今回はKAGGLEのCMIコンペ2025に参加したので、そこの反省の記事を書こうと思います。今回は2ヶ月前から参加し、少しずつモデルを作成していきましたが、なかなか手元でスコアが出ず、大変苦戦しました。
取り組み環境
今回はチームで参戦しました。3人チームでしたが、1人は研究が忙しくてほぼ参加していなかったので、2人チームの取り組みになります。1人は情報学科の友人と、私自身は船舶海洋コースという全く情報には関係ないコースで研究をしています
自身は大学院を休学しているので、ほぼ全ての時間をカグルに捧げることができましたが、そんなスーパー人間ではなかったので、ボルダリングをしたり、趣味の時間の合間に取り組んでいました。とは言っても、コンペ終盤でなかなかスコアが上がらない時期以外は、1日8時間程度は参加していました。
総括
本コンペに参加するにあたって最初はパブリックノートブックを参考にパイプラインを組んでいましたが、途中から自分で独自のモデルを実装し始めることにして、このCVが全くあがらなかったので一旦限界を感じて少し距離を置いてみました。
結局コンペ終盤ではシングルモデルでLB0.84以上のノートブックが更新されたのでこれを元に実装を始めCV0.90を達成しましたが提出してみるとLB0.793に落ち着いたのでリークしていたのかなと今では思いますが....
結局最後に提出したノートブックはパブリックノートブックを元に作ったアンサンブルノートブックでしたが、LB0.823でメダル獲得とはなりませんでした
CMI - Detect Behavior with Sensor Data コンペティション振り返り
1. コンペティション概要
本コンペティションはどのような構成で開催されていたか、overviewを読むことは大事だと思っていたので、ウェアラブルデバイスがどういう風に使われているかを動画で確認しました。
基本情報
- 主催: Child Mind Institute
- 期間: 2025年7月〜8月
-
目的: ウェアラブルデバイス(Heliosウォッチ)のセンサーデータを使用して、身体集中反復行動(BFRBs: Body-Focused Repetitive
Behaviors)を検出 - 意義: 髪を引っ張る、皮膚をつまむ、爪を噛むなどのBFRBsは、不安障害やOCDの重要な指標であり、メンタルヘルス治療ツールの改善に貢献
テストデータはシーケンス単位でデータが保管されており、1シーケンスに1動作、そして時間ごとのデータが保存されていました。このシーケンスごとに蓄積予測するAPIを使用するのが最初は難しく、かなり手間取っていましたが、クラスによる責任分担を行うことによって予測が可能になりました。それまで1週間はかかったと思います。
テストセットの特徴
- 約3,500シーケンス
- 重要: テストセットの50%はIMUデータのみ(サーモパイル・ToFセンサーは欠損値)
- 追加センサーの価値を評価する設計
- CPUノートブック: 最大9時間実行時間
- インターネットアクセス無効
2. データ内容
データの内容は以下のようになり、3日ほどかけてデータ分析を行いましたが、初心者なものでハズレ値やデータ分布を眺める程度に終わっています。おそらく私が処理していない部分でセンサーに価値があったと思われる部分は,Time-of-Flight(距離センサー)でこのピクセルをうまく画像にする必要があったのではと今となっては思います.
公開のノートブックのEDAを読んでも精度上昇につながる直接的な要素は見受けられませんでした
センサー構成
IMU(慣性計測ユニット)
- 加速度: acc_[x/y/z] (m/s²)
- 回転: rot_[w/x/y/z] (クォータニオン)
- 欠損: 加速度なし、回転に一部あり
サーモパイル(温度センサー)
- 5センサー: thm_[1-5] (℃)
- 欠損パターン:
- thm1-4: 6,000〜7,600
- thm5: 33,286(他の4倍以上)
Time-of-Flight(距離センサー)
- 5センサー: 各8×8ピクセル
- 合計: 320チャンネル
- 値域: 0-254(-1は無応答)
- センサーごとに異なる欠損パターン
人口統計データ
- adult_child: 成人(1)/子供(0)の区分
- age: 年齢
- sex: 生物学的性別(0=女性、1=男性)
- handedness: 利き手(0=左、1=右)
- 身体測定値(身長、腕の長さ等)
ジェスチャー分類
Target gestures (BFRB):
- Above ear - pull hair
- Cheek - pinch skin
- Eyebrow - pull hair
- 他5種類
Non-target gestures:
- Wave hello(最多)
- Write name in air
- Text on phone
- 他7種類
評価指標
Modified Macro F1スコア
Score = (Binary F1 + Macro F1) / 2
- Binary F1: Target(BFRB)vs Non-target(非BFRB)の2値分類
- Macro F1: 18ジェスチャーの多クラス分類(Non-targetは1クラスに統合)
3. データ分析・EDAの知見
センサーの直接的なグラフからは分かりませんでしたが、個人的には以下の主要な発見があったと思っています。欠損値などを見ることは大事だと知っていたので、注意していました.
