PPT内のテキストコンテンツを直接抽出することは、それをさらに処理や分析することを容易にし、また抽出したコンテンツを他のドキュメントの編集に直接使用することができます。Pythonプログラムを使用することで、PowerPointプレゼンテーション内のテキストコンテンツを効率的に抽出することができます。本記事では、スライドのテキスト、スピーカーノート、コメントなど、PowerPointプレゼンテーション内のテキストコンテンツを抽出する方法をPythonプログラムを使って探求します。
- Pythonを使ったプレゼンテーションスライドからテキストを抽出する方法
- Pythonを使ったスピーカーノートからテキストを抽出する方法
- Pythonを使ったプレゼンテーションコメントからテキストを抽出する方法
この記事で使用される方法には、Spire.Presentation for Pythonが必要です。公式ウェブサイトからダウンロードするか、PyPIを通じてインストールできます:pip install Spire.Presentation。
Pythonを使ったプレゼンテーションスライドからテキストを抽出する方法
PowerPointプレゼンテーションスライド内のテキストは、形状内に配置されています。そのため、プレゼンテーション内の各スライドのすべての形状にアクセスし、それらに含まれるテキストを抽出することで、テキストを抽出することができます。詳細な手順は以下の通りです:
- Presentation クラスのオブジェクトを作成し、Presentation.LoadFromFile() メソッドを使用してPowerPointプレゼンテーションをロードします。
- プレゼンテーション内のスライドを反復処理し、各スライド内の形状を反復処理します。
- 形状が IAutoShape のインスタンスであるかどうかを確認します。もし IAutoShape であれば、IAutoShape.TextFrame.Paragraphs プロパティを使用して形状内の段落を取得し、Paragraph.Text プロパティを使用して段落内のテキストを取得します。
- スライドのテキストをテキストファイルに書き込みます。
コード例
from spire.presentation import *
from spire.presentation.common import *
# Presentationクラスのオブジェクトを作成
pres = Presentation()
# PowerPointプレゼンテーションをロードする
pres.LoadFromFile("サンプル.pptx")
text = []
# 各スライドをループする
for slide in pres.Slides:
# 各シェイプをループする
for shape in slide.Shapes:
# シェイプがIAutoShapeのインスタンスであるかをチェックする
if isinstance(shape, IAutoShape):
# シェイプからテキストを抽出する
for paragraph in (shape if isinstance(shape, IAutoShape) else None).TextFrame.Paragraphs:
text.append(paragraph.Text)
# テキストをテキストファイルに書き込む
f = open("output/スライドのテキスト.txt", "w", encoding='utf-8')
for s in text:
f.write(s + "\n")
f.close()
pres.Dispose()
抽出の結果

Pythonを使ったスピーカーノートからテキストを抽出する方法
講演者ノートはプレゼンターにガイダンスやヒントを提供するための追加情報であり、観客には表示されません。スライドのノートは NotesSlide オブジェクトに保存されており、ISlide.NotesSlide プロパティを使用して取得することができます。NotesSlide オブジェクトを取得した後は、NotesSlide.NotesTextFrame.Text プロパティを使用してテキストを抽出することができます。ノート内のテキストを抽出するための詳細な手順は以下の通りです:
- Presentation クラスのオブジェクトを作成し、Presentation.LoadFromFile() メソッドを使用してPowerPointプレゼンテーションをロードします。
- 各スライドを反復処理します。
- ISlide.NotesSlide プロパティを使用してノートスライドを取得し、NotesSlide.NotesTextFrame.Text プロパティを通じてテキストを取得します。
- ノートのテキストをテキストファイルに書き込みます。
コード例
from spire.presentation import *
from spire.presentation.common import *
# Presentationクラスのオブジェクトを作成します
pres = Presentation()
# PowerPointプレゼンテーションをロードします
pres.LoadFromFile("サンプル.pptx")
notes_list = []
# 各スライドを反復処理します
for slide in pres.Slides:
# ノートスライドを取得します
notes_slide = slide.NotesSlide
# ノートを取得します
notes = notes_slide.NotesTextFrame.Text
notes_list.append(notes)
# ノートをテキストファイルに書き込みます
f = open("output/ノートのテキスト.txt", "w", encoding="utf-8")
for note in notes_list:
f.write(note)
f.write("\n")
f.close()
pres.Dispose()
抽出の結果

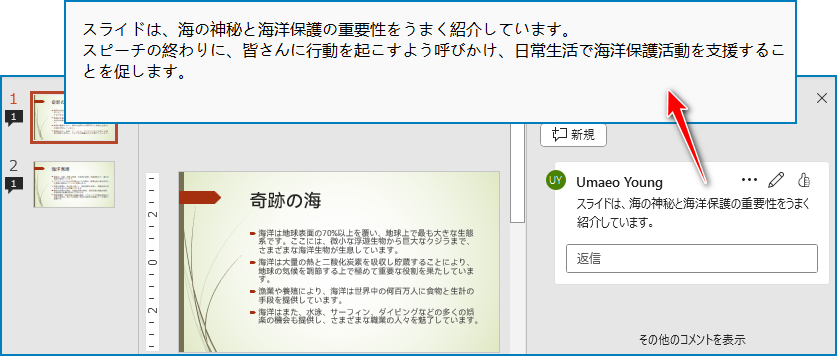
Pythonを使ったプレゼンテーションコメントからテキストを抽出する方法
PowerPointプレゼンテーション内のコメントからもテキストを抽出することができます。ISlide.Comments プロパティを使用してスライドからコメントを取得し、Comment.Text プロパティを通じてコメントからテキストを取得します。詳細な手順は以下の通りです:
- Presentation クラスのオブジェクトを作成し、Presentation.LoadFromFile() メソッドを使用してPowerPointプレゼンテーションをロードします。
- 各スライドを反復処理し、ISlide.Comments プロパティを使用して各スライドからコメントを取得します。
- 各コメントを反復処理し、Comment.Text プロパティを使用して各コメントからテキストを取得します。
- コメントのテキストをテキストファイルに書き込みます。
コード例
from spire.presentation import *
from spire.presentation.common import *
# Presentationクラスのオブジェクトを作成します
pres = Presentation()
# PowerPointプレゼンテーションをロードします
pres.LoadFromFile("サンプル.pptx")
comments_list = []
# すべてのスライドを反復処理します
for slide in pres.Slides:
# スライドからすべてのコメントを取得します
comments = slide.Comments
# コメントを反復処理します
for comment in comments:
# コメントのテキストを取得します
comment_text = comment.Text
comments_list.append(comment_text)
# コメントをテキストファイルに書き込みます
f = open("output/コメントのテキスト.txt", "w", encoding="utf-8")
for comment in comments_list:
f.write(comment + "\n")
f.close()
pres.Dispose()
抽出の結果
結論
この記事では、Pythonプログラムを使用してPowerPointプレゼンテーションファイルからテキストを抽出する方法、スライド、スピーカーノート、コメントからテキストを抽出する方法について説明しました。このAPIは他の多くのプレゼンテーションファイル処理機能もサポートしており、詳細な情報についてはSpire.Presentation for Pythonチュートリアルをご覧ください。
もしAPIの使用中に問題が発生した場合は、Spire.Presentationフォーラムにアクセスして技術サポートを受けることができます。