はじめに
前回の記事で Claude Code の Skill を紹介しましたが、「作り方がわかった」止まりで終わってしまいました。今回はそこを掘り下げます。

Skill はひとことで言うと、繰り返す作業をスラッシュコマンドにまとめる仕組みです。「毎回同じことを Claude に説明している」「チームで同じ手順を何度も踏んでいる」と感じたとき、Skill がその繰り返しをなくしてくれます。
この記事ではスクラム開発の定例作業を題材にして、実際に動く Skill を3つ紹介します。
-
/standupでデイリースクラムのノートを git log から生成する -
/reviewでスプリントの成果をコードの差分からまとめる -
/retroでコミット履歴からレトロスペクティブのネタを出す
フロントマターの各フィールドをこの3つの実例を通して紹介していくので、「どのフィールドを何のために使うのか」がひとつひとつ腑に落ちると思います。最後には自分で Skill を1つ作るハンズオンもあります。
対象読者は、Claude Code を使い始めていて Skill の仕組みをもう少し詳しく知りたい方です。インストールや基本操作はこの記事では扱いません。
Skill の仕組みをおさらい
Skill を作るには、.claude/skills/<スキル名>/SKILL.md というファイルを置くだけです。
.claude/
skills/
standup/
SKILL.md ← これがスキルの本体
review/
SKILL.md
このファイルを置いた瞬間から、 /standup や /review というスラッシュコマンドが使えるようになります。
どこに置くかで適用範囲が変わる
Skill を置く場所は3つあります。
| 場所 | パス | 適用範囲 |
|---|---|---|
| 個人用 | ~/.claude/skills/ |
全プロジェクトで使える |
| プロジェクト用 | .claude/skills/ |
そのプロジェクトだけ |
| エンタープライズ | 管理者設定で配布 | 組織全体 |
チームで共有したい Skill はプロジェクトの .claude/skills/ に置いてリポジトリにコミットします。自分だけが使う汎用的なコマンドは ~/.claude/skills/ に置くのが定番です。
Claude が自動で呼ぶこともできる
/standup と明示的に呼ぶだけでなく、Claude が会話の流れから「このスキルを使うべき場面だ」と判断して自動で呼ぶこともできます。この挙動を制御するのが、これから解説するフロントマターのフィールドです。
フロントマターで Skill の動きを制御する
SKILL.md はフロントマターとその下の本文の2パーツで構成されています。
---
name: standup
description: 今日のgit logから朝会用のスタンドアップノートを生成する
---
ここに Claude への指示を書く
主なフィールドを整理します。
| フィールド | 説明 |
|---|---|
name |
スラッシュコマンド名。省略するとディレクトリ名が使われる |
description |
Claude がこの Skill をいつ使うかを判断するための説明 |
disable-model-invocation |
true にすると手動呼び出しのみになる(Claude が自動で呼ばない) |
user-invocable |
false にするとスラッシュコマンドメニューから非表示になる |
allowed-tools |
このスキルが使えるツールを事前許可する(スペース区切り) |
context |
fork にするとサブエージェントのコンテキストで実行する |
argument-hint |
オートコンプリート時に引数のヒントを表示する |
$ARGUMENTS はスキル呼び出し時に渡した引数に置き換わります。 /retro 2 weeks ago なら、 $ARGUMENTS が 2 weeks ago になります。
それぞれのフィールドが実際にどう機能するか、3つの Skill を作りながら見ていきます。
この記事で使うサンプルプロジェクト
実例とハンズオンはすべて、シンプルなタスク管理 CLI を題材にして進めます。この記事で使うコード一式はこちらにあります。
ファイル構成はこのとおりです。
demo/
.claude/
skills/
standup/SKILL.md
review/SKILL.md
retro/SKILL.md
explain/SKILL.md
task.py ← タスクのデータモデルと管理ロジック
