実行環境
- Google Colaboratory, Python 3.8
- 使用ライブラリ: pandas, numpy, matplotlib, sklearn, vaderSentiment, datetime, yahoo_finance_api2, requests,LinearRegression, SVR, RandomForestRegressor, mean_squared_error, r2_score
- API: Yahoo Finance, NewsAPI
目次
- イントロダクション
- データ取得と準備
- 分析
- 結果
- 考察
- 課題と苦労した点
イントロダクション
こんにちは!
私は機械学習を学び始めたばかりの初心者ですが、今回はじめて記事を投稿します。
これまで学んだ知識の初のアウトプットとして、課題設定から分析まで一貫して実施した内容になっております。
今回の取り組みでは、ニュース記事のヘッドラインについて感情分析行い、株価との関連性を見出して予測モデルの構築に挑戦しました。
ただし、非常に限られた情報リソースを用いており、高い精度の予測モデルを作るというよりは、データ分析の基本的な手法を実践し、初心者でもモデル構築と予測までなんとかやりきるということが目標でした。
感情分析の対象としてはSNSも一般的ですが、同じく一般的なニュースヘッドラインを今回対象としました。私自身も米国市場に投資していることから、NASDAQ上場の主要な企業であるApple、Tesla、Nvidiaを分析対象としました。
*このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています
データ取得と準備
このプロジェクトの最初のステップは、必要なデータを集めることでした。今回はNASDAQ上場の海外企業が対象ということで、株価データについてはYahoo Finance API https://pypi.org/project/yfinance/ を使って、Apple、Tesla、Nvidiaの直近一か月分のものを取得しました。
ニュース記事については、NewsAPI https://newsapi.org/ を利用して同じ期間のニュースヘッドラインも収集しました。
結果的にこのステップで最も苦労して時間を費やしてしまいました。APIの制限、データ同士の期間ズレ、データ型のズレなどに苦労しました。
株価データ取得のコード
ライブラリのインストール
pip install yahoo-finance-api2を使用して、yahoo-finance-api2という名前のPythonライブラリをインストールします。このライブラリは、Yahoo Financeから金融データを取得するための便利なツールを提供しています。
モジュールのインポート
yahoo_finance_api2モジュールからshareとYahooFinanceErrorをインポートしています。shareは株式関連のデータを取得するためのクラスであり、YahooFinanceErrorはエラー処理のための例外クラスです。
shareクラス~Yahoo Finance APIを使用するためのクラス~
shareクラスを使用することで、特定の銘柄や指標に関する金融データを取得できます。このクラスは以下の機能を提供します。
株価データの取得(時系列データ)
企業情報の取得(プロフィール、業績、配当など)
ニュース記事の取得
ヒストリカルデータの取得
YahooFinanceError~例外処理~
YahooFinanceErrorは、Yahoo Finance APIからのデータ取得時に発生する可能性があるエラーを処理するための例外です。エラーが発生した場合、適切に処理するために使用されます。
それではまず yahoo financeからApiを利用して直近一か月間の終値を取得します。 なお、無料では過去30日間より以前の日次株価データを取得することが制限されています。 今回は無料の範囲で行います。
それでは先ず株価の取得からです。
# ライブラリのインストール:
!pip install yahoo-finance-api2
# 必要な基本的なモジュールをインポート
from datetime import datetime
import pandas as pd
import numpy as np
# yahoo_finance_api2モジュールから必要なクラスをインポート
from yahoo_finance_api2 import share #株式関連のデータを取得するためのクラス
from yahoo_finance_api2.exceptions import YahooFinanceError #エラー処理のための例外クラス
# ティッカーシンボルのリストを作成
symbols = ['AAPL', 'TSLA', 'NVDA']
# データを格納するためのデータフレームを初期化
all_data = pd.DataFrame()
# 各企業の株価データを取得してデータフレームに追加
for symbol in symbols:
my_share = share.Share(symbol)
symbol_data = None
try:
symbol_data = my_share.get_historical(share.PERIOD_TYPE_DAY,
35,
share.FREQUENCY_TYPE_DAY,
1)
except YahooFinanceError as e:
print(f"Error for {symbol}: {e.message}")
continue
data = symbol_data['timestamp']