シーケンス上の分布は後に大切だと分かったのですが、これはコンペ序盤では気づけませんでした。
主要な発見
-
シーケンス長分布
- 平均: 約60フレーム
- 95パーセンタイル: 180フレーム
- 99パーセンタイル: 210フレーム ← 最終的に採用
- パディング長の最適化が重要
-
センサー欠損値パターン
- IMU: 回転データに一部欠損
- THM5: 他の4倍以上の欠損(33,286)
- ToF: センサーごとに異なる
- → センサー分割アーキテクチャの必要性
-
被験者ごとのデータ分布
- 81名の被験者
- 各被験者: 51〜102シーケンス
- StratifiedGroupKFoldの必要性
-
加速度の大きさ分布
- ジェスチャーごとに特徴的なパターン
- 物理特徴量エンジニアリングの有効性を示唆
4. 取り組みの変遷
ここは取り組み分布をクロードコードにまとめてもらったものです。やはり8月中旬までは全く精度が出ておらず、公開ノートブックにすら負けていたことを思い出します。友人と相談して、第一ステージはGBDTを使ってほぼ100%を達成することができたので、LightGBMで処理し、その後の分類をディープラーニングで処理することにしました。これで性能がMAX LB 0.763程度だったのでやはり第一ステージからディープラーニングで分類するべきだという考えに落ち着きました。
序盤(7月下旬〜8月初旬)
アプローチ:
- 2段階システム構築(Stage 1: LightGBM、Stage 2: Deep Learning)
- 統計特徴量エンジニアリング
- 基本的なCNN/LSTMモデル
結果: CV 〜0.75(基礎的なパイプライン確立)
中盤になってシングルモデルでコースカのノートブックが公開されてそちらのモデルの性能が失ったのでこのノートブックを再現することに注力していました。ノートブックを再現し少し工夫を加えるとCV0.8781を達成することができ、これは勝てるのではと思いました。
中盤(8月中旬)
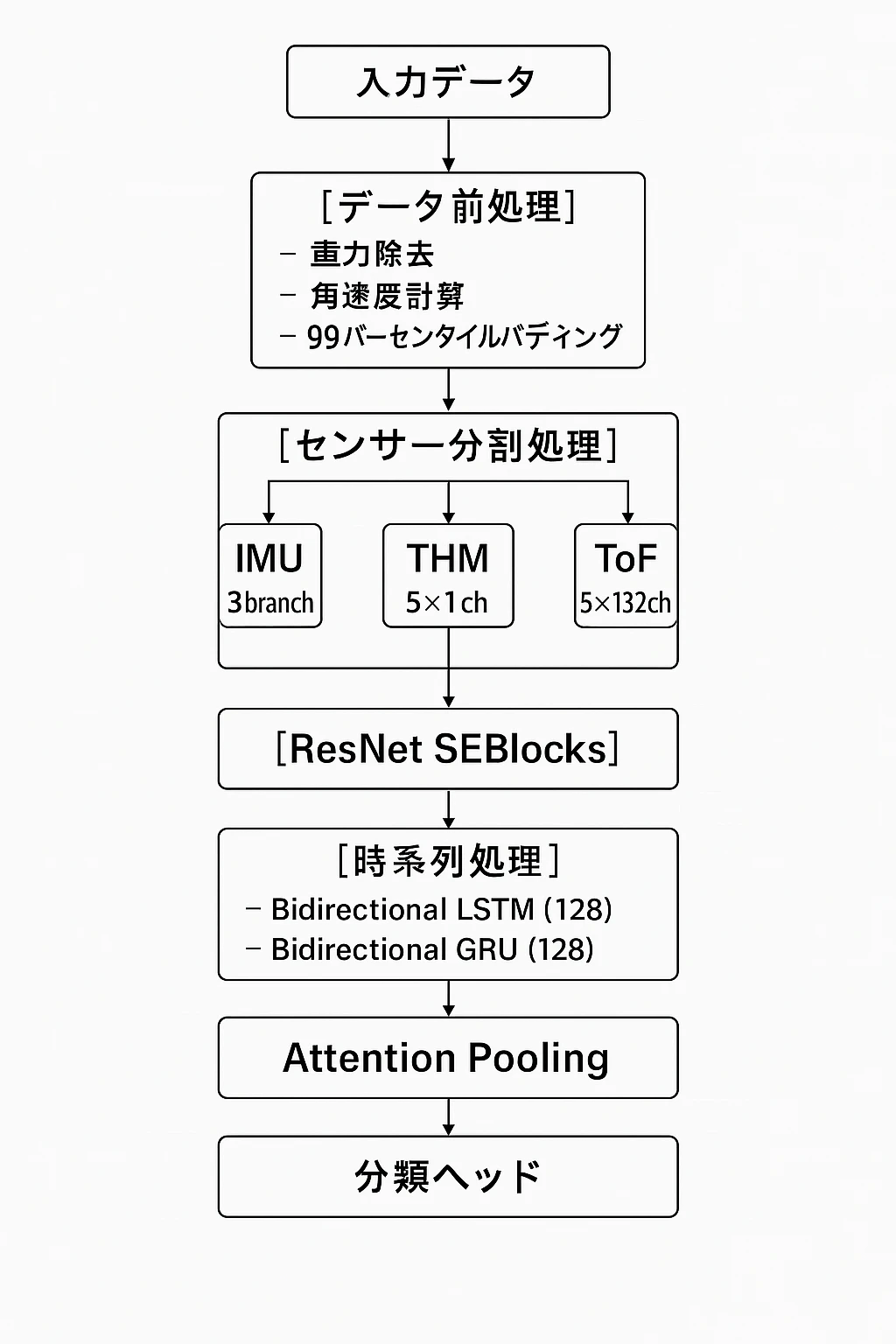
転換点: LB 0.841ノートブックの発見
- センサー分割アーキテクチャ
- IMU: 3ブランチ(acc, rot, other)
- THM/ToF: 各5ブランチ
- ResNet SEBlocks導入
- 99パーセンタイル採用
成果:
- 完全再現に成功
- 5-fold CV: 0.8781 ± 0.0201
- 最高fold: 0.9064
終盤になるとコンペに取り組む記録もだんだんなくなっていき、おそらくCV0.9を超えないと勝てないと思ったので様々な方法を試しましたが、以下の4つくらいが目立った工夫で、結局自前モデルでは0.9を達成することはできませんでした。
終盤(8月下旬)
exp_9: CV 0.9への挑戦
- ToF 16領域分割(8×8→4×4×4)
- Focal Loss(クラス不均衡対策)
- データ拡張(MixUp, TimeWarp)
- 時系列特徴量追加
最終的にはパブリックノートブックのアンサンブルを行うことにし、そこそこいいアンサンブルノートブックができたのでそれを提出することにしました。私はこの時点でだいぶ気力が薄れていたので、友人がほぼアンサンブルノートブックを作ってくれました。
