課題と目的
昨今,機械学習技術の飛躍的な発展と高性能な計算機の低価格化によって,個人でもGPTやBERTといった大規模言語モデル(LLM)を手元で実行,転移学習などを用いたカスタマイズが容易にできるようになりました.
しかし,対象となるテキストデータをPDFファイルから取得する場合,HTMLやMarkdownといった他形式と異なり,安易にコピー・アンド・ペーストができないなど,下処理に多くの労力を割く必要がありました.
そこで,本記事では,Pythonのライブラリの一つである spacy-layout を使用して,複数の図や表を含むPDFから,必要なテキストのみを分類・抽出する方法を紹介します.
インストールと実行環境
実行環境
Python: 3.11〜3.12
GPU: RTX3060 12GB(なくても動作可能・CPUで動作します)
インストール
pip install spacy-layout
spacy-layout はバックエンドに Docling(IBM Research製)を使用しています.インストール時に,Doclingおよびレイアウト解析AIモデル(docling-ibm-models)も一緒に導入されます.
spacy-layout とは何をしているのか
spacy-layout は単なる「テキスト抽出ツール」ではありません.以下の処理を組み合わせています:
- レイアウト解析: Doclingが搭載するAIモデルにより,ページ上の各要素(本文・見出し・図・表など)を識別・分類
- テキスト抽出: デジタルPDF(テキスト埋め込み型)はpdfium2経由で直接抽出,画像埋め込み領域はOCR(RapidOCR)を使用
-
spaCy Doc化: 抽出した要素をspaCy の
Docオブジェクトとして返す
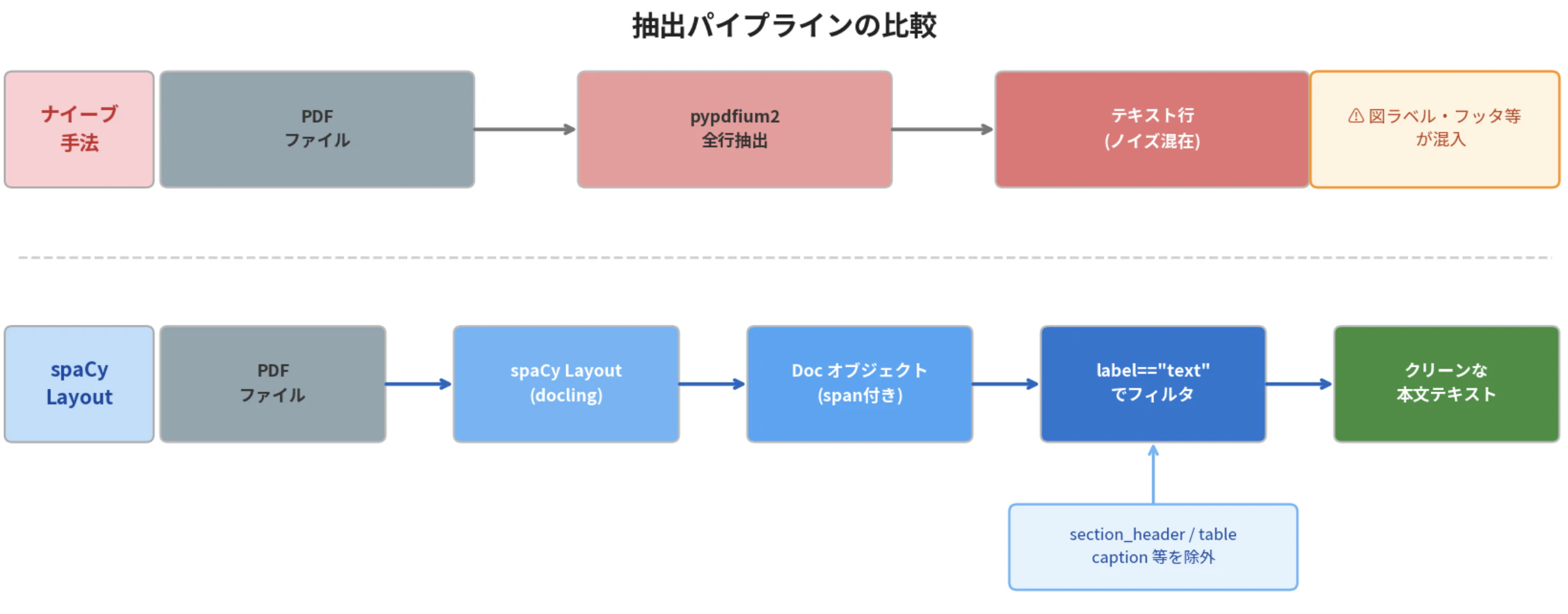
「ナイーブな抽出(pypdfium2等で全行取得)」との違いは,各テキストに種類ラベルが付与される点にあります.これにより,本文テキストだけを選んで取得したり,表のデータだけを取り出したりが容易になります.
