この記事はAteam LifeDesign Advent Calendar 2024の10日目記事です
結論から書きます
非エンジニア向け
スプレッドシートの大量のデータでブラウザが固まったらどうしたらいいか
結論:エンジニアを頼ってください!
そのときにこの記事をそっと添えてあげてください
エンジニア向け
スプレッドシートの大量のデータでブラウザが固まったらどうしたらいいか
結論:BigQueryに入れちゃいましょう
もちろん、長期的に対応が必要ならETLやdbt配備の検討や
そもそもデータ量を減らすには...みたいな話になるとは思いますが
この記事ではまず目の前の問題を最速で乗り越えることにフォーカスします
BigQueryを利用する場合の注意点
この記事ではBigQueryを利用した解決方法を提案していますが、
いくつか個人的落とし穴があるので紹介していきます
▼落とし穴① スプレッドシートはちゃんと固まる
まず、大量のデータを入れられたスプレッドシートが
どうなってしまうのかを知っておきましょう
当然1行1行のデータ量にもよりますが
大体の目安感が以下です
※2024年時点での自分の体験談ベースです
-
2万行- いくつかの関数が止まり始めます
-
4万行- コピペ・シート全体への修正が止まり始めます
-
15万行- 一括置換機能が止まり始めます
- PCのメモリをG単位でブラウザが消費します
- 場合によってはPC自体が固まります
-
それ以上- シート全体でのセル量上限(1000万セル)に突き当たるとセルを追加できなくなります
- ※これはパフォーマンスではなくスプレッドシートの仕様
- シートが開けなくなります
- シート全体でのセル量上限(1000万セル)に突き当たるとセルを追加できなくなります
割と簡単に誰も触れないシートが完成するので、酷使しすぎないことをお勧めします
▼落とし穴② BigQueryにデータを入れるのも一苦労
BigQueryへの読み込み方法については沢山ありますが
一番簡単そうな2つについて落とし穴ポイントを紹介しておきます
手段1: 直接読み込む
まず思いつくのは直接シートからの読み込みですね
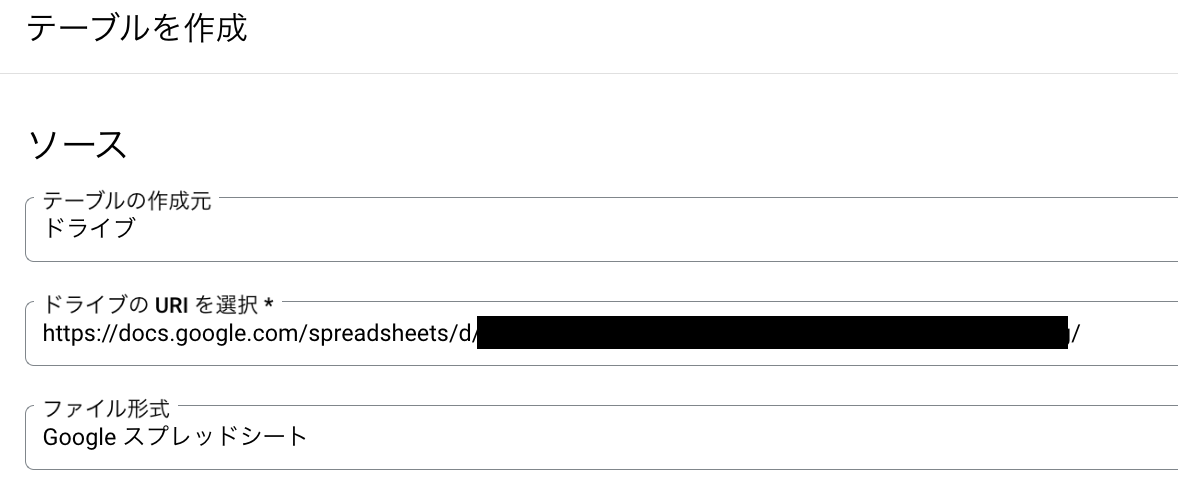
テーブル作成時に指定するだけで済むのでとても簡単ですし
作業中のマスターデータの更新もスプレッドシートを更新するだけなので簡単です
この方法の問題点は
- 15万行以上のデータはそもそもスプレッドシート上で扱うのが難しい
- その後の計算量次第では工夫が必要になる
- ※計算量の問題については詳しく後述します
という2点があります
とはいえ、15万行以下のデータで関数の実行に困っているだけなら
基本的にはこの方法が簡単で良いと思います
手段2: CSVインポート
手段1で難しいなら、CSVで直接インポートしよう..っと考えるかと思います
しかしこれには罠があり、
公式ドキュメントにあるように
圧縮をしていても4GB、条件次第では1GBと
一度にインポートできるデータ量には割と厳しい制限があります
もしCSVデータが作業中に更新されるようなことがあった場合に
随時取り込み直さないといけないのも大きなデメリットです
基本的にはお勧めしないですが
一度きりのインポートとわかっている場合は
手元でCSVを分割して入れてしまっても良いかもしれません
▼落とし穴③ BigQueryにデータを入れた後も気をつけて
さて、データもBigQueryに取り込めてひと段落し
あなたは集計作業に移ろうとしている頃でしょう
このとき、シンプルなフィルターやソートだけであれば問題無いですが
JOINや全体への探索が発生する場合どうなるでしょうか?