price = symbol_data['close']
new_data = [datetime.utcfromtimestamp(int(data[i] / 1000)) for i in range(len(data))]
symbol_df = pd.DataFrame({'Date': new_data, f'Price_{symbol}': price})
if all_data.empty:
all_data = symbol_df
else:
all_data = all_data.merge(symbol_df, on='Date', how='left')
#"date_ymd"カラムを追加、datetime.dateオブジェクトのnumpy配列を格納
all_data["date_ymd"] = all_data["Date"].dt.date
# カラム "date" をインデックスに変換
all_data = all_data.set_index('date_ymd')
# 不要カラム削除
all_data.drop("Date", axis=1, inplace=True)
all_data.to_csv('all_data.csv')
このような形でApple、Tesla、Nvidiaの直近一か月の株価終値を格納したデータフレームが得られました。
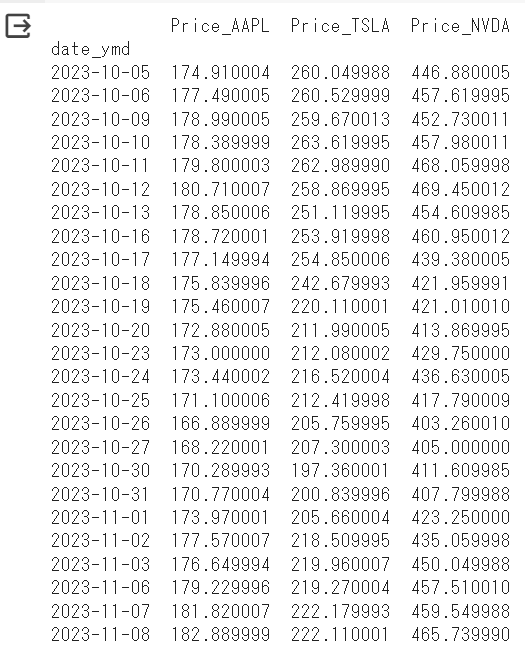
それでは一旦、これを可視化して値動きを確認してみたいと思います。
# 可視化 その1~そのままの値
import matplotlib.pyplot as plt
# データを設定
date = all_data.index
price_AAPL = all_data['Price_AAPL']
price_TSLA = all_data['Price_TSLA']
price_NVDA = all_data['Price_NVDA']
# グラフを作成
plt.figure(figsize=(12, 6))
plt.plot(date, price_AAPL, label='Apple (AAPL)', linestyle='-', marker='o')
plt.plot(date, price_TSLA, label='Tesla (TSLA)', linestyle='-', marker='o')
plt.plot(date, price_NVDA, label='NVIDIA (NVDA)', linestyle='-', marker='o')
# グラフのタイトルと軸ラベルを設定
plt.title('Stock Prices Over Time')
plt.xlabel('Date')
plt.ylabel('Price')
# 凡例を表示
plt.legend()
# x軸の日付を見やすくする
plt.gcf().autofmt_xdate()
# グラフを表示
plt.show()
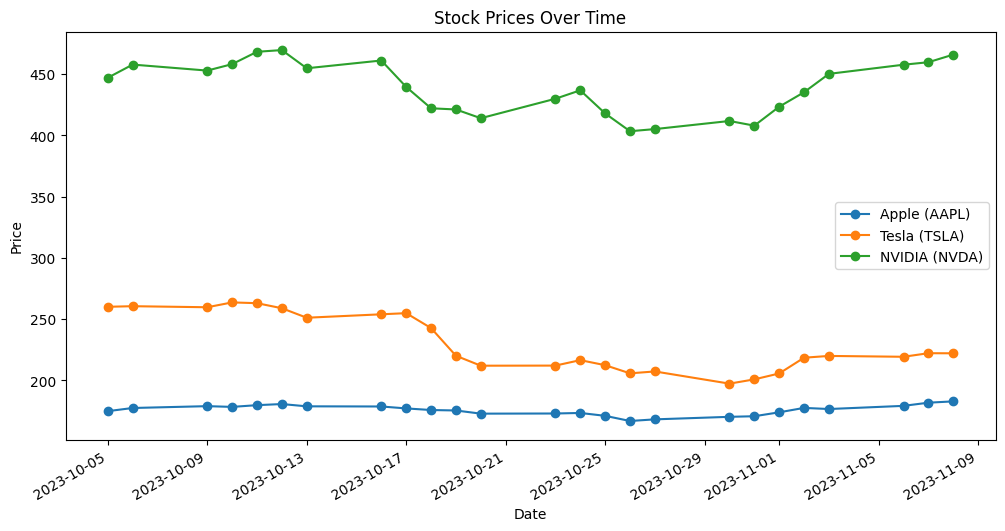
株価は其々の企業でバラバラなので、日ごとの株価変動の比較がしやすいように標準化してもう一度可視化してみます。
# 可視化パターンその2 ~標準化して比較
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
# データを設定
date = all_data.index
price_AAPL = all_data['Price_AAPL']
price_TSLA = all_data['Price_TSLA']
price_NVDA = all_data['Price_NVDA']
# データの標準化
scaler = StandardScaler()
price_AAPL_std = scaler.fit_transform(price_AAPL.values.reshape(-1, 1))
price_TSLA_std = scaler.fit_transform(price_TSLA.values.reshape(-1, 1))
price_NVDA_std = scaler.fit_transform(price_NVDA.values.reshape(-1, 1))
# グラフを作成
plt.figure(figsize=(12, 6))
plt.plot(date, price_AAPL_std, label='Apple (AAPL)', linestyle='-', marker='o')
plt.plot(date, price_TSLA_std, label='Tesla (TSLA)', linestyle='-', marker='o')
plt.plot(date, price_NVDA_std, label='NVIDIA (NVDA)', linestyle='-', marker='o')
# グラフのタイトルと軸ラベルを設定
plt.title('Standardized Stock Prices Over Time')
plt.xlabel('Date')
plt.ylabel('Standardized Price')
# 凡例を表示
plt.legend()
# x軸の日付を見やすくする
plt.gcf().autofmt_xdate()
# グラフを表示
plt.show()
この期間では変動の様子は3社とも似通っているようです。
感情分析
次に、ニュースヘッドラインの感情分析を行いました。ここでのポイントは、ニュースのポジティブまたはネガティブな感情が株価にどのように影響を及ぼすかを見極めること。このために、vaderSentiment ライブラリを使用して、各ニュース記事のPN値を計算しました。
