Pandasとは何ですか
PythonのPandasライブラリは、データ操作において優れたサポートを提供するオープンソースのライブラリです。 それはまたPythonプログラミング言語のためのデータ分析と処理ツールの強力なセットです。 このライブラリはデータサイエンスアプリケーションの研究と開発の両方で広く使用されています。 このライブラリはDataFrameと呼ばれる別のデータ構造を使用します。 Pandasは、このデータ構造を使ってデータを処理するための多くの機能を提供します。 柔軟性と効率性により、Pandasは広く使用されるようになりました。
なぜPandasのライブラリを使うのですか
- DataFrameは、データの操作と索引付けにおける柔軟性と効率性を提供します。
- それはメモリと多くのファイルフォーマットの間でデータを読み書きするためのツールです。例:csv、text、excel、sqlデータベース、hdf5。
- 不足しているデータを処理するスマートデータリンク。構造化フォームについてのごちゃごちゃしたデータを自動的に持ってくる。
- データのレイアウトを簡単に変更できます。
- 統合スライド、索引付け、大規模データセットのサブセット。
- データ列を追加または削除できます。
- group byを使用してデータを収集または変更すると、データセットに対して演算子を実行できます。
- データセットの混合と結合における高効率。
- データの次元インデックスは、高次元データと低次元データの操作に役立ちます。
- パフォーマンスの最適化。
- Pandasは学術と商業の両方で広く使われています。統計、貿易、分析、広告を含む。
Pandasをインストールする
Pandasライブラリをインストールするには、ドキュメントに従っていくつかの異なる方法に従うことができます。
-
pipを使う:
pip install pandas -
condaを使う:
conda install pandas
それではPythonのPandasライブラリの使い方を学びましょう。 しかし始める前に、Pandasライブラリをインポートします。 matplotlibライブラリも使用したらインストールします。
import pandas as pd
import matplotlib.pyplot as plt
import random
Pandasライブラリを使用してcsvのフォマットがあるファイルを読み込む
read_csv関数を使用してDataFrameを返すことで、csvのフォマットがあるファイルに簡単に読み込むことができます。 デフォルトでは、この関数はコンマ区切りのcsvのフォマットがあるファイルのフィールドを区別します。 次のように読み方はとても簡単です。
dataset = pd.read_csv('./fer2013.csv')
head関数を使ってDataFrameの最初のレコードを表示できます。 head関数の反対はtail関数です。
dataset.head(5)
表示される結果は以下のとおりです。

ただし、read_csv関数のいくつかのパラメータにも注意する必要があります。
- encoding:読み込みファイルのエンコーディングを指定します。 デフォルトはutf-8です。
- sep:列間の区切り記号を変更します。 デフォルトはカンマ(,)です。
- header:読み込んだファイルにヘッダがあるかどうかを指定します。 デフォルトはある。
- index_col:どの列インデックスがインデックスかを指定します。 デフォルトはNoneです。
- n_rows:読み込むレコード数を指定します。 デフォルトはNoneですべて読みます。
例えば、
dataset = pd.read_csv('./fer2013.csv', encoding='utf-8', header=None, sep=',')
dataset.head(5)
ヘッダを指定しないと、ヘッダ行が1つのデータレコードになりました。

ここでパンダpythonライブラリのread_csv関数の各パラメータの完全な説明を見ることができます。
PandasでDataframeを操作する
Dataframeの情報を見る
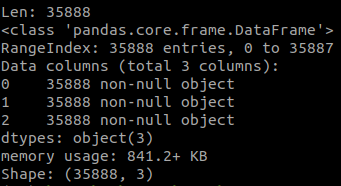
info()関数を使用して今読んだデータフレームの情報を表示することも、shape属性を使用してこのデータフレームのサイズを表示することもできます。 具体的には次のとおりです。
# DataFrameのサイズを取得, shape[0]と同じ
print('Len:', len(dataset))
# 読んだDataFrameの情報を見る
dataset.info()
# DataFrameのサイズを見る
print('Shape:', dataset.shape)
取得する結果は以下のとおりです。
データフレーム上のデータを取得する
列名に従って1列取る
取得したい列を指定するには、単に次のように列名を渡します。
dataset['emotion']

複数の列を取り込む
文字列を渡す代わりに、列名のリストを渡します。 略して最初の5レコードだけをプリントアウトするためにhead(5)を追加しました。デフォルトでは全部で取得する。
dataset[['emotion', 'pixels']].head(5)

インデックスの通りレコードを取得する
DataFrameの連続した1つ以上のレコードを取得するには、Pythonのリストのようにインデックスベースのスライダーメカニズムを使用します。 最初の5レコードを取得する。
dataset [0:5]

この場合、結果は上記のhead関数と同じです。
目的の行と列を取得することもできます。
dataset ['emotion', 'pixels'][:5]