cli.py ← コマンドラインインターフェース
test_task.py ← ユニットテスト
コアになる task.py の中身です。
from dataclasses import dataclass
from datetime import date
from typing import Optional
import json
import os
STORAGE_FILE = "tasks.json"
@dataclass
class Task:
id: int
title: str
done: bool = False
due_date: Optional[date] = None
priority: str = "medium"
def to_dict(self) -> dict:
return {
"id": self.id,
"title": self.title,
"done": self.done,
"due_date": self.due_date.isoformat() if self.due_date else None,
"priority": self.priority,
}
@classmethod
def from_dict(cls, data: dict) -> "Task":
due = data.get("due_date")
return cls(
id=data["id"],
title=data["title"],
done=data.get("done", False),
due_date=date.fromisoformat(due) if due else None,
priority=data.get("priority", "medium"),
)
class TaskManager:
def __init__(self):
self.tasks: list[Task] = []
self._next_id = 1
self._load()
def add(self, title: str, due_date: Optional[date] = None, priority: str = "medium") -> Task:
task = Task(id=self._next_id, title=title, due_date=due_date, priority=priority)
self._next_id += 1
self.tasks.append(task)
self._save()
return task
def complete(self, task_id: int) -> bool:
task = self._find(task_id)
if task is None:
return False
task.done = True
self._save()
return True
def delete(self, task_id: int) -> bool:
task = self._find(task_id)
if task is None:
return False
self.tasks.remove(task)
self._save()
return True
def list_tasks(self, show_done: bool = False, priority: Optional[str] = None) -> list[Task]:
tasks = self.tasks if show_done else [t for t in self.tasks if not t.done]
if priority:
tasks = [t for t in tasks if t.priority == priority]
return sorted(tasks, key=lambda t: (t.due_date or date.max, t.priority))
def _find(self, task_id: int) -> Optional[Task]:
return next((t for t in self.tasks if t.id == task_id), None)
def _save(self):
with open(STORAGE_FILE, "w") as f:
json.dump([t.to_dict() for t in self.tasks], f, indent=2)
def _load(self):
if not os.path.exists(STORAGE_FILE):
return
with open(STORAGE_FILE) as f:
data = json.load(f)
self.tasks = [Task.from_dict(d) for d in data]
self._next_id = max((t.id for t in self.tasks), default=0) + 1
git の履歴はこんな状態になっています。スプリントの途中で feature/priority-filter ブランチを切って開発を進めているイメージです。
* test: add test for priority filter ← feature/priority-filter
* feat: add priority filter to task list
* test: add unit tests for TaskManager ← main
* feat: add CLI interface for task management
* feat: add Task model and TaskManager
実例1: /standup でデイリースクラムを自動化する
毎朝デイリースクラムの前に「昨日何やったっけ」と git log を掘り返している、という経験はないでしょうか。 /standup はそれを自動でやってくれます。
SKILL.md
---
name: standup
description: 今日のgit logから朝会用のスタンドアップノートを生成する
---
直近の作業日のコミット履歴を確認して、朝会(デイリースクラム)用のノートを日本語で生成してください。
まず以下のコマンドで確認してください。
` `` `
git log --oneline --since="3 days ago"
` `` `
次の形式で出力してください。
## 昨日やったこと
- コミットから読み取った作業内容を箇条書きで
## 今日やること
- コミットの流れから次に取り組みそうな作業を推測して箇条書きで
## ブロッカー
- 問題があれば記載、なければ「なし」
フロントマターは name と description だけです。 description があることで、「スタンドアップのノートを作って」と話しかけただけでも Claude が自動でこの Skill を使ってくれます。
実行結果
/standup
昨日やったこと
- タスク一覧に優先度フィルター機能を追加した
- 優先度フィルターのユニットテストを追加した
今日やること
- 優先度フィルターの動作確認・バグ修正があれば対応
- feature/priority-filter ブランチのレビュー・main へのマージ
- 次の機能(期限フィルターや並び替えなど)の実装着手
ブロッカー
- なし
git log を読んで「今日やること」まで推測してくれます。朝会の前にこれを走らせておけば、チームへの共有がすぐ書けます。
実例2: /review でスプリントレビューの準備をする
スプリントレビューの直前、「このスプリントで何を実装したか」を整理するのが意外と手間です。 /review は差分を読んでステークホルダー向けのサマリーを生成します。
SKILL.md
---
name: review
description: スプリントの成果をコードの差分からまとめる
allowed-tools: Bash Read
disable-model-invocation: true
---
現在のブランチで行った変更を確認して、スプリントレビュー向けのサマリーを日本語で生成してください。
まず以下のコマンドで変更ファイルと差分を確認してください。
` `` `
git diff main --stat
git log main..HEAD --oneline
` `` `
次の形式で出力してください。
## 今スプリントでやったこと
- 変更内容を機能・修正・リファクタリングなどカテゴリ別に箇条書きで
## 変更の規模
- 変更ファイル数・追加行数・削除行数
## デモできること
- ステークホルダーに見せられる変更点を具体的に
ここで使っているフィールドが2つあります。
allowed-tools: Bash Read は、 Bash と Read の2つのツールを事前に許可する設定です。通常、Bash コマンドの実行は Claude Code が確認ダイアログを出しますが、このフィールドを指定すると /review 実行中は確認なしで通過します。スキルが使うツールが明確なら事前に許可しておくと快適です。
