初めに
こんにちは!
CYBIRD Advent Calendar 2025の13日目を担当します、インフラエンジニアの@ice_matcha3です。
12日目は@shiso_cさんの「Geminiと二人三脚でゲームを作ってみた話」でした。
背景
サイバードでは、クラウド基盤として主にAWSを採用しています。 現在、開発環境等の構築において Amazon ECS Fargate Spot を活用しており、役割ごとに以下の3つのサーバ群を稼働させています。
- Appサーバ(アプリケーション本体)
- Adminサーバ(管理画面用)
- Cronサーバ(バッチ処理用)
これまではSpotインスタンス特有の中断が発生しても遅くとも3分程度で再起動していたため、開発業務への影響は軽微でした。しかし、2025年1月以降、状況が一変します。アプリケーション開発者から「サーバが利用できない」という問い合わせが頻発するようになり、調査したところ SpotInterruption によるタスク中断が原因でした。
深刻だったのはそのダウンタイムです。以前は数分で復旧していたものが、10分以上待ってもサーバが立ち上がらない現象が多発し始め、開発効率を著しく下げる要因となってしまいました。
本記事では、この「Fargate Spotの再起動遅延問題」に私がどう立ち向かったかをご紹介します。
事前知識
Fargate と Fargate Spot の違い
AWS Fargate は、コンテナをサーバーレスで実行できるコンピュート基盤です。
その中でも、実行タイプとして Fargate と Fargate Spot の2種類が選択できます。
両者の特徴と違いをまとめると以下の通りです。
-
Fargate
- 通常のオンデマンド実行
- AWS がコンテナ基盤をフルマネージドで提供
- 安定した稼働を求めるサービスに向く
- 停止される可能性がなく、任意の長さで継続実行できる
- コストは高めだが予測可能
-
Fargate Spot
- スポットキャパシティを利用する低価格オプション
- 最大 70% 以上安くなる
- AWSによってタスクが停止される可能性がある
- 中断の2分前に “停止通知(SpotInterruption)” が来る
Fargateという解決策のジレンマ
まずは事態の収集を図るために、すべての構成をFargate SpotからオンデマンドのFargateに切り替えました。これにより再起動の問題は完全に解消されましたが、今度はコストという新たな壁にぶつかります。