条件でレコードを取得する
利用がトレーニングがある情報を含むすべてのレコードを取得する。
trainingData = dataset[dataset['Usage'] == 'Training']
trainingData.head(5)

NumpyのArrayの戻り値を取得する
戻り列の値をPythonライブラリのNumpyのArray配列として取得するには、単純に後で.valuesを追加します。次に例を示します。
trainingData['emotion'].head(5).values
得られる出力は次のとおりです。

DataFrameのデータ表現
機械学習では、データの実行と分類が非常に重要です。コンピュータビジョンに関する基本的なデータ表現をいくつか示します。
matplotlibライブラリも使用する。
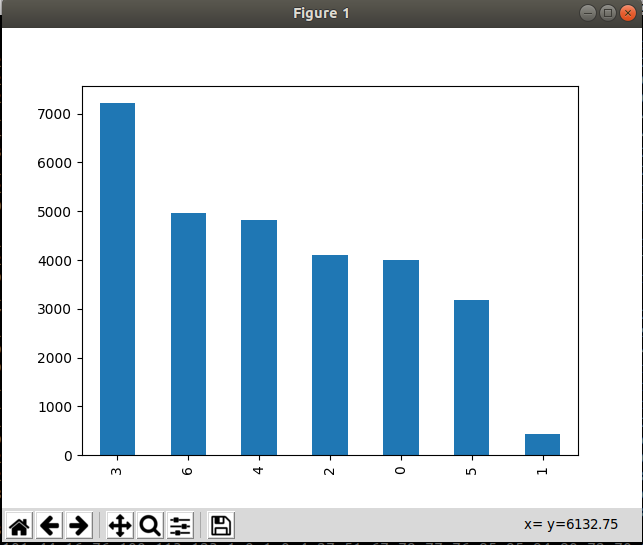
クラスのデータ量を示すグラフを描く
trainingData['emotion'].value_counts().plot(kind='bar')
plt.show()
表示される結果
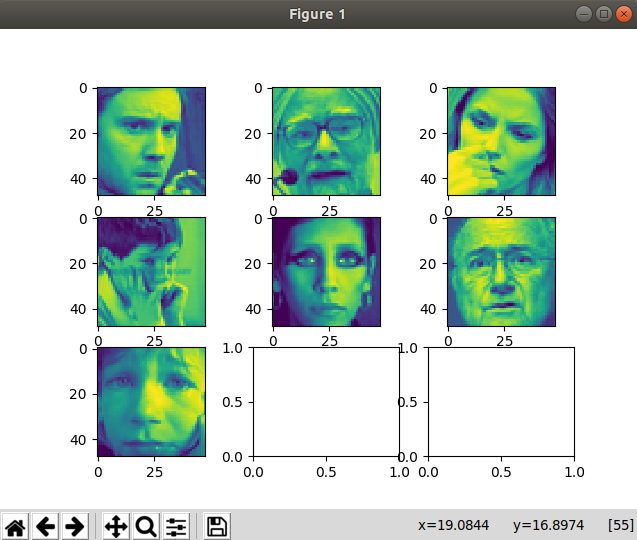
最初の7つのデータの絵を描く
表示される結果
最後の7つのデータの絵を描く
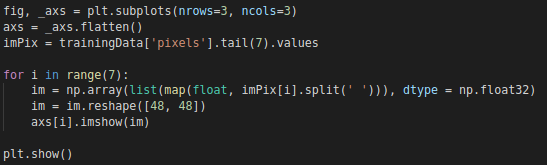
表示される結果
最初の7層のデータの絵を描く
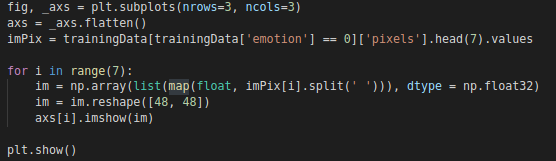
表示される結果
ランダムに7データレイヤー1の絵を描く
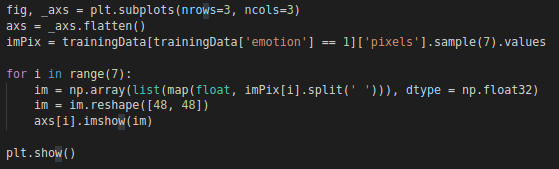
表示される結果
結論
Pandasのライブラリについていろいろな面白いことがありますが以上で基本的な内容をせつめいしました。他にはドキュメントで自分で調べることができます。
読んでいただきありがとうございます、あなたが理解できない何かがあれば、私にメールで連絡してください。データセットとでGoogle Colab使ったソースコードの詳細は以下のリンクで見てください。Google Colabをわからない場合私はこれを紹介した記事を見ることができます。
Email: hungph.dev.ict@gmail.com
記事で使ったデータセット: https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge
Google Colab: https://colab.research.google.com/drive/1Ehh-s7ZnvurGhVYo9u8atKBlJvmtTzSX