はじめに
もうそろそろ鐘の音が聞こえ始めたクリスマス、坊主もサンタも走り回るこの師走時期に電車が遅延しているだなんて『なんという機会損失だ!』ということで(?)、今回は『Webスクレイピング(Python)』で電車の運行情報を取得してみようと手を動かして構築してみました
参考資料
参考リンクには今回作成した大元になる方のハンズオンです。__こちらにプラスして、遅延情報の理由を表示させている__ハンズオンをさせていただきました。しかし、なによりお手本があると大変助かり理解も捗りました。
構成図

ハンズオン
1:LINE Notifyでアクセストークンを発行する
下記リンクからご確認ください
天気予報情報をスクレイピング(Python)で、LINE NotifyによりLINE通知の構築
2:コードの記述
サンプルコード(コメントアウトで各動作の内容記述あり)
import requests #LINEへリクエスト
from bs4 import BeautifulSoup #スクレイピング
import os #環境変数のため
from dotenv import load_dotenv #環境変数のため
load_dotenv()
# LINE Notifyと連携するためのtoken
line_notify_token = os.getenv('TRAIN')#トークン直打ちでも可能
line_notify_api = 'https://notify-api.line.me/api/notify' #LINE Notifyへの通知URL
# LINENotifyにメッセージを送付
def delay_information_send(message):
payload = {'message': message}
headers = {'Authorization': 'Bearer ' + line_notify_token}
requests.post(line_notify_api, data=payload, headers=headers)
# スクレイピングして運行状況ページの抽出
def Extract_delay_information():
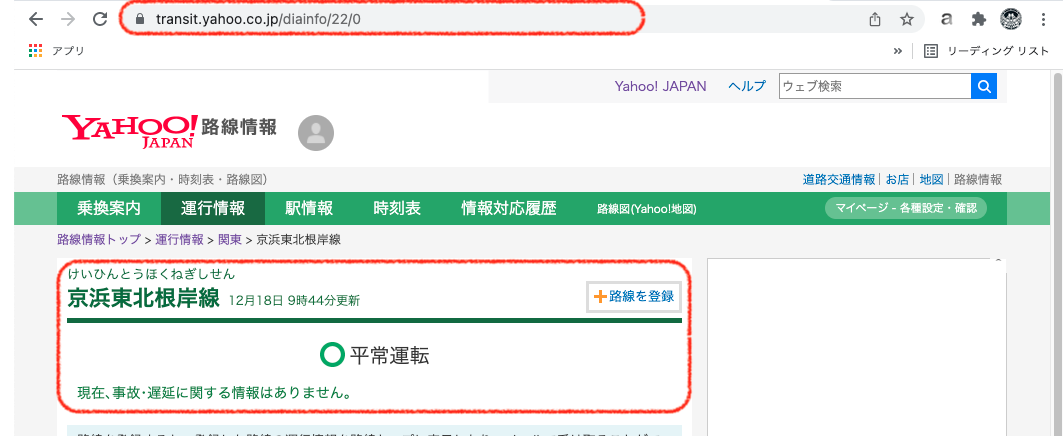
url ='https://transit.yahoo.co.jp/diainfo/22/0'#京浜東北線の運行状況のURL
r = requests.get(url)#Requestsを利用してWebページを取得する
