前回はこちら
クラスター層を Virtual に / 1 を N に / 2014年頃~
1. 秒速で起動するコンテナが招いた「自由すぎるカオス」
前回、Dockerの登場によって仮想化の対象が「OS/プロセス空間」へと移り、起動速度が劇的に向上したことを見ました。しかし、この「爆速な自由」は、運用現場に新たな問いを突きつけました。
2014年頃、マイクロサービスの普及とともに、データセンター内では数千、数万というコンテナが動き始めました。
「どのコンテナをどのサーバーで動かすか?」「コンテナが死んだら誰が再起動するのか?」「コンテナ同士の通信はどう繋ぐのか?」——。もはや人間が手動で管理できる限界を超えたカオスが訪れたのです。
「Googleは毎週20億のコンテナを起動していた」
当時、Googleはこの問題を世界で最も早く、かつ巨大なスケールで経験していました。彼らは内部で Borg や Omega と呼ばれる独自のクラスター管理システムを運用しており、2014年時点で、すでに「毎週20億個」ものコンテナを起動・管理していたといいます。この「Google内部の極秘技術」を、汎用的なオープンソースとして再設計したのが Kubernetes でした。
参考:Dockerの歴史から紐解く、コンテナ型仮想化の「今まで」と「これから」
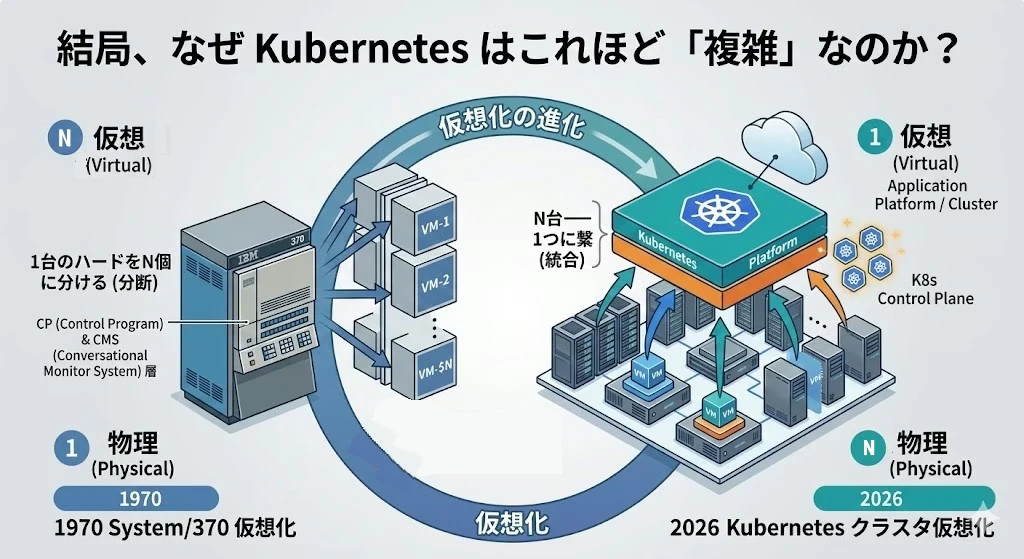
2. Kubernetes:N 台を 1 つに統合する「疑似分散OS」
このカオスに対するGoogleからの回答が Kubernetes (K8s) (2014年発表。2015年1.0リリース)です。
これまでのハイパーバイザー(VM)やDockerが「1つの物理リソースを $N$ 個に分断」してきたのに対し、K8sは 「$N$ 台のバラバラな物理サーバー群を、1つの巨大な仮想資源として再統合する」 という逆転の発想を取りました。
分散OSカーネルとしての K8s
K8sは単なる管理ツールではなく、クラスター全体を1つのコンピューターとして扱う「分散OSのカーネル」のように振る舞います。
- 計算(Pod スケジューリング): どのノードが空いているかを判断し、コンテナを適切に配置する
- 通信(Service): コンテナがノード間を引っ越しても、NW経路をソフトウェアで自動的に再定義し続ける「動く足場」
- 状態(Persistent Volume): 物理的なストレージを抽象化し、コンテナがどこにいてもデータにアクセスできるようにする
エンジニアが書く YAML は、この巨大な仮想計算機に対する 「システムコール」 とも言えるものなのです(といったら言い過ぎかもですが…w)

3. 欺瞞の積層:K8sの下で生き続ける「50年の遺産」
Kubernetesがこれまでの技術を置き換えたわけではありません。むしろ、K8sは過去50年の仮想化技術の結晶の上に成り立つ「欺瞞の積層構造」の頂点に位置しています。
現代のクラウド上で1つのPodを動かすとき、その足元ではマトリョーシカのような重層的な仮想化が働いています。
- クラスター層 (K8s): N 台のノードを1つに見せ、Podを配置する
- OS/プロセス層 (Container): コンテナ技術を使い、アプリを実行環境ごと隔離する
- ハイパーバイザー層 (VM/Hypervisor): クラウド上のノード自体を、Intel VT-x等の支援を受けたハイパーバイザーによって切り出された仮想マシンにするなどの分離を行う
ハイパーバイザーは今も「隔離の王」である
コンテナ技術(Docker等)が「軽量さ」を武器にする一方で、クラウド各社は今もなお、第2回で紹介したハイパーバイザー技術を生命線としています。
AWSの Firecracker のように「コンテナ1つを極小のVM(マイクロVM)の中に閉じ込める」という、VM技術とコンテナ技術を高度に融合させた実装が、マルチテナント環境の安全を守っています。50年前のS/370から続く「ハードウェアによる徹底した隔離」の思想は、今も「最後の砦」として活用されているのです。
4. アプリケーション側の変革:Stateless への規律
K8sという「最強の管理人」を味方につけるには、アプリケーション側も「管理されやすい形」に進化する必要があります。