基本的な使い方
最小限のコード
import spacy
from spacy_layout import spaCyLayout
from pathlib import Path
# spaCyの空のパイプラインを初期化(言語は任意)
nlp = spacy.blank("ja")
layout = spaCyLayout(nlp)
# PDFを処理 → Doc オブジェクトが返る
doc = layout(Path("./report.pdf"))
# 全テキスト(本文・見出し・表など結合)
print(doc.text[:200])
# ページ情報
print(doc._.layout)
# Markdown形式で出力
print(doc._.markdown[:500])
layout span を確認する
処理結果は doc.spans["layout"] に格納されています.各 span には以下の属性があります:
| 属性 | 説明 |
|---|---|
span.label_ |
要素の種類("text", "section_header" など) |
span.text |
抽出されたテキスト |
span._.layout.page_no |
ページ番号(1始まり) |
span._.layout.x, span._.layout.y
|
バウンディングボックスの座標 |
span._.heading |
直近の見出し span |
span._.data |
表データ(pandas.DataFrame,table型のみ) |
for span in doc.spans["layout"]:
print(f"ページ {span._.layout.page_no} [{span.label_}]: {span.text[:60]}")
出力例(JGCホールディングス株式会社「JGC Report 2020」より引用):
ページ 1 [text ]: 〒 220-6001
ページ 1 [text ]: 神奈川県横浜市西区みなとみらい 2-3-1
ページ 1 [section_header]: 統合報告書
ページ 2 [section_header]: 今日まで受け継がれる 創業者の思い
ページ 2 [caption ]: 創業者 実吉 雅郎
ページ 2 [section_header]: JGC Way 企業理念
