モチベーション
かばんちゃん萌え
は?可愛すぎやろ(キレ気味)。何が可愛いかって全部だぞお前。
Twitterで二次絵を見て悶絶する日々を送っております。
ここから本題
ごちうさーちマジですごくて、高速だし、正確だしでこのソフトをリスペクトで、けものフレンズ版を自作してみた。アルゴリズムとかは参考にしたけど、できるだけごちうさーちのソースプログラムは勉強を兼ねて見ないで作成した。本家はC#だけど、今回はPython3で作る。使用したライブラリ等のインストールについてはここでは解説しない。OpenCVとimagehash、mysql connectorを使う。
データベースの作成
OpenCVで、動画から1フレームずつ取り出して、画像を64bitまでdHashを使って圧縮する。それをDBに登録する。ここではPHPMyAdmin。1レコードは「dHash値、フレーム数、話数」です。
(2018年3月7日追記)
最初の投稿では、numpy.ndarrayとPIL.JpegImagePlugin.JpegImageFile間の変換方法がわからず、一度cv2.imwriteでbuffer.jpgに書き出してからImage.openで読み込むというアホすぎるコードでしたが、変換方法がわかりましたのでそちらの方法に書き換えています。
# .mp4から1フレームずつ取り出しdHash計算後、指定されたDBに登録
# 2017/12/28
# 2018/03/07
import cv2
import numpy as np
from PIL import Image
import imagehash
import mysql.connector
conn = mysql.connector.connect(user='root', password='', host='localhost', database='kemonofriends')
cur = conn.cursor()
cap=cv2.VideoCapture("KemonoFriends1.mp4")
i=1
while(cap.isOpened()):
ret,frame=cap.read()
pilImg = Image.fromarray(np.uint8(frame))
hash=imagehash.dhash(pilImg)
print("dHash="+str(hash)+",Frame="+str(i))
cur.execute("insert into main values ('"+str(hash)+"',"+str(i)+",1);")
conn.commit()
i+=1
if cv2.waitKey(1) & 0xFF==ord('q'):
break
cur.close
conn.close
cap.release()
cv2.destroyAllWindows()
dHash、フレーム数、話数の順で昇順に並べて、完成したDBをcsvでエクスポートした。50万行ぐらいになった。メモリに展開して15MBぐらい。
5979a89c9eeeae2a,34080,12
5979a89c9eeeae6a,34078,12
5979a89c9eeeae6a,34079,12
5979bb9b9999b973,27207,7
5979bb9b9999b973,27208,7
5979bb9b9999b973,27209,7
5979bb9b9999b9b3,27210,7
5979bb9b9999b9b3,27211,7
5979f0b2c666636e,31367,9
597c789898b6766c,26162,7
597c789898b6766c,26163,7
597c789898b6766c,26164,7
597c789898b6766c,26165,7
597c789898b6766c,26166,7
597c7c9898b6766c,26161,7
597c7c989c96766c,26139,7
597c7c989c96766c,26140,7
597c7c989c96766c,26141,7
5982c6ddc2aacae8,2660,1
5988c162a2e1e5e3,21076,2
5988c162a2e1e5e3,21077,2
598d8e8d8d189868,40668,1
598d8e8d8d189868,40669,1
5991858785ebc9cb,13397,10
メインプログラムの作成
探したい画像を入力すると、dHashを計算して、csvから一番近いdHash値を探して、フレーム数から、何話の何分何秒当たりのシーンかを当てる。線形探索で探す。他の探索アルゴリズムより遅いので、できるだけ速くなるように申し訳程度にハミング距離の計算部分はビット演算にしてる。
# 画像を読みこみdHash計算後、それに最も近い値をcsvから探索
# 2017/12/30
# 2018/01/15
from PIL import Image
import imagehash
import csv
# ハミング距離
def getHammingDistance(n,m):
data=n ^ m
data=(data & 0x5555555555555555)+((data & 0xAAAAAAAAAAAAAAAA)>> 1)
data=(data & 0x3333333333333333)+((data & 0xCCCCCCCCCCCCCCCC)>> 2)
data=(data & 0x0F0F0F0F0F0F0F0F)+((data & 0xF0F0F0F0F0F0F0F0)>> 4)
data=(data & 0x00FF00FF00FF00FF)+((data & 0xFF00FF00FF00FF00)>> 8)
data=(data & 0x0000FFFF0000FFFF)+((data & 0xFFFF0000FFFF0000)>>16)
data=(data & 0x00000000FFFFFFFF)+((data & 0xFFFFFFFF00000000)>>32)
return data
# 探索する画像のdHash計算
hash=imagehash.dhash(Image.open("buffer.png"))
hash_str=str(hash)
hash_int=int(hash_str,16)
# csv読み込み
f = open("KemonoFriendsDB.csv", "r")
csv_data = csv.reader(f)
db = [ e for e in csv_data]
f.close()
result="近い画像が見つかりました"
ans=-1 #答えとなるレコード
min=65 #答えとなるハッシュ値とのハミング距離
max=len(db)-1 #DBのレコード数
Hamming_limit=5 #同じ画像を発見できなかった時、許容できるハミング距離の上限
# 線形探索
for i in range(len(db)-1):
diff=getHammingDistance(int(db[i][0],16),hash_int)
#print("lines="+str(i)+","+hash_str+","+db[i][0]+",diff="+str(diff)+",min="+str(min))
#同じ画像があった
if(diff==0):
min=diff
ans=i
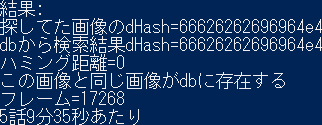
result="この画像と同じ画像がdbに存在する"
break
#近い画像があった
if(diff<min):
min=diff
ans=i
print("\n結果:")
print("探してた画像のdHash="+hash_str)
print("dbから検索結果dHash="+db[ans][0])
print("ハミング距離="+str(min))
if(min>Hamming_limit):
result="検索失敗 この画像はdbに存在しない"
print(result)
else:
seconds= int(int(db[ans][1])/30)%60
minutes=int(int(int(db[ans][1])/30)/60)
print(result)
print("フレーム="+db[ans][1])
print(db[ans][2]+"話"+str(minutes)+"分"+str(seconds)+"秒あたり")
実行結果
入力画像1
あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛あ゛

結果1
「5話9分35秒あたり」とな...
確認してみる。
OHHHHHHHHHHHHHHHHHHHHH!!!!!!YEEEEEEEEEEEEEEEES!!!!!!!!!!!!!!
入力画像2
一応もう一枚やってみますか...

結果2
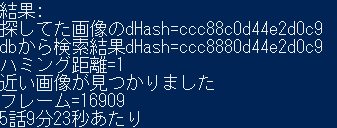
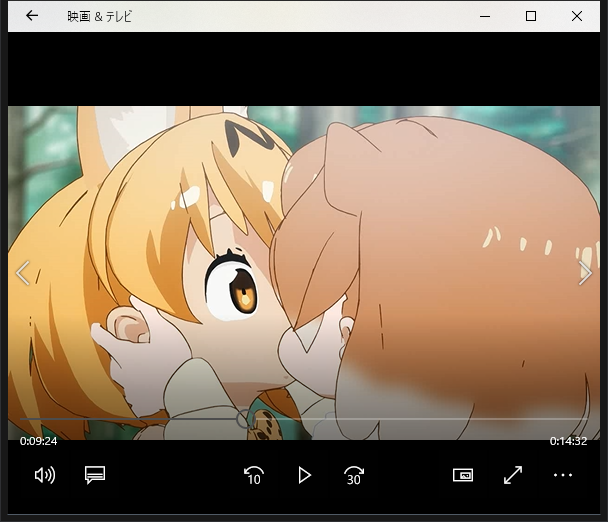
フレーム数をキャストして「分、秒」を算出してるので若干の誤差はでますね。
これで尊い映像を素早く見つけられるようになったぞ!
入力画像3
友人と遊んだときの記念撮影を入力してみる。

結果3
精度良し。