PDFファイルは、文書アーカイブや資料配布など、さまざまな用途で広く使われています。その中に含まれる画像は、イラスト、アイコン、印影、透かしなど、重要な情報を含んでいることが少なくありません。
Java開発者にとって、PDF内の画像を正確に抽出することは、文書処理システムや画像認識サービスの実装において非常に重要です。
本記事では、JavaでPDFファイルからすべての画像を抽出する方法をご紹介し、実用的なシナリオに基づいて以下のテクニックも解説します。
- JavaでPDFからすべての画像を抽出する方法
- 背景画像をスキップする方法
- サイズで有効な画像をフィルタリングする方法
- PNG/JPG/BMP形式で画像を保存する方法
本記事は Free Spire.PDF for Java を使用しています。インストール方法は公式の ダウンロードページ をご参照ください。
JavaでPDFからすべての画像を抽出する
Spire.PDFは、あるページに含まれるすべての画像情報を取得できる PdfImageHelper.getImagesInfo() メソッドを提供しています。画像は getImage() を使って BufferedImage として取得可能です。
処理の流れ:
- PDFドキュメントを読み込む
- 各ページをループし、画像情報を取得
- 各画像をファイルとして保存
- リソースを解放し文書を閉じる
サンプルコード:
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ExtractAllImagePDF {
public static void main(String[] args) throws IOException {
// PDFドキュメントをロード
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("input.pdf");
// 画像抽出ヘルパー
PdfImageHelper imageHelper = new PdfImageHelper();
// 各ページを処理
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfPageBase page = pdf.getPages().get(i);
PdfImageInfo[] imagesInfo = imageHelper.getImagesInfo(page);
// 各画像を保存
for (int j = 0; j < imagesInfo.length; j++) {
BufferedImage image = imagesInfo[j].getImage();
File file = new File("output/Page" + i + "_Image" + j + ".png");
ImageIO.write(image, "png", file);
}
}
pdf.close();
}
}
出力結果のイメージ:
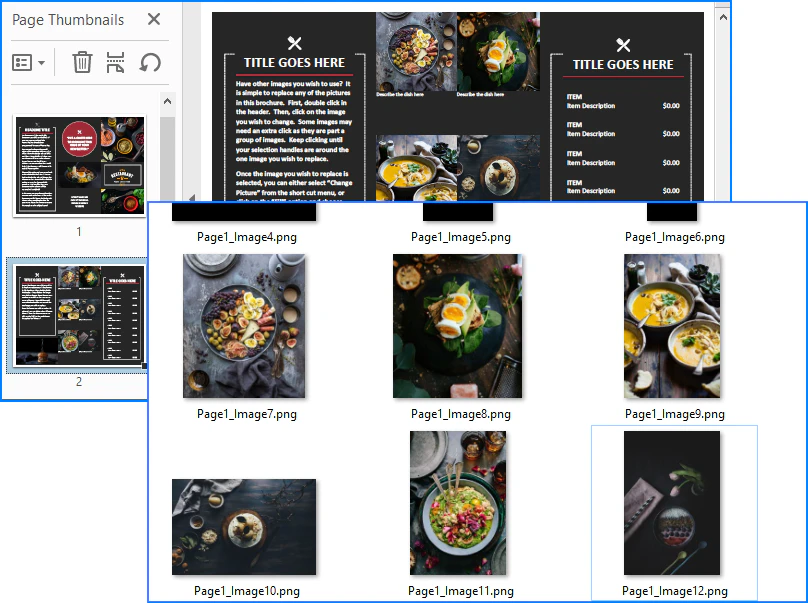
背景画像をスキップする
PDFのページには、背景として使用されている画像が最初に含まれていることがよくあります。
必要な画像(挿絵、印影など)のみを抽出したい場合は、最初の画像をスキップすることで効率的に処理できます。
背景画像をスキップするコードの変更点:
// 最初の画像(背景)をスキップして2番目から処理
for (int j = 1; j < imagesInfo.length; j++) {
BufferedImage image = imagesInfo[j].getImage();
ImageIO.write(image, "png", new File("output/Page" + i + "_Image" + j + ".png"));
}
サイズで有効な画像をフィルタリングする
PDFに含まれる画像の中には、1x1の透明ピクセルやノイズのような不要な画像が含まれていることもあります。
画像のサイズを条件にすることで、無効な画像をフィルタリング可能です。
サイズによるフィルタリングの追加コード:
for (int j = 0; j < imagesInfo.length; j++) {
BufferedImage image = imagesInfo[j].getImage();
// 例えば、幅または高さが50pxより大きい画像のみを保存
if (image.getWidth() > 50 && image.getHeight() > 50) {
File file = new File("output/Page" + i + "_Image" + j + ".png");
ImageIO.write(image, "png", file);
}
}
この処理により、不要な小さな画像を除外し、精度とパフォーマンスを向上させることができます。
PNG/JPG/BMP形式で画像を保存する
抽出された BufferedImage は、さまざまな画像形式で保存可能です。
用途に応じて、PNG(高画質)、JPEG(圧縮)、BMP(非圧縮)などを使い分けましょう。
形式別保存の例:
ImageIO.write(image, "PNG", new File("output/image_" + i + ".png")); // 推奨
ImageIO.write(image, "JPEG", new File("output/image_" + i + ".jpg")); // 圧縮
ImageIO.write(image, "BMP", new File("output/image_" + i + ".bmp")); // 高品質
メモリ上に書き出す場合:
ByteArrayOutputStream stream = new ByteArrayOutputStream();
ImageIO.write(image, "PNG", stream);
このようにして、画像をサーバーにアップロードしたり、別の文書に組み込む用途にも活用できます。
まとめ
本記事では、Javaを用いてPDFファイル内のすべての画像を抽出する基本的な方法を紹介し、さらに以下のような実践的なテクニックを解説しました:
- 背景画像のスキップ:無駄な背景画像の保存を防止
- サイズフィルタリング:無効な小さな画像を除外
- 多形式保存:ビジネスニーズに合わせた形式選択
これらのテクニックは、文書のデジタル化、請求書処理、画像認識などの多くの業務シナリオで応用可能です。
Spire.PDFの高い互換性と安定性により、複雑なPDF文書でも確実に対応できます。
さらに詳しい情報は公式ガイドをご参照ください:
👉 Spire.PDF for Java プログラミングガイド