株価データと組み合わせることで、感情値と株価の関連性を分析する準備が整えました。
VADER(Valence Aware Dictionary for Sentiment Reasoning)は、感情の極性(ポジティブ/ネガティブ)と強度(感情の強さ)の両方に敏感な、テキストのセンチメント分析に使用されるモデルです。NLTKパッケージで利用可能で、ラベルのないテキストデータに直接適用することができます。
VADERのセンチメント分析は、辞書に基づいており、これは感情の強度を示すセンチメントスコアに言語的特徴をマッピングします。テキストのセンチメントスコアは、テキスト内の各単語の強度を合計することによって得られます。
例えば、「love」、「enjoy」、「happy」、「like」などの言葉はすべてポジティブな感情を伝えます。また、VADERはこれらの言葉の基本的な文脈を理解するのに十分な知能を持っており、「did not love」をネガティブな表現として捉えることができます。さらに、「ENJOY」のような大文字や句読点の強調も理解します。
https://pypi.org/project/vaderSentiment/
# ステップ1: 必要なライブラリのインストール
!pip install requests
# ステップ2: NewsAPIを使用してニュース記事を取得する関数を定義
import requests
from datetime import datetime, timedelta
import pandas as pd
def get_news_articles(api_key, company, from_date, to_date):
url = f'https://newsapi.org/v2/everything?q={company}&from={from_date}&to={to_date}&apiKey={api_key}'
response = requests.get(url)
data = response.json()
articles = data['articles']
return articles
# 過去30日間の日付を計算(NewsAPIの無料プランでは、過去30日間の記事のみを取得できる)
# 過去30日間の記事を取得するために、NewsAPIのeverythingエンドポイントを使用し、fromおよびtoパラメータを追加して指定
to_date = datetime.now().date()
from_date = to_date - timedelta(days=30)
from_date_str = from_date.strftime('%Y-%m-%d')
to_date_str = to_date.strftime('%Y-%m-%d')
# NewsAPIのAPIキー
api_key = "取得したAPIキーを入力"
# ステップ3: 特定の企業に関するニュース記事を取得
# アップル、テスラ、エヌビディアを指定
companies = ['apple', 'tesla', 'nvidia']
# ニュース記事をデータフレームに格納
data = {'Company': [], 'date': [], 'Headline': []}
for company in companies:
news_articles = get_news_articles(api_key, company, from_date_str, to_date_str)
for article in news_articles:
data['Company'].append(company)
data['date'].append(article['publishedAt'])
data['Headline'].append(article['title'])
df = pd.DataFrame(data)
# カラム "date" のデータタイプを datetime 型に変換
df['date'] = pd.to_datetime(df['date'])
# カラム "date" のデータタイプを確認
data_type = df['date'].dtype
print("Data Type of 'date' column:", data_type)
#"datetime.dateオブジェクトのnumpy配列を格納
df["date_ymd"] = pd.to_datetime(df["date"].dt.date)
# カラム "date_ymd" をインデックスに変換
df = df.set_index('date_ymd')
# 不要カラム削除
df.drop("date", axis=1, inplace=True)
# "company" カラムで昇順に並び替え、その後インデックスで並び替え
df = df.sort_values(by=['Company', 'date_ymd'], ascending=[True, True])
# データフレームを表示
df
企業毎に、その企業に関するニュースのヘッドラインと日付を格納したデータフレームが得られました
次は特定の企業に係らないすべての経済ニュースのヘッドライン記事を取得します。
#特定の企業に係らないすべての経済ニュース
import requests
from datetime import datetime, timedelta
import pandas as pd
def get_economic_news(api_key, from_date, to_date):