ページ 2 [text ]: 日揮グループの企業理念「JGC Way」は,日揮グループが企業活動を進めるうえでの基本的な軸です.
ページ 2 [text ]: 私たちは,世界を舞台に,技術と知見を結集して,人と地球の豊かな未来を創ります.
検出できるレイアウト要素の種類
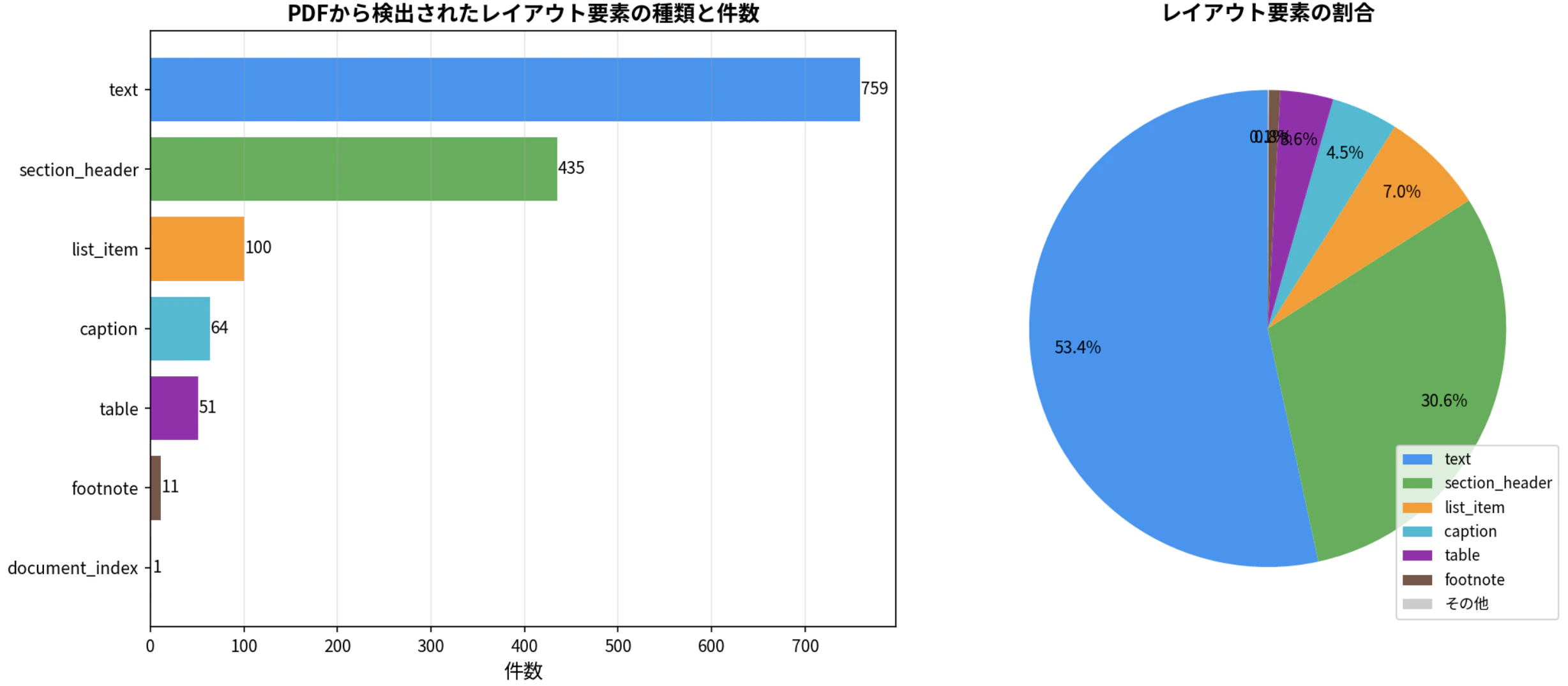
実際の統合報告書PDF(JGCホールディングス株式会社「JGC Report 2020」,76ページ,同社ウェブサイトより公開取得)を処理した結果,以下のラベルが検出されました:
| ラベル | 件数 | 説明 |
|---|---|---|
text |
759 | 本文テキスト |
section_header |
435 | 見出し・セクションタイトル |
list_item |
100 | 箇条書き |
caption |
64 | 図・表のキャプション |
table |
51 | 表(データはDataFrameで取得可) |
footnote |
11 | 脚注 |
document_index |
1 | 目次 |
ラベルの種類一覧
| ラベル | 意味 |
|---|---|
text |
本文(段落テキスト) |
section_header |
セクション見出し |
title |
ドキュメントタイトル |
list_item |
箇条書き項目 |
table |
表 |
figure |
図 |
caption |
図・表のキャプション |
footnote |
脚注 |
page_header |
ページヘッダー |
page_footer |
ページフッター |
formula |
数式 |
document_index |
目次・索引 |
本文テキストのみを抽出する
LLMの学習データや検索用コーパスを作る場合,本文(type == "text")だけが欲しいことがほとんどです.
import spacy
from spacy_layout import spaCyLayout
from pathlib import Path
nlp = spacy.blank("ja")
layout = spaCyLayout(nlp)
doc = layout(Path("./report.pdf"))
# 本文テキストのみ抽出
body_texts = [
span.text.strip()
for span in doc.spans["layout"]
if span.label_ == "text"