もちろん、コスト対策としてSavings Plansの購入も検討しました。しかし、東京リージョン1年間のSavings Plansの割引率はFargateと比較して約22%程度です。対して Fargate Spot は最大約70%の割引が適用されます。 利益を直接生まない開発環境においては、この「圧倒的な安さ」は何物にも代えがたいメリットです。「安定性は欲しい、でもSpot並みの低コストも諦めたくない」。このトレードオフを解消する、次なる構成を模索する必要がありました。
イベント駆動型の自動切り替えアーキテクチャ
「Spotの安さ」を享受しつつ、「必要な時にはオンデマンドの安定性」を確保するため、私はAWSのサービス(EventBridge, Lambda, Step Functions等)を組み合わせた動的な切り替えシステムを構築しました。
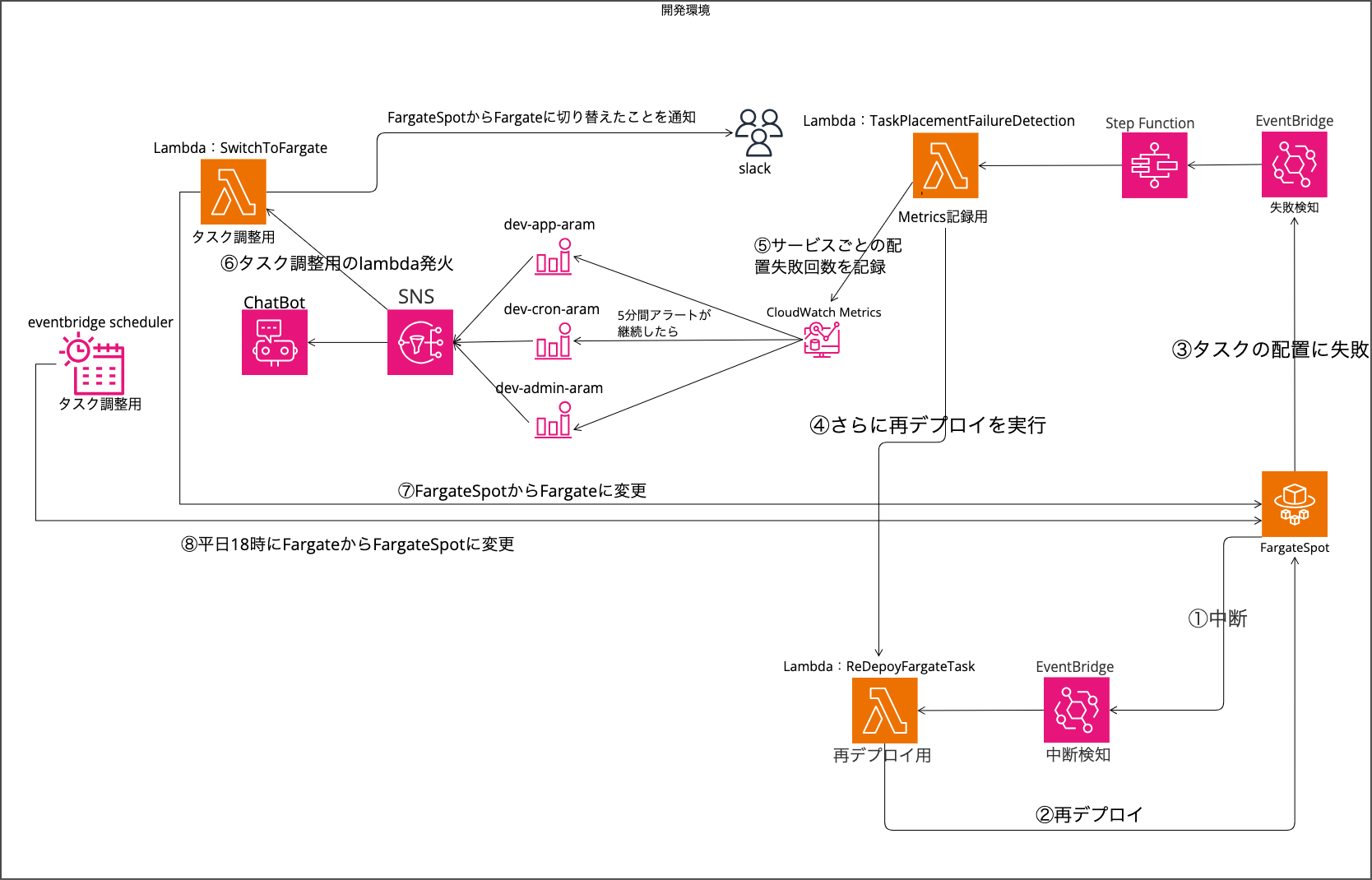
仕組みのポイント
このアーキテクチャの肝は、「Fargate Spotが枯渇して5分以内に起動できない時だけ、自動的にFargateへ切り替える」、そして「業務時間外には自動的にFargate Spotへ戻す」というサイクルを自動化した点にあります。
具体的な処理の流れは以下の通りです。
-
中断検知と再試行(図の①~②)
まず、AWS側からのSpotインスタンス中断通知(SpotInterruption)や、タスクの予期せぬ停止(TaskStateChange)を EventBridge で検知します。 これをトリガーとして、まずは即座に再デプロイ用のLambda/Step Functionsを実行します。AWS側の在庫不足が一時的なものであれば、この初動の再デプロイによってすぐに新しいFargate Spotタスクが割り当てられ、復旧が完了します。この段階で復旧できれば、コストへの影響はゼロです
-
5分間の猶予と再試行ループ(図の③~④)
ここが本構成におけるコスト最適化の重要なポイントです。 再デプロイを実行してもタスクが起動しない(配置に失敗する)場合、即座にFargateへ切り替えるのではなく、あえてFargate Spotでの再デプロイを繰り返す期間を設けています。-
Step Functionsによる再試行ループ
タスクの配置失敗イベントをトリガーにStep Functionsが起動します。フロー内で「メトリクス記録用Lambda」を経由し、再び「再デプロイ用Lambda」を実行することで、Fargate Spotへのタスク配置をリトライする仕組みです。 -
なぜ「5分間」待つのか?
