Scenario Planning) では、具体的な会話例を見ることで「今日」や「来週」といった曖昧な指示によるエラーや、スケジュールが作成できない場合どう落ち着けるべきかなど、例外ケースの検討が充足し、事前の改善に活かせました
- Phase 2 (Simulation) では、シミュレーションを行うことで、対話コスト (ターン数) がどれぐらいかかるか、また Quota によるエラーがどの程度で発生するかなど、現実的な問題を事前に把握できました

(関係者が協力して具体的な仕様を決めている図 by Gemini)
ご紹介したコードはまだ粗削りですが、Spec から Simulation まで約 2~3 時間程度で実装できました。これまでは、シナリオは人手、会話例も人手、会話例に Dialog Act をつけるのも人手、シミュレーターはゼロから構築、など数日からへたすると数週間はかかる印象でしたが、生成 AI により大幅な時間短縮ができました。また、Phase 1 で具体的なシナリオと期待値を定義することで「こういう対話ならこの程度の満足度」という共通理解が得られ後の意思決定をスムーズにできました。
過去自然言語処理の研究で手間がかかるから難しいとされていた評価方法が生成 AI により現実的な時間で終わるようになり、「温故知新」の進め方といえます。
終わりに
AI エージェントを作る敷居は下がっていますが、役立てる敷居は必ずしも下がっていません。誰にどんな体験を届けるか、それをどのように計測するかを決めるには、積み重ねられた自然言語処理の研究を参照することが効果的です。具体的には、AI エージェントの類型を決めることで評価観点が明らかになり、評価観点から具体的なシナリオ・会話例で検討とシミュレーションを行い実効性のある検討・開発を進めることができました。
AI エージェント開発を始める際は、ぜひ「作る前から始める評価」を試してみて頂ければ幸いです!
Reference
過去の対話研究についてよくまとめられたサーベイです!
- Deriu, J., Rodrigo, A., Otegi, A. et al. Survey on evaluation methods for dialogue systems. Artif Intell Rev 54, 755–810 (2021).