url = f'https://newsapi.org/v2/everything?q=economy&from={from_date}&to={to_date}&apiKey={api_key}'
response = requests.get(url)
data = response.json()
articles = data['articles']
return articles
# 過去30日間の日付を計算
to_date = datetime.now().date()
from_date = to_date - timedelta(days=30)
from_date_str = from_date.strftime('%Y-%m-%d')
to_date_str = to_date.strftime('%Y-%m-%d')
#NewsAPIのAPIキー
api_key = "NewsAPIのAPIキー"
economic_news = get_economic_news(api_key, from_date_str, to_date_str)
# ニュース記事をデータフレームに格納
data = {'date': [], 'Headline': []}
for article in economic_news:
data['date'].append(article['publishedAt'])
data['Headline'].append(article['title'])
df_all = pd.DataFrame(data)
# カラム "date" のデータタイプを datetime 型に変換
df_all['date'] = pd.to_datetime(df_all['date'])
# カラム "date" のデータタイプを確認
data_type = df_all['date'].dtype
print("Data Type of 'date' column:", data_type)
#"date_ymd"カラムを追加、%Y-%m-%dのdatetimeを格納
df_all["date_ymd"] = pd.to_datetime(df_all["date"].dt.date)
# カラム "date" をインデックスに変換
df_all = df_all.set_index('date_ymd')
# 不要カラム削除
df_all.drop("date", axis=1, inplace=True)
# インデックスを昇順に並び替え
df_all.sort_index(inplace=True)
# データフレームを表示
df_all
特定の企業に係らないすべての経済ニュースのヘッドライン記事を取得しました。
それでは取得したニュースのヘッドラインについて感情分析を行いPN値を取得します。
# 感情分析
!pip install vaderSentiment
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
from nltk.sentiment.vader import SentimentIntensityAnalyzer
import nltk
nltk.download("vader_lexicon")
# SentimentIntensityAnalyzerオブジェクトを作成
sia = SentimentIntensityAnalyzer()
# 関数1_データフレームの「Headline」カラム内の各テキストをトークン化し、各単語に対してPN値を計算、結果を新しいカラム「PN_value」に格納
# テキストの各単語に対してPN値を計算する関数を定義
def calculate_mean_pn(text):
word_pn_values = [sia.polarity_scores(word)['compound'] for word in text.split()]
return sum(word_pn_values) / len(word_pn_values) if len(word_pn_values) > 0 else 0
# 関数2_テキスト全体のPN値を計算する関数を定義
def calculate_pn_text(text):
analyzer = SentimentIntensityAnalyzer()
sentiment = analyzer.polarity_scores(text)
return sentiment['compound']
# 関数1 applyメソッドで使用、新しいカラム「PN_value_mean」を計算
df_all['PN_value_mean'] = df_all['Headline'].apply(calculate_mean_pn)
# 関数2 カラム "Headline" のテキスト全体に対してPN値を計算、新しいカラム「PN_value_mean」に格納
df_all['PN_value_text'] = df_all['Headline'].apply(calculate_pn_text)
# 各ニュースヘッドラインの日毎の平均PN値を計算(関数1と2の両方)
average_pn_values_mean = df_all.groupby('date_ymd')['PN_value_mean'].mean().reset_index()
average_pn_values_text = df_all.groupby('date_ymd')['PN_value_text'].mean().reset_index()