Fargate Spotの在庫状況(キャパシティ)は刻一刻と変化しており、数分待機することで在庫が回復し、確保に成功するケースが多々あるためです。 また、社内の開発エンジニアと「開発環境であれば5分程度のダウンタイムは許容できる」という合意ができたため、この期間はコストメリットを優先してFargate Spotでの確保を試みる設計としました。
-
Step Functionsによる再試行ループ
-
タイムアウトとFargateへの切り替え(図の⑤~⑦)
「5分待ってもFargate Spotが確保できない」という状況は、深刻な在庫不足が発生している可能性が高く、これ以上待っても開発に影響がでると判断し、コストよりも可用性を優先するフローへ移行させます。-
アラーム発火とLambda起動(⑤~⑥)
CloudWatch Alarmsが「タスク配置失敗が5分間継続した」ことを検知すると、アラーム状態に移行します。これをトリガーにSNS経由で「タスク調整用Lambda」が発火します。 同時に、Chatbotを通じてSlackへ「Spot枯渇のため、オンデマンドへ切り替えます」という通知を飛ばし、開発者へ状況を共有します。 -
Capacity Providerの切り替え(⑦)
Lambdaは対象ECSサービスの Capacity Provider Strategy を更新します。 具体的には、ベースを FARGATE_SPOT からオンデマンドの FARGATE へと変更します。これにより、AWSの在庫状況に左右されず、確実にタスクが起動する状態となり、開発環境が復旧します。
-
-
AWSの需要傾向を見越した自動復帰(図の⑧)
オンデマンドへ切り替わった設定を戻すタイミングにも、運用上の知見を取り入れています。-
18時設定の根拠
AWSの需給バランス これまでの運用経験から、「Fargate Spotのキャパシティ不足(中断)は、多くの国内企業が活動する日中帯に集中しやすい」 という傾向が見えてきました。 逆に言えば、18時を過ぎると他社の利用が落ち着き、AWS側のリソース(在庫)に余裕が生まれる可能性が高くなります。 -
EventBridge Schedulerによる書き戻し
この「市場の需給バランス」が改善するタイミングを狙い、平日18時にタスク調整用Lambdaを実行します。 在庫が回復しやすいこの時間帯に設定を Fargate Spot へ戻すことで、夜間のバッチ処理や翌日の始業時には、再び低コストなFargate Spotで稼働できる確率を高めています。
-
18時設定の根拠
実装詳細
-
EventBridgeによるトリガー設定
自動復旧フローの起点となるのは、EventBridgeによるイベント検知です。 今回の構成では、「稼働中のタスクが中断された時」と「新しいタスクが起動できなかった時」の2パターンをトリガーとして設定しています。-
中断検知
AWS側からSpotインスタンスの回収通知(2分前の警告)が来た際に発生するイベントです。これを検知することで、タスクが強制停止される前に能動的に再デプロイフローを開始します。{ "source": ["aws.ecs"], "detail-type": ["ECS Task State Change"], "detail": { "stopCode": ["SpotInterruption"], "desiredStatus": ["STOPPED"], "lastStatus": ["RUNNING", "DEACTIVATING"] } }
-
失敗検知
こちらは「Fargate Spotの在庫切れ」により、そもそも新しいタスクを起動できなかったケースを検知する設定です。「Fargateのリソース不足(キャパシティ枯渇)」による失敗だけを拾いたいため、「"reason": ["RESOURCE:FARGATE"]」このフィルタリングを入れることで不要なLambdaの起動を防いでいます。{ "source": ["aws.ecs"], "detail-type": ["ECS Service Action"], "detail": { "eventName": ["SERVICE_TASK_PLACEMENT_FAILURE"], "reason": ["RESOURCE:FARGATE"] } }
-
中断検知
-
再デプロイ実行用Lambda:ReDeployFargateTask
検知イベントやStep Functionsから呼び出され、実際にECSサービスに対して再デプロイを命令するLambdaで、ランタイムにNode.js 22.xを使用しています。この再デプロイ用Lambdaは、要件上、「EventBridgeから単発で起動される場合」と「Step Functionsからループの一部として起動される場合」という2つの異なる経路から呼び出されます。
入力ソースが異なればイベントペイロードの構造も微妙に異なるため、どちらの状況でもサービスを特定して再デプロイできるよう、サービス名の取得を2パターン作成しています。