disable-model-invocation: true は、手動呼び出し専用にする設定です。スプリントレビューのタイミングで自分が明示的に呼ぶもので、Claude が勝手に「そろそろレビューが必要そう」と判断して動かれては困ります。このフィールドで「 /review と入力したときだけ動く」という挙動にします。
実行結果
/review
今スプリントでやったこと
- 機能追加: タスク一覧に優先度フィルター機能を実装した(task.py、cli.py)
- テスト追加: 優先度フィルターのユニットテストを追加した(test_task.py)
変更の規模
- 変更ファイル数: 3ファイル
- 追加行数: 13行
- 削除行数: 2行
デモできること
- CLI からタスク一覧を優先度でフィルタリングして表示できる
- 優先度フィルターの動作がテストで保証されていることを確認できる
diff コマンドの出力からここまで整理してくれます。スプリントレビューのスライドに貼る内容がそのまま出てくるイメージです。
実例3: /retro でレトロスペクティブのネタを出す
KPT でのレトロスペクティブは「なんとなく話して終わる」になりがちです。コミット履歴を根拠にすると、印象ではなく事実ベースで話せます。
SKILL.md
---
name: retro
description: スプリントのコミット履歴からレトロスペクティブのネタを生成する
allowed-tools: Bash
context: fork
---
$ARGUMENTS で指定した期間のコミット履歴を分析して、レトロスペクティブ(振り返り)のネタを日本語で生成してください。
期間が指定されていない場合は直近2週間を対象にしてください。
まず以下のコマンドで確認してください。
` `` `
git log --oneline --since="$ARGUMENTS" 2>/dev/null || git log --oneline --since="2 weeks ago"
` `` `
次の形式で出力してください。
## よかったこと(Keep)
- コミットの勢いや修正の少なさなど、うまくいっていた点を推測して箇条書きで
## 改善したいこと(Problem)
- バグ修正・リバートの多さなど、課題を感じる点を推測して箇条書きで
## 次のスプリントで試すこと(Try)
- 上記の Problem をもとにした具体的なアクション案を箇条書きで
$ARGUMENTS を使うことで期間を柔軟に指定できます。
/retro 2 weeks ago # 直近2週間
/retro 1 month ago # 直近1ヶ月
/retro # 指定なし → デフォルトの2週間
context: fork は、このスキルをサブエージェントの独立したコンテキストで実行する設定です。メインの会話の履歴とは切り離された状態で動くので、長い会話の途中で呼んでもコンテキストが汚染されません。レトロのような「まとめて分析する」タスクに向いています。
実行結果
/retro 2 weeks ago
よかったこと(Keep)
- feat と test をセットで積み上げる習慣が定着している。機能追加の直後にテストを追加しており、テストファーストに近い開発リズムが保てている
- コミットメッセージが Conventional Commits 形式(feat: / test:)で統一されており、変更の種別が一目でわかる
- バグ修正(fix:)やリバートが0件。小さい単位で積み上げることで品質を保てている
- 5コミットすべてが前進しており、後退・迷走なくスプリントを完走できた
改善したいこと(Problem)
- refactor: / chore: / docs: 系のコミットが皆無で、動く機能を追うことに集中している。内部品質への投資が後回しになりがち
- コミット粒度はそろっているが、スプリント全体の進捗が見えにくい(Issue・チケットとの紐づけが不明)
次のスプリントで試すこと(Try)
- 機能追加後に refactor: コミットを1本挟む「実装 → 即リファクタ」のルーティンを試す
- コミットメッセージにチケット番号を付ける運用を始め、変更の背景を追跡できるようにする(例: feat: add priority filter (#12))
- テストのカバレッジ指標を CI に追加し、次スプリントのベースラインを測っておく
コミット履歴だけからここまで具体的に出てくるのは正直驚きました。「fix: が多いスプリントはProblemに上がる」「全部 feat: でリファクタがないとProblemになる」など、コミットの質を読んでいます。
Skill を育てるコツ
description を丁寧に書く
