GeForce(GTX1070Ti)のパワーを体感するためにCNNの訓練速度を比較してみた。
CPUは Core i7 で12コアでメモリが32GBのマシン。
そのマシンにGTX1070Ti(メモリ8GB)を積んでいる。
検証に利用するモデルをダウンロード
$ git clone https://github.com/tensorflow/models.git
最初に画像データ(160MB)のダウンロードをするために、一度スクリプトを実行し、ダウンロードが終わったら一度止める。
$ python3 tutorials/image/cifar10/cifar10_train.py
>> Downloading cifar-10-binary.tar.gz 100.0%
Successfully downloaded cifar-10-binary.tar.gz 170052171 bytes.
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
2018-05-19 12:21:51.508117: step 0, loss = 4.67 (1335.2 examples/sec; 0.096 sec/batch)
あと、ステップ数がもともと100万回だったりするので時間がかかりすぎるので、ちょっと少なくしておく。今回は精度を目的にしていないので。
diff --git a/tutorials/image/cifar10/cifar10_train.py b/tutorials/image/cifar10/cifar10_train.py
index b9e21df..853bd83 100644
--- a/tutorials/image/cifar10/cifar10_train.py
+++ b/tutorials/image/cifar10/cifar10_train.py
@@ -45,10 +45,10 @@
FLAGS = tf.app.flags.FLAGS
-tf.app.flags.DEFINE_string('train_dir', '/tmp/cifar10_train',
+tf.app.flags.DEFINE_string('train_dir', './tmp/cifar10_train',
"""Directory where to write event logs """
"""and checkpoint.""")
-tf.app.flags.DEFINE_integer('max_steps', 1000000,
+tf.app.flags.DEFINE_integer('max_steps', 10000,
"""Number of batches to run.""")
tf.app.flags.DEFINE_boolean('log_device_placement', False,
"""Whether to log device placement.""")
diff --git a/tutorials/image/cifar10/cifar10.py b/tutorials/image/cifar10/cifar10.py
index 018e2f2..0107610 100644
--- a/tutorials/image/cifar10/cifar10.py
+++ b/tutorials/image/cifar10/cifar10.py
@@ -50,7 +50,7 @@
# Basic model parameters.
tf.app.flags.DEFINE_integer('batch_size', 128,
"""Number of images to process in a batch.""")
-tf.app.flags.DEFINE_string('data_dir', '/tmp/cifar10_data',
+tf.app.flags.DEFINE_string('data_dir', './tmp/cifar10_data',
"""Path to the CIFAR-10 data directory.""")
tf.app.flags.DEFINE_boolean('use_fp16', False,
"""Train the model using fp16.""")
まずは、GPUを利用しない設定の Tensorflow で訓練をしてみる。
$ time python3 tutorials/image/cifar10/cifar10_train.py
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
2018-05-19 12:51:35.212672: step 0, loss = 4.67 (1304.8 examples/sec; 0.098 sec/batch)
2018-05-19 12:51:36.726462: step 10, loss = 4.63 (845.6 examples/sec; 0.151 sec/batch)
2018-05-19 12:51:38.231417: step 20, loss = 4.43 (850.5 examples/sec; 0.150 sec/batch)
2018-05-19 12:51:39.678864: step 30, loss = 4.46 (884.3 examples/sec; 0.145 sec/batch)
...
...
...