Soup = BeautifulSoup(r.text, 'html.parser')# BeautifulSoupを利用してWebページ解析
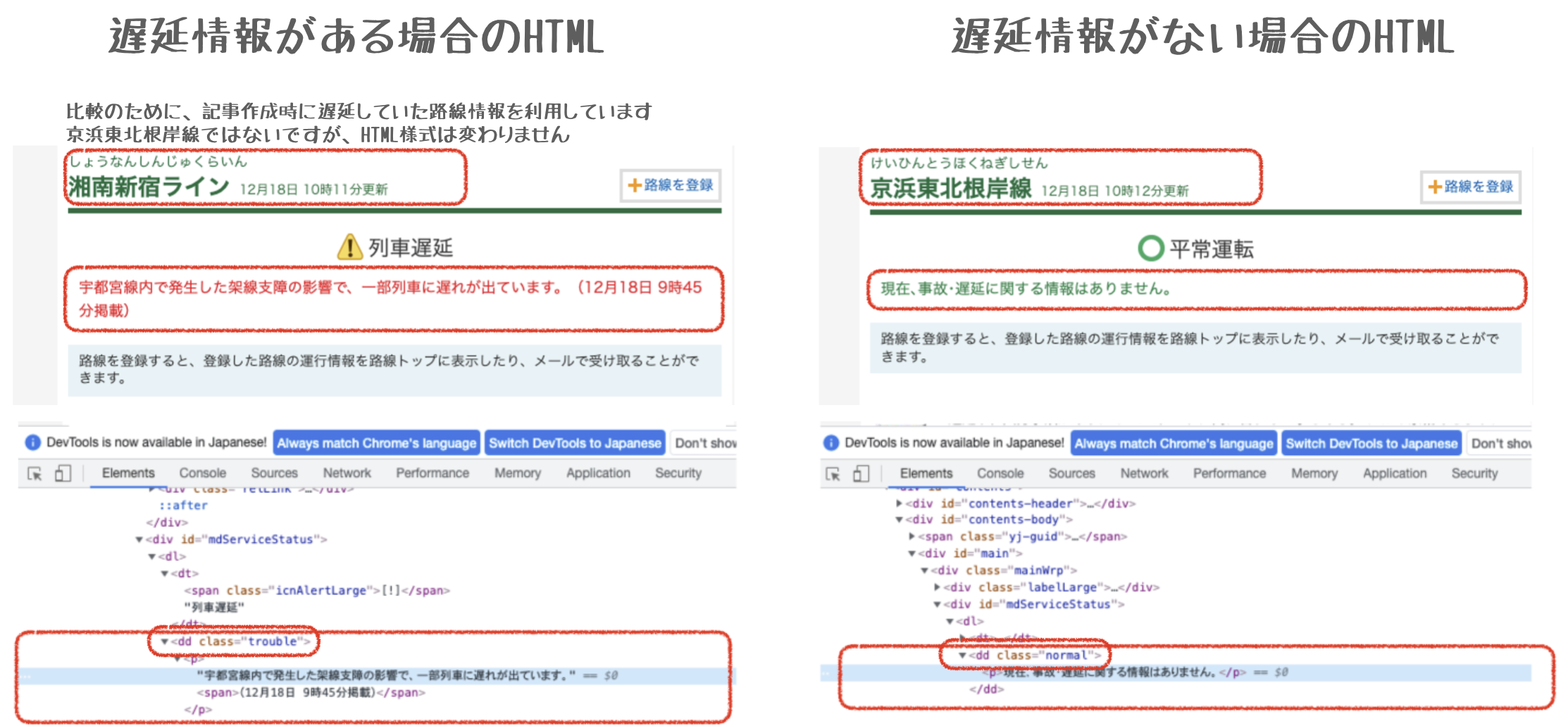
trouble_info = Soup.find('dd',class_='trouble')#.findでtroubleクラスのddタグを探す
# 運行状況ページに'trouble'があるかで条件を分岐する
if trouble_info in locals():#ローカルスコープの中にtrouble_infoの値が存在してれば実行
trouble_l = [i.strip() for i in trouble_info.txt.splitlines()]#troubleをリストにする
message = [i for i in trouble_l if i != ""]#リストの文字前後を削除して文章整形
delay_information_send("\n" + "京浜東北線は" + message[0])#遅延理由のメッセージ
else:
delay_information_send("\n" + '京浜東北線は通常運転です')#何も無い場合のコメント
if __name__ == "__main__":
Extract_delay_information()
3:部分的な説明
1:Extract_delay_information関数のページ取得について
# スクレイピングして運行状況ページの抽出
def Extract_delay_information():
url ='https://transit.yahoo.co.jp/diainfo/22/0'#京浜東北線の運行状況のURL
r = requests.get(url)#Requestsを利用してWebページを取得する
Soup = BeautifulSoup(r.text, 'html.parser')# BeautifulSoupを利用してWebページ解析
trouble_info = Soup.find('dd',class_='trouble')#.findでtroubleクラスのddタグを探す
3.1.1 取得するページを変数に値を代入
変数URLには取得したいページ(今回は京浜東北(根岸)線となります)の値を代入します
3.1.2 BeautifulSoup parserを利用してページ解析
Soup = BeautifulSoup(r.text, 'html.parser')# BeautifulSoupを利用してWebページ解析