スプレッドシートから読み込んだデータは重たい
元々が数十万件あるデータですから、JOINすれば一時的なテーブルは
簡単に数百万行になるでしょう
このとき、クエリ実行がとても遅くなった場合、
もしかしたらその原因はスプレッドシートから読み込んだデータによるものかもしれません
一度、対象のテーブルをSELECT *した結果を
テーブルとして保存してみて、そのテーブルを計算のソースしてみてください
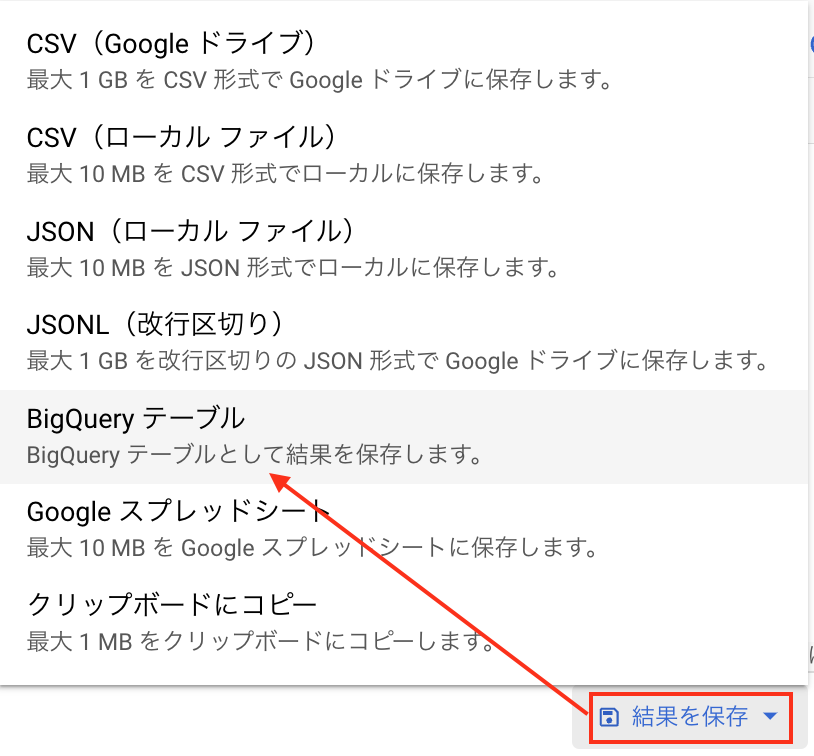
これだけで処理が早くなったら、計算が遅いのはスプレッドシートから読み込んでいることが原因です
対策
対策として先ほどのように
SELECT結果をテーブルに変換して物理データとしてBigQueryに持ち直して
上げる方法があります
このときに、後々のデータ更新や
そもそも計算対象を減らすことを考えて
Mergeステートメントでテーブル間のデータ同期を準備しておくのがオススメです
BigQueryのスケジュール機能での実行は出来なかったと思いますが
共有クエリとして置いておくことは可能です
マテリアライズドビューの落とし穴
その他の方法として、
データの実体化としてマテリアライズドビューの利用を
考えた方もいるかと思います
しかし、マテリアライズドビュー自体が実体化されたデータテーブルを対象としているため
以下のようなエラーが出てしまって利用ができないです
Materialized views can only reference native tables or BigLake external tables with cached metadata enabled or Iceberg tables.
とはいえマテリアライズドビュー自体は
計算結果を保持するのに有効な手段ではあるため
活用の検討はすると良いと思います
(それなりに制限はありますが..)
まとめ
- エンジニアに頼ろう
- BigQueryに入れてしまうのが早い
- ただし、それなりに落とし穴がある
以上
最後に
spreadsheet使ってますか?
便利ですよね
弊社ではマーケや営業はもちろん、エンジニア、デザイナー職まで、
幅広く業務でspreadsheetを使う機会があります
そんな時、
「100万件のログを集計しないといけないんだけど、ブラウザが固まって困った..」
なんてこと...よくありますよね...ね..?
まぁあまり無いかもしれないですが
そんな時に、エンジニアに気軽にヘルプを出せる関係性も魅力的なので
- みんなが頼みやすいように
- 頼まれたエンジニアが対応しやすいように
記事にまとめてしまおうと思いました
この記事が誰かの助けになれば幸いです
PS:
他にこういう解決策もあるよ!はぜひコメントで教えてください🙏