ローカル環境でのシステム監視基盤をモダンな構成で整理したく、MacBook (M3) の上でK3s、OpenTelemetry Collector、そしてClickHouseを連携させたオブザーバビリティ基盤をプロトタイピングしてみました。
ログとメトリクスを別々のデータストアに置かず、ClickHouseに単一ストリームとして集約するというアプローチを試してみたところ、思いのほか上手く動作し、AIOpsの文脈などでも応用が利きそうだったので、備忘録として残しておきます。
まだまだ至らぬ点も多いかと思いますが、何かの参考になれば幸いです。
システムアーキテクチャ
今回の構築した環境の全体像です。
複数のダミーアプリ(Pod)から出力されるログと、Kubernetesノード(Kubelet)のメトリクスを、各ノードにデプロイされたDaemonSetであるOpenTelemetry Collectorが収集し、ClickHouseに流し込みます。
実装のポイントと工夫した点
1. K3s (containerd) ログの抽出とメタデータ付与
K3sで採用されているcontainerdの生ログは、CRI形式(タイムスタンプ + stdout/stderr + フラグ + メッセージ)で出力されます。
OpenTelemetryの filelog レシーバーの regex_parser オペレーターを活用し、ファイルパスから namespace や pod_name を抽出した上で、ログ本文だけをクリーンにClickHouseへ送るようにしました。
# otel-collector-config の一部
operators:
# ファイルパスからK8sメタデータを抽出
- type: regex_parser
id: extract_metadata
regex: '^/var/log/pods/(?P<namespace>[^_]+)_(?P<pod_name>[^_]+)_(?P<pod_uid>[^/]+)/(?P<container_name>[^/]+)/(?P<restart_count>\d+)\.log$'
parse_from: attributes["log.file.path"]
parse_to: attributes
# CRIログのヘッダを除去し、純粋な本文をBodyへ
- type: regex_parser
id: parse_cri
regex: '^(?P<time>[^ \n]+)\s+(?P<stream>stdout|stderr)\s+(?P<logtag>[^ \n]+)\s+(?P<log>.*)$'
parse_to: attributes
これにより、ログ送信側のアプリケーションを変更することなく、インフラ側(エッジ)でメタデータの付与と成形を完結できています。
2. ClickHouseエクスポーターによるメトリクステーブルの自動分割
最初は単一の otel_metrics テーブルにデータが入ると思い込んでいたのですが、最新のOpenTelemetry ClickHouse Exporterは非常に優秀で、最初のデータが届いた瞬間にシグナルに応じて自動的にスキーマを分割作成してくれます。
-
otel_metrics_gauge: メモリ使用量などのスナップショット値 -
otel_metrics_sum: CPU使用時間やネットワーク転送量などのカウンター値
これにより、後段のGrafanaでの集計クエリ(nonNegativeDerivative によるレート計算など)が非常に書きやすくなりました。
3. Kubeletへのアクセスは spec.nodeName を利用
k3dのようなローカルクラスタ環境では、ノード名での名前解決が上手くいかず、IPアドレス(status.hostIP)に逃げたくなることがあります。
