はじめに
弊社ブログに投稿があったらいちはやく反応したい気持ちから、自分のスマートフォンにLINE通知ができるような構築をしました。弊社ブログ以外にも、お気に入りのブログの更新などにも利用できそうな気がしています。
webスクレイピング(Python)で情報を取得していますが、サイトによってはスクレイピングの使用を禁止されている場合もありますので各ページの御利用規約等をご確認ください。
参考資料
参考リンクには今回作成した大元になる方のハンズオンです。こちらの漫画の部分を弊社ブログに変更して構築し直しましたが、なによりお手本があると大変助かり理解も捗りました。
構成図

ハンズオン
1:LINE Notifyでアクセストークンを発行する
下記リンクからご確認ください
天気予報情報をスクレイピング(Python)で、LINE NotifyによりLINE通知の構築
2:コードの記述
サンプルコード(コメントアウトで各動作の内容記述あり)
import requests #LINEへリクエスト
from bs4 import BeautifulSoup #スクレイピング
import os #環境変数のため
from dotenv import load_dotenv #環境変数のため
load_dotenv()
# LINE Notifyと連携するためのtoken
line_notify_token = os.getenv('NEWERARTICLES')#トークン直打ちでも可能
line_notify_api = 'https://notify-api.line.me/api/notify'#LINE Notifyへの通知URL
# LINENotifyにメッセージを送付
def update_the_article_send(message):
payload = {'message': message}
headers = {'Authorization': 'Bearer ' + line_notify_token}
requests.post(line_notify_api, data=payload, headers=headers)
# スクレイピングして最新ブログタイトルの抽出
def extract_the_latest_blog_titles():
url = 'https://cloud5.jp/'#スクレイピング対象弊社ブログURL
r = requests.get(url)#Requestsを利用してWebページを取得する
soup = BeautifulSoup(r.content, "html.parser")# BeautifulSoupを利用してWebページ解析
card = soup.find("h5",class_="card-title")#.findで一番最初のcard-titleクラスのタグを探す
card_title_list = [i.text.strip() for i in card]#取得したcard-titleリストにする
latest_article = [i for i in card_title_list if i != ""]#タイトルの前後から不要箇所削除
return latest_article[0]#ブログ最新のタイトルを返す
# 抽出したタイトルをblog_title_logログファイルに保存する
def determine_if_you_are_uptodate(content):
logfile_name = "blog_title_log.txt"#最新ブログタイトルを保存するファイル名を変数に代入
if not os.path.exists("./"+logfile_name):#同階層にタイトル保存ファイルはの存在するか
file = open(logfile_name, 'w')#存在しなければファイルを作成して開く
file = open(logfile_name, 'r')#ファイル読み取り開く
if file.readline() == content:#もし内容が今回取得したタイトルと同様かをチェックする
checker = False#同じの場合Falseで終了する
else:
checker = True#異なるの場合はTrueとして後述の動作をする
file = open(logfile_name, 'w')#ファイルを開く
file.write(content)#開いたファイルに最新タイトルを書き込む
file.close()#ファイルを閉じる
return checker#それぞれの判定(checker)を返す
# newer_articles.pyが呼び出された場合、下記の挙動をする
if __name__ == "__main__":
latest_article = extract_the_latest_blog_titles()#関数extract_the_latest_blog_titles()で取得した最新タイトル名を代入