結果:
- 自前モデル: CV 0.878
- 時間制約で完成せず
- 最終提出: パブリックノートブックのアンサンブル
5. 採用したモデル
コンペで使用したモデルは以下のモノです
モデル比較表
| モデル名 | アプローチ | CVスコア | 特徴 |
|---|---|---|---|
| LightGBM 2段階 | 統計特徴量 | 0.720 | 初期ベースライン |
| 基本CNN-LSTM | 時系列処理 | 0.750 | シンプル構造 |
| Multi-scale TCN | 複数時間スケール | 0.820 | 16バージョン作成 |
| Physical BERT | 物理特徴+Transformer | 0.835 | 計算コスト高 |
| Gated Two-Branch | センサー別処理 | 0.845 | 有望だが未完成 |
| LB 0.841再現 | センサー分割+SE | 0.878 | ✅ 最良結果 |
| exp_9改善版 | ToF16分割+Focal | 0.871 | 開発中で終了 |
最終ソリューション: LB 0.841再現モデル
5-Fold CV結果:
| Fold | CMI Score |
|---|---|
| 0 | 0.9064 |
| 1 | 0.8838 |
| 2 | 0.8654 |
| 3 | 0.8533 |
| 4 | 0.8817 |
| 平均 | 0.8781 |
6. 前処理の重要性について
このコンペではモデルの重要性より前処理の重要性が大きかったように思います。実際、パブリックノートブックで高スコアを記録しているものを見ると、少しリークにはなるものの、訓練データ全体で一括スケーリングしており、実際私のモデルにも当てはめてみたところ、 CV が0.03向上しました。また、今回は前処理段階で作った多くの特徴量は、あまり効果がなく、最低限のものだけを採用するといった方が学習がうまくいきました。私見ですが深層学習を用いたモデルはモデル内で特徴量を学習するので少ない方が精度が出たのだと思います。
ただ、この辺りの処理の仕方を書いているノートブックは異様に煩雑で私自身追いきれなかったところが、スコアの停滞に繋がったのかなと思っています
7. 実験の方法
最初はソースで、一括管理していましたが、実験ごとにディレクトリーを作成し、実験1実験2実験3のように名前をつけてそこで各々にソースファイルを持たせて管理していました。また、さらにその中で複数の結果を保存できるようにしました
8. 敗因分析
主要な敗因
-
公開リソースの活用遅れ
- 高スコアノートブック(LB 0.841)の発見が中盤
- 早期に分析していれば、より多くの改善時間を確保できた
-
独自手法への過度な固執
- Multi-scale TCNに16バージョンも作成
- 既存の優れた手法を軽視
-
実験管理の不備
- 16個のMulti-scale TCNバージョン混在
- 設定ファイルの管理不足
- 再現性の確保が困難
-
時間配分の失敗
- 序盤に独自開発に時間を使いすぎ
- 終盤でアンサンブル戦略の時間不足
9. 反省点