const { ECSClient, DescribeTasksCommand, UpdateServiceCommand } = require('@aws-sdk/client-ecs'); // リージョンは環境に合わせて変更してください const ecs = new ECSClient({ region: 'ap-northeast-1' }); exports.handler = async (event) => { try { console.log('Received event:', JSON.stringify(event, null, 2)); // EventBridgeのdetailから情報を取得 if (event && event.detail) { const taskArn = event.detail['taskArn'] || null; let serviceArn = event.detail['serviceArn'] || null; const clusterArn = event.detail['clusterArn']; console.log(`Fargate Spot task interruption detected: Task ARN: ${taskArn} : Cluster ARN: ${clusterArn}`); // イベントにserviceArnが含まれていない場合の救済処置 try { if (serviceArn == null) { // タスク情報からサービス名を逆引きする serviceArn = await getServicesInCluster(taskArn, clusterArn); } if (serviceArn) { console.log('Retrieved service:', serviceArn); // サービスの再デプロイを実行 await redeployService(serviceArn, clusterArn); console.log(`Service ${serviceArn} redeployed successfully.`); } else { console.log('Service ARN could not be retrieved.'); } } catch (error) { console.error('Error retrieving service for task:', error); } } else { console.error('No detail field found in the event.'); } } catch (error) { console.error('Error handling Spot interruption:', error); throw error; } }; // タスクARNからサービス名を逆引きする関数 async function getServicesInCluster(taskArn, clusterArn) { const params = { cluster: clusterArn, tasks: [taskArn], }; try { // ECSのDescribeTasksCommandを使用してタスク詳細を取得 const command = new DescribeTasksCommand(params); const data = await ecs.send(command); const task = data.tasks[0]; // task.group (例: "service:my-service-name") からサービス名を抽出 if (task && task.group) { const serviceArn = task.group.split(":")[1]; return serviceArn; } else { console.error('Service not found for task:', taskArn); return null; } } catch (error) { console.error('Error describing tasks:', error); throw error; } } // 強制デプロイを実行する関数 async function redeployService(serviceArn, clusterArn) { const params = { cluster: clusterArn, service: serviceArn, forceNewDeployment: true, // 新しいタスク配置を強制する }; try { // ECSサービスを更新 const command = new UpdateServiceCommand(params); const data = await ecs.send(command); console.log('Service updated:', data); return data; } catch (error) { console.error('Error updating service:', error); throw error; } }
-
メトリクス記録用Lambda:TaskPlacementFailureDetection
Step Functionsのワークフロー内で呼び出され、発生したエラーをカスタムメトリクスとしてCloudWatchへ送信するLambdaで、ランタイムにNode.js 22.xを使用しています。ここで記録されたデータポイントが、後述する「5分間のタイムアウト判定(CloudWatch Alarm)」の判断材料となります。エラー発生時に TaskPlacementFailureCount 独自のメトリクスに 1 を送信することで「CloudWatchメトリクスとして数値化」することができ、CloudWatch Alarmで「5分間でエラーが継続しているか」を監視できるようになります。
また、このLambdaはStep Functionsのフローの途中に位置しているため、処理の最後で return { detail: { ... } } のように次のステートに必要な情報(サービス名やクラスタARN)を含めて返すことで、後続の「再デプロイ用Lambda」がスムーズに処理を実行できるよう設計しています。