]
print(f"本文 span 数: {len(body_texts)}")
for text in body_texts[:3]:
print(f" {text[:80]}")
ページ番号付きで取得したい場合:
body_with_page = [
{"page": span._.layout.page_no, "text": span.text.strip()}
for span in doc.spans["layout"]
if span.label_ == "text"
]
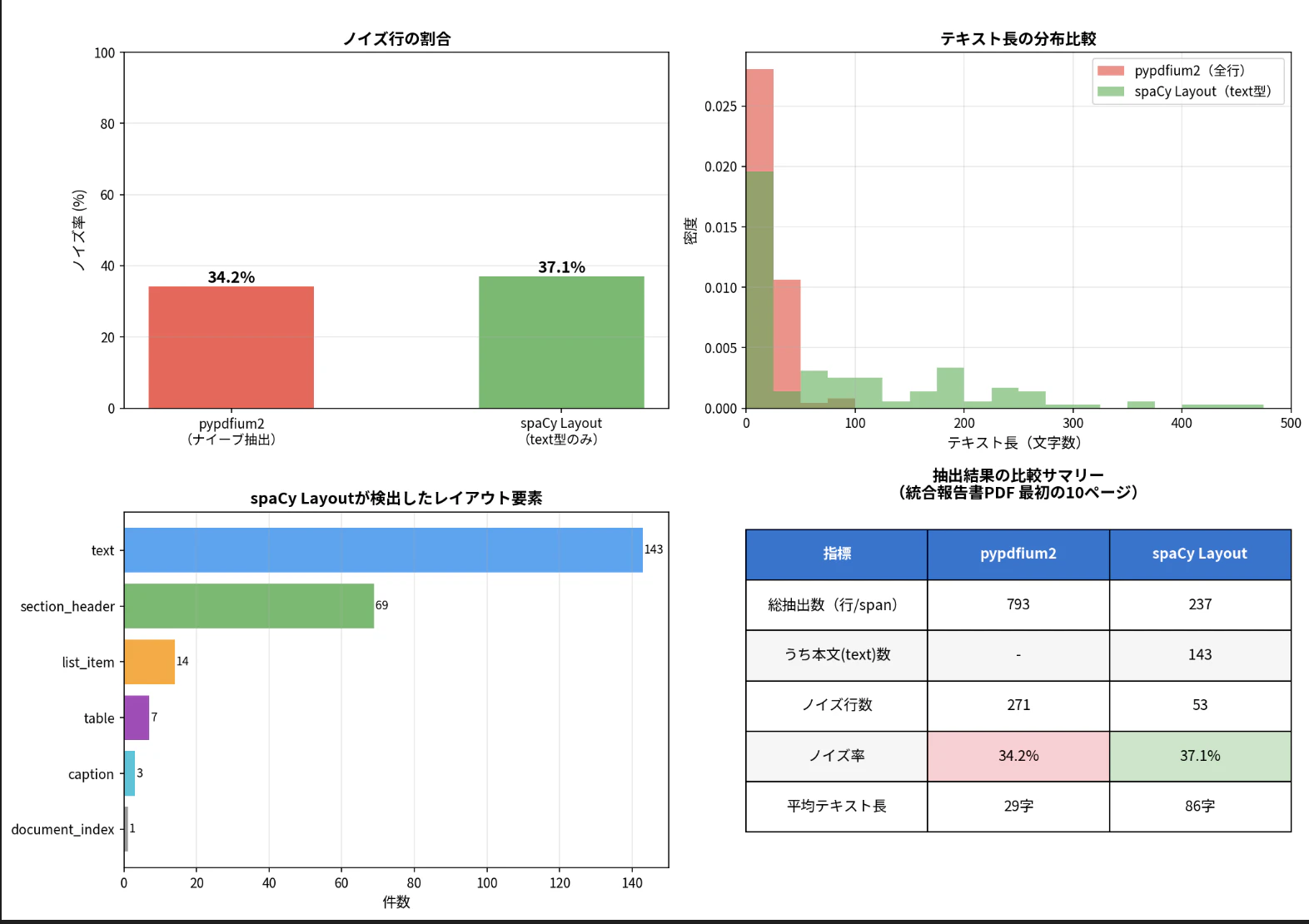
ナイーブ抽出との比較
pypdfium2(Doclingも内部で使用するPDFライブラリ)を使ってページのテキストをそのまま取り出す「ナイーブな方法」と比べてみます.
ナイーブな抽出(pypdfium2)
import pypdfium2 as pdfium
pdf = pdfium.PdfDocument("./report.pdf")
for i in range(len(pdf)):
page = pdf[i]
text = page.get_textpage().get_text_range()
for line in text.splitlines():
if line.strip():
print(line.strip())
出力(最初の10行):
'統合報告書'
'2020年3月期'
'2020'
'JGC Report'
'神奈川県横浜市西区みなとみらい 2-3-1'
'T e l: 045 - 682 - 1111'
'Fax: 045 - 682 - 1112'
'www.jgc.com'
'〒220 - 6001'
'MISSION'
表紙の断片が大量に出てきます.数字単体,英字単体,住所,電話番号など,後処理で除去すべきノイズが多数混入しています.
spacy-layout による抽出
body_texts = [
span.text.strip()
for span in doc.spans["layout"]
if span.label_ == "text" and len(span.text.strip()) > 20
]
本文(type == "text")だけに絞ると:
'日揮グループの企業理念「JGC Way」は,日揮グループが企業活動を進めるうえでの基本的な軸です.'