# 2つの平均PN値を元のデータフレームにマージ
df_PN_by_day = pd.merge(average_pn_values_mean, average_pn_values_text,on='date_ymd',how="left")
df_PN_by_day = df_PN_by_day.set_index('date_ymd')
df_PN_by_day
# 関数1 applyメソッドで使用、新しいカラム「PN_value_mean」を計算
df['PN_value_mean'] = df['Headline'].apply(calculate_mean_pn)
# 関数2 カラム "Headline" のテキスト全体に対してPN値を計算、新しいカラム「PN_value_mean」に格納
df['PN_value_text'] = df['Headline'].apply(calculate_pn_text)
# 各ニュースヘッドラインの日毎の平均PN値を計算(関数1と2の両方)
average_pn_values_mean_co = df.groupby(['Company','date_ymd'])['PN_value_mean'].mean().reset_index().set_index('date_ymd')
average_pn_values_text_co = df.groupby(['Company','date_ymd'])['PN_value_text'].mean().reset_index().set_index('date_ymd')
# 2つの平均PN値を元のデータフレームにマージ
# df_PN_by_day_by_co = pd.merge(average_pn_values_mean_co, average_pn_values_text_co, left_index=True, right_index=True)
# df2のカラム名を変更
average_pn_values_text_co.rename(columns={'Company': 'Company_text_co'}, inplace=True)
# 2つのデータフレームを行方向に結合
df_PN_by_day_co = pd.concat([average_pn_values_mean_co, average_pn_values_text_co], axis=1)
# 結合後の重複カラム削除
df_PN_by_day_co.drop("Company_text_co", axis=1, inplace=True)
# "company" カラムで昇順に並び替え、その後インデックスで並び替え
df_PN_by_day_co = df_PN_by_day_co.sort_values(by=['Company', 'date_ymd'], ascending=[True, True])
# "Company"カラムの値ごとにデータフレームを分割して辞書に格納
company_dataframes = {}
for company, group_df in df_PN_by_day_co.groupby('Company'):
group_df.rename(columns={'PN_value_mean': f'PN_value_mean_{company}', 'PN_value_text': f'PN_value_text_{company}'}, inplace=True)
company_dataframes[company] = group_df
company_dataframes["apple"].index
#可視化
from matplotlib import pyplot as plt
import seaborn as sns
#特定の企業に係らないすべての経済ニュースのPN値
fig, ax = plt.subplots(figsize=(10, 5.2))
xs = df_PN_by_day.index # 'date_ymd'をインデックスとして使用
ys1 = df_PN_by_day['PN_value_mean'] # 'PN_value_mean'をプロット
ys2 = df_PN_by_day['PN_value_text'] # 'PN_value_text'をプロット
plt.plot(xs, ys1, label='PN_value_mean', linestyle='-', marker='o')
plt.plot(xs, ys2, label='PN_value_text', linestyle='-', marker='^')
# df_sorted = df_PN_by_day_co.sort_index(ascending=True) # インデックスでソート
plt.legend(title='All', bbox_to_anchor=(1, 1), loc='upper left')
sns.despine(fig=fig, ax=ax)
plt.xlabel('date_ymd')
plt.ylabel('PN_value')
plt.xticks(rotation=45) # x軸の日付ラベルを回転して読みやすくする
plt.show()
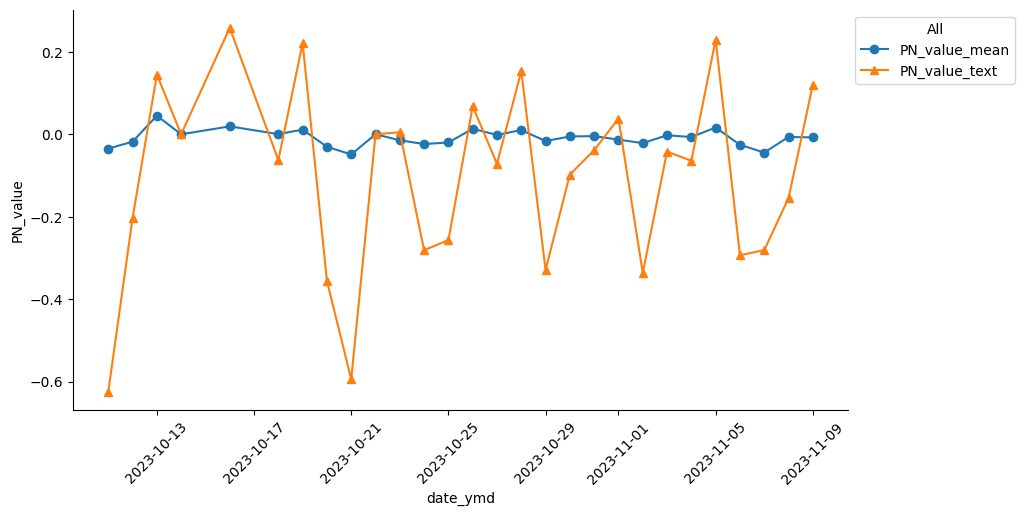
#特定の企業に関するニュースのPN値 アップル、テスラ、エヌビディア
def _plot_series(_df, _df_name, _df_index=0):
palette = list(sns.color_palette('Dark2'))
xs = _df.index # 'date_ymd'をインデックスとして使用
ys1 = _df['PN_value_mean'] # 'PN_value_mean'をプロット