const { CloudWatchClient, PutMetricDataCommand, GetMetricDataCommand } = require('@aws-sdk/client-cloudwatch'); // リージョンは環境に合わせて変更してください const cloudwatch = new CloudWatchClient({ region: 'ap-northeast-1' }); exports.handler = async (event) => { console.log('Received event:', JSON.stringify(event, null, 2)); if (event && event.detail) { const serviceArn = event.resources[0]; const clusterArn = event.detail.clusterArn; const detectionTime = event['time']; // ARNからリソース名を抽出 const serviceName = serviceArn.split('/').pop(); const clusterName = clusterArn.split('/').pop(); try { // 1. CloudWatchカスタムメトリクスの送信 // Namespace: 'TaskPlacementFailureCount' に '1' をカウントアップ const countParams = { Namespace: 'TaskPlacementFailureCount', MetricData: [ { MetricName: 'TaskPlacementFailureCount', Dimensions: [ { Name: 'ServiceName', Value: serviceName }, ], Timestamp: new Date(detectionTime), Unit: 'Count', Value: 1 }, ], }; await cloudwatch.send(new PutMetricDataCommand(countParams)); // 2. 直近のメトリクス状況を確認(ログ出力用) // ※ここで過去10分間の発生状況を取得し、ログに残すことでデバッグを容易にしています const now = new Date(); const startTime = new Date(now.getTime() - 10 * 60 * 1000); const params = { StartTime: startTime, EndTime: now, MetricDataQueries: [{ Id: 'recentTrigger', MetricStat: { Metric: { Namespace: 'TaskPlacementFailureCount', MetricName: 'TaskPlacementFailureCount', Dimensions: [{ Name: 'ServiceName', Value: serviceName }] }, Period: 60, Stat: 'Sum' }, ReturnData: true }], ScanBy: 'TimestampDescending' }; const result = await cloudwatch.send(new GetMetricDataCommand(params)); console.log(`Current Failure Metrics:`, JSON.stringify(result)); // 3. 次のステップ(再デプロイLambda)へ情報を渡す return { statusCode: 200, body: JSON.stringify('Processing complete'), detail: { serviceArn: serviceName, // 再デプロイ用にサービス名を渡す clusterArn: clusterArn, time: detectionTime } }; } catch (error) { console.error('Failed to process metrics:', error); // Step FunctionsのRetry機能に任せるためエラーをスロー throw error; } } else { console.error('No detail field found in the event.'); return { statusCode: 400, body: JSON.stringify('Invalid event structure') }; } };
-
Step Functionsによる実行フロー
EventBridgeが検知したイベントを受け取り、実際に処理を行うワークフロー定義です。 構成は非常にシンプルで、まずメトリクスを記録するLambdaを実行させ、その結果をもって再デプロイ用Lambdaを実行する流れになっています。アカウントID等は自身の環境に合わせて変更が必要です。} "Comment": "From TaskPlacementFailureDetection To ReDeployFargateTask", "StartAt": "TaskPlacementFailureDetection", "States": { "TaskPlacementFailureDetection": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:123456789012:function:TaskPlacementFailureDetection", "ResultPath": "$.detail", "Next": "ReDeployFargateTask" }, "ReDeployFargateTask": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:123456789012:function:ReDeployFargateTask", "InputPath": "$.detail", "End": true } }, "TimeoutSeconds": 500 }
