このシリーズではアナロジーを使った説明中心となっていますが、あくまでもイメージをつかむための例えとなっております。
記事の内容が完全に正しいというわけではありませんのでご了承ください。
公式リンクを随時添付しておりますので、公式の説明も読むことをお勧めします。
今回から、アナロジー解説シリーズを連載していきます!
第一弾はterraformについて解説します!
アナロジーとは、ある事柄を別の似ている事柄に当てはめて理解・説明する「類推(るいすい)」のことです。
なぜTerraformが必要なのか
AWSでサーバーやストレージを作るとき、最初はマネジメントコンソールをポチポチ操作するところから始める人が多いと思います。画面を見ながら直感的に操作できるので、学習の入り口としてはとても良い方法です。
ただ、開発が進むにつれてこんな問題が出てきます。
「本番環境と同じ構成をステージング環境にも作りたい。どこをどう設定したんだっけ?」
「半年前に誰かが作ったリソース、なんのために作ったか誰も知らない。」
「新しいメンバーが入ったとき、環境の作り方をどう伝えればいい?」
コンソール操作はどうしても属人化しやすく、変更の履歴も残りません。同じ構成を再現しようとすると、画面のスクリーンショットを見ながら手作業でポチポチするしかなくなります。
Terraformはこの問題を解決するために生まれたツールです。インフラの構成をコードとして記述し、そのコードを実行することでAWSリソースを作成・変更・削除します。コードはGitで管理できるので、誰が・いつ・何を変えたかが履歴として残ります。チームメンバーとも同じコードを共有できます。
このように、インフラの構成をコードで管理するアプローチを Infrastructure as Code(IaC) と呼びます。
Terraformとは
Terraformは、HashiCorp社が開発したIaCツールです。AWSだけでなく、Google CloudやAzure、その他さまざまなサービスに対応しています。
建築設計図のアナロジー
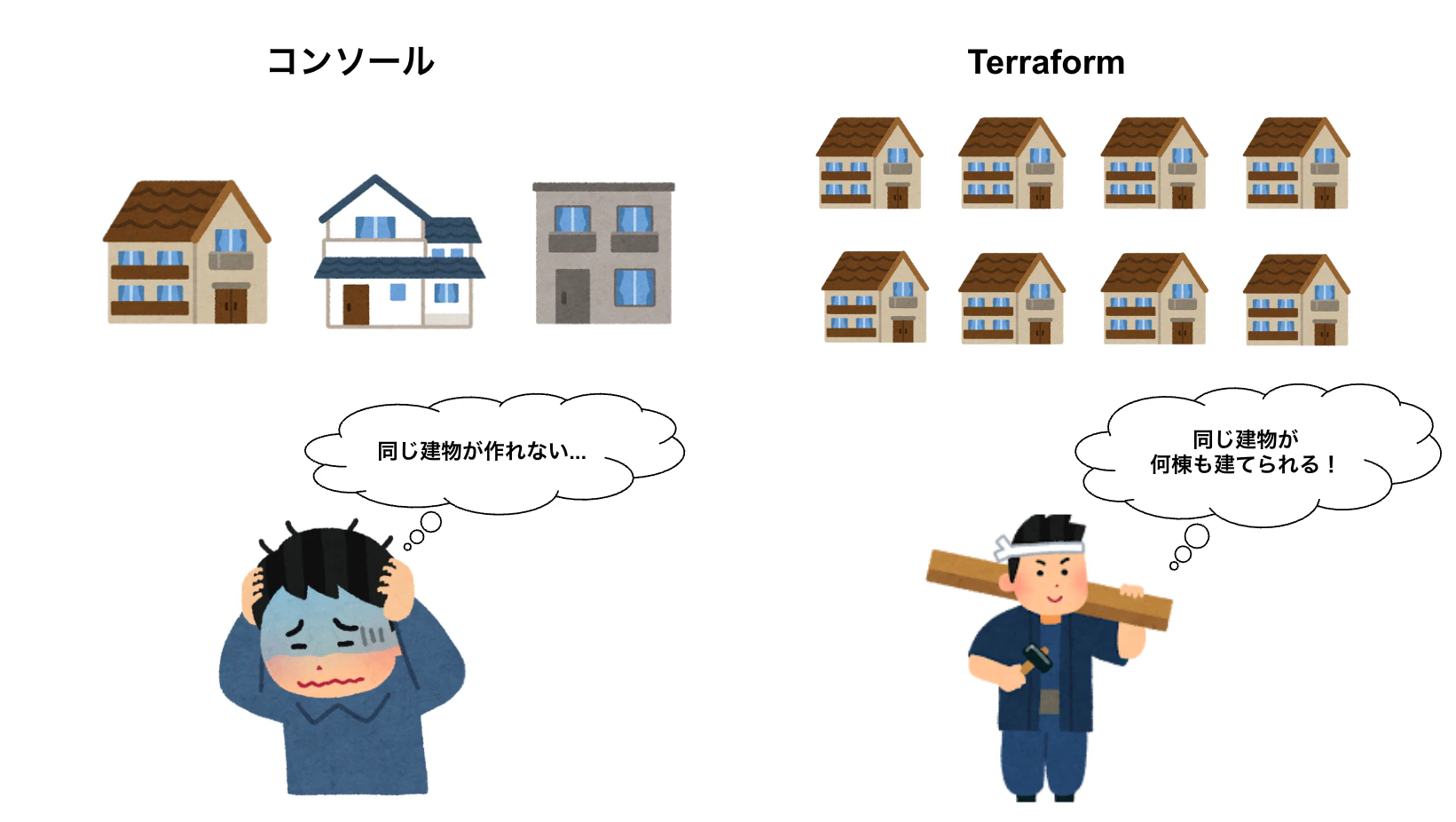
コンソールでのポチポチ作業と、Terraformの違いをイメージするときは「建築」で考えるとわかりやすいです。
コンソール作業は、職人が現場で口頭の指示を受けながら建物を作るようなイメージです。腕のいい職人なら素晴らしいものを作れますが、同じ建物を別の場所にもう一棟建てようとしたとき、どう作ったかを正確に再現するのは難しい。
Terraformは、設計図を先に書いてから建てるやり方です。設計図(コード)があれば、同じものを何度でも・どこでも・誰でも再現できます。設計図に変更を加えれば、変更前と変更後の差分が明確になります。
HCLってどんな言語?
TerraformはHCL(HashiCorp Configuration Language)という独自の言語で書きます。JSONに近い見た目ですが、コメントが書けたり人間が読みやすい構文になっています。
基本的な構造はこのような形です。
resource "リソースの種類" "このコード内での識別名" {
設定項目 = 値
}
resource というキーワードに続けて、リソースの種類と識別名を書き、波括弧の中に設定を書いていきます。
例えば、S3バケットを作るコードはこのようになります。
resource "aws_s3_bucket" "logs" {