'私たちは,世界を舞台に,技術と知見を結集して,人と地球の豊かな未来を創ります.'
'1928年(昭和3年),創業者である実吉雅郎は関東大震災以降,輸入が急増していたガソリンの国内生産...'
'当社は,2015年より「JGCレポート」を発行し,ステークホルダーの皆さまに企業活動を紹介しています.'
意味のある段落テキストだけが抽出されます.
比較のまとめ
表(Table)を取り出す
spacy-layout では,表をパースして pandas.DataFrame として取得できます:
for table_span in doc._.tables:
page = table_span._.layout.page_no
df = table_span._.data
if df is not None and not df.empty:
print(f"ページ {page} の表({df.shape[0]}行 x {df.shape[1]}列):")
print(df.head())
print()
バッチ処理(複数PDFを一括変換)
複数のPDFを順番に処理するには layout.pipe() を使います:
from pathlib import Path
import spacy
from spacy_layout import spaCyLayout
nlp = spacy.blank("ja")
layout = spaCyLayout(nlp)
pdf_paths = list(Path("./pdf_folder").glob("*.pdf"))
for doc in layout.pipe(pdf_paths):
texts = [
span.text.strip()
for span in doc.spans["layout"]
if span.label_ == "text"
]
print(f"抽出テキスト数: {len(texts)}")
デバイス指定(GPU / CPU)
処理が重いと感じた場合,GPUを使うことで高速化できます(ただしGPUメモリが必要です):
# spaCyLayoutのdeviceパラメータは現バージョン(0.0.12)では非対応
# → 環境変数で指定する
import os
os.environ["DOCLING_DEVICE"] = "cuda" # or "cpu"
nlp = spacy.blank("ja")
layout = spaCyLayout(nlp)
doc = layout(Path("./report.pdf"))
補足: spacy-layout v0.0.12 では
spaCyLayout(nlp, device="cuda")のようなパラメータは未対応のバージョンがあります.環境変数DOCLING_DEVICEで指定するのが確実です.
注意点・既知の問題
カスタムフォントのGLYPH化
PDFがカスタムフォント(フォントの文字コードマッピングが埋め込まれていないもの)を使っている場合,見出しなどが GLYPH<31> GLYPH<30> ... のように文字化けすることがあります.
[section_header]: GLYPH<31> GLYPH<30> GLYPH<29> GLYPH<29> GLYPH<30>...
これはOCRの失敗ではなく,PDF仕様上の問題(フォントのエンコーディング情報が欠落)です.本文テキスト(type == "text")は一般的に影響を受けにくいですが,見出しや特殊フォントを使った部分で発生します.対処法としては:
- 該当ラベル(
section_headerなど)を使用しない - PDFを再出力してフォントを埋め込む
OCRについて
Docling は画像として埋め込まれたテキスト領域に対してはOCR(RapidOCR)を自動適用します.デジタルPDF(テキスト直接埋め込み型)に対してはOCRは必要ない場合が多く,その場合はレイアウト解析モデルが主役です.
処理時間
Doclingのレイアウト解析AIモデルが初回にロードされるため,処理には相応の時間がかかります(76ページのPDFで数分程度).CPUでも動作しますが,GPUがあると高速です.
まとめ
| 手法 | メリット | デメリット |
|---|---|---|
| pypdfium2など(ナイーブ) | 高速,軽量 | ノイズ除去が必要,構造情報なし |
| spacy-layout | 要素ラベル付き,表もDataFrameで取得可能 | 処理が遅い,カスタムフォントで文字化けの可能性 |
spacy-layout(Docling)は,PDFのレイアウトを理解した上でテキストを分類・抽出するため,機械学習や RAG(Retrieval-Augmented Generation)の前処理として非常に有用です.特に:
- 本文(
type == "text")だけを抽出してコーパスを作る - 表データを
pandas.DataFrameとして取り出す - 見出しをキーにしてセクションを分割する
といったユースケースで威力を発揮します.
参考
使用データの出典
本記事の動作例に使用したPDFは以下の通りです。いずれも各社ウェブサイトにて一般公開されている統合報告書です。本記事での使用は,ライブラリの動作説明を目的とした最小限の引用(著作権法第32条)の範囲内です。
- JGCホールディングス株式会社「JGC Report 2020」