-
CloudWatch Alarmの設定(5分間のタイムアウト判定)
前述のLambdaによって記録されたカスタムメトリクスを監視し、「再デプロイの失敗が5分間継続したこと」を検知するためのアラーム設定です。 このアラームが「ALARM状態」に遷移することで、後続のSNSトピックが発火し、オンデマンドへの切り替え処理が実行されます。これを運用している各サービス分作成します。設定項目 設定値 補足 メトリクス名 TaskPlacementFailureCount Lambdaで送信したカスタムメトリクス 名前空間 TaskPlacementFailureCount ディメンション ServiceName サービスごとに監視するため指定 統計 合計 (Sum) 1分間に発生した失敗回数を合計 期間 (Period) 1 分 しきい値 1 以上 1回でも失敗があればカウント アラームを実行するデータポイント 5 / 5 ここで5分判定している 欠落データの処理 適正 (not breaching) として処理 エラーがない時は正常とみなす
-
タスク調整用Lambda:SwitchToFargate
CloudWatch Alarmからの通知(SNS)をトリガーに実行されるLambdaで、ランタイムにNode.js 22.xを使用しています。
対象のECSサービスを特定し、Capacity Provider Strategy を更新してFargateへと切り替えます。
※本コードでは、サービス更新後のSlack通知処理は省略し、「オンデマンドへの切り替え」に関する主要部分のみを掲載しています。import { ECSClient, ListClustersCommand, DescribeServicesCommand, UpdateServiceCommand, DescribeTasksCommand, ListTasksCommand } from '@aws-sdk/client-ecs'; // import https from 'https'; // Slack通知用ライブラリ(本記事では通知処理を省略するためコメントアウト) const ecsClient = new ECSClient(); export const handler = async (event) => { console.log(`event: ${JSON.stringify(event)}`); for (const record of event.Records) { const snsMessage = JSON.parse(record.Sns.Message); const dimensions = snsMessage.Trigger?.Dimensions || []; const serviceDimension = dimensions.find(d => d.name === "ServiceName"); const serviceName = serviceDimension?.value; console.log(`サービス名: ${serviceName}`); let clusterArn; try { clusterArn = await findClusterByService(serviceName); console.log(`クラスター名: ${clusterArn}`); } catch (err) { console.error(`クラスター取得エラー: ${err.message}`); continue; } let taskStatus; try { const serviceInfo = await ecsClient.send(new DescribeServicesCommand({ cluster: clusterArn, services: [serviceName] })); const service = serviceInfo.services?.[0]; if (!service) throw new Error('サービス情報が取得できません'); const latestTaskDef = service.taskDefinition; // Fargate SpotからFargate(オンデマンド)へ切り替え await ecsClient.send(new UpdateServiceCommand({ cluster: clusterArn, service: serviceName, taskDefinition: latestTaskDef, capacityProviderStrategy: [ { capacityProvider: 'FARGATE', weight: 1 } ], forceNewDeployment: true, platformVersion: 'LATEST' })); console.log(`${serviceName} を最新タスク定義で再デプロイしました。