上記URLにrequests.get(url)してURLを開き、取得した情報をparserによりHTMLで書式化されているテキストファイルを解析
3.1.3 find()を利用することでHTMLタグを検索する
trouble_info = Soup.find('dd',class_='trouble')#.findでtroubleクラスのddタグを探す
解析された情報から findを利用して引数を検索する
対象となるURLを開発者ツールで確認してみると__遅延がある場合__は<dd class="trouble">のなかに遅延情報が表示されるので、引数は上記の記述となる
因みに
| メソッド | 引数 | 内容 |
|---|---|---|
| find() | 検索するHTMLタグ | 引数に一致する最初の__1つ目__の要素を取得 |
| find_all() | 検索するHTMLタグ | 引数に一致する__全て__の要素を取得 |
2:Extract_delay_information関数の条件分岐について
# 運行状況ページに'trouble'があるかで条件を分岐する
if trouble_info in locals():#ローカルスコープの中にtrouble_infoの値が存在してれば実行
trouble_l = [i.strip() for i in trouble_info.txt.splitlines()]#troubleをリストにする
message = [i for i in trouble_l if i != ""]#リストの文字前後を削除して文章整形
delay_information_send("\n" + "京浜東北線は" + message[0])#遅延理由のメッセージ
else:
delay_information_send("\n" + '京浜東北線は通常運転です')#何も無い場合のコメント
3.2.1 取得したtrouble_infoに値がある場合(Class="trouble"の遅延情報がある)と、ない場合で条件分岐
存在する場合
# 運行状況ページに'trouble'があるかで条件を分岐する
if trouble_info in locals():#ローカルスコープの中にtrouble_infoの値が存在してれば実行
trouble_l = [i.strip() for i in trouble_info.txt.splitlines()]#troubleをリストにする
message = [i for i in trouble_l if i != ""]#リストの文字前後を削除して文章整形