本当にGPUはまったく利用していないみたい。
CPUだけで頑張っている。
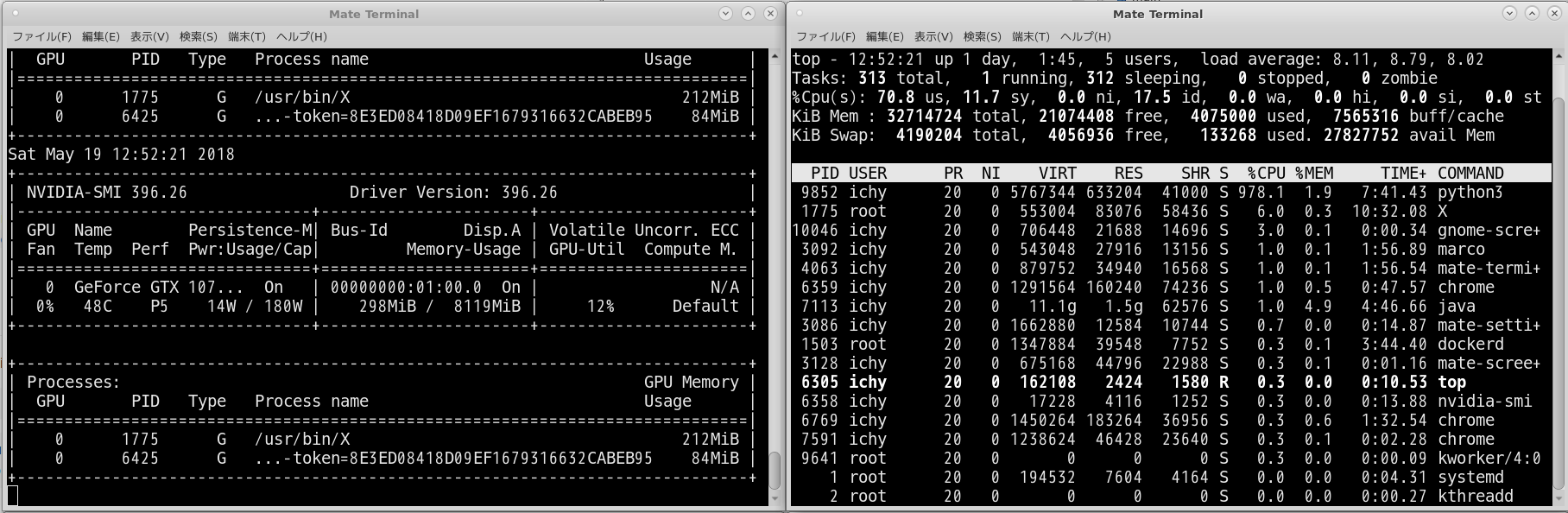
この状態で終了するまでひたすら待機。
2018-05-19 13:14:33.477680: step 9960, loss = 0.97 (946.5 examples/sec; 0.135 sec/batch)
2018-05-19 13:14:34.826108: step 9970, loss = 0.97 (949.3 examples/sec; 0.135 sec/batch)
2018-05-19 13:14:36.168713: step 9980, loss = 0.83 (953.4 examples/sec; 0.134 sec/batch)
2018-05-19 13:14:37.537877: step 9990, loss = 0.89 (934.9 examples/sec; 0.137 sec/batch)
real 23m5.563s
user 194m40.870s
sys 29m54.059s
終わった。約30分。
では、GPUを利用する設定の Tensorflow でもう一度。
$ time python3 tutorials/image/cifar10/cifar10_train.py
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
2018-05-19 14:38:38.953239: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:898] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2018-05-19 14:38:38.953629: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1356] Found device 0 with properties:
name: GeForce GTX 1070 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.683
pciBusID: 0000:01:00.0
totalMemory: 7.93GiB freeMemory: 7.50GiB
2018-05-19 14:38:38.953654: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-05-19 14:38:39.118864: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-05-19 14:38:39.118893: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-05-19 14:38:39.118902: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-05-19 14:38:39.119026: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 7244 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1070 Ti, pci bus id: 0000:01:00.0, compute capability: 6.1)
2018-05-19 14:38:40.517776: step 0, loss = 4.68 (751.4 examples/sec; 0.170 sec/batch)
2018-05-19 14:38:40.709342: step 10, loss = 4.61 (6681.7 examples/sec; 0.019 sec/batch)
2018-05-19 14:38:40.828196: step 20, loss = 4.54 (10769.4 examples/sec; 0.012 sec/batch)
2018-05-19 14:38:40.944359: step 30, loss = 4.37 (11019.1 examples/sec; 0.012 sec/batch)
python3 がGPUを使っているのが見て取れます。
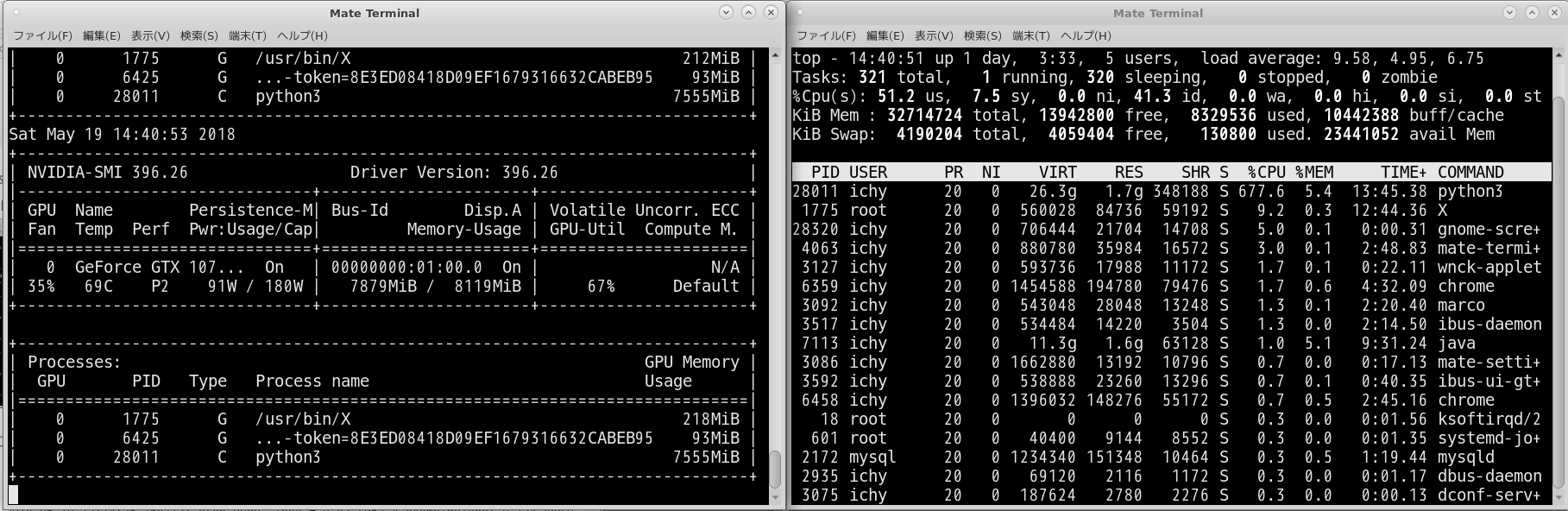
2018-05-19 14:41:12.962790: step 9960, loss = 0.81 (9595.2 examples/sec; 0.013 sec/batch)
2018-05-19 14:41:13.096004: step 9970, loss = 0.85 (9608.7 examples/sec; 0.013 sec/batch)
2018-05-19 14:41:13.229903: step 9980, loss = 0.93 (9559.4 examples/sec; 0.013 sec/batch)
2018-05-19 14:41:13.365088: step 9990, loss = 0.84 (9468.6 examples/sec; 0.014 sec/batch)
real 2m35.842s
user 14m3.309s
sys 2m4.000s
終わった。3分かからず。速いかもしれない。