`); // タスクがRUNNING状態になるまで待つ taskStatus = await waitForTaskToRun(clusterArn, serviceName, ecsClient); } catch (err) { console.error(`サービス更新エラー: ${err.message}`); taskStatus = 'TIMEOUT'; // エラー時はTIMEOUT } // ===== Slack通知処理 ===== // ※実運用ではここで https モジュール等を使用し、 // taskStatus の結果(RUNNING / TIMEOUT)に応じてSlackへ通知を送信していますが、 // 本記事では長くなるためコードを省略します。 // ======================== } }; // サービス名からクラスターを取得する async function findClusterByService(serviceName) { const clustersData = await ecsClient.send(new ListClustersCommand({})); const clusterArns = clustersData.clusterArns || []; for (const clusterArn of clusterArns) { try { const result = await ecsClient.send(new DescribeServicesCommand({ cluster: clusterArn, services: [serviceName] })); const service = result.services?.[0]; if (service && service.status !== 'INACTIVE') { return clusterArn; } } catch { // 無視して次のクラスターへ } } throw new Error(`サービス ${serviceName} が属するクラスターが見つかりませんでした`); } // サービスのタスクがRUNNING状態になるのを待つ async function waitForTaskToRun(clusterArn, serviceName, ecsClient) { const timeout = 10 * 60 * 1000; // 最大10分 const interval = 30 * 1000; // 30秒間隔 const startTime = Date.now(); while (Date.now() - startTime < timeout) { // RUNNING状態のタスクをリスト化(サービス名指定) const listTasksResponse = await ecsClient.send(new ListTasksCommand({ cluster: clusterArn, serviceName, desiredStatus: 'RUNNING', })); const taskArns = listTasksResponse.taskArns || []; if (taskArns.length === 1) { // タスクの詳細情報を取得 const describeTasksResponse = await ecsClient.send(new DescribeTasksCommand({ cluster: clusterArn, tasks: taskArns, })); const task = describeTasksResponse.tasks[0]; const isFargate = task.launchType === 'FARGATE' && task.capacityProviderName === 'FARGATE'; // FARGATE の RUNNING 状態を確認 if (task.lastStatus === 'RUNNING' && isFargate) { console.log(`タスクが RUNNING かつ FARGATE で起動中です: ${task.taskArn}`); return 'RUNNING'; } else { console.log(`タスクは RUNNING だが FARGATE ではありません。launchType: ${task.launchType}, capacityProvider: ${task.capacityProviderName}`); } } else { console.log(`RUNNING タスク数が ${taskArns.length} 件。切り替え中の可能性があります。`); } console.log(`${Math.floor((Date.now() - startTime) / 1000)}秒経過。再確認します。`); await new Promise(resolve => setTimeout(resolve, interval)); // 30秒待機 } console.warn(`FARGATE の RUNNING タスクが確認できませんでした(タイムアウト)`); return 'TIMEOUT'; }
-
定時リセット設定 (EventBridge Scheduler)
最後に、夜間や翌日の開発業務に向けて、構成を自動的に Fargate Spot へ戻すためのスケジューラ設定です。 AWSの需要が落ち着き始める「平日 18:00」をトリガーに設定しています。この例はapp用となっています。これを運用している各サービス分作成します。-
スケジュール設定