bucket = "my-app-logs-2024"
}
aws_s3_bucket がリソースの種類(AWSのS3バケットを表す)で、 logs がこのTerraformコード内での識別名です。識別名はAWSに作られるリソース名とは別物で、同じtfファイルの中で他のリソースから参照するときに使います。
bucket がS3バケットの実際の名前です。S3バケット名はAWS全体で一意である必要があるので、他と被らない名前にする必要があります。
基本コマンド4つ
Terraformを操作するコマンドは主に4つです。
terraform init
terraform plan
terraform apply
terraform destroy
料理レシピのアナロジー
この4つを料理に例えると、すんなりイメージが湧きます。
terraform init は、料理を始める前の準備です。必要な調理器具を揃えて、食材を買い出しに行く段階に当たります。実際には、Terraformがコードを実行するために必要なプラグイン(プロバイダーと呼びます)をダウンロードします。新しいプロジェクトを始めるときや、プロバイダーのバージョンを変えたときに実行します。
terraform plan は、「このレシピで料理するとどんな完成品になるか」を事前に確認する段階です。実際には何もAWSに対して実行されません。コードとAWSの現在の状態を比較して、「このリソースが新しく作られます」「この設定が変わります」という差分を表示してくれます。
terraform apply が実際に料理する段階です。planで確認した内容をAWSに対して実行します。実行前に確認プロンプトが出るので、 yes と入力して初めてリソースが作成・変更されます。
terraform destroy は作ったものを全部片付ける操作です。作ったリソースをまとめて削除します。学習環境のお片付けや、一時的な検証環境の廃棄に使います。
実際の作業では init → plan → apply の順番で実行することになります。いきなり apply するのではなく、必ず plan で差分を確認するのが大切なポイントです。
実際に terraform plan を実行すると、このような出力が得られます。
Terraform will perform the following actions:
# aws_s3_bucket.input will be created
+ resource "aws_s3_bucket" "input" {
+ bucket = "inose-handson-input-data"
+ force_destroy = true
+ tags = {
+ "Environment" = "dev"
+ "Name" = "inose-handson-input-data"
+ "Project" = "aws-handson"
}
# ... (その他の属性は apply 後に確定)
}
# aws_s3_bucket.output will be created
+ resource "aws_s3_bucket" "output" {
+ bucket = "inose-handson-output-data"
+ force_destroy = true
# ...
}
Plan: 2 to add, 0 to change, 0 to destroy.
