前書き
この投稿では、TensorNetworkと、それを使用してTensorFlowのフィードフォワードニューラルネットワークをスーパーチャージする方法について説明します。 TensorNetworkは、テンソルネットワークでの計算を容易にするために、19年6月にリリースされたオープンソースライブラリです。 通常、人々が私たちに最初に尋ねる質問は「テンソルネットワークとは何ですか?」であり、その次に「なぜテンソルネットワークを気にする必要があるのですか?」です。 最初の質問(以前のGoogle AIブログ投稿など)に対処する多くのリソースがあります。ここでは、2番目の質問に答えることに焦点を当てます。 基本的な考え方は、ニューラルネットワークの「テンソル化」と呼ばれ、2015年のNovikovらの論文にそのルーツがあります。 al。 TensorNetworkライブラリを使用すると、この手順を簡単に実装できます。 以下に、KerasとTensorFlow 2.0を使用した明示的かつ教育的な例を示します。
TensorNetworkを使い始めるのは簡単です。 ライブラリは、pipを使用してインストールできます:
pip install tensornetwork
TN Layers
TN拡張ニューラルネットワークの基本的な考え方は、ネットワークの1つ以上のレイヤーをTNレイヤーに置き換えることです。 TNレイヤーは、元のレイヤーの圧縮バージョンと考えることができます。 最適な結果は、圧縮の可能性が高い高密度で接続性の高いレイヤーで開始するときに期待できます。 たとえば、次のことを考慮してください:
Dense = tf.keras.layers.Dense
fc_model = tf.keras.Sequential(
[
tf.keras.Input(shape=(2,)),
Dense(1024, activation=tf.nn.swish),
Dense(1024, activation=tf.nn.swish),
Dense(1, activation=None)])
このネットワークには2次元の入力、1次元の出力があり、それぞれ1024個のニューロンを持つ2つの隠れ層が含まれています。 パラメーターの総数(重みとバイアスを含む)は、(2 + 1)* 1024 +(1024 + 1)* 1024 +(1024 +1)* 1 = 1,053,697です。 これらのパラメータの大部分、(1024 + 1)* 1024 = 1,049,600は、2番目の非表示層に関連付けられています。 これらを元のサイズの1%未満のTNレイヤーに置き換えます。
隠れ層の1,049,600パラメーターは、1024 x 1024 = 1024 x 1024のマトリックスに配置された1,048,576の重みと1024のバイアスで構成されます。 1024 x 1024の重み行列をテンソルネットワークに置き換えることで節約できます。 ネットワークの他の部分との互換性を保つために、1024個の入力と1024個の出力があるという事実を変更しません。 そのようにして、TNレイヤーを元のレイヤーのドロップイン置換として扱うことができます。
通常、レイヤーへの1024入力は、形状の単純な配列X(1024、)と考えます。 これらの入力に重み行列Wを掛けて、新しいベクトルYを生成します。次のステップはYに非線形性を適用することですが、TNの変更はレイヤーの線形部分にのみ影響するため、それには焦点を当てません。 テンソルネットワーク表記では、Yの計算を次のように記述します:
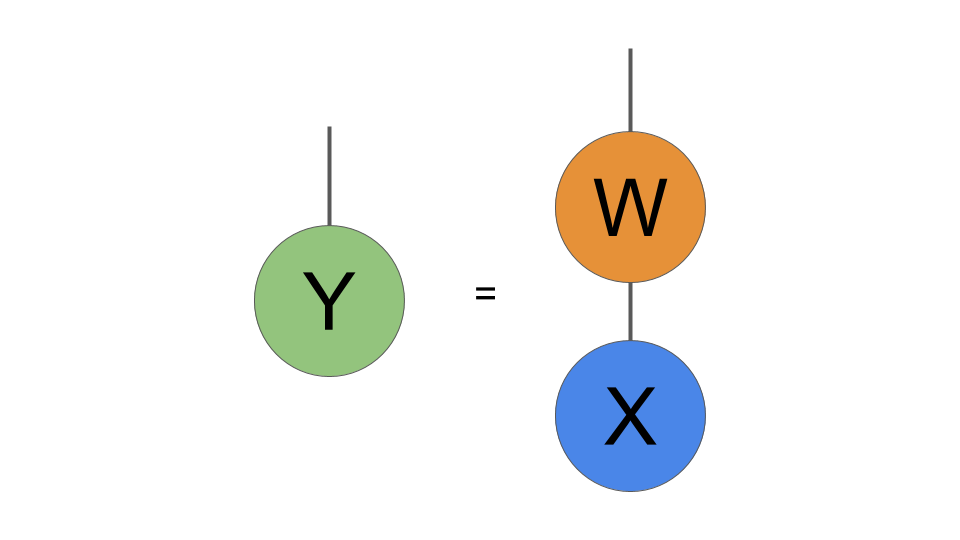
通常、ニューラルネットワーク層の重みWは入力Xに行列乗算として作用し、出力Y = WXを生成します。 ここで、その行列乗算を図式的に示します。
この時点で、レイヤーのテンソル化について説明できます。 まず、入力配列を(1024、)の代わりに(32,32)のような形に変更します。 図では、形状の変更は次のようになります:
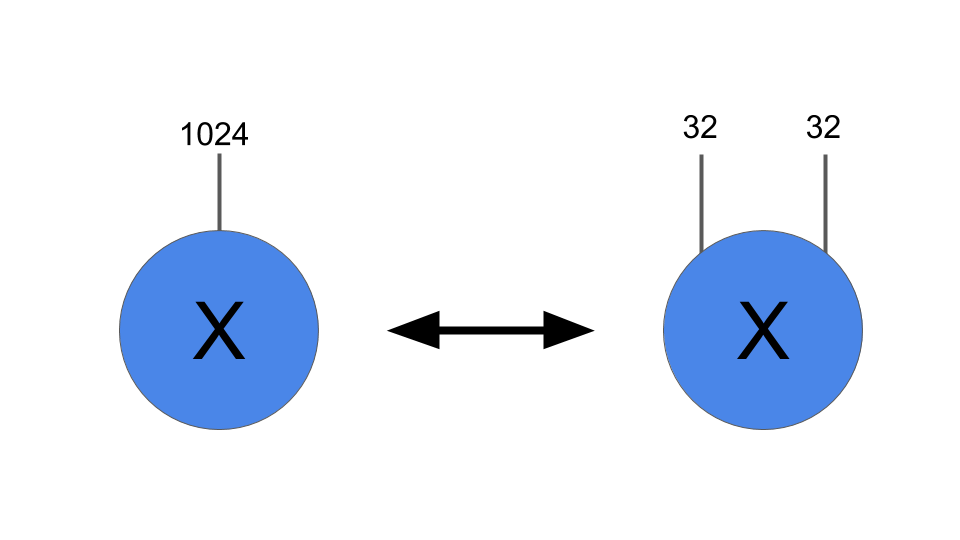
入力Xを形状のベクトル(1024、)から形状の配列(32,32)に変形することが、テンソル化プロセスの最初のステップです。 原則として、任意の形状変更が許可されています。この例では、この特に単純な形状を選択しました。
ここで、(1024,1024)重み行列Wを適用する代わりに、2つのコアで構成されるテンソルネットワーク操作を適用します:
テンソル化された重み乗算の図式表現。 必要に応じて、出力Yをベクトルに再形成できます。
2つのコアを接続する脚の次元(結合次元と呼ばれることが多い)について選択する必要があります。 簡単にするために、2次元であると見なします。 次に、各コアには2つの30の2次元脚と1つの2次元脚があり、形状は(32,32,2)になります。 結合次元はモデル内のパラメーターの数を制御し、結合次元を適切に選択することにより、多くの場合、パフォーマンスの低下がほとんどまたはまったくない、良好なパラメーター削減率を実現します。
TNレイヤーを使用した結果、1,048,576個の完全に接続された重み行列の重みを、テンソルネットワークの2 *(32 * 32 * 2)= 4,096パラメーターに置き換えました。 それはものすごい削減です! 他のレイヤーを考慮した後でも、元の1,053,697と比較して、モデルの合計サイズは9,217個のパラメーターになります。
この簡単な例では、2コアテンソルネットワークをeinsum式に変換するのはそれほど難しくありません。 ただし、より多くのコアとより複雑な接続を持つテンソルネットワークの場合、einsumのデバッグまたは拡張は非常に困難です。 したがって、代わりに、ネットワークを構築するよりオブジェクト指向の方法のためにTNライブラリを使用します。 以下のコード例では、わかりやすいように単純な2コアの例に固執しますが、最後に戻って他の可能性について説明します。
Code for a TN Layer
上記の1024 x 1024のケースに特化したKerasでTNレイヤーを作成するためのサンプルコードを次に示します:
import tensorflow as tf
import tensornetwork as tn
class TNLayer(tf.keras.layers.Layer):
def __init__(self):
super(TNLayer, self).__init__()
# Create the variables for the layer.
self.a_var = tf.Variable(tf.random.normal(
shape=(32, 32, 2), stddev=1.0/32.0),