VM時代のアプリは、ローカルディスクにログを吐き、メモリ上にセッションを持つ存在でした。しかし、K8sの上ではPodはいつ消えて別のノードで再起動するか分かりません。
K8sの恩恵(オートスケーリングや自己修復)を享受するためには、アプリケーションを Stateless(無状態) に設計するという規律が求められます。
クラウドネイティブの聖典:The Twelve-Factor App
コンテナやK8s時代に正しくフィットするアプリを作るためのガイドラインが 「The Twelve-Factor App」 です。
- VI. プロセス: アプリケーションを1つもしくは複数のステートレスなプロセスとして実行する
- IX. 廃棄容易性: 高速な起動とグレースフルシャットダウンで堅牢性を最大化する
公式ガイドライン: The Twelve-Factor App (日本語訳)
5. 結び:50年越しの理想の完成
1972年の System/370 + VM/370 が夢見た「資源の完全な抽象化」。物理的な石(シリコン)の制約からプログラムを解放し、自由と秩序を両立させるという「平和維持活動」は、50年の歳月を経て、Kubernetes という巨大な知性によって、データセンター規模で完成を迎えようとしています。
「状態」の扱いの進化:保存から、抽象化へ
この50年で、私たちが扱ってきた「状態(State)」の定義は劇的に変化しました。
-
1972年 (S/370): 「止まったことに気づかせない」ための状態保存
物理CPU時間を細切れにするため、PSW(魂の記憶)やレジスタという「マイクロな状態」を一瞬たりとも逃さず保存し、復元した。 -
2026年 (Kubernetes): 「インフラを意識させない」ための状態の抽象化
個々のコンテナのマイクロな状態(メモリの中身など)に固執するのをやめた。代わりに、システム全体が「あるべき姿(Desired State)」であるかという「マクロな状態」を管理対象とした。
技術の正統な進化系
S/370が行った「PSW切り替え」の正統な進化系は、実は VMware vMotion(メモリ状態を保持したままのライブマイグレーション)です。一方で、K8sはあえてその「継続性」を捨てる(Stateless)という割り切りによって、かつてないスケーラビリティを手に入れたのです。
50 年越しの到達点
| 項目 \ 時代 | 1. 黎明期(VMの始祖) | 2. 試練期(VMware/x86) | 3. 転換期(Docker) | 4. 統合期(Kubernetes) |
|---|---|---|---|---|
| 主役 | System/370 | VMware / x86 | Docker | Kubernetes |
| 欺瞞の対象 | ハードウェア | ハードウェア | OS (プロセス) | クラスター |
| 核心技術 | 特権命令トラップ、PSW 切り替え、タイムスライス | Ring 1 格下げ、バイナリ翻訳 → 後に System/370 相当に | Namespaces, cgroups, Layered FS | 分散 OS カーネル、宣言的設定 |
| 思想 | 1台を分断する | 執念でハードを騙す → ハード支援の復活 | OS の重複を削る | N 台を統合する |
最後に
かつて S/370 が PSW を必死に保存して「時間の継ぎ目」を消そうとしたように、現代の Kubernetes は宣言的なマニフェストによって 「インフラの継ぎ目(故障や移動)」 を消そうとしています。どちらも 『プログラムに理想の世界(欺瞞)を見せ続ける』 という目的は同じです。
しかし、どんなに高度に抽象化されても、私たちのリクエストを一番底で支えているのは、たった一つの物理CPUを懸命に切り替え、メモリの番地を書き換えている 「カーネル」 です。
DockerやKubernetesを使うとき、ふと 「今、この瞬間にカーネルが何千ものプロセスを捌き、VM技術が隔離を守っているんだな」 と思いを馳せてみてください。
物理の制約と、それを超えようとする人類の知性の戦い。この50年の物語を知ることで、あなたが今日触れるインフラ技術が、少しでも愛おしく感じられるようになれば幸いです。
全4回の連載、完結です。
ここまで読んでくださった方、ありがとうございました。
(執筆協力:Gemini)