Claude が Skill を自動で呼ぶかどうかは、 description の内容で判断します。「何をするスキルか」だけでなく「どんな場面で使うか」まで書くと精度が上がります。
# 薄い書き方
description: スタンドアップノートを生成する
# 丁寧な書き方
description: 今日のgit logから朝会用のスタンドアップノートを生成する。
デイリースクラムの前や「昨日何をやったか整理したい」ときに使う。
公式ドキュメントでは「ユーザーが自然に口にするキーワードを description に含めること」「key use case を先頭に書くこと(長い description は途中で切り捨てられるため)」が推奨されています。Skill が期待通りに呼ばれないときのトラブルシューティングも公式に載っています。
500行以内に収める
公式ドキュメントは「 SKILL.md は500行以内に収めること」を推奨しています。長くなりすぎた場合は、詳細な参考情報を別ファイルに切り出して SKILL.md から参照する形にします。
my-skill/
SKILL.md ← 概要と呼び出し手順だけ
reference.md ← 詳細なAPI仕様など
examples/
sample.md ← 出力例
チームで共有するならコミットする
プロジェクトの .claude/skills/ に置いて git にコミットするだけで、チーム全員が同じ Skill を使えます。
git add .claude/skills/
git commit -m "feat: add scrum skill set"
「チームで揃えたい手順」は CLAUDE.md よりも Skill に書くほうが管理しやすいです。CLAUDE.md は Claude が常に読み込むのに対して、Skill は呼ばれたときだけ読まれます。
ハンズオン: /explain を作ってみる
ここまで3つの Skill を見てきました。最後に自分で1つ作ってみましょう。
作るのは /explain です。ファイルパスを渡すと、そのコードを日本語でわかりやすく説明してくれます。スクラムとは関係なく、コードを読む作業全般で使えます。
1. ディレクトリを作る
プロジェクトのルートで以下を実行します。
mkdir -p .claude/skills/explain
2. SKILL.md を作る
.claude/skills/explain/SKILL.md を以下の内容で作成します。
---
name: explain
description: ファイルや関数の内容を日本語でわかりやすく説明する
allowed-tools: Read Grep Glob
---
$ARGUMENTS で指定されたファイルを読んで、日本語でわかりやすく説明してください。
以下の順で説明してください。
1. このファイルが何をするものか(一言で)
2. 主要なクラス・関数の役割
3. 他のファイルとの関係や依存
このコードを初めて見るエンジニアにもわかるように、平易な言葉で説明してください。
$ARGUMENTS には /explain task.py のように渡したファイルパスが入ります。 allowed-tools: Read Grep Glob で、ファイルを読んだりコードを検索したりするツールを事前に許可しています。
3. Claude Code を起動して呼び出す
プロジェクトのルートで Claude Code を起動します。
claude
/explain に続けて説明したいファイルのパスを渡します。
/explain task.py
実行結果
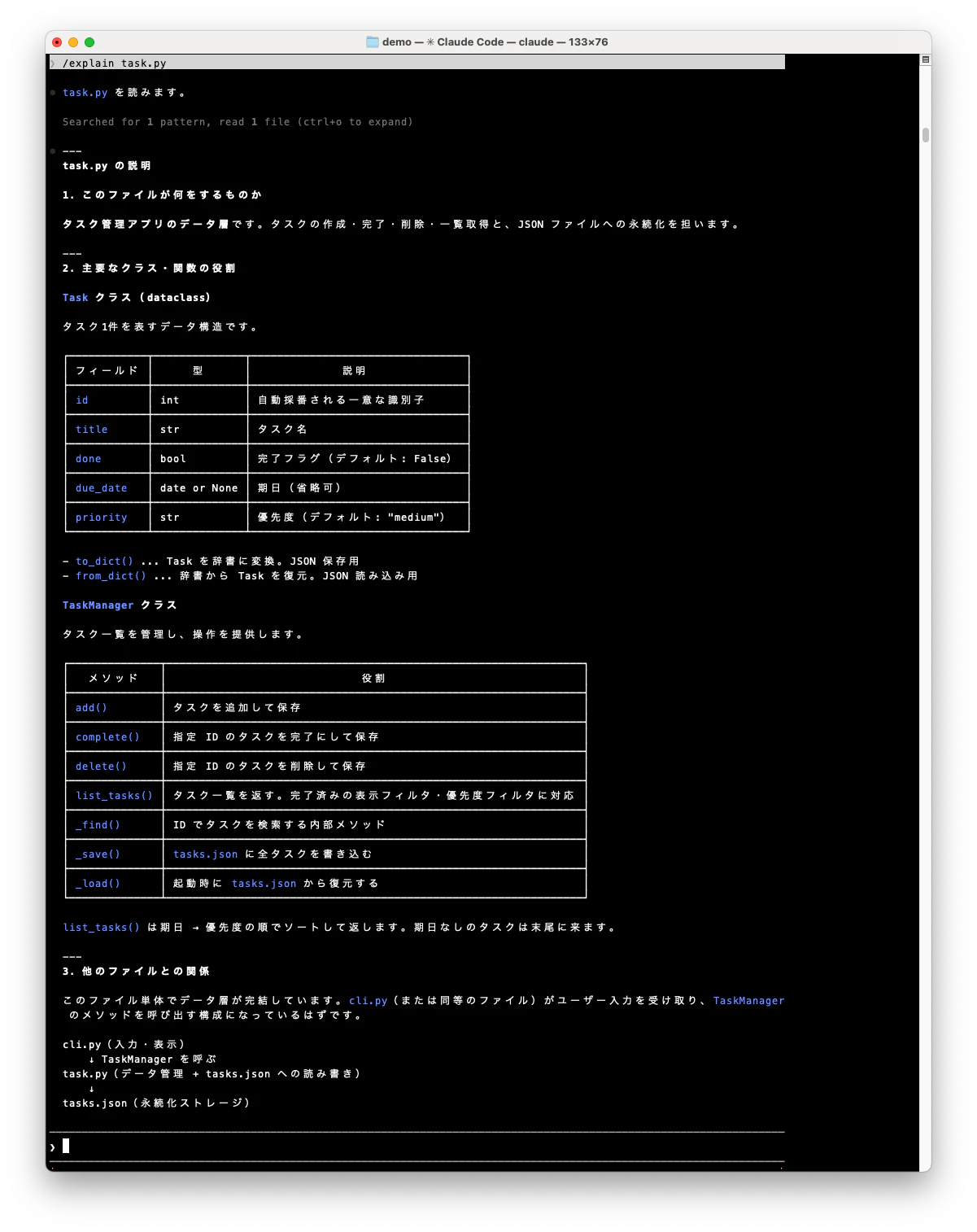
コードの構造を読んで、初めて見る人にもわかるように説明してくれます。/explain cli.py や /explain test_task.py のようにファイルを変えるだけで、同じ Skill がそのまま使えます。
おわりに
3つの Skill を通じて、フロントマターの主なフィールドを一通り触りました。
最初は name と description だけで十分です。使っていくうちに「これは手動でだけ呼びたい」「引数を渡したい」「別のコンテキストで動かしたい」という場面が出てきたら、そのときに disable-model-invocation や $ARGUMENTS や context: fork を足していけばいい、という順序で育てていくのが自然だと思います。
スクラムのセレモニー以外でも、「毎回同じことを指示している」作業があれば、それが Skill のよい候補です。
参考リンク