name="a", trainable=True)
self.b_var = tf.Variable(tf.random.normal(shape=(32, 32, 2), stddev=1.0/32.0),
name="b", trainable=True)
self.bias = tf.Variable(tf.zeros(shape=(32, 32)), name="bias", trainable=True)
def call(self, inputs):
# Define the contraction.
# We break it out so we can parallelize a batch using
# tf.vectorized_map (see below).
def f(input_vec, a_var, b_var, bias_var):
# Reshape to a matrix instead of a vector.
input_vec = tf.reshape(input_vec, (32,32))
# Now we create the network.
a = tn.Node(a_var, backend="tensorflow")
b = tn.Node(b_var, backend="tensorflow")
x_node = tn.Node(input_vec, backend="tensorflow")
a[1] ^ x_node[0]
b[1] ^ x_node[1]
a[2] ^ b[2]
# The TN should now look like this
# | |
# a --- b
# \ /
# x
# Now we begin the contraction.
c = a @ x_node
result = (c @ b).tensor
# To make the code shorter, we also could've used Ncon.
# The above few lines of code is the same as this:
# result = tn.ncon([x, a_var, b_var], [[1, 2], [-1, 1, 3], [-2, 2, 3]])
# Finally, add bias.
return result + bias_var
# To deal with a batch of items, we can use the tf.vectorized_map
# function.
# https://www.tensorflow.org/api_docs/python/tf/vectorized_map
result = tf.vectorized_map(
lambda vec: f(vec, self.a_var, self.b_var, self.bias), inputs)
return tf.nn.relu(tf.reshape(result, (-1, 1024)))
In this example, we hard-coded the size of the layer, but that is fairly easy to adjust. Having made this layer, we can use it as part of a Keras model very simply:
tn_model = tf.keras.Sequential(
[
tf.keras.Input(shape=(2,)),
Dense(1024, activation=tf.nn.relu),
# Here use a TN layer instead of the dense layer.
TNLayer(),
Dense(1, activation=None)
]
)
モデルは、Keras fitを使用して通常どおりトレーニングできます。
トランスなどの圧縮
上で説明した簡単な例は、テンソル化のアイデアの良い例ですが、その特定のモデルはおそらく実際にはあまり役に立ちません。 より現実的なものとして、最近、非常によく似た方法でTransformerモデルをテンソル化する実験を行いました。 私たちが見たモデルには、はるかに大きな密度の層がありました。元のモデルには236Mのパラメーターがありました! 4コアテンソルネットワークを備えた8つのTransformerブロックの完全に接続されたレイヤーをテンソル化しました:
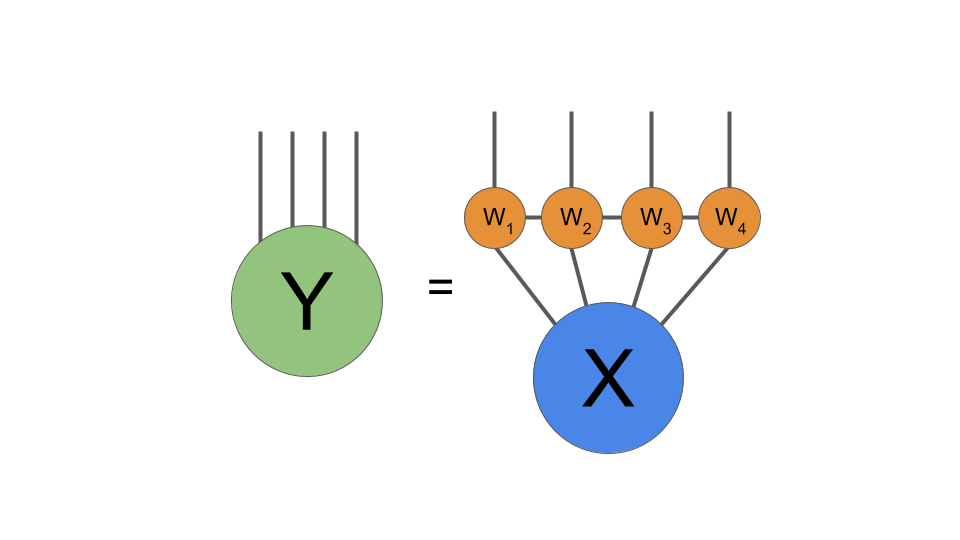
Transformerモデルの完全に接続されたレイヤーをテンソル化するために使用した4コアのテンソルネットワーク。
テンソル化後、モデルは約101Mパラメーターに縮小しました! テンソル化モデルは、はるかに小さいことに加えて、英語の文を大幅に高速で生成しました。 これは、パフォーマンスの違いを示すビデオです。
ニューラルネットワークのさまざまなタイプのレイヤーに適用できる他のタイプのテンソルネットワークとテンソル分解がいくつかありますが、ここでは完全な参照リストを提供しようとはしません。 しかし、はじめに、Khrulkov et alをチェックしてください。 埋め込み層のテンソルネットワーク、Ma et al。 注意層のため、およびレベデフ等。 畳み込み層用。
ニューラルネットワークのテンソル化はまだ初期段階です。 まだ多くの未回答の質問があり、試行すべき多くの実験があります。 この投稿で検討するすべてのテンソルネットワークは、物理学ではMPO(このペーパーも参照)として知られているテンソル列タイプですが、PEPSやMERAなどの他のよく研究されたテンソルネットワークも使用できます。 TensorNetworkライブラリは、可能性のあるすべてのテンソルネットワークを処理するように設計されており、特にここで説明したように、機械学習のコンテキストで処理するように設計されています。 私たちは、あなたがそれを使って料理できる新しい刺激的な結果のすべてを見るのを楽しみにしています。(からのソース: https://blog.tensorflow.org/2020/02/speeding-up-neural-networks-using-tensornetwork-in-keras.html)
彩蛋:
GravitylinkはGoogle Coralの量販代理店としてアジア、北米、欧州、その他の国・地域に広がる世界的販売網を構築している。その開始以来、多数の企業が生産開発のため、GravitylinkオンラインストアでCoralデバイスの大量購入をしている。

詳細はhttps://store.gravitylink.com/ を参照。大量購入については割引が可能で、さらにどの製品でもGravitylinkで購入すれば、移行学習ツールやさまざまなAIモデルリソースが提供される。