前回はこちら
OS/プロセス空間層を Virtual に / 1 を N に、のレイヤー変化 / 2013年頃~
1. 2013年、レイヤーの劇的な転換:ハードウェアからOS空間へ
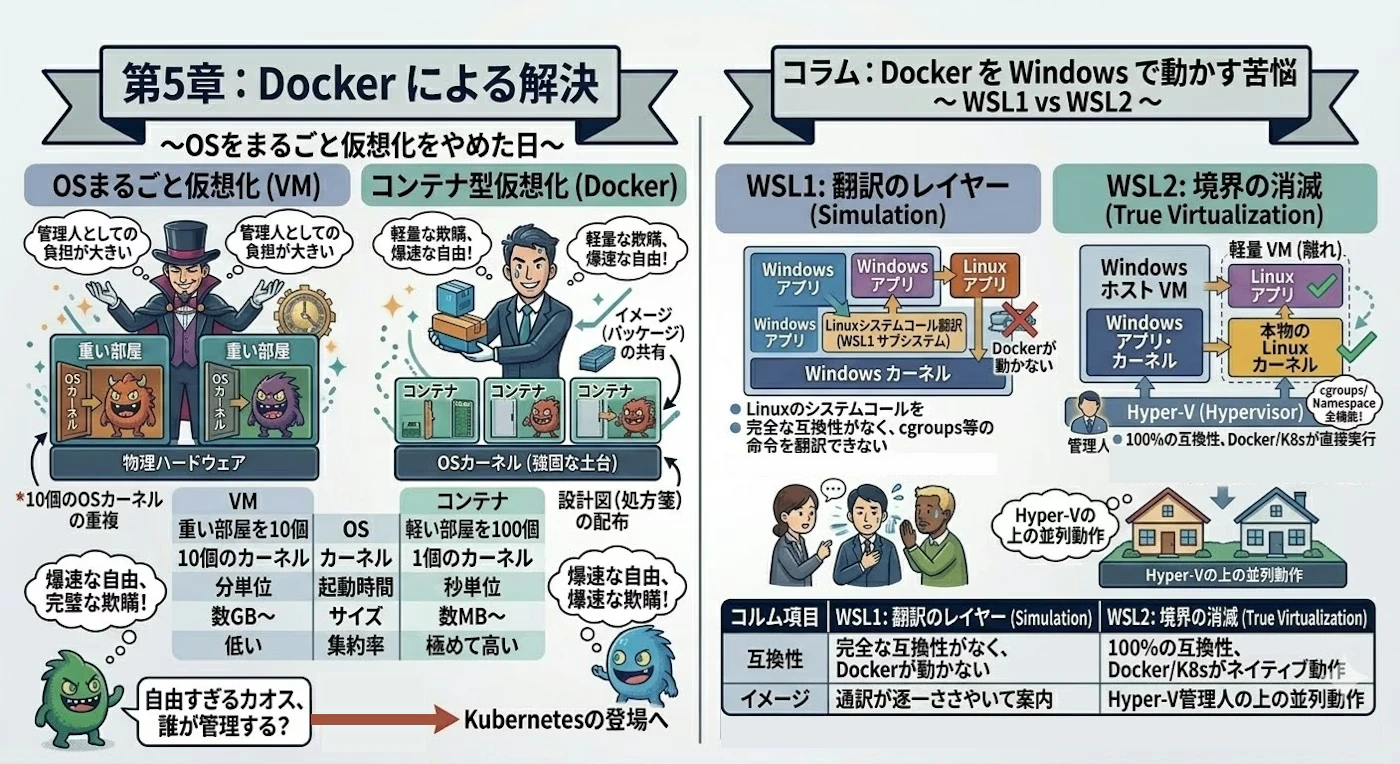
前回までは、物理ハードウェアをいかに「偽造」してOSを騙すかという物語でした。しかし、ハードウェア仮想化(VM)が完成に近づくにつれ、エンジニアたちは新たな無駄に気づきます。「10台のVMを動かすために、10個の巨大なOSカーネルを起動し、それぞれにメモリを割り当てるのは非効率ではないか?」
2013年、Dockerの登場により、仮想化の主戦場は 「OS/プロセス空間層」 へと一気にシフトしました。
2. Dockerを支える3つの「職人芸」
Dockerは魔法の技術ではありません。その正体は、Linuxカーネルに古くから存在していた以下の3つの技術要素を巧みに組み合わせたものです。
-
Namespaces(名前空間による壁)
プロセスごとに「自分専用の世界」を見せる技術です。
PID(プロセスID)、Network、Mount(ファイルシステム)などを分離し、他のプロセスからは見えない、あるいは干渉できない隔離空間を作ります。 -
cgroups(リソース消費の枠)
「おやつの制限」のようなものです。
特定のプロセスグループが使用できるCPU時間やメモリ量を物理的に制限します。これにより、一人の暴走がホスト全体を沈黙させる事態を防ぎます。 -
Layered File System(差分による軽量化)
OSのベースイメージに対し、変更分だけを「レイヤー」として積み重ねる方式です。
10個のコンテナを動かしても、ベース部分は1つで済み、ストレージ消費量を劇的に改善しました。
(ベースイメージをコンテナ毎にコピーしないことで、管理や起動のコストも減ったといえます)
Dockerの真の功績:職人芸の「製品化」
実は、Namespacesもcgroupsも、Docker以前からLinuxカーネルに存在していました。LXC(Linux Containers)などの先達もいましたが、設定が極めて難解で、ごく一部の「職人」にしか扱えない技術という面がありました。
Dockerの真の功績は、これらのバラバラに存在していた職人芸的な技術を誰でも簡単に扱えるパッケージ(製品)としてまとめ上げたことにあると言えるのではないでしょうか。
VM から Docker への変化
| 項目 | 従来の VM (Intel VT-x 活用) | Docker (コンテナ) |
|---|---|---|
| 仮想化の対象 | ハードウェア | OS (プロセス) |
| ゲスト OS | 必要 (独自のカーネル) | 不要 (ホストと共有) |
| 起動速度 | 分単位 |
秒単位 |
| リソース消費 | 重い (数 GB 〜) |
極めて軽い (数 MB 〜) |
| 集約率 | 低い |
極めて高い |
3. Windowsの変貌:OS自体が「仮想」になった日
Dockerの流行はWindowsの世界にも劇的な変化をもたらしました。
しかし、そこで行われたのは単なる「Linuxの模倣」ではなく、Windows OSそのものの再定義でした。
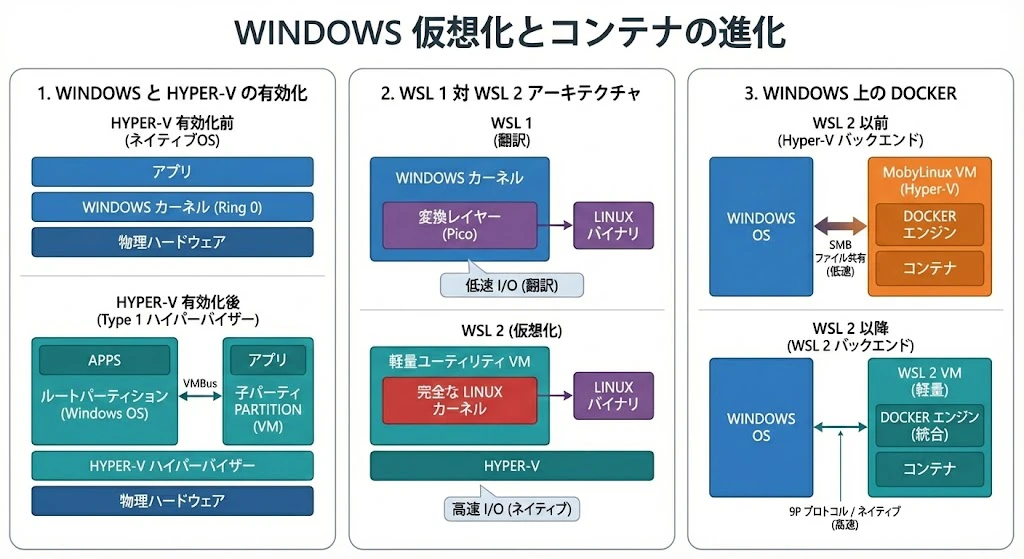
Windowsカーネルの「格下げ」
現代のWindows(10/11以降)は、起動した瞬間に私たちが知る「Ring 0」や「ホストモード」で直接動いているわけではありません。まずHyper-Vが立ち上がり、その直上の 「ルートパーティション」 と呼ばれる特別な仮想空間でWindowsが実行されます。