ys2 = _df['PN_value_text'] # 'PN_value_text'をプロット
fig, ax1 = plt.subplots(figsize=(10, 5.2))
ax2 = ax1.twinx() # 2つ目のy軸を作成
ax1.plot(xs, ys1, label=_df_name, color=palette[_df_index % len(palette)])
ax2.plot(xs, ys2, label=_df_name, color=palette[(_df_index + 1) % len(palette)])
plt.legend(title='Company', bbox_to_anchor=(1, 1), loc='upper left')
# sns.despine(fig=fig, ax=ax)
plt.xlabel('date_ymd')
plt.xticks(rotation=45) # x軸の日付ラベルを回転して読みやすくする
plt.show()
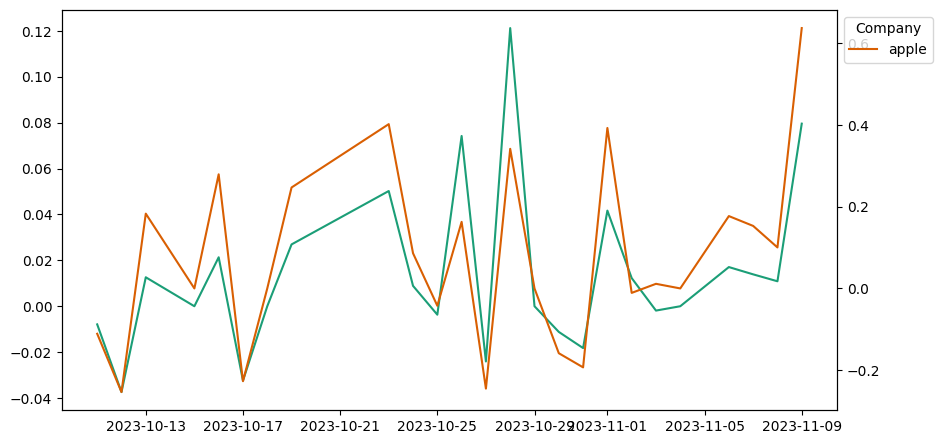
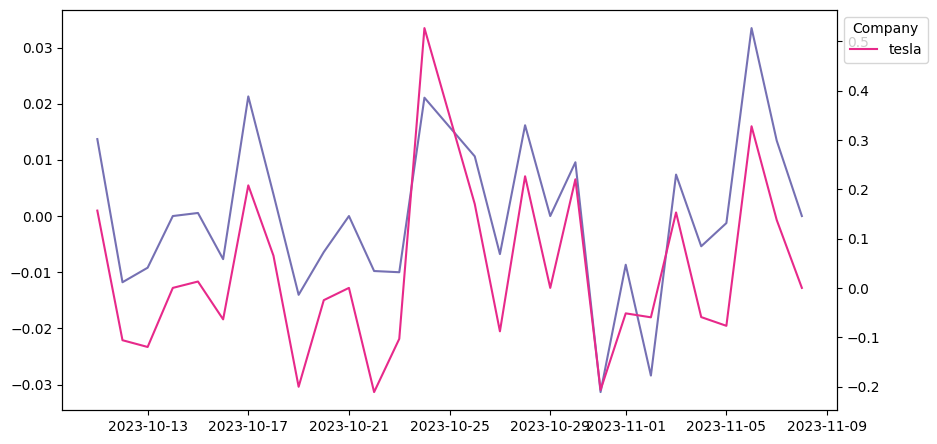
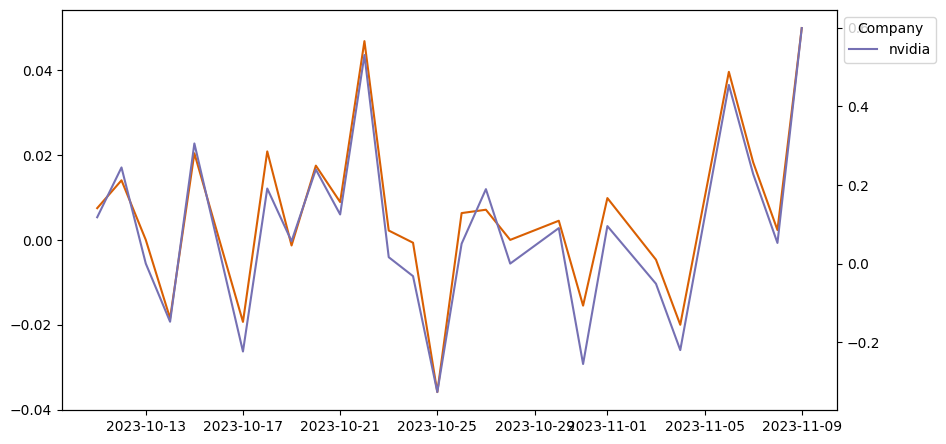
これまで得た分析結果をすべてまとめて一つのデータフレームにします。
df_sorted = df_PN_by_day_co.sort_index(ascending=True) # インデックスでソート
for i, (series_name, series) in enumerate(df_sorted.groupby('Company')):
_plot_series(series, series_name, i)
all_data = pd.read_csv('/content/all_data.csv')
# date_ymdを日付型に変換
all_data["date_ymd"] = pd.to_datetime(all_data["date_ymd"])
all_data = all_data.set_index("date_ymd")
# all_dataとdf_PN_by_dayをマージ
merged_df = all_data.merge(df_PN_by_day, left_index=True, right_index=False, how='left')
# company_dataframes["apple"]とcompany_dataframes["nvidia"]をマージ
merged_df = merged_df.merge(company_dataframes["apple"], left_index=True, right_index=True, how='left')
merged_df = merged_df.merge(company_dataframes["nvidia"], left_index=True, right_index=True, how='left')
# company_dataframes["tesla"]をマージ
merged_df = merged_df.merge(company_dataframes["tesla"], left_index=True, right_index=True, how='left')
# データフレームのリストを作成
dataframes = [all_data, df_PN_by_day, company_dataframes["apple"], company_dataframes["nvidia"], company_dataframes["tesla"]]
# # すべてのデータフレームを外部結合(outer join)します。
# result = all_data.join([df_PN_by_day, company_dataframes["apple"], company_dataframes["nvidia"], company_dataframes["tesla"]], how='outer')
# 5つのデータフレームを順に結合する
merged_df = dataframes[0]
for df in dataframes[1:]:
merged_df = pd.merge(merged_df, df, left_index=True, right_index=True, how='left')
merged_df
merged_df.to_csv('merged_df.csv')
# データフレームのリストを作成
dataframes = [all_data, df_PN_by_day, company_dataframes["apple"], company_dataframes["nvidia"], company_dataframes["tesla"]]
# 5つのデータフレームを順に結合する
merged_df = dataframes[0]
for df in dataframes[1:]:
merged_df = pd.merge(merged_df, df, left_index=True, right_index=True, how='left')
print(merged_df)
対象の企業の株価と感情分析結果をマージしたデータフレーム
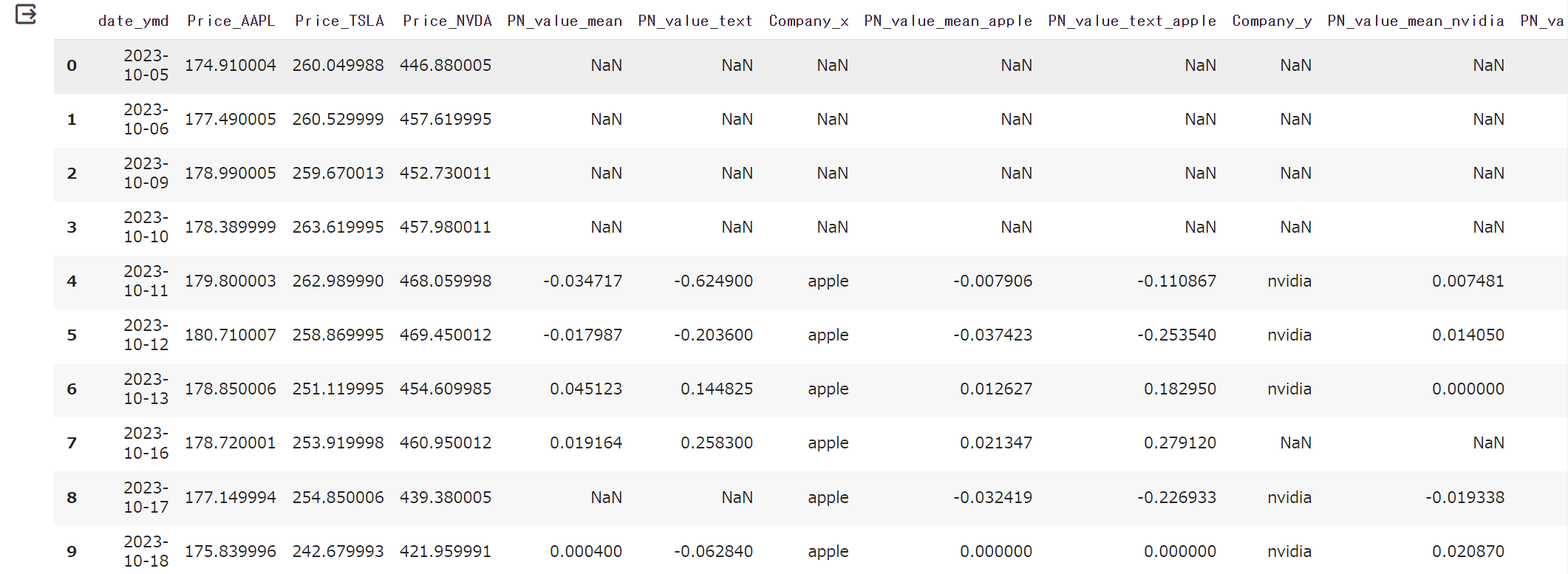
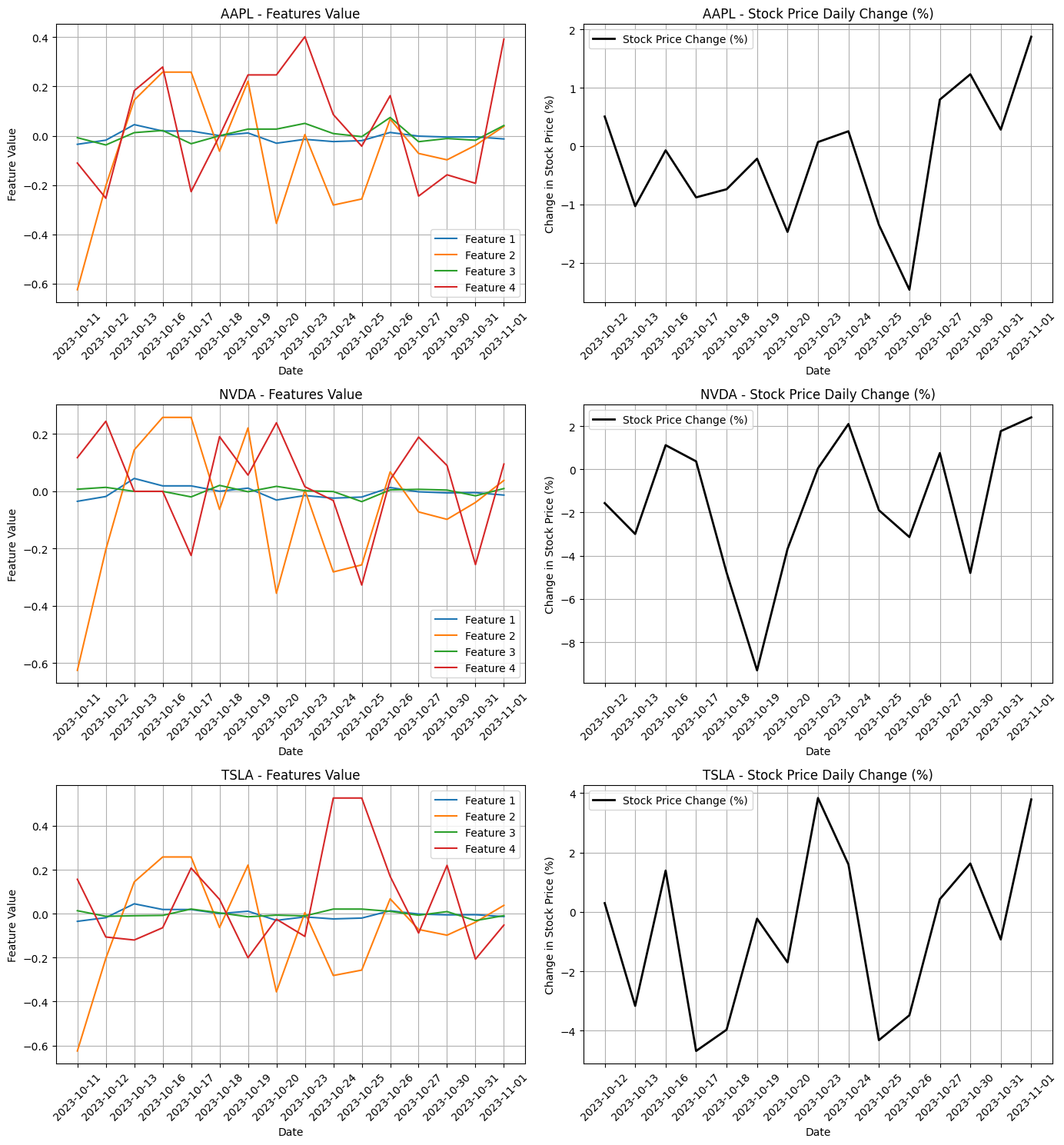