if determine_if_you_are_uptodate(latest_article): #抽出したタイトルを関数Determine_if_you_are_uptodate()で判定して引数があった場合、後述の動作をする
update_the_article_send(latest_article)#checkerを引数にして関数update_the_article_send()を実行する
3:部分的な説明
1:関数update_the_article_send()でLINE Notifyでメッセージ通知を行う
import requests #LINEへリクエスト
from bs4 import BeautifulSoup #スクレイピング
import os #環境変数のため
from dotenv import load_dotenv #環境変数のため
load_dotenv()
# LINE Notifyと連携するためのtoken
line_notify_token = os.getenv('NEWERARTICLES')#トークン直打ちでも可能
line_notify_api = 'https://notify-api.line.me/api/notify'#LINE Notifyへの通知URL
# LINENotifyにメッセージを送付
def update_the_article_send(message):
payload = {'message': message}
headers = {'Authorization': 'Bearer ' + line_notify_token}
requests.post(line_notify_api, data=payload, headers=headers)
3.1.1
下記3.3.2における条件分岐の条件であるブログタイトルの更新があった場合は関数update_the_article_send()に引数(ブログの最新タイトル)が渡されmessageとしてLINE Notifyにrequests.postでメッセージが送付される
2:関数extract_the_latest_blog_titles()で対象webページの最新タイトルを検索してreturnする
# スクレイピングして最新ブログタイトルの抽出
def extract_the_latest_blog_titles():
url = 'https://cloud5.jp/'#スクレイピング対象弊社ブログURL
r = requests.get(url)#Requestsを利用してWebページを取得する
soup = BeautifulSoup(r.content, "html.parser")# BeautifulSoupを利用してWebページ解析
card = soup.find("h5",class_="card-title")#.findで一番最初のcard-titleクラスのタグを探す
card_title_list = [i.text.strip() for i in card]#取得したcard-titleリストにする
latest_article = [i for i in card_title_list if i != ""]#タイトルの前後から不要箇所削除
return latest_article[0]#ブログ最新のタイトルを返す
3.2.1
取得するページを変数に値を代入して、ブログにrequests.get(url)でgetリクエストを送る

3.2.2
BeautifulSoupを利用してページ解析
soup = BeautifulSoup(r.content, "html.parser")# BeautifulSoupを利用してWebページ解析
URLから取得した情報をparserにより解析をする
3.2.3
find()を利用してHTMLタグを検索する
card = soup.find("h5",class_="card-title")#.findで一番最初のcard-titleクラスのタグを探す
解析された情報から findを利用して引数を検索する
対象となるURLを開発者ツールで確認してみると__ブログのタイトル__は<h5 class="card-title"></h5>に含まれていることが確認できることから上記の記述をしています
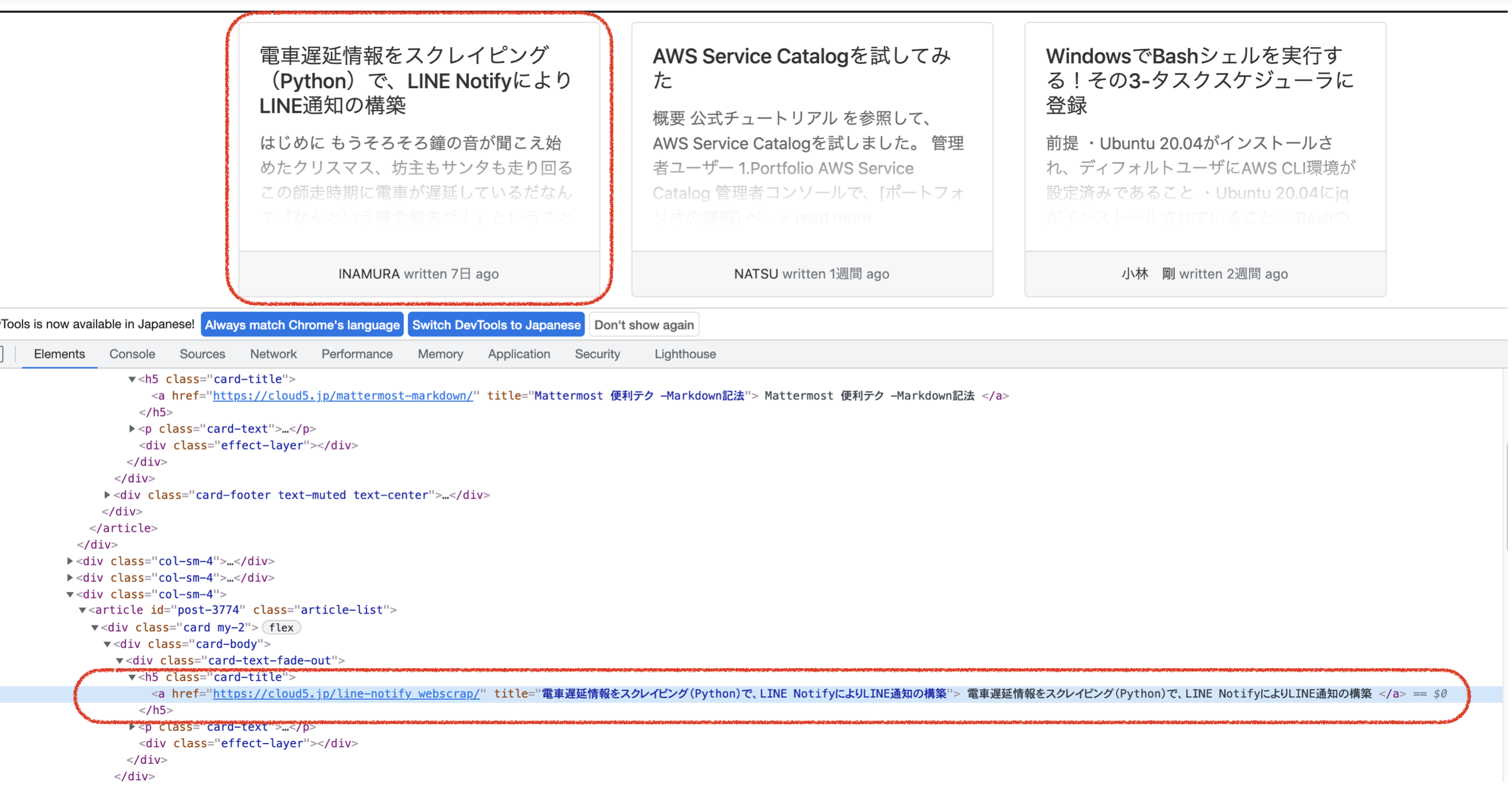
因みに
| メソッド | 引数 | 内容 |
|---|---|---|
| find() | 検索するHTMLタグ | 引数に一致する最初の__1つ目__の要素を取得 |
| find_all() | 検索するHTMLタグ | 引数に一致する__全て__の要素を取得 |