Claude Codeへの依存について
最近ではバイブコーディングと呼ばれるAI によるコーディング支援ツールですが、私はこれにどっぷりはまっており、休学初めてから参加したコンペではコーディングはほぼclaude codeに頼っていますただ、最近依存が大きくて少し大きなプロジェクトを作ると、今回のように提出で学習の再現ができなかったりと、使い手に完成のイメージがなければ良いものは作れないなと思いました。以下の点が今回のコンペでは感じられました
良かった点:
- 高速なコード実装
- バグの迅速な修正
- 複雑なアーキテクチャの実装支援
問題点:
- 深い理解なしにコードを量産
- デバッグ能力の低下
- 独自の問題解決能力が育たない
改善策:
- Claude Codeは補助ツールとして使用
- 重要な部分は自分で実装・理解
- コードレビューの徹底
特にコードレビューを行うことは当たり前ですが、大事でかなりコードを読む時間に当てました。また、クラスについても実装する際はある程度自分で下書きをして、かなりコメントを打つことで実装をより自分のイメージに近いものにしました。バイブコーディングについては確かに便利ではありますが、使い手が能力に依存すると思いますので、私のように能力が低い人が使うとスパゲティコード化待ったなしなので、今後はある程度プログラムを組んでからAI に投げようと思いました。いつの時代になってもお手本になれる人は大事ということですね
10. 学んだこと・今後への活用
私は個人的に元々加速度センサーに興味があったのでCMIコンペでは是非ともメダルを獲得したかったですが、このような結果になりました。ここは AI に記録させていたログから抽出した教訓です
重要な教訓
-
センサー特性の理解が最重要
- 欠損値パターンの分析
- センサーごとの特性把握
- 物理的意味の考慮
-
シンプルさと性能のバランス
- 複雑 ≠ 高性能
- 基本的な手法の組み合わせが有効
- デバッグ・調整のしやすさ
-
適切な検証の重要性
- StratifiedGroupKFoldの必須性
- 実際のテスト環境を再現
-
公開リソースの価値
- 高スコアノートブックから学ぶ
- ディスカッションの活用
- 車輪の再発明を避ける
確かに読んでいてできなかった部分ではありますが、これが最初からできたら苦労しないよっていう感じですね、今回は初めて精力的に取り組んだカグルコンペだったので、この辺の未熟度はまあ仕方ないかなと思っています。最初から完璧を追い求めて挫折するよりはだんだん力をつけていく方が絶対いいので
10. まとめ
達成したこと
- CV 0.8781の高精度モデル構築
- センサー分割アーキテクチャの実装
- 物理特徴量エンジニアリングの確立
- 時系列Deep Learningの実践
得られた知見の応用
- センサーデータ処理技術
- 時系列解析手法
- 欠損値処理戦略
- 実験管理のベストプラクティス
最終的な学び
センサー特性の理解とシンプルさの重要性を学んだ貴重な経験でした。技術的には高いCVスコアを達成できましたが、提出に戸惑ったり、LBのスコアが出なかったりととても難しいコンペでした。また頑張ろうと思います。次はオープンポリマーコンペに出るつもりです