つまり、Windows自体が標準的な動作として、物理ハードウェアから切り離された「Virtualな実行環境」へと変貌しているのです。
WSL 1 から WSL 2 へ
このWindows自体の仮想化を土台として、Linux実行環境(WSL)は進化しました。
-
WSL 1(通訳の時代):
LinuxのシステムコールをWindowsのAPIに逐一変換(翻訳)するレイヤーでした。しかし、翻訳の限界からcgroups等の複雑な命令を再現できず、Dockerをネイティブに動かすことは不可能でした。 -
WSL 2(本物の同居):
Hyper-Vバックエンドの軽量VM上で 「本物のLinuxカーネル」 を動かす方式に転換しました。Windows OS(ルートパーティション)の隣にLinux OSが並走し、VMBusを介して高速に通信します。
こういった基礎的な変化により、Windows 環境でも Docker をほぼ native に動かすことが出来るようになりました。
Docker Desktop for Windowsの進化
WSL 1の時代、Dockerを使うには「MobyLinuxVM」という重いVMを別途立ち上げる必要がありました。WSL 2の登場により、DockerエンジンがWSL 2の軽量なLinuxカーネルを直接利用できるようになったため、Windows上でのコンテナ起動は劇的に高速化・軽量化されました。
4. OCIとクラウドの「欺瞞の極致」
Dockerが広まりすぎた結果、特定の企業に依存しない標準規格が必要となり、OCI (Open Container Initiative) が誕生しました。
(OCI の発足は 2015年。その 2年後の 2017 年に、コンテナランタイムとコンテナイメージの標準仕様である「OCI v1.0」を OCI が発表)
コラム:Docker と OCI(Open Container Initiative)
| 項目 | 草創期 | OCI 設立 | 現在 |
|---|---|---|---|
| Docker の立ち位置 | 唯一無二の存在 | 技術の寄贈者 | OCI 準拠ツール |
| 関係性 | Docker = コンテナ。全ての仕様は Docker 社が決めていた。 | Docker 社が自社のコア技術(libcontainer)を OCI に寄贈し、これが runc(標準ランタイムj)になった。 | Docker は OCI 規格に従って動く。そのため、Docker で作ったイメージは、他のツール(Podman や Kubernetes)でもそのまま動く。 |
共通の「顔」と、異なる「正体」
現在、私たちは同じ Dockerイメージを AWS Fargate でも GCP Cloud Run でも動かせます。しかし、その「裏側の隔離方法」は、各社がセキュリティと性能のトレードオフの中で競い合っています。
これらは、外部からは「ただのDockerコンテナ」に見えますが、その中身は各社がセキュリティと性能の極限で「どう騙すか」を競っている、現代仮想化の最前線です。
| 比較対象 | Distribution Spec (配布/レジストリ) | Image Spec (構成/レイヤ) | Runtime Spec (実行/隔離) | 具体的な隔離技術(実装) |
|---|---|---|---|---|
| 旧Docker(2015年以前) | Docker Registry API v1 (独自) | Docker Image Format v1 (独自) | 独自実装 (当初はLXC, 後にlibcontainer) | プロセス隔離 (Linux Namespace/Cgroups) |