3.2.4
最新ブログタイトルをreturnで返す
card_title_list = [i.text.strip() for i in card]#取得したcard-titleリストにする
latest_article = [i for i in card_title_list if i != ""]#タイトルの前後から不要箇所削除
return latest_article[0]#ブログ最新のタイトルを返す
cardの変数を取り出しリスト化、リストにされた内容の値の前後にある不要な空白を削除して最新タイトルをreturnする
3:determine_if_you_are_uptodate()関数の条件分岐について
def determine_if_you_are_uptodate(content):
logfile_name = "blog_title_log.txt"#最新ブログタイトルを保存するファイル名を変数に代入
if not os.path.exists("./"+logfile_name):#同階層にタイトル保存ファイルはの存在するか
file = open(logfile_name, 'w')#存在しなければファイルを作成して開く
file = open(logfile_name, 'r')#ファイル読み取り開く
if file.readline() == content:#もし内容が今回取得したタイトルと同様かをチェックする
checker = False#同じの場合Falseで終了する
else:
checker = True#異なるの場合はTrueとして後述の動作をする
file = open(logfile_name, 'w')#ファイルを開く
file.write(content)#開いたファイルに最新タイトルを書き込む
file.close()#ファイルを閉じる
return checker#それぞれの判定(checker)を返す
3.3.1
最新ブログタイトルを保存するためのファイルがあるかの条件分岐をする、存在しない場合作成する
def determine_if_you_are_uptodate(content):
logfile_name = "blog_title_log.txt"#最新ブログタイトルを保存するファイル名を変数に代入
if not os.path.exists("./"+logfile_name):#同階層にタイトル保存ファイルはの存在するか
file = open(logfile_name, 'w')#存在しなければファイルを作成して開く
file = open(logfile_name, 'r')#ファイル読み取り開く
引数(最新タイトル)を受け取り"blog_title_log.txt(最新タイトル名を保存するテキスト)"が存在しているかを条件分岐(作成して開く、または開く)
3.3.2
ログと比較して以前保存したタイトルと異なる場合(変更されている=更新と捉えています)は、LINE Notifyにメッセージを送る判断をする
if file.readline() == content:#もし内容が今回取得したタイトルと同様かをチェックする
checker = False#同じの場合Falseで終了する
else:
checker = True#異なるの場合はTrueとして後述の動作をする
file = open(logfile_name, 'w')#ファイルを開く
file.write(content)#開いたファイルに最新タイトルを書き込む
file.close()#ファイルを閉じる
return checker#それぞれの判定(checker)を返す
file.readline()からログに記述されているタイトルと、今回取得したcontent(引数:latest_article[0])を比較して同じだった場合は__Falseで終了する
以前取得したブログタイトルと異なっている場合は取得したブログタイトルを書き込み、True__として後続の処理である、関数update_the_article_send()でLINE Notifyでメッセージ通知を行うを実行する
4:挙動の確認
サンプルという記事をアップしてターミナルで押下する

tetutetu214@mbp 0_Qiita_hanson % python newer_articles.py
LINEの通知された画面

cronを利用すれば毎朝出勤する7時30分などの決まった時間にwebページの確認し、更新されている場合はLINEに通知をすることが可能です
さいごに
弊社ブログにRSSが見当たらなかったので、webスクレイピングで情報を取得してみました。最新のタイトルをログファイルに保存して比較しているだけですが、なんとなくいい感じの挙動をしてくれています。年末年始にかけてもっと手を動かしながら、コード理解を深めていきたいと思います。