Microsoftでは、2015/5/1からProject Oxfordと呼ばれるプロジェクトの一環で、機械学習系のAPIをリリースしました。
MicrosoftのProject Oxfordから、顔、画像、音声認識APIが利用可能に
今回は、この中から音声合成・音声認識を行うSpeech APIを取り上げます。
というのも、音声合成を行ってくれるサービスは結構あるのですが、音声認識となるとAPI的に使えるものは結構限られていたりするためです。大抵はAndroid/iOSのSDKで、Webで使えるといってもブラウザ依存だったりします。
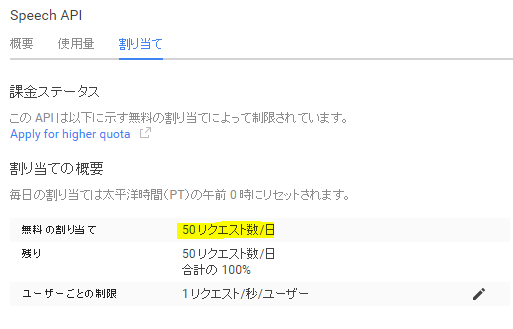
GoogleにもSpeech APIがあるのですが、なにせ公式ドキュメントがほとんど見当たらないうえ、一日50回の制限はかなり厳しいです(2015/7現在。課金すれば増えるというものでもない模様)。
Project Oxfordは、2015/7現在はPublic Betaで、今のところは無料で特に制限なく使うことができます(日本語にも対応)。
音声合成以外にも顔認識などのAPIがあるので、こちらで試してみて下さい。
環境準備
最初にSpeech APIを使うための環境を準備します。利用にあたってはMicrosoft Azureアカウントが必要なので、登録します。
1ヶ月間、という記述がありますがそもそも今回使うSpeech APIは無料なので、1ヶ月を過ぎてもたぶん大丈夫・・・だと思います。
アカウントが作成できたらポータルにアクセスします。
Speech APIはMarketplace経由での購入となっているようなので、左下の「新規」のボタンを押し、Marketplaceを選択します。
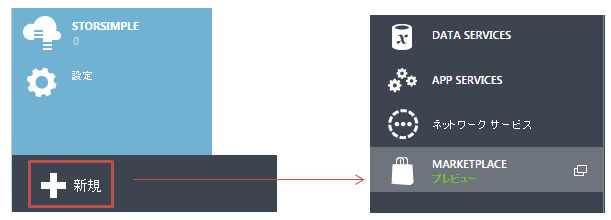
ここから、Speech APIを選択します。Face API等も見えるので、Project OxfordのAPIは同じ手法で購入できると思います(※現在はFREE)。

購入後、下の「管理」のボタンを押すことでAPIのアクセスに必要なキーを参照することができます。
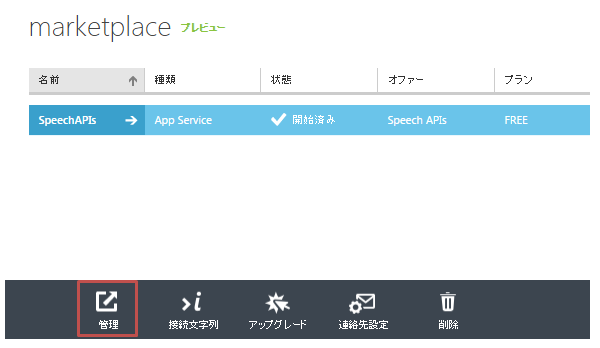
ここまで来たら、環境準備は完了です。
APIの利用
APIは、当然他の音声認識同様SDKも存在するのですが、Web API形式でも使うことができます。以下から、自分の環境/用途に合ったSDKをダウンロードできます。
Software Development Kit (SDK)
公式ドキュメントは以下になります。
今回は、Web API形式での利用、サンプルコードについてはPython3で記載します(が、HTTPが飛ばせる言語であればJavaScript/Ruby/PHP/Javaなど何でも構いません)。なお、PythonでのHTTP Requestは、標準は結構つらいのでrequestsを使います。
なんだかめんどいからさっさと使いたい!という方は以下に簡単なライブラリを作ったので、こちらで試してみてください。
認証
まず、先ほどの環境準備で取得したAPIアクセスに必要なキーを使い、認証を行います。
キーは2つありますが、primaryがclient_id、secondaryがclient_secret(secret token)になります。以下は、認証を行うサンプルコードです(上記のリポジトリから少し変更し抜粋)。
def authorize(self, client_id, client_secret):
url = "https://oxford-speech.cloudapp.net//token/issueToken"
headers = {
"Content-type": "application/x-www-form-urlencoded"
}
params = urllib.parse.urlencode(
{"grant_type": "client_credentials",
"client_id": client_id,
"client_secret": client_secret,
"scope": "https://speech.platform.bing.com"}
)
response = requests.post(url, data=params, headers=headers)
if response.ok:
_body = response.json()
return _body["access_token"]
else:
response.raise_for_status()
ここで得られた認証トークン(_body["access_token"])を、今後の合成/認識の際に使っていきます。
音声合成
では、音声合成を行ってみます。下記で、引数のtextが音声合成すべき文字列、tokenが先ほど取得した認証トークンです。
def text_to_speech(self, text, token, lang="en-US", female=True):
template = """
<speak version='1.0' xml:lang='{0}'>
<voice xml:lang='{0}' xml:gender='{1}' name='{2}'>
{3}
</voice>
</speak>
"""
url = "https://speech.platform.bing.com/synthesize"
headers = {
"Content-type": "application/ssml+xml",
"X-Microsoft-OutputFormat": "riff-16khz-16bit-mono-pcm",
"Authorization": "Bearer " + token,
"X-Search-AppId": "07D3234E49CE426DAA29772419F436CA",
