まずはデータを準備します。
import numpy as np
import pandas as pd
from sklearn import datasets
iris_all = datasets.load_iris(as_frame=True)
iris = iris_all['data']
iris_target = iris_all['target']
iris.shape,iris_target.shape
# iris_all.keys()
# iris_all['DESCR']
iris = pd.concat([iris,iris_target],axis=1)
iris_0 = iris.query('target==0')
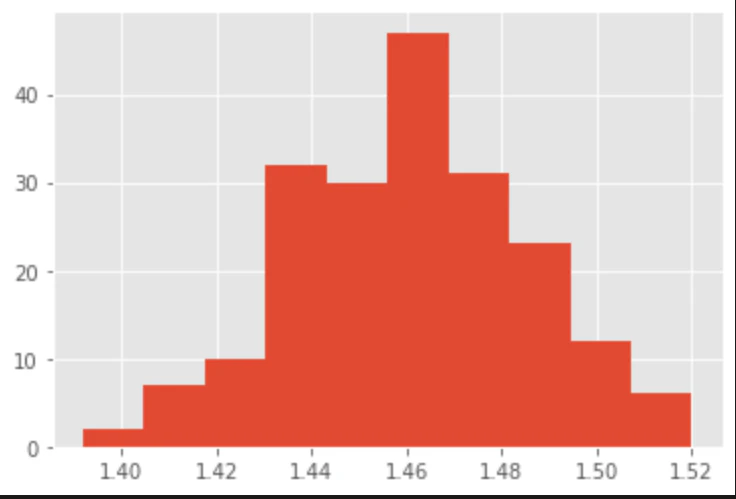
ブートストラップ法による標本平均の分布のサンプリング
対象 Petal length 花びらの長さ
1. 一様分布に従って乱数を len(iris_0) 個生成
2. そのPetal lengthの平均を標本平均とする
3. 1~2を200回繰り返す
4. 標本平均の分布の様子を観察
cycle = 200
sample_mean_list = []
for i in range(cycle):
# 1.Generate a uniform random sample from np.arange(len(iris_0)) of size 50:
random_numbers = np.random.choice(len(iris_0), len(iris_0))
# 2.
sample = iris_0.iloc[random_numbers]
sample_mean = np.mean(sample['petal length (cm)'])
sample_mean_list.append(sample_mean)
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.hist(sample_mean_list)
結果は以下の通り。単純で強力な手法だなと思いました。詳しくは統計検定準1級の内容らしいの今回はここまで。