delay_information_send("\n" + "京浜東北線は" + message[0])#遅延理由のメッセージ
find で取得したtrouble_infoをi.strip()にて両端(先頭、末尾)の文字を削除してリストにする
リストから[i for i in trouble_l if i != ""]で空白以外を抽出してmessageに代入する
messageリストの[0] をdelay_information_send関数の引数にする
存在しない場合
下記内容をdelay_information_send関数の引数にする
else:
delay_information_send("\n" + '京浜東北線は通常運転です')#何も無い場合のコメント
3:Extract_delay_information関数の条件分岐について
# LINENotifyにメッセージを送付
def delay_information_send(message):
payload = {'message': message}
headers = {'Authorization': 'Bearer ' + line_notify_token}
requests.post(line_notify_api, data=payload, headers=headers)
delay_information_send関数に送られてきた引数(message)を、LINENotifyに送信するための様式に整え、requests.postでメッセージを送る
4:挙動の確認
tetutetu214@mbp 0_Qiita_hanson % python train.py
上記打刻後LINEに下記通知がされたことを確認できます(今回の表示では練習用で取得した際の12月8日の京浜東北(根岸)線の遅延情報を切り貼りしています)
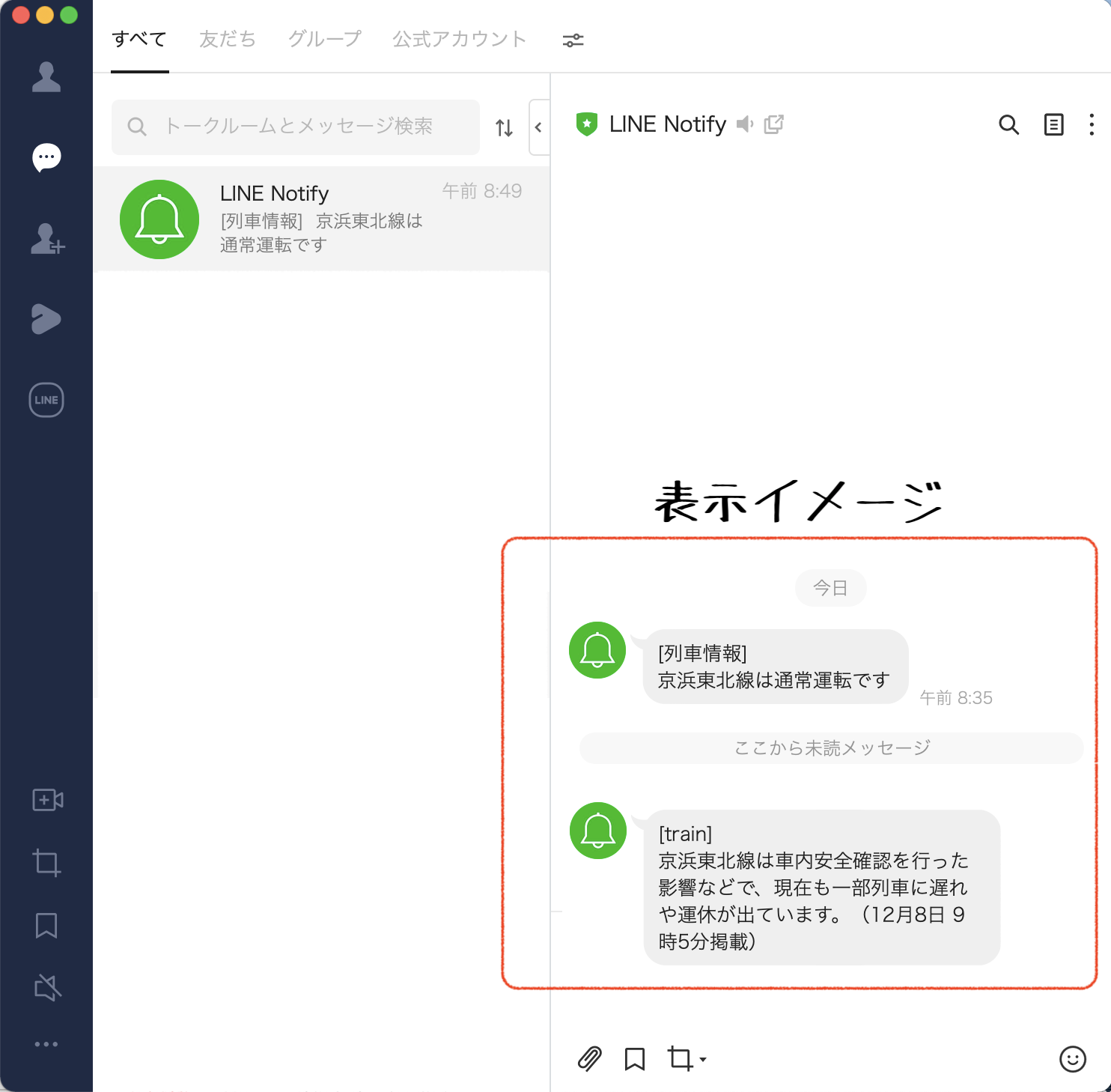
cronを利用すれば毎朝出勤する7時30分などの決まった時間に通知を送ることも可能です
さいごに
find,find_all部分の理解をより深めれば、より細かな情報の抽出が可能であるのでもう少し学習を深めていくこと、サービス的にはターミナルは動かせばLINEnotifyにメッセージが送られるものの、今の遅延情報を知りたい場合や、他の路線の情報が知りたい場合などの拡張性がない部分を今後は変更していきたいと思います。
より多くのサンタに使ってもらえるように、実態に沿ったサービスを作りたい所存でございました。