設定項目 設定値 補足 スケジュールタイプ Cronベースのスケジュール Cron式 0 18 ? * 2-6 * 毎週 月~金 の 18:00 (JST) に実行 フレックスウィンドウ オフ 正確な時間に実行するため ターゲット AWS Lambda 前述の「タスク調整用Lambda」を指定
-
ターゲット入力 (JSON)
{ "Cluster": "dev-cluster", "Service": "dev-app-service", "ForceNewDeployment": true, "CapacityProviderStrategy": [ { "CapacityProvider": "FARGATE_SPOT", "Weight": 1, "Base": 0 } ] }
-
スケジュール設定
導入効果
-
中断時間の比較
このアーキテクチャ導入の最大の成果は、Fargate Spot特有の中断が発生してから復旧するまでの「ダウンタイムの大幅な短縮」です。-
【Before】ECS標準スケジューラの場合
以前の構成で在庫枯渇(Capacity is unavailable)が発生した際、ECSサービススケジューラのバックオフ(待機時間の延長)挙動により、復旧までに約9分を要したケースがありました。

-
【After】イベント駆動リカバリーの場合
一方、導入後に同様のエラーが発生した際のログです。 SpotInterruption や PlacementFailure を検知して即座にLambdaが強制デプロイ(forceNewDeployment)を実行した結果、バックオフ時間を無視してリトライが行われ、わずか1分以内に復旧しました。

-
-
運用実績
導入から約半年が経過しましたが、実際にオンデマンドへの切り替え(=5分以上復旧しなかったケース)が発生した頻度についても触れておきます。6月〜12月の発生回数
2025年6月に本構成を導入してから現在(12月)に至るまで、CloudWatch Alarmが発火し、Slackに「Fargate(オンデマンド)へ切り替えました」という通知が届いた回数は、合計で 4回 でした。この結果から、「ほとんどの在庫枯渇(中断)は、5分以内の再デプロイリトライによって Fargate Spot のまま復旧できるようになった」ことがわかります。
-
コスト削減の実績
最後に、本アーキテクチャ運用におけるコストパフォーマンスについてです。 「安定性のためにFargateへ切り替える」という仕組みを入れたことで、コストがどの程度変動したのか、2025年6月〜11月(6ヶ月間)の実績をもとに試算しました。-
前提条件
- 稼働期間: 2025年6月1日 〜 11月30日(計 183日間 ≒ 4,392時間)
- リソース構成: 合計 4 vCPU / 8 GB
- APIサーバ: 2 vCPU / 4 GB
- Adminサーバ: 1 vCPU / 2 GB
- Cronサーバ: 1 vCPU / 2 GB
- 単価(東京リージョン):
- Fargate (On-Demand):
- vCPU $0.05056/h
- GB $0.00553/h
- Fargate Spot:
- vCPU $0.01595/h
- GB $0.00175/h
- Fargate (On-Demand):
- 比較シナリオ:
- パターンA:
- 4392時間すべてFargateで稼働した場合
- パターンB:今回の構成
- 4360時間Fargate Spotで稼働
- 期間中に発生した4回の在庫枯渇時のみ、日中(10:00〜18:00の8時間)をFargateへ切り替えて稼働した場合
- 32時間Fargateで稼働
- パターンA:
- 試算結果
比較項目 パターンA (完全Fargate) パターンB (今回の構成) Fargate費用 4,392h × \$0.2465 = \$1,082.54 32h × \$0.2465 = \$7.89 Fargate Spot費用 (利用なし) = \$0.00 4,360h × \$0.0778 = \$339.12 合計コスト (USD) \$1,082.54 $347.01 日本円換算 (1ドル=155円) 約 167,800円 約 53,800円 削減率 - 約 68% 削減
-
前提条件
まとめ
-
コストパフォーマンス
試算結果の通り、半年間の運用でFargateにかかったコストはわずか $7.89(約1,200円) でした。 これにより、全体の 99%以上 の時間を割安なSpotインスタンスで賄うことができ、トータルで 約11万円(削減率68%) という大きな削減効果を上げています。
-
開発の可用性の確保
以前はFargate Spot枯渇により10分近く環境が停止し、開発の手が止まることもありました。 しかし導入後は、イベント駆動の即時リトライにより 1分以内 に復旧するケースが大半となり、万が一枯渇が長引いても「5分後には確実にFargateで復旧する」という安全装置が機能しています。 その結果、開発チームから「サーバに繋がらない」という問い合わせは激減し、開発者はインフラの事情を気にせず業務に集中できました。結論
「Fargate Spotは安いが、可用性が無いし、Fargateは高い」、この悩みに対して、「動的に切り替える」 というアーキテクチャで一つの解決策を出しました。 AWSのマネージドサービスを組み合わせることで、運用負荷を上げることなく「コスト削減」と「高可用性」の両立 は十分に可能です。
この記事が、同じようにFargate Spotの運用で悩まれている方の参考になれば幸いです。
最後に
CYBIRD Advent Calendar 2025、 明日は@R_araiさんのさんの「シェルスクリプト初心者がGeminiを使ってビルドを自動化した話」です。