"X-Search-ClientID": "1ECFAE91408841A480F00935DC390960",
"User-Agent": "OXFORD_TEST"
}
name = "Microsoft Server Speech Text to Speech Voice (en-US, ZiraRUS)"
data = template.format(lang, "Female" if female else "Male", name, text)
response = requests.post(url, data=data, headers=headers)
if response.ok:
return response.content
else:
raise response.raise_for_status()
上記のtemplateにあるとおり、リクエストはSSMLと呼ばれる音声のためのXMLフォーマットで送ります。これについては、docomoのサイトが詳しいです。なお、合成可能な音声は15秒がリミットです。
結果はバイナリ形式で返ってくるので、これを音声ファイル(.wavなど)として保存すれば合成された音声が聞けます。
他、細かいパラメーターについては以下の通りです。
- X-Search-AppId、X-Search-ClientID
- ハイフンなしのGUIDになります(
07D3234E49CE426DAA29772419F436CAとか)。おそらくモバイル用で、AppIDはアプリケーションのID、ClientIDはクライアント(インストールごと)のIDになるようです。HTTPで使うときは双方適当なGUIDで構いません。 - name
- voice fontと呼ばれる声の種別?で、人の名前のようなものを指定します。ドキュメントのSupportedLocalesVoiceFontsに、使用可能なものの一覧が掲載されています。
音声認識
次に、音声認識を行ってみます。先ほど音声合成した内容(binary)をそのまま使って、認識させてみます。
認識しながら連続的にテキストにするという使い方も想定しているようで、一回10秒、トータル?(requestid単位?)14秒がリミットのようです。
def speech_to_text(self, binary, token, lang="en-US", samplerate=8000, scenarios="ulm"):
data = binary
params = {
"version": "3.0",
"appID": "D4D52672-91D7-4C74-8AD8-42B1D98141A5",
"instanceid": "1ECFAE91408841A480F00935DC390960",
"requestid": "b2c95ede-97eb-4c88-81e4-80f32d6aee54",
"format": "json",
"locale": lang,
"device.os": "Windows7",
"scenarios": scenarios,
}
url = "https://speech.platform.bing.com/recognize/query?" + urllib.parse.urlencode(params)
headers = {"Content-type": "audio/wav; samplerate={0}".format(samplerate),
"Authorization": "Bearer " + token,
"X-Search-AppId": "07D3234E49CE426DAA29772419F436CA",
"X-Search-ClientID": "1ECFAE91408841A480F00935DC390960",
"User-Agent": "OXFORD_TEST"}
response = requests.post(url, data=data, headers=headers)
if response.ok:
result = response.json()["results"][0]
return result["lexical"]
else:
raise response.raise_for_status()
こちらはクエリパラメーターでファイルについての情報、bodyでファイル本体というGET/POST双方を合わせたかのような若干アクロバティック感のあるリクエストで送ります。
- appID
- "D4D52672-91D7-4C74-8AD8-42B1D98141A5"で固定の模様
- instanceid
- デバイス固有のID。X-Search-ClientIDと同じ意味?
- requestid
- requestごとに単一の値
- device.os
- Windows7など、デバイスのOS種別。適当で可。
- scenarios
- ulmかwebsearchの二択。デフォルトはulmだが、これが何の略なのかは謎。
- sourcerate
- 音声ファイルのサンプリングレート。8000か16000で、8000がデフォルト。この値に確信がある場合は(ちゃんと録音しているなど)、trustsourcerate=trueにすると厳密な設定とみなされる模様
また、オプションとして以下も指定できます。
- maxnbest
- 認識した候補を何個返すか。デフォルトは3
- result.profanitymarkup
- 認識した結果が良い子には聞かせられない言葉になる可能性もあるので、そうした場合1に設定しておくとこうした単語を削除してくれます(デフォルトは1、つまり有効)。
返り値は、認識できた文字列を確率が高い順にいくつか返してくれます。これはresultsの中に配列として入っており、lexicalが文字列、confidenceが確度になります。
解説は以上になります。手軽に音声合成/認識ができますので、ぜひ試してみてください。