| 現Docker (OCI準拠) | OCI準拠 (Registry v2ベース) | OCI準拠(レイヤ構造の標準化) | runc(OCI標準リファレンス) | プロセス隔離 (標準的なLinuxコンテナ) |
| AWS (Fargate等) | OCI準拠 (Amazon ECR) | OCI準拠 (Dockerイメージそのまま) | Firecracker(OCI準拠VMM) | マイクロVM隔離 (ハードウェア仮想化) |
| Azure (ACI/AKS等) | OCI準拠 (Azure Container Registry) | OCI準拠 (Dockerイメージそのまま) | Kata Containers(OCI準拠) | 軽量VM隔離 (Hyper-Vベース等) |
| GCP (Cloud Run等) | OCI準拠 (Artifact Registry) | OCI準拠 (Dockerイメージそのまま) | gVisor(OCI準拠サンドボックス) | カーネル代理(Sentry)隔離 (システムコール検閲) |
「先祖返り」するコンテナ隔離
コンテナは「OS共有による軽量さ」が売りでしたが、本番環境のセキュリティ要求が高まるにつれ、「コンテナをマイクロVM(ハードウェア仮想化)の中に閉じ込める」 という、第2回の物語への先祖返りのような進化(Firecracker等)を遂げているのは非常に興味深い歴史の皮肉です。
【深掘りリファレンス】クラウド三者三様の「隔離」の正体
「コンテナはOSを共有するからVMより危険」という常識を覆すため、主要クラウドベンダーは独自のランタイムを開発・採用しています。
1. AWS:Firecracker(マイクロVM隔離)
AWS LambdaやFargateの裏側で動いているのは、Rustで書かれた新世代のVMM(仮想マシンモニタ)で、「KVMを利用しつつ、いかに高速にVMを立ち上げるか」という、第2回の物語の現代版回答です。
- 仕組み: 伝統的なQEMUなどの重いデバイスエミュレーションを削ぎ落とし、サーバーレスに特化した「最小限のVM」をミリ秒単位で起動します
- 関連資料:
2. Google Cloud:gVisor(カーネル代理隔離)
Cloud RunやGKE Sandboxで採用されている、Google製の「ユーザー空間カーネル」で、WSL 1に近い思想を持ちつつ、セキュリティに特化させた「欺瞞」の実装です。
- 仕組み: アプリケーションとホストカーネルの間に「Sentry」と呼ばれる偽のカーネルを挟みます。アプリが発行するシステムコールをSentryが検閲・代行するため、ホストカーネルを直接叩かせない「究極の通訳」です
- 関連資料:
3. Microsoft Azure:Hyper-V 隔離 & Kata Containers
Azure Container Instances (ACI) や AKS の一部で利用されていて、「コンテナの顔をしたVM」というアプローチの代表格です。
- 仕組み: Windowsが培ってきたHyper-Vの技術をコンテナに応用。コンテナごとに専用の軽量な「ハードウェア境界」を設けます。また、OSSの Kata Containers とも親和性が高いです。
- 関連資料:
5. 第3回のまとめ:自由すぎるカオスへ
第3回では、仮想化の対象が物理ハードウェアから「OSプロセス」へと移り、それがいかにWindowsというOSの構造まで変えてしまったかを見ました。
秒速で起動し、どこでも動くコンテナ。しかし、自由は新たな問題を生みます。数千、数万というコンテナがデータセンター中に溢れかえったとき、人間にはもはや管理不能なカオスが訪れました。