それではこのデータフレームについて欠損値処理等を行い整えた後、3企業それぞれについて4種類のPN値の変動、これに対応する株価の変動を並べて可視化してみます。
# 不要な会社名のカラムをドロップ
df = df.drop(['Company_x', 'Company_y', 'Company'], axis=1)
#欠損値処理
#「ニュースがなかった日はその前のニュースの影響が継続」とみなし'ffill'で補填
df = df.fillna(method='ffill', axis=0)
# 5行目(インデックス4)から最後までを取り出す、インデックスリセット
df = pd.DataFrame(df.iloc[4:]).reset_index(drop=True)
df.to_csv('stock_pn_prediction')
# Xに説明変数PN値を格納
# PN_value_mean全体 PN_value_text全体 PN_value_mean_企業 PN_value_text_企業 の順番
X_aapl = df.iloc[:, [4, 5, 6, 7]].to_numpy()
X_nvda = df.iloc[:, [4, 5, 8, 9]].to_numpy()
X_tsla = df.iloc[:, [4, 5, 10, 11]].to_numpy()
X_list = [X_aapl, X_nvda, X_tsla]
# yに目的変数の株価終値を格納
y_aapl = df.values[:, 1]
y_nvda = df.values[:, 2]
y_tsla = df.values[:, 3]
y_list = [y_aapl, y_nvda, y_tsla]
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
fig, axs = plt.subplots(nrows=3, ncols=2, figsize=(14, 15))
company_names = ["AAPL", "NVDA", "TSLA"]
for i, (X, y, company) in enumerate(zip(X_list, y_list, company_names)):
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False, random_state=42)
# yの前日との変化割合(%)を計算 (差分ではなく変化率)
y_train_diff = np.diff(y_train, axis=0) / y_train[:-1] * 100
# 特徴量をプロット
ax1 = axs[i, 0]
for j in range(X_train.shape[1]):
ax1.plot(df["date_ymd"][:len(X_train)], X_train[:, j], label=f'Feature {j+1}')
ax1.set_title(f'{company} - Features Value')
ax1.set_xlabel('Date')
ax1.set_ylabel('Feature Value')
ax1.legend()
ax1.grid(True)
ax1.tick_params(axis='x', rotation=45)
# 株価の変化量をプロット
ax2 = axs[i, 1]
ax2.plot(df["date_ymd"][1:len(y_train)], y_train_diff, label='Stock Price Change (%)', linewidth=2, color='black')
ax2.set_title(f'{company} - Stock Price Daily Change (%)')
ax2.set_xlabel('Date')
ax2.set_ylabel('Change in Stock Price (%)')
ax2.legend()
ax2.grid(True)
ax2.tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()
各社ともにFeature2,Feature4、つまりテキスト全体について計算して得たPM値の方が株価を説明できそうです。この二つを説明変数として次のステップで機械学習を行うことにしました。
結果
分析の結果、特定の感情値が株価の動きに影響を与えている可能性が見られました。線形回帰、サポートベクターマシン、ランダムフォレストといった様々なモデルを試してみたところ、一部のモデルでは株価変動の傾向を捉えることができました。
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
data = df
def build_and_evaluate_model(data, target_column, feature_columns):
# 目的変数と説明変数を選択
# y = data[target_column]
y = np.diff(data[target_column], axis=0) / data[target_column][:-1] * 100
X = data[feature_columns].iloc[1:] # 最初の要素を除外
dates = data['date_ymd'].iloc[1:] # 最初の要素を除外 # 日付データ
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test, dates_train, dates_test = train_test_split(