しかし、将来的なRKE2などの本番環境へのポータビリティやTLS証明書の整合性を考慮し、DaemonSetの環境変数として spec.nodeName を渡し、Kubeletの 10250 ポートにアクセスするKubernetesの標準的なお作法に準拠しました。
ClickHouseによる動的JSONパースの強力さ
個人的に一番感動したのが、ClickHouseのログ分析能力です。
今回ダミーとして用意したバックエンドAPIは、以下のようなJSONを単なる標準出力として吐き出します。
{"status": 200, "path": "/api/v1/users", "latency_ms": 36}
旧来のログ基盤では、これを事前パースしてインデックスを作成する必要がありましたが、ClickHouseでは単なるString型の Body カラムに対して、検索時に動的にJSON関数を適用して集計できます。
SELECT
toStartOfMinute(Timestamp) AS minute,
avg(JSONExtractInt(Body, 'latency_ms')) AS avg_latency_ms
FROM default.otel_logs
WHERE LogAttributes['pod_name'] LIKE 'api-backend%'
GROUP BY minute
この「スキーマレスなログから、SQL一発でメトリクスを生み出せる」という特性は、ログとメトリクスの境界を無くす次世代のオブザーバビリティ基盤として、非常に魅力的だと感じました。
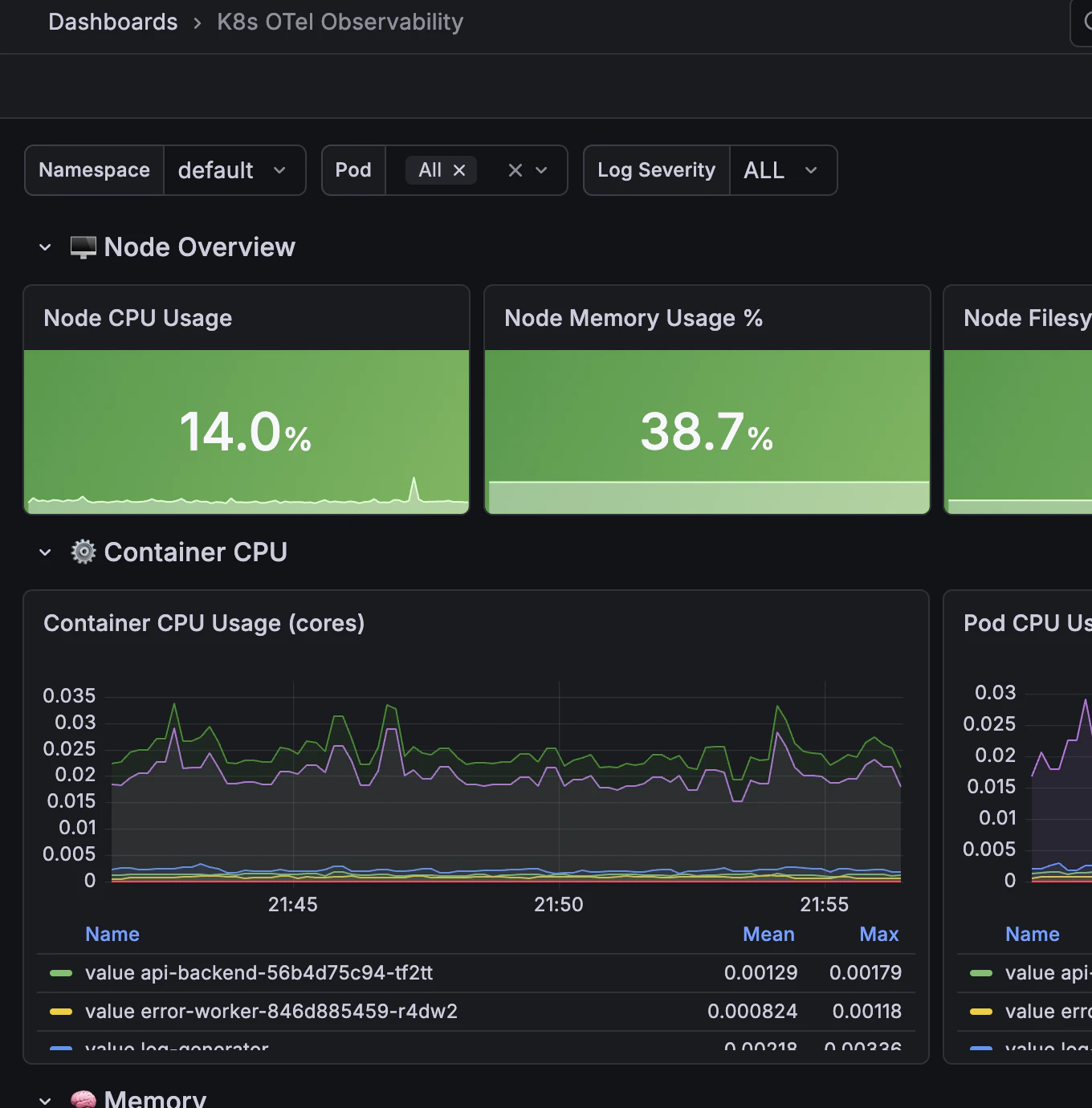
ClickHouseのデータをつかった可視化
こういうダッシュボードもAIで簡単に作れちゃう時代なんですね…
なんならKubeの出力もよみたくない!
ので、ローカルLLMもついてに使ってみることにします。
~ % kubectl get pods
NAME READY STATUS RESTARTS AGE
api-backend-56b4d75c94-tf2tt 1/1 Running 0 3h57m
error-worker-846d885459-r4dw2 1/1 Running 0 3h57m
log-generator 1/1 Running 0 5h52m
nginx-frontend-7996796dbf-68vpd 1/1 Running 0 3h57m
nginx-frontend-7996796dbf-cppph 1/1 Running 0 3h57m
otel-collector-gcsq5 1/1 Running 0 4h13m
~ % kubectl get pods | lfm-cmd
[Chunk 0]
複数のサービスが正常に稼働中(READY: 1/1)と報告されています。
[Meta-Prompt Applied]: このテキストはシステムの状態を報告するもので、技術的な情報です。要約は簡潔に、サービス稼働状況を確認する内容となります。
[Final Summary]
システム全体の状態は良好です。複数のサービスが正常に稼働しており、READYステータスは1/1となっています。
- lfm-cmdには LFM2.5-Instructが入ってます
- とうとう一つのコマンドに閉じ込められてしまったSmall Language Model (涙
まとめ
Mac ローカル環境でも、数個のYAMLとコンテナを立ち上げるだけで、驚くほど本格的な統合監視ダッシュボードを作ることができました。
- OpenTelemetry Collector(DaemonSet) を使うことで、新しいPodを追加しても設定変更が不要。
- ClickHouse は、メトリクスの時系列データと、非定型なログデータを同じDBで超高速に処理できる。
今後はこのローカル基盤を使って、エラーログの急増を検知するクエリを書いたり、AIOps的な異常検知のプロトタイピングを進めてみようと思います。