+ がついている行が「新しく作成される」という意味です。 (known after apply) と書かれている項目は、実際に apply してリソースが作られるまで確定しない値です。末尾の Plan: 2 to add, 0 to change, 0 to destroy. で変更の概要が一目でわかります。
tfstateという仕組み
Terraformは terraform.tfstate というファイルに、「現在AWSにどんなリソースが存在するか」を記録しています。
terraform apply を実行すると、Terraformは次の手順で動きます。まず自分が書いたコードを読み込み、次にtfstateに記録されている現在の状態と比較します。差分があれば、その差分だけをAWSに対して実行します。そして実行後、tfstateを最新の状態に更新します。
冷蔵庫の在庫ノートのアナロジー
tfstateは「冷蔵庫の在庫管理ノート」だとイメージしてください。
冷蔵庫の中身(AWSのリソース)と、在庫ノート(tfstate)が常に一致しているのが正常な状態です。ノートを見れば「今何がある」かが正確にわかります。
ノートを手書きで書き換えてしまったらどうなるか。「ないはずのものがある」「あるはずのものがない」とTerraformが混乱します。場合によっては意図しないリソースの削除が起きることもあります。これがtfstateを手動で編集してはいけない理由です。
チームで開発する場合は、tfstateをS3などのリモートストレージで共有して管理します(Terraform Backendと呼ばれる仕組みです)。各メンバーのローカルに別々のtfstateがある状態は、「一人ひとりが別のノートを持っている」状態なので、正確な在庫管理ができなくなります。
変数(variable)で環境を使い分ける
開発環境(dev)と本番環境(prd)で、同じ構成のリソースを別々に作りたいことは多いです。そのために variable という仕組みがあります。
変数は専用のファイルに定義しておきます。
# variables.tf
variable "env" {
description = "デプロイ先の環境名(dev / prd)"
type = string
}
variable "app_name" {
description = "アプリケーション名"
type = string
default = "my-app"
}
default を設定しておくと、実行時に値を指定しなかったときにその値が使われます。 default がない変数は、実行時に必ず値を渡す必要があります。
定義した変数は var.変数名 で参照します。
# main.tf
resource "aws_s3_bucket" "uploads" {
bucket = "${var.app_name}-${var.env}-uploads"
}
"${var.app_name}-${var.env}-uploads" という書き方で変数を文字列に埋め込めます。 env に prd を渡せば my-app-prd-uploads というバケット名になり、 dev を渡せば my-app-dev-uploads になります。
実行時に変数を渡す方法はいくつかあります。
# コマンドラインで渡す
terraform apply -var="env=dev"
# tfvarsファイルにまとめて書いておく
terraform apply -var-file="dev.tfvars"
dev.tfvars というファイルに env = "dev" のように書いておくと、コマンドが短くなります。環境ごとにtfvarsファイルを用意しておくのが一般的です。
リソース参照の書き方
Terraformでは、同じコード内の別のリソースの値を参照できます。
例えば、S3バケットを作った後に、そのバケットに対してアクセスポリシーを設定したいとします。
resource "aws_s3_bucket" "uploads" {
bucket = "my-app-prd-uploads"
}
resource "aws_s3_bucket_public_access_block" "uploads" {
bucket = aws_s3_bucket.uploads.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
aws_s3_bucket_public_access_block の bucket には、先ほど作った aws_s3_bucket.uploads のIDを渡しています。
参照の書き方は リソースの種類.識別名.属性名 という形です。
aws_s3_bucket.uploads.id
aws_s3_bucket.uploads.bucket
aws_s3_bucket.uploads.arn
このようにリソースを参照でつなぐことで、Terraformは依存関係を自動的に把握します。上の例では「先にS3バケットを作ってから、パブリックアクセスブロックを設定する」という順番をTerraformが自動で判断してくれます。
まとめ
| 概念 | 説明 |
|---|---|
| IaC | インフラの構成をコードで管理するアプローチ |
| HCL | Terraformが使う設定言語 |
terraform init |
プロバイダーのダウンロードなど初期化を行う |
terraform plan |
実行前に変更内容のプレビューを確認する |
terraform apply |
実際にAWSリソースを作成・変更・削除する |
terraform destroy |
管理しているリソースをすべて削除する |
| tfstate | TerraformがAWSの現在の状態を記録するファイル |
variable |
環境ごとに変えたい値を変数として定義する仕組み |
| リソース参照 | 別のリソースの属性値を 種類.識別名.属性名 の形で参照する |
Terraformを使い始めると、最初は「コンソールで作った方が早いのでは?」と感じる場面もあるかもしれません。ただ、チームでの開発や複数環境の管理が始まると、コードで管理することの恩恵が一気に実感できます。まずは plan の出力を読む練習から始めると、Terraformの動きが直感的に掴めてきます。
より深く学びたい場合は公式ドキュメントが充実しています。