X, y, dates, test_size=0.2, shuffle=False, random_state=42
)
# y_train = np.diff(y_train, axis=0) / y_train[:-1] * 100
# y_test = np.diff(y_train, axis=0) / y_train[:-1] * 100
# モデルの構築と訓練
models = {
'Linear Regression': LinearRegression(),
'SVR': SVR(),
'Random Forest Regressor': RandomForestRegressor()
}
predictions = {}
mse_scores = {}
r2_scores = {}
for name, model in models.items():
model.fit(X_train, y_train)
predictions[name] = model.predict(X_test)
mse_scores[name] = mean_squared_error(y_test, predictions[name])
r2_scores[name] = r2_score(y_test, predictions[name])
# 結果を表示するための図を作成
plt.figure(figsize=(10, 8))
# 結果の可視化1:モデルのMSEとR^2
plt.subplot(2, 1, 1)
plt.bar(mse_scores.keys(), mse_scores.values(), label='MSE')
plt.bar(r2_scores.keys(), r2_scores.values(), label='R^2 Score')
plt.xlabel('Model')
plt.ylabel('Scores')
plt.title(f'{target_column} Stock Price Prediction MSE & R^2 Score')
plt.legend()
# 結果の可視化2:実際の価格と予測価格
plt.subplot(2, 1, 2)
plt.plot(dates, y, label='Training Data', color='blue', alpha=0.4) # 学習期間のデータをプロット
plt.plot(dates_test, y_test, label='Actual Price', color='blue', alpha=0.9) # 実際の価格をプロット
for name, pred in predictions.items():
plt.plot(dates_test, pred, label=f'Predicted by {name}', alpha=0.9) # 各モデルによる予測価格をプロット
plt.xlabel('Date')
plt.ylabel('Stock Price')
plt.title(f'{target_column} Stock Price Prediction')
plt.xticks(rotation=45)
plt.legend()
plt.tight_layout()
return mse_scores, r2_scores
# AAPLの株価予測
aapl_accuracies = build_and_evaluate_model(
data, 'Price_AAPL', ['PN_value_text'] #PN_value_mean, 'PN_value_text',
)
# TSLAの株価予測
tsla_accuracies = build_and_evaluate_model(
data, 'Price_TSLA', ['PN_value_text_tesla','PN_value_text'] #, 'PN_value_text',PN_value_text_tesla
)
# NVDAの株価予測
nvda_accuracies = build_and_evaluate_model(
data, 'Price_NVDA', ['PN_value_text_nvidia','PN_value_text'] #, 'PN_value_text',PN_value_text_nvidia
)
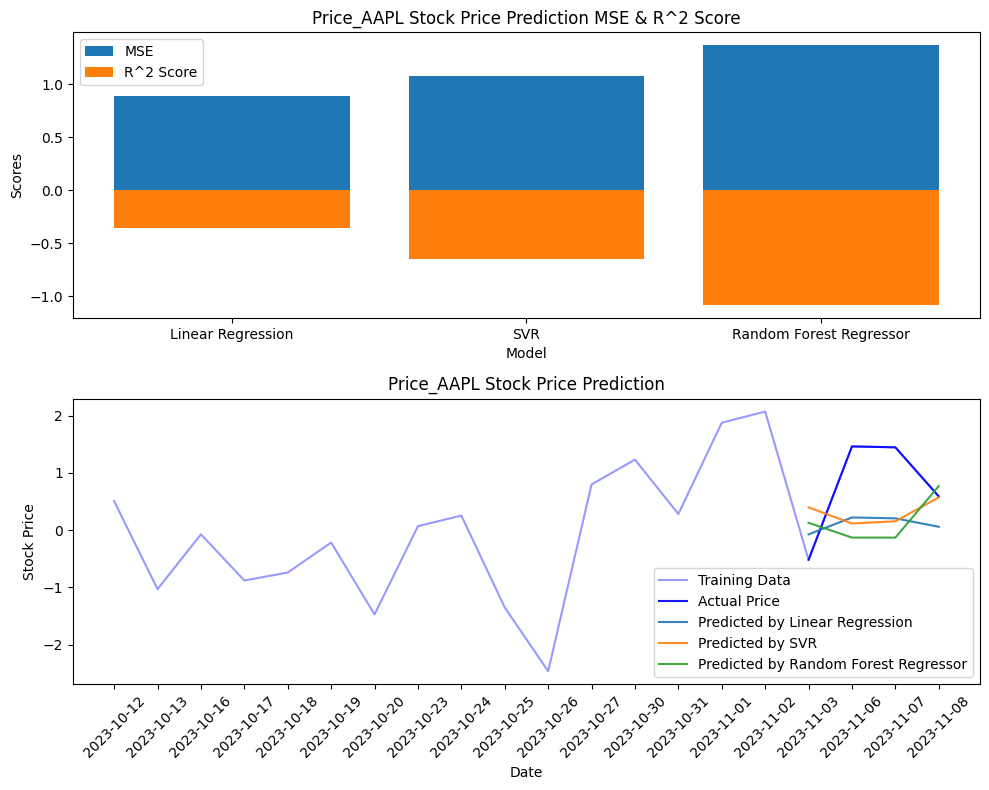
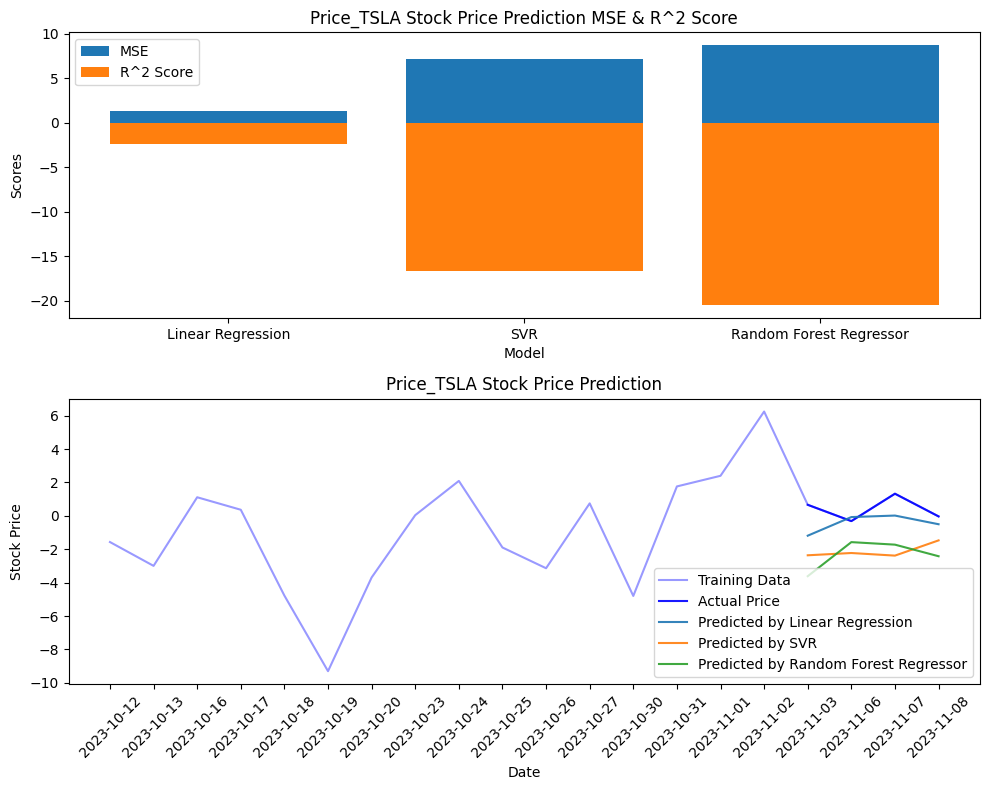
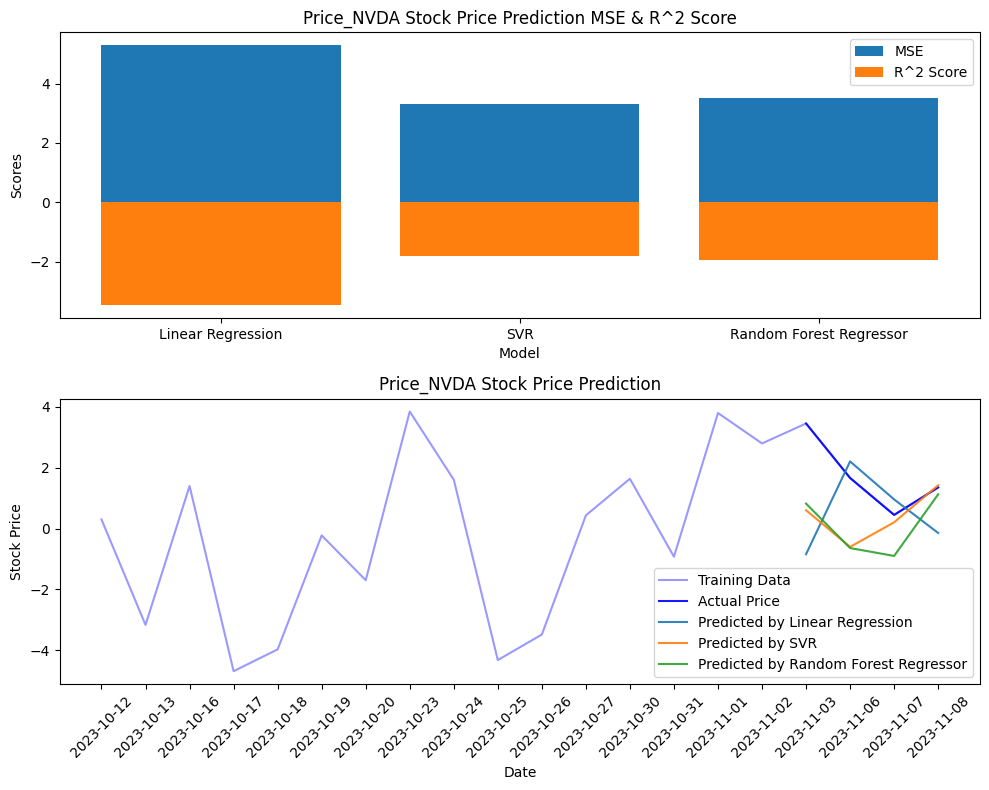
考察
今回の分析から、ニュースのヘッドラインという限られた情報からでもある程度は株価を予測できる可能性があることがわかりました。
一方、これはあくまで一つの要因に過ぎません。市場は多くの要因によって動いており、限定的な情報の感情分析だけでは実用的な予測モデル構築は難しいということを身をもって理解する(思い知る)ことができました。
情報取得に用いたAPIの無料利用の範疇ということで、今回は分析開始時直近約一か月間という短い期間の情報リソース制限の下で行いましたが、学習に用いる期間を増やせばもう少し精度は高められるかもしれません。
課題と苦労した点
今回の取り組みでは、データの取得から処理、分析に至るまで多くの課題に直面しました。
特に、APIの制限や欠損データの取り扱い、データの型の違いによる挙動の違いなどなど。
見て聴いて理解していたつもりのものが、実際に手を動かしてみて初めて理解不足であったと認識でき、頭と同時に身体で理解した気分です。今回は学習の延長でしたが次は実用性にフォーカスして、データの選択、着眼点、モデル選択とチューニング迄、精度に拘った分